基于用户行为序列的概率矩阵分解推荐算法
2020-07-13王运,倪静
王 运,倪 静
(上海理工大学 管理学院,上海 200093)
1 引 言
近年来,随着互联网对人们生活的逐渐渗透,人们面临的信息量呈现爆炸式增长.根据《中国互联网络发展状况统计报告》可知,截至2018年12月,我国的网民规模已达8.29亿,互联网普及率为59.6%,网站数量达到523万个.面对如此复杂的场景,如何为用户准确推荐需要的信息显得尤为重要.传统的推荐算法主要分为基于协同过滤的推荐算法[1]、基于内容的推荐算法[2]、基于关联规则的推荐算法[3]和基于效用的推荐算法[4]等.关于这些算法的研究应用也有很多,例如,文献[5]通过用户的地域特征数据计算用户之间的相似度,并将用户相似度数据用于协同过滤推荐;文献[2]将卷积神经网络应用到基于内容的推荐算法中,实验表明算法取得了较好的结果;文献[6]提出了一种分布式计算框架,并结合关联规则进行推荐,与传统的推荐算法相比具有显著的效果提升.另一方面,广大专家学者通过寻找更多的用户物品信息,并以此提高用户相似度的准确度,进而提高推荐的效果.如文献[7]根据用户社交信任数据计算用户之间的社交相似度,提高了用户相似度值的准确度,进而提高了算法的预测准确度;文献[8]利用用户及物品数据计算用户偏好模型,在计算得到用户偏好相似度后,将用户相似度融入传统协同过滤推荐算法,实验表明算法具有一定的有效性.但是,推荐算法在运用的过程中仍然面临数据稀疏的问题,比如用户冷启动,推荐系统中的新用户通常没有充足的社交信任等信息来计算用户相似度.
在2006年的Netflix竞赛中,有人将矩阵分解技术运用到了推荐算法中,竞赛结果表明该方法在评分预测准确性方面具有显著的提升,至此,广大专家学者不断展开对矩阵分解技术的研究.文献[9]提出了BiasSVD算法,在矩阵分解的过程中融入用户或物品的偏置因素,实验表明提高了评分预测准确性;文献[10]提出了SVD++,将基于领域的推荐算法和BiasSVD算法进行融合,进而更进一步提高预测准确性;文献[11]将概率论相关知识引入矩阵分解,提出了基于概率矩阵分解的推荐算法,在算法的可解释性和评分预测准确性方面均有提升.因此,矩阵分解技术与传统算法的融合对于算法的预测准确性具有很大的提升.
但是,广大专家学者总是通过寻找更多的用户数据来提高算法预测准确性,没有充分利用已有的数据,即在用户数据稀疏的情况下对数据的利用效率不高.本文在上述研究基础上提出了基于用户行为序列的概率矩阵分解推荐算法UBS-PMF(Probability Matrix Factorization Recommendation Algorithm Based on User Behavior Sequence),通过分析用户评分数据和物品标签数据得到用户的评分行为转移序列和偏好转移序列,进而挖掘用户之间的关系和物品之间的关系,将所得用户(物品)相似度矩阵融入概率矩阵分解模型中,Movielens数据集中的实验表明UBS-PMF算法提高了对用户物品评分数据的利用效率,在评分预测准确性上具有一定的提升.
2 相关工作
传统推荐算法在运用的过程中经常面临数据稀疏的缺点,而矩阵分解技术可以很好的改善这个缺点,在利用矩阵分解技术的同时融入更多的用户(物品)信息则可以提高算法的评分预测准确性.文献[12]利用用户的社交信息计算用户之间的社交相似度,将所得社交相似度矩阵融入概率矩阵分解模型,实验表明该算法在评分预测准确性方面优于传统的推荐算法;文献[13]通过用户之间的社交信息进一步挖掘用户之间的信任关系,通常用户对信任用户具有一定的影响力,将用户之间的信任相似度矩阵融入概率矩阵分解模型,实验表明算法进一步提高了预测准确性;文献[14]根据用户社交标签信息和用户信任信息计算用户之间的相似度关系及物品之间的相似度关系,从用户与物品两个角度进行计算,并将计算所得的用户(物品)相似度矩阵共同融入概率矩阵分解模型,Last.fm数据集中的实验表明增加用户信息或者从用户物品角度共同进行特征提取,最终可以取得更准确的预测结果.因此,在传统的推荐算法中融入概率矩阵分解相关知识可以提高预测的准确性.
将矩阵分解技术运用到推荐算法中可以带来更好的推荐效果,但是对用户(物品)相似度的计算准确度有较高的要求,因此,许多研究人员从用户(物品)信息量的角度出发,通过寻找更多的用户(物品)信息来提高相似度的计算准确度,从而提高算法的预测准确性.正如上文所述,有许多学者利用用户偏好、用户社交以及用户信任等信息来计算相应的相似度.另一方面,在实际应用中,推荐系统总会面临数据稀疏的缺点,如用户冷启动问题,关于用户的信息种类通常很少,基本只具备用户物品评分信息.如果可以提高对用户物品评分信息的利用效率,深度挖掘用户(物品)之间的相似度,那么对预测准确性的提升也会有很大的帮助.
因此,本文提出了基于用户行为序列的概率矩阵分解推荐算法,利用用户物品评分信息得到用户对物品的评分行为序列,将用户对物品的评分序列转化为用户对标签的评分序列,即为用户偏好转移序列并计算出对应的用户相似度矩阵,同时,利用用户物品评分序列也可挖掘出物品之间的关系,即为物品相似度矩阵,最后,将用户相似度矩阵和物品相似度矩阵共同融入概率矩阵分解模型中并做评分预测.
3 概率矩阵分解模型
基于矩阵分解的推荐算法相较于传统推荐算法提高了评分预测的准确性,而基于概率矩阵分解的推荐算法则在此基础上融入了概率论相关知识,从概率的角度出发计算与解释矩阵分解技术,对于算法的可解释性和与预测准确性都做到了更进一步提升.
如表1所示为本文算法所用符号及对应解释:
表1 数学符号
Table 1 Mathematical notations

符号解释M、N用户集合、物品集合UMK、VNK用户特征矩阵、物品特征矩阵Ui用户i的特征矩阵Vj物品j的特征矩阵Mi用户i的相似用户集合Nj物品j的相似物品集合Wi,j用户l与用i的相似度Sk,j物品k与物品j的相似度Ri,j用户i对物品j的真实评分^Ri,j用户i对物品j的预测评分W、S用户相似度矩阵、物品相似度矩阵λU、λV、λW、λSU、V、W、S的正则化系数Ii,j用户i对物品j有评分时为1,否则为0

(1)

(2)
(3)
由贝叶斯公式可得U与V的概率分布函数如公式(4)所示:
p(U,V|R)∝p(U,V,R)=p(R|U,V)p(U)p(V)
(4)
最大化公式(4)可得公式(5)所示目标函数:
(5)
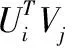
4 UBS-PMF算法
4.1 算法原理
根据本文前几节可知,将概率矩阵分解模型应用在推荐系统中可以提高评分预测的准确性,同时,在融合后的模型中加入用户(物品)相似度矩阵会更进一步提升算法效果,且该模型对用户(物品)相似度的计算准确度有较高要求.如图1所示为基于用户物品相似度的概率矩阵分解模型.
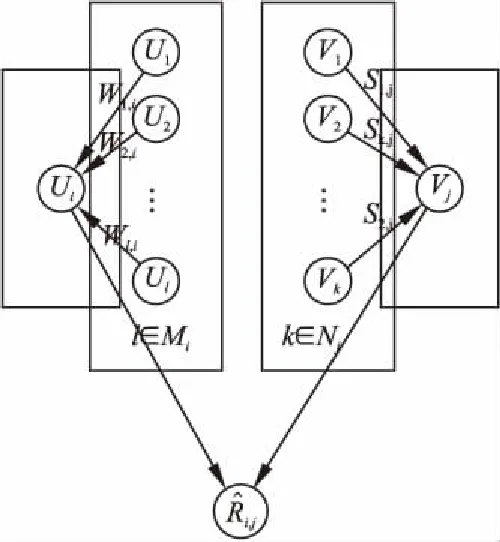
图1 基于用户物品相似度的概率矩阵分解模型
图1中,用户i的特征向量受到相似用户l∈Mi的影响,物品j的特征向量受到相似物品k∈Nj的影响,融合相似用户(物品)信息可以提高用户(物品)特征向量的计算准确度,进而提高预测准确性.
在推荐系统中,用户物品评分信息是最基本的数据,且通常包含用户评分时间,根据这些数据可以得到用户的评分行为序列,同时,物品通常具有许多对应的标签,进而得到用户关于标签的评分序列,即为用户偏好转移序列,根据用户偏好转移序列可以计算出用户相似度矩阵;另一方面,多个用户评分行为序列也隐藏着物品之间的关系,如大量用户在评分过A物品后总会评分物品B,则说明物品A与物品B具有一定的相似度,因此可得物品相似度矩阵.最后,将计算所得用户相似度矩阵和物品相似度矩阵融入图1所示的概率矩阵分解模型中并做评分预测.
4.2 用户行为序列在计算用户相似度中的应用
根据4.1可知,利用用户物品评分信息可以得到用户对物品的行为序列,如图2所示为某一用户对物品的行为序列示意图.同时,利用用户行为序列和物品标签信息可以得到用户的偏好转移序列,如图3所示为某一用户的偏好转移序列示意图.

图2 用户行为序列示意图
Fig.2 User behavior sequence diagram

图3 用户偏好转移序列示意图
图3 中,由于物品包含的特征标签有时不止一个,因此,用户在某一时刻可能会对多个标签具有行为.用户在相邻时刻的行为可以反映出用户的偏好转移信息,若两个用户具有很多相同的转移序列,则说明他们的偏好转移相似,即用户之间具有很高的相似度.该转移序列即为图3中每两个相邻特征标签之间的连线.
对于用户i与用户l,有公式(6)所示用户相似度计算公式:
(6)
公式(6)中,seqi、seql分别为用户i和用户l的行为序列总数,seql,i为用户i和用户l的共同行为序列总数.例如,若用户i、用户l的行为序列总数分别为2个和3个,这两个用户的共同行为序列总数为1个,则说明用户i有1/2的行为序列和用户l的1/3序列是相同的,因此,这两个用户的相似度为1/6.
由于用户的特征受到相似用户的影响,则对于用户i,有公式(7)所示公式:
(7)
将公式(7)以矩阵形式进行描述可转化为公式(8)所述形式:
(8)
(9)
所以,融合用户相似度的用户潜在特征向量的概率分布如公式(10)所示:
(10)
4.3 用户行为序列在计算物品相似度中的应用
在概率矩阵分解模型中融入用户相似度矩阵和物品相似度矩阵可以提高评分预测的准确性.关于物品相似度的计算,很多专家学者通过物品的标签或者热度等信息来计算,通常物品的信息较难获取,计算所得相似度也不够准确,因此,最终的评分预测准确性仍然有待提高.
但是,不通过物品的标签等数据也可以计算物品之间的相似度,如利用用户行为序列计算物品相似度.图2所示为某一用户的行为序列,在推荐系统中包含许多类似的行为序列,如果存在许多用户在对物品1有行为后都对物品2有行为,则可以说明物品1与物品2之间具有一定的关联度,即可认为是物品之间的相似度.推荐系统具有大量的用户行为数据,因此,计算所得物品相似度较为准确.
对于任意物品k与物品j,物品k对物品j的影响力(相似度)为Sk,j,计算方法如公式(11)所示:
(11)
公式(11)中,numj为所有用户对物品j有行为后对下一物品的行为总数,numj,k为所有用户对物品j与物品k先后存在行为的总数,且物品k对物品j的相似度和物品j对物品k的相似度不相等,即存在物品相似度的有向性.
同4.2,对于物品Vj,有公式(12):
(12)
(13)
所以,融合物品相似度的物品潜在特征向量的概率分布如公式(14)所示:
(14)
4.4 UBS-PMF模型
由4.1、4.2及4.3可知,融合用户相似度矩阵、物品相似度矩阵和概率矩阵分解模型可得公式(15)所示后验概率公式:
(15)
最大化上述概率时,可得如公式(16)所示目标函数:
(16)
(17)
(18)
对Ui与Vj进行梯度下降法迭代时满足公式(19)及公式(20):
(19)
(20)
公式(19)与公式(20)中,α为学习速率,用以控制用户特征向量与物品特征向量在每次迭代时取值变化的大小,当迭代结束时即可得到相应用户特征矩阵和物品特征矩阵,也可预测出任何用户对任何物品的评分.
4.5 算法步骤
本文的算法主要分为输入输出两步:
输入:用户物品评分矩阵R、用户和物品特征矩阵的维度K、物品标签属性数据T、算法最大迭代次数maxepoch、正则化系数λ、用户相似度的正则化系数λW、物品相似度的正则化系数λS、学习速率α,读入总批次num_batches及每批读取数据的数量batch_size.
输出:用户潜在特征矩阵UMK和物品潜在特征矩阵VNK,迭代次数变化时RMSE的变化情况.
具体步骤如下:
Step 1.读入用户物品评分矩阵,并按8∶2划分数据集为实验用到的训练集和测试集;
Step 2.利用用户评分数据及物品标签属性数据计算用户行为序列和用户偏好序列;
Step 3.利用用户偏好序列数据和公式(6)计算用户相似度,进而得到用户相似度矩阵W;
Step 4.根据用户行为序列数据和公式(11)计算物品相似度,进而得到物品相似度矩阵S;
Step 5.初始化用户特征矩阵和物品特征矩阵为正态分布;
Step 6.分批读入训练集中的数据,根据公式(16)计算目标函数;
Step 7.根据公式(19)和公式(20)迭代计算用户特征和物品特征,并计算训练集和测试集的RMSE.
5 实验分析
本文的研究主要有两个目的:
1)验证UBS-PMF算法优于传统推荐算法;
2)验证无论从用户角度还是物品角度,基于用户行为序列的概率矩阵分解推荐算法均可以提高评分预测准确性.
5.1 数据集
本文实验所用数据集为Movielens-100k数据集,该数据集由明尼苏达州大学的GroupLens项目组开发,数据集包括943名用户的基本信息,1682部电影的标签信息以及用户对电影的评分信息,评分记录多达100000条.另外,每位用户对超过20部电影有评分,数据集有动作、冒险、儿童,纪录片等18种标签[15].
实验数据集包含了用户的评分信息(包含评分时间)以及物品的标签信息,但是没有用户社交信任等信息,同时,用户的评分电影数不多,满足了用户数据稀疏的背景,且包含的数据可以计算用户的行为序列以及用户的偏好转移序列,便于算法的计算.
5.2 评价指标
为了验证UBS-PMF算法的相对优劣,本文采用均方根误差RMSE(Root Mean Square Error)作为评价指标,RMSE计算方法如公式(21)所示:
(21)
公式(21)中,Γ为测试集,计算所得RMSE值越小,则说明真实值与预测值的偏差越小,即算法性能越好.采用均方根误差来评价算法的性能,对真实值和预测值的误差进行平方处理,扩大了计算的结果,对算法要求更为严格,也更能体现出算法的优劣情况.
5.3 参数调整
本文提出了UBS-PMF算法,该算法包含的参数有用户特征矩阵和物品特征矩阵的维度K、迭代次数maxepoch、正则化系数λ、用户相似度的正则化系数λW、物品相似度的正则化系数λS、学习速率α,读入总批次num_batches及每批读取数据总量batch_size.
对于参数K,通常取值较小时算法的结果较好,为了对比出最优的参数K,本实验选取了2、4、6、8、10五组数据,并对比在不同迭代次数下测试集RMSE的变化情况,实验结果如图4所示.

图4 不同参数K及迭代次数对实验结果的影响
由图4可以发现,当迭代次数增加时,各参数下的RMSE值整体先变小后逐渐趋于平缓,当参数K取值为2时,算法的结果整体较差,同时,取值为4到10时,算法结果较为接近,因此,合适的参数K可取值为10.

图5 不同参数α及迭代次数对实验结果的影响
参数α为学习速率,通常对算法结果影响不大,只影响算法迭代到最优值的快慢,取值过小时,迭代到最优解的速度过慢,取值过大时,迭代所得结果相对较差.本文实验选取0.5、1、5、10四组数据进行实验对比,其结果如图5所示.
正如图5所示,当参数α取值为0.5或1时,随着迭代次数的增加,RMSE值整体先变小后趋于平缓,当参数α取值为5或10时,RMSE值随着迭代次数的增加几乎没有变化,且最终当参数α取值为1时,RMSE值最小,所以,最优的参数α取值为1.
参数λ为正则化系数,用以调整算法性能,防止出现过拟合现象,结合广大专家学者的已有实验,在本文的实验中,将选取0.005、0.01,0.05、0.1和0.5五组数据进行实验对比,不同参数λ及迭代次数下的RMSE变化情况如图6所示.

图6 不同参数λ及迭代次数对实验结果的影响
由图6可知,随着迭代次数的增加,不同参数λ下的RMSE值整体先变小再逐渐趋于平缓.当参数λ取值为0.005至0.1时,随着参数值的增加,RMSE值整体逐渐变小,当参数λ取值为0.5时,RMSE值整体最大,所以,最优的参数λ应当取值为0.1.同时,λW与λS对实验的影响与λ类似,为了不失一般性及实验对比的方便,λW与λS均取值为0.1.
5.4 算法对比
经过大量的实验,UBS-PMF算法中的参数得到了调整,为了对比出本文算法的相对优劣,将选取其他几种经典的推荐算法进行对比.由于UBS-PMF算法属于基于矩阵分解的推荐算法,且算法的评分预测准确性与迭代次数有关,因此,将选择与矩阵分解和迭代次数有关的推荐算法进行对比,本文选择的算法有概率矩阵分解推荐算法(PMF)、融合用户行为序列和用户相似度的概率矩阵分解推荐算法(UBUS-PMF)、融合用户行为序列和物品相似度的概率矩阵分解推荐算法(UBIS-PMF)、融合用户偏好和物品相似度的概率矩阵分解推荐算法(UPIS-PMF).实验所得算法对比结果如图7所示.
图7中,PFM算法为没有融入用户相似度矩阵和物品相似度矩阵的概率矩阵分解推荐算法;UBUS-PMF算法为根据用户行为序列计算用户相似度,并将用户相似度矩阵融入概率矩阵分解模型;UBIS-PMF算法为根据用户行为序列计算物品相似度,并将物品相似度矩阵融入概率矩阵分解模型;UPIS-PMF算法为根据用户评分信息及物品标签信息计算用户对标签的评分,即为用户偏好,并可得用户相似度矩阵,再根据物品标签信息计算物品相似度矩阵,最后将所得的两个相似度矩阵共同融入概率矩阵分解模型;UBS-PMF则为本文的算法.上述五种算法的RMSE值变化趋势均为随着迭代次数的增加先变小再逐渐变平缓,PMF算法的RMSE值整体最大,即算法的评分预测准确性最低,UBUS-PMF算法和UBIS-PMF算法相对PMF算法整体相对较小,即将用户行为序列应用在用户相似度矩阵或者物品相似度矩阵的计算中均可以提高评分预测的准确性,而UPIS-PMF算法相对之前三种算法的RMSE值整体更小,因为该算法同时考虑到了用户相似度和物品相似度,最后,对于本文的算法(UBS-PMF),将用户行为序列同时应用在用户相似度和物品相似度的计算中,算法的RMSE值整体最小,说明了UBS-PMF算法评分预测准确性最高,即优于传统的推荐算法.综上所述,图7中的实验数据表明本文的研究目的已达到.

图7 不同迭代次数下的各类算法对比图
6 总结和展望
概率矩阵分解推荐算法在评分预测准确性方面相较传统推荐算法有所提升,但是算法在实际应用中经常面临数据稀疏的缺点,且对已有数据的利用效率不高.针对上述问题,本文在广大专家学者的研究基础上提出了基于用户行为序列的概率矩阵分解推荐算法,通过用户对物品的评分信息(包含评分时间)计算用户行为序列,同时根据用户行为序列和物品标签信息计算用户的偏好序列,然后计算出关于用户的相似度矩阵和关于物品的相似度矩阵,最后,将所得用户(物品)相似度矩阵共同融入概率矩阵分解模型中.Movielens数据集中的实验表明该算法优于传统的推荐算法,同时也说明了无论从用户角度还是物品角度,融入用户行为序列信息均可以提高评分预测准确性.
但是,由于本文所用数据集信息有限,在算法的对比部分只做到了与传统的几种推荐算法进行对比,没有同基于社交网络的推荐算法、基于用户信任的推荐算法等多种推荐算法进行对比,计划在接下来的研究中寻找用户信息更加全面的数据集进行对比.另一方面,对于近几年比较火热的深度学习和马尔科夫等技术,计划研究用户行为序列与这些技术的结合,并对比在不同模型中的评分预测准确性,从而也更能说明用户行为序列在用户(物品)相似度计算过程中的有效性.
