一种结合主题模型与段落向量的短文本聚类方法
2020-07-08饶毓和凌志浩
饶毓和, 凌志浩
(华东理工大学化工过程先进控制和优化技术教育部重点实验室,上海 200237)
随着互联网日益深入人们的日常生活,以互动交流为特点的Web2.0 技术进入了高速发展阶段,其中包括Twitter、微博、Facebook 以及各种即时信息工具等多种互联网新媒体平台。这些平台每时每刻都在产生着大量的内容简短、特征稀疏的半结构性或非结构性文本数据,如何处理这些短文本数据进而从中提取出有价值的信息已经成为当下互联网领域的技术热点。
文本聚类是文本信息挖掘领域的一个常见方向,目前已被广泛用于信息检索、搜索引擎等方面,然而对于短文本而言,其所具有的高维度性和特征稀疏性使得短文本聚类面临着诸多挑战。稀疏性带来了包括上下文信息不足、词共现信息不足等问题,具体来说,由于短文本所包含的单词数量很少,且大部分单词只出现一次,如果继续使用传统的向量空间模型(Vector Space Model, VSM)来表示短文本,极度稀疏的高维特征向量将会导致内存与计算时间的过度开销。另外,由于单词数量过少,词频统计将失去意义,所以常用的词频-逆文档频率加权(TF-IDF)也不适用于短文本[1]。
为了克服短文本的稀疏性和高维度性,相关学者已经进行了大量研究,比如引入外部信息源或重新构建新的针对短文本的模型等。然而,在如何进一步提升短文本聚类质量方面的研究目前还有待深入。文本聚类的关键在于对文本特征的提取,而现有常用的文本特征大都存在所含信息单一且信息量较少的缺陷,进而导致文本聚类时特征对短文本的区分能力不强,聚类效果有待改善。本文在前人研究的基础上,从统计学与神经网络算法的角度出发,提出了一种结合词对主题模型与段落向量的短文本聚类方法,旨在将主题信息融入由神经网络算法得到的文本特征向量中,以期能结合二者的优点加强文本特征向量对短文本的区分能力,同时避免受到短文本稀疏性而造成的影响。
1 相关工作
针对短文本聚类时所面临的稀疏性等问题,相关研究大致分为两个方向,一种是引入外部知识源,如利用WordNet[2]、HowNet[3]、Wikipedia[4]以及其他用户自行构建的知识库[5]将短文本扩展为长文本,但是该方案存在两个问题,一是需要保证外部知识源的时效性,比如对于微博中所讨论的新热门话题是难以第一时间在诸如百度百科这样的外部资料中找到的,所以这就需要对外部知识源及时更新与维护,不过由此产生的相关成本和代价很高;二是如何保证外部加入信息的正确性以及如何正确地使用这些信息,这已经成为了该方案所带来的新的挑战,而处理这些问题自身已经相当复杂[6]。
因此,研究者们将目光放在了对传统的普通文本处理方法的改进或是对新模型的设计上,以此来应对短文本的稀疏性。Xu 等[7]提出了一种利用词向量与自学习的动态卷积神经网络来提取短文本特征进而实现短文本聚类的方法,该方法能将原本用高维词袋模型表示的短文本转化为用低维稠密向量表示;Yin 等[1]利用Dirichlet 多项式混合模型进行短文本聚类,结果表明该方法能有效克服短文本的稀疏性和高维度问题;文献[8]假定在给定的短文本语料库中词与主题之间存在一个固定的语义结构,在此基础上可以推断出文本的主题比例向量,然后根据主题比例向量和主题在单词上的分布生成额外的单词以扩充短文本,由于额外扩充的单词来自于数据集本身,所以该文中的扩充集不需要外部知识源;文献[9]通过定义基于词性和词长度加权的特征词提取公式并提取特征词来表示短文本,然后利用词向量与词语游走距离(Word Mover’s Distance, WMD)计算短文本间的相似度并将其应用到层次聚类算法中实现短文本聚类。纵观这些方法可知,其中的一类基于统计学,另一类则是主要依赖于神经网络的单一方法,而本文则是将基于统计的主题模型(BTM)和基于神经网络的文本向量化方法(PV-DBOW)结合起来,以达到改善短文本聚类效果的目的。
2 短文本的特征表示与聚类
在实际的短文本处理中,时常会遇到这样一种情况:同一个词在不同主题下的语义相差甚远,比如单词“苹果”,它在“水果”主题下和在“信息技术”主题下分别表达的是“一种水果”和“一家信息科技公司”两种意思,这种同一个词受不同主题影响的情形,本文称其为“主题歧义”。如果能有效地区分出这些歧义,无疑能改善文本聚类的效果。为此,本文提出了一种利用主题信息对特定词语进行语义拆分的方法,直观的理解就是利用主题信息将上述例子中的“苹果”分别拆分成“水果中的苹果”和“信息技术中的苹果”这样两个词,使得后续步骤进行文本向量化时能对二者有所区分。
为了获取单词的主题信息,本文使用了一种既适合于长文本也适合短文本的词对主题模型,流程如图1 所示。主要步骤描述如下:
(1)利用通过词对主题模型求出的词-文档-主题概率分布结合局部离群因子与JS 散度对整个文本集合中的词语进行语义拆分;
(2)将经过词语拆分后的文档输入文本向量化模型PV-DBOW 得到对应的段落向量,再将段落向量与对应的文档-主题概率分布拼接起来构成文本特征向量;
(3)在整个特征向量集中使用K-means 算法完成短文本聚类。

图1 短文本聚类过程Fig. 1 Process of short text clustering
2.1 主题信息的获取
BTM 由隐Dirichlet 分布(Latent Dirichlet Allocation,LDA)改进而来,与LDA 不同,BTM 不是直接对文档进行建模,而是对整个文本集合中的词对进行建模,并认为集合中的所有词对共享一个主题分布,这样能依靠整个文本集合来估计这个主题分布,从而有效缓解因文档单词数量过少所带来的主题推理中的稀疏问题[10]。
2.1.1 主题-词概率分布与文档-主题概率分布 在BTM中,将同一文档内特定大小窗口中的词两两结对,称其为词对,BTM 的主要内容就是从文本集合中抽取出所有词对,然后基于词对建立概率模型。模型生成过程如下:
(1)确定短文本集合的全局主题概率分布θ~Dirichlet(α)。
(2)确定每一个主题z 所对应的词概率分布φ~Dirichlet(β)。
(3)对于词对集合B 中的每一个词对b=(wi,wj),重复以下操作:
(a)从全局主题概率分布θ 中抽取一个主题z,z~Multinomial(θ);
(b)从主题z 所对应的词分布φ 中抽取两个词,则wi,wj~Multinomial(φ)。
BTM 概率图模型如图2 所示,图中K 表示主题数目,|B|表示整个文本集合中词对的数目,α、β 是Dirichlet 分布的超参数。
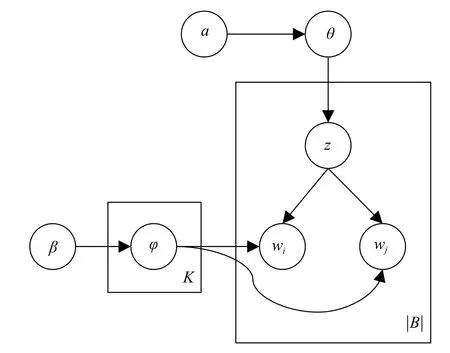
图2 BTM 概率图模型Fig. 2 Probabilistic graphical model of BTM


2.2 词语拆分
对于具有“主题歧义”的单词,需要对其进行语义区分以提升聚类的精度。本文采用词-文档-主题概率分布与局部离群因子相结合的方法,将同一个词按不同主题进行拆分。考虑到同一个词在同一短文本中的主题信息基本保持不变,所以该方法实际上针对的是单词在不同文本中的语义拆分。




2.3 文本向量化与聚类


3 实验部分
3.1 实验数据
实验使用了2 个带有主题标签的语料库:(1)搜狗实验室新闻语料库,从中选取了互联网、教育、金融、军事、汽车、体育、娱乐7 个主题,每个主题选取了2 000 条短新闻共14 000 条文本;(2)复旦大学文本分类语料库,从中选取了金融、农业、体育、艺术、政治5 个主题,每个主题各选取2 500 条,一共12 500条短文本。
3.2 实验对比
为了验证本文方法所得的特征向量对短文本具有更强的区分能力,使用几个常用的且同样是无监督学习的文本向量化方法与之对比。
(1)词向量算术平均。通过Skip gram 模型求出文本集合中所有词语对应的词向量,然后将每一个文档中的所有词的词向量累加并求算术平均作为该文档的文本向量,为了方便叙述,本文将该方法称为WM2Vec(Word Mean to Vector)。
(2)词向量加权平均。参考文献[15],先得到所有词语的词向量,然后将文档中的词向量进行加权平均,得到平均向量,这里的权重使用的是平滑逆词频(Smooth Inverse Frequency, SIF),最后移除平均向量在所有文本向量所组成矩阵的第一主成分上的投影,并将移除主成分后的平均向量作为文本向量,将该方法称为SIF2Vec。
(3)PV-DBOW。直接利用PV-DBOW 模型得到文本集合中的各个文档的段落向量,将该方法称为Doc2Vec(Document to Vector)。
(4)BTM。利用BTM 求出文本集合的文档-主题概率分布,然后对于每一个文档而言,将其文档-主题概率分布作为其特征向量,将该方法称为BTM2Vec。
为了得到短文本的聚类结果,方法(1)、(2)、(3)均采用K-means 算法结合Euclid 距离进行聚类,而方法(4)可直接将文档的主题概率分布中的最大概率值所对应的主题作为该文档的主题类别进而完成聚类。
3.3 评价指标
本文选取常用的V-measure 和F1 值评价指标作为聚类效果衡量标准。V-measure 综合考虑了聚类结果的同质性与完整性,令K 代表聚类结果中每个簇对应的样本集合,C 代表实际类别中每一类对应的样本集合,则

F1 值综合考虑了精确率P(Precision)与召回率R(Recall rate)。由于本文实验所用语料库具有多个类别,所以这里使用的是基于微平均法与宏平均法所得的宏F1 值(Macro-F1)和微F1 值(Micro-F1)。
3.4 实验结果与分析
3.4.1 词语语义拆分方法的实验验证 为了测试本文提出的词语拆分方法对最终短文本聚类的影响,对从搜狗新闻语料选取出的文本经过分词、去停用词等预处理后,首先对其进行不同数目的词语拆分操作与对比实验,一共进行7 轮实验,每轮实验除了随机选取进行拆分的词语数目不同以外,其他设定均一致。
第1 轮到第7 轮实验从整个文本集合中分别随 机 抽 取10 000、20 000、30 000、40 000、50 000、60 000、64 854 个词语作为备选词语集合,去除其中的高低频词以及非名词以后,对词语集合进行语义拆分,之后经文本向量化与拼接操作得到特征向量。为了不干扰实验结果,7 轮实验对于λ 值均设置为0.01,最终聚类所得评价结果如图3 所示。按照本文的预想,进行语义拆分步骤的词语越多,则拆分后文本集合中的“主题歧义”现象就越少,文本之间也就越容易区分。从图3 可以看出,随着随机选择进行语义拆分的词语数目逐渐增加,V-measure 与宏F1 值都在上升,证实了本文提出的词语语义拆分的方法确实能有效加强特征向量对文本的区分能力。

图3 聚类结果与随机选取出来进行拆分的词语数目之间的关系Fig. 3 Relation between clustering results and numbers of randomly selected words to be splited
3.4.2 本文方法与其他方法对比实验结果 为了获得相对客观、稳定的实验结果,所有方法在使用Kmeans 聚类时初始值选取的次数都取值足够大(300 次)以保证收敛,此外,每种方法都进行10 轮聚类,取10 次结果的算术平均值作为最终的实验结果。
在具体的参数设置上,设距离阈值α = 0.3,局部离群因子阈值β = 0.95,对于搜狗语料,特征向量权重系数λ 设置为2.5,对于复旦语料,λ 设置为7。基于搜狗语料库的实验结果如表1 所示,基于复旦语料的实验结果如表2 所示。为了便于叙述,将本文方法称为 DT2Vec( Document with Topic Information to Vector)。

表1 搜狗语料聚类结果对比Table 1 Comparison of clustering results of Sogou corpus

表2 复旦语料聚类结果对比Table 2 Comparison of clustering results of Fudan corpus
由表1、表2 可见,在5 种方法中,词粒度的方法(WM2Vec 和SIF2Vec)表现最差,这是因为无论是直接对词向量作算术平均还是作加权平均,所得的文本向量都仅与文档中所含单词有关,而如果两篇短文档中的单词重合度较小,即使它们描述的是同一主题的内容(实际的文本中经常出现用不同的词描述同一类事物的情形),也极有可能被划分为两类,因此实验结果中这2 种方法的聚类效果和其他3 种方法相比出现了明显差距。
基于主题的BTM2Vec 和基于段落向量的Doc2Vec 则好于前2 种方法,这是因为这2 种方法利用了更为全面的信息:前者使用了文本集合中所有的词对作为主题信息,而后者则相对词向量而言加入了综合全段落主旨的段落向量。
本文方法在5 种方法中获得了最好的聚类效果。对于搜狗语料来说,本文方法在V-measure 和F1 值上分别至少提升了4.0%与1.75%;而对于复旦语料,则分别至少提升了2.9%和2.85%;与前4 种方法相比,DT2Vec 所得的特征向量包含了最多的文本特征信息,包括由BTM 所获得的主题信息和由段落向量所获得的段落主旨信息,二者得到了有效的融合,这也就给予了特征向量对短文本更强的区分能力,所以本文方法能有效改善短文本的聚类效果。
为了深入观察本文方法与其他方法相比的改进之处,在实验部分给出本文方法与Doc2Vec 在各个主题上聚类结果的详细对比,采用的对比指标为精确率与召回率。图4 为本文方法与Doc2Vec 在搜狗语料上的精确率对比,图5 为本文方法与Doc2Vec在搜狗语料上的召回率对比。
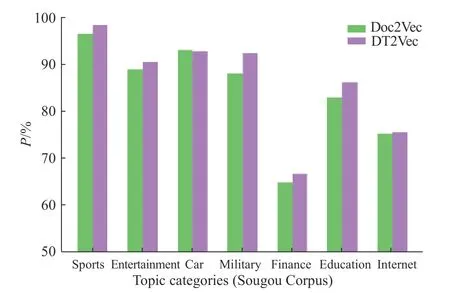
图4 本文方法与Doc2Vec 的精确率对比(搜狗语料)Fig. 4 Precision comparison between DT2Vec and Doc2Vec(Sougou Corpus)
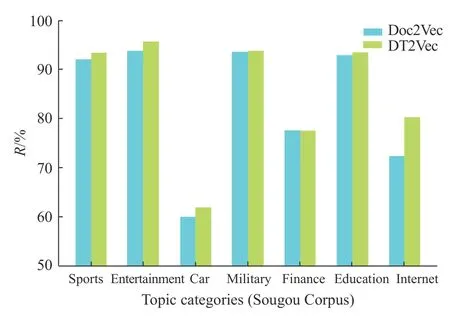
图5 本文方法与Doc2Vec 的召回率对比(搜狗语料)Fig. 5 Recall rate comparison between DT2Vec and Doc2Vec(Sougou Corpus)
由图4、图5 可知,本文方法与Doc2Vec 的聚类结果相比,7 个主题的聚类精确率与召回率绝大部分都得到了提升,再次验证了本文方法的有效性。因为前期已经利用主题信息对“主题歧义词”作了语义拆分,因此使用本文方法所得的段落向量对含“歧义词”文档的区分能力更强,再加上与文档-主题概率分布的拼接,最终的特征向量有效结合了主题信息与段落向量,在保证维度基本不变的前提下丰富了文本特征所携带的信息量,所以利用该文本特征能更好地区分不同主题的文档,具体表现就是对各个主题而言,相应的聚类精确率与召回率都在提升。
另外,从图4、图5 中可以注意到“金融”主题的精确率相比其他主题而言较低,只有64.7%(Doc2Vec)和66.6%(DT2Vec);而“汽车”主题的召回率也同样只有59.9%(Doc2Vec)和61.9%(DT2Vec),不难推测“汽车”和“金融”相互影响,很多“汽车”主题的短新闻在聚类时被划分到了“金融”主题下,从侧面反映了这两个主题之间的彼此辨识度不高,这符合实际生活中的情况。有很多短文本如新闻之类的是同时具备多个主题的,比如描述汽车行业的市场销售值这类新闻,它与“汽车”和“金融”都相关,实际上不应单独将其直接划入“汽车”或是“金融”主题下,解决这类问题的方法之一是为这类短文本提供多个主题标签,这也是本文的后续研究方向。
4 结束语
针对目前短文本聚类常用的文本特征大都存在所含信息单一且信息量较少的缺陷,提出了一种结合词对主题模型与神经网络算法用于短文本聚类的方法,通过利用主题信息对文本集合中的词语作语义拆分、拼接文档-主题概率分布这两种方式将主题信息融入文本特征向量,在保证特征维度较低的前提下丰富了文本特征所携带的信息量,有效地加强了特征向量对文本的区分能力,同时也能避免受到短文本的稀疏性影响。从实验结果来看,短文本最终的聚类效果得到有效改善,证实了上述观点。本文方法为信息检索、搜索引擎等领域提供了一种新的建立短文本特征向量以及文本聚类的思路。另外,在实验过程中,遇到了多主题短文本的情况,这类短文本实际上不应单独划分至某个主题下,因此下一步考虑研究如何为这类短文本提供多个主题标签。
