语音识别技术架构下的英语音标辅助学习平台开发及应用研究
2020-07-06梁玮
梁玮

摘 要:针对传统英语发音学习过程中存在的发音不准确、缺乏发音评价和纠错指导的现状。提出了基于Android平台开发一款发音跟读、发音比对、发音评分和纠错多功能应用的英语发音训练系统。基于短时过零率端点检测进行语音预处理,获得较为稳定的语音段信号,利用美尔倒普系数(MFCC)提取语音信号特征值,获得每帧语音频谱特性。通过矢量间距离计算表征信号的匹配度,在自适应(AP)评价法来实现平均匹配距离与发音评分间的逻辑关系,得到发音共振峰包络图,利用生成的发音共振峰对比图构建发音共振峰和读音口型模型进行发音跟读质量反馈。实际应用结果表明:开发的系统应用能够准确进行定性化的发音口型纠正,有效满足现代英语学习过程中的智能化、实时性和便携化需求。
关键词:语音识别;英语语音;Andorid系统
中图分类号:TP391 文献标识码:A
文章编号:1003—6199(2020)02—0155—05
Abstract:In view of the present situation of inaccurate pronunciation,lack of pronunciation evaluation and error correction guidance in the process of traditional English pronunciation learning. An English pronunciation training system based on Android platform is proposed for pronunciation following reading,pronunciation comparison,pronunciation scoring and error correction. speech preprocessing based on short-time zero-crossing rate endpoint detection to obtain a more stable speech segment signal,using the mer inverted coefficient (mfcc) to extract the speech signal eigenvalues and obtain the speech spectrum characteristics of each frame. Using vector-to-vector distance to calculate the matching degree of the representation signal,the average matching distance and pronunciation evaluation are realized in the adaptive (AP) evaluation method In this paper,the phonetic resonance peak envelope map is obtained,and the model of pronunciation resonance peak and pronunciation mouth pattern is constructed by using the generated phonetic resonance peak contrast map. The practical application results show that the developed system can accurately carry out the correction of pronunciation and mouth shape,and effectively meet the needs of intelligence,real-time and portability in the process of modern English learning.
Key words:speech recognition;English speech;Anorid system
英语作为国際通用语言,一直受到各国重视。国内对英语学习热情一直在不断高涨,各类英语学习软件、平台层出不穷[1-2]。但在整个学习过程中,由于缺乏对英语口语发音的评价和反馈纠正,导致大部分学习中听说能力较弱,难以实现标准的口语化交流。随着互联网信息技术的发展,利用语音识别技术来辅助英语发音学习,在一定程度上有效纠正了学习者的错误发音方式[3],如目前应用较为成熟的FLUENCY外语发音系统,EduSpeak语音系统、PLASER语音发音训练系统等[4-6]。不同的发音系统提供了语音信号的识别捕捉、基于英语发音的类别划分、基于语普、时长的反馈评分等,但各类陪平台均存在一定的缺陷[7-9]。如FLUENCY采用动态时间规整(Dynamic Time Warping DTW)进行英语单词和语句训练识别,有效降低了匹配运算量,但语音发音中未考虑到单词间的相似特征,导致发音评价对比难以实现[10]。PLASER语音系统基于英语单词的因素评分置信度进行区分,导致语音信号特模糊,难以实现精准化匹配,且这些系统主要集中于计算机平台系统,难以实现当前便携化、及时化的训练需求[11]。基于Android平台,在对语音信号进行处理后,采用美尔倒普系数(MFCC)和矢量间距离计算进行语音信号的匹配度计算,利用生成的发音共振峰进行发音跟读质量反馈,实现英语发音和纠错的定性化。
1 语音信号识别和匹配
1.1 语音识别算法设计
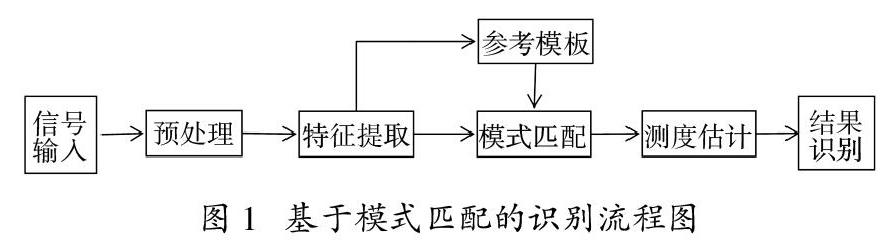
语音识别是由气流激励声道产生,本质上是让机器识别人的语音[12]。即在一个极小的时间段内,利用语音频谱等特征量作为定值参数,利用短时平稳信号处理技术提取语音信号中的特征矢量值,与待测语音特征矢量比较来实现语音的对比识别。如图1为典型的语音识别流程。
预处理:相关研究指出,语音识别系统中存在的识别错误大部分是基于端点检测异常引起[13]。同时,现实学习中存在的背景噪音,进一步增加了语音信号端点检测的难度。针对 Android平台特征,在比较不同端点检测法基础上,采用基于短时过零率端点检测进行语音预处理。由于浊音能量较低,通过率低,清音则具有较高的能量,通过率相对高,采用短时过零率的端点检测法能够较好的判定较为稳定的语音段信号[14]。
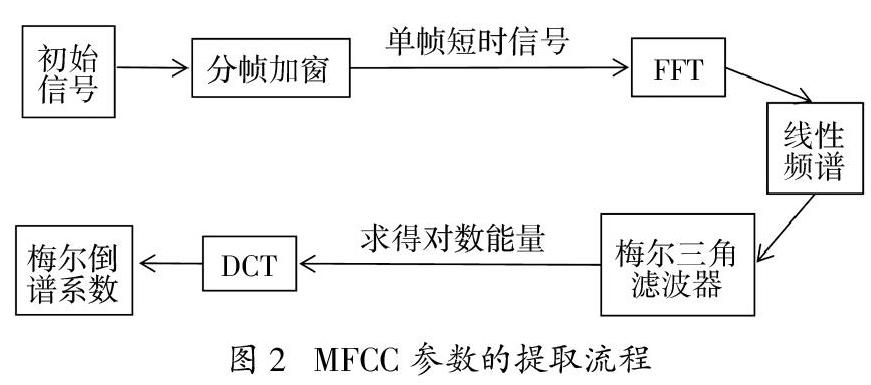
语音信号特征提取:进行语音信号预处理后,需要提取信号的特征参数,利用参数进行语音信号描述方便对信号的后续处理。本系统在比较各类特征参数提取算法的基础上,采用美尔倒普系数(MFCC)[15],如图2为MFCC参数提取流程图。
首先将初始语音信号进行分帧加窗处理获得单帧信号x(n),通过对短时信号x(n)进行傅里叶变换(FFT),获得线性频谱X(k),由三角滤波器得到对数能量S(i),进行离散余弦变换(DCT)得到单帧语音信号的MFCC特征参数:
1.2 语音信号模式匹配
通过比较待评价语音和参考标准语音的特征参数差距来表征两者的相似性。不同语音间的发音语速、方式差异性较大,传统的比较法难以进行区分[16]。采用动态规整(DTW)将测试模板和参考模板特征矢量的匹配度通过矢量间距离表示,即对于特征矢量T(n)和参考模板特征矢量R(m),存在有:
2 发音反馈评价技术
2.1 发音评价算法
通过对测试语音模板和标准模板信号匹配获得匹配距离Dmin(N,M)作为两者发音差异性的度量,建立一个评分机制对相似度进行评分。由于不同发音对应的语音帧长不同,因此,通常采用每帧的平均匹配距离来比较可靠发音水平的高低,即:
式中:N为测试模板帧长。发音反馈评价就是要建立起帧平均匹配距离与发音评分间的逻辑关系。本文基于自适应(AP)评价法来实现平均匹配距离与发音评分间的逻辑关系,定义AP评分算法为:
式中:x、y为自适应函数,通过系统自适应训练生成,具体流程如图3所示:
在评分参数模块中,专家根据学习者的若干发音进行经验评分,因此,每一个发音所建立的MFCC帧匹配距离都对应一个专家评分。即每一个帧匹配距离与专家评分数据,满足关系:
式中,x,y为自适应函数。通过最小二乘曲线拟合获得[17]。当样本空间越大,则获得的拟合函数精度越高。考虑到样本空间太大影响到平台的计算实时性,为简化评分参数生成过程,通常选择最适合的3个样本进行评分计算。
2.2 发音反馈与口型矫正
相关研究表明,元音共振峰的高低与口腔和舌头出力点存在相互对应关系[18]。国际音标中,英语发音共48个音素,包括20个元音和28个辅音。国人在英语发音中主要在于元音的发音。欧美人采用的“后部发音法”,在发音过程中,由口腔后方作为主要发音位置,发音较为细腻。而汉语发音过程中主要以口腔前部发力为主,嘴唇大开大合,舌尖部位灵活,缺乏细腻感,因而容易產生所谓的“中式英语”。
人在发音中,声道和口腔起共振腔作用,通过共振腔的滤波作用能够实现声音能量在不同频率上的重新分配,在某一频率声音得到加强形成共振峰,是发音信息的主要来源。对于英语元音发音,通常包括3个共振峰,其中较低频率共振峰在频谱上较为明显,携带了语音共振峰的主要特征[19]。而共振峰数值与口腔形状和舌位有直接关系,即舌位越高,共振峰越低,开口度越大[20],因此,系统采用较低频的共振峰来判定发音质量。
为得到发音共振峰特性,将初始的信号经过预处理、DFT变换后,获得每帧语音频谱特性。通过距离计算获得语音信号频谱包络,其中获得的包络最大值即是语音最高共振峰[21],如图4中F1即元音第一共振峰。
在语音信号处理时,对于每帧语音,在短时间内可以看作是短时平稳信号,每帧的发音对应的口型和舌位是一定的,不同帧段的共振峰具有唯一性,反应了发音过程中口型和舌尖的变化。在Android平台可采用发音共振峰对比图反应整个发音口型变化,若代表标准参考发音和测试发音所形成的共振波折线重合度越高,则发音越准确。若学习中发音的共振峰偏高于标准参考发音,则根据共振峰的发音口型和舌位置关系,学习者可减小口型,抬高舌位来纠正发音。
3 系统的设计与实现
3.1 开发环境
基于Anroid平台实现软件开发,实现语音跟读、发音对比和评分、反馈一系列功能。系统运行环境如下:
PC操作系统:Windows XP
开发软件/硬件环境:Android 0S 4.0/Andorid智能手机;
编程语言:Java
开发组件:JDK6;Andorid SDK1.8
3.2 功能应用
通过系统功能分析,确定四大功能模块,分别为:视频播放、语音录入、发音评分、发音共振图像显示四大功能模块。其中系统所有界面,均采用扩展活动(Activity)实现。
如图5为系统主界面图。其中包括音标、单词的发声练习等快捷按钮,单击菜单栏按钮会跳转至相应的功能界面,同时,“帮助”按钮会弹出系统帮助窗口。
评分参数自适应作为系统特色,点击“评分自适应”菜单栏便会跳转至自适应训练界面。系统根据每次发音的帧匹配距离与专家打分生成自适应参数,提高评分函数准确性和自适应能力。点击“发音跟读”按钮,系统将示范音频和录入音频对比。点击“图像参考”按钮,后台指令调用相关语音识别算法,显示录制发音和标准发音共振峰对比图形,用户可根据共振图来进行发音纠正。点击“专家评分”按钮,系统计算帧的匹配距离,并显示在评分对话框中。对话中中设置了一个EditText空间来负责获取专家打分数据,并在AlertDialog中建立“生成评分函数”,用户可点击提交,也可以恢复默认评分函数,重新进行录音比对。
本系统中还提供了单词发音练习,当进入单词发音练习集界面后,点击“发音跟读”录入发音,点击“发音对比”进行比对,点击“发音评价”,系统根据评分算法进行评分,并将成绩显示在发音成绩窗口,也可在成绩窗口点击“查看共振峰图”按钮,方便用户进行发音比较和口音纠正。
4 结 论
针对语音识别技术,讨论了语音评分和语音纠正算法。并基于Android平台研发了一款包括语音跟读、语音评价和语音纠正的多功能语音训练系统,实现对语音学习的智能化、便携化。研究的主要成果:
(1)基于AP评分方法将发音评分和反馈纠错模块置于同一系统中生成自适应参数进行发音评分。根据发音工作峰和口型的关系建立发音共振峰对比图实现发音跟读质量反馈,进行定性化的发音口型纠正。
(2)通过Android平台开发建立发音评价和反馈的英语发音训练系统,进行发音跟读、发音比对、发音评分和纠错多功能应用,实现语音发音学习的智能化、实时性和便携化。
参考文献
[1] 景亚鹏,郑骏,胡文心. 基于深层神经网络(DNN)的汉语方言种属语音识别[J]. 华东师范大学学报(自然科学版),2014(01):60-67.
[2] 李春兰. 英语口语自动发音校对系统设计[J]. 现代电子技术,2017,40(24):59-61.
[3] 袁里驰. 基于改进的隐马尔科夫模型的语音识别方法[J]. 中南大学学报(自然科学版),2008,39(06):1303-1308.
[4] 吴延占. 基于HMM与遗传神经网络的改进语音识别系统[J]. 计算机系统应用,2016,25(01):204-208.
[5] 戴礼荣,张仕良,黄智颖. 基于深度学习的语音识别技术现状与展望[J]. 数据采集与处理,2017,32(02):221-231.
[6] 金晓宏. 基于隐马尔可夫模型的英语口语考试智能评分系统[J]. 内蒙古师范大学学报(自然科学汉文版),2017,46(03):386-389.
[7] 王晓斌,倪传斌. 神经认知体系的构建——基于二语语音识别的研究[J]. 南京师大学报(社会科学版),2012(02):116-122.
[8] 刘健刚,马冬梅,赵力. 英语口语机考评分系统除噪处理的研究[J]. 中国科技论文,2012,7(04):302-307.
[9] 李艳玲,颜永红. 多特征融合的英语口语考试自动评分系统的研究[J]. 电子与信息学报,2012,34(09):2097-2102.
[10] 陈妍,邱小军. 母语为汉语的听者听英语时的空间去掩蔽现象研究[J]. 声学学报,2011,36(02):231-238.
[11] 梁青青,杨鸿武. 基于语音识别和语速修改的语音复读系统[J]. 计算机工程,2011,37(05):288-290.
[12] 赵博,檀晓红. 基于语音识别技术的英语口语教学系统[J]. 计算机应用,2009,29(03):761-763.
[13] 冯楚滢,司徒国强,倪玮隆. 协同深度学习推荐算法研究[J]. 计算机系统应用,2019,28(01):169-175.
[14] 王国梁,梁维谦. 嵌入式中等词汇量英语语音识别片上系统[J]. 清华大学学报(自然科学版),2005(10):99-102.
[15] 吴蔚澜,蔡猛. 低数据资源条件下基于Bottleneck特征与SGMM模型的语音识别系统[J]. 中国科学院大学学报,2015,32(01):97-102.
[16] 张文林,牛铜,屈丹,等. 基于声学特征空间非线性流形结构的语音识别声学模型[J]. 自动化学报,2015,41(05):1024-1033.
[17] 许金喜,张新有. Android平台基于MQTT协议的推送机制[J]. 计算机系统应用,2015,24(01):185-190.
[18] 王山海,景新幸. 基于深度学习神经网络的孤立词语音识别的研究[J]. 计算机应用研究,2015,32(08):2289-2291.
[19] 张晴晴,刘勇红. 基于卷积神经网络的连续语音识别[J]. 工程科学学报,2015,37(09):1212-1217.
[20] 田莎莎,唐菀,佘纬. 改进MFCC参数在非特定人语音识别中的研究[J]. 科技通报,2013,29(03):139-142.
[21] 白静,楊利红,张雪英. 一种面向语音识别的抗噪SVM参数优化方法[J]. 中南大学学报(自然科学版),2013,44(02):604-611.
