校正生存曲线在SPSS、Stata及R中的实现与方法比较*
2020-06-28徐泽锋董文革王俊峰
刘 爽 徐泽锋 董文革 崔 壮 王俊峰
【提 要】 目的 比较校正生存曲线图在SPSS、Stata和R软件中实现方法的异同,指导临床医师实现校正生存曲线图的绘制与解释。方法 利用欧洲血液和骨髓移植学会注册数据,展示SPSS、Stata和R统计软件实现校正生存曲线的操作过程和结果,详细解析不同统计软件采用的校正方法。结果 SPSS、Stata所提供的校正生存曲线绘制方法默认为均值法,R软件提供的逆概率加权法对生存曲线有更好的校正作用。结论 不同统计软件在实现生存曲线校正时采用了不同的方法,研究者需要知悉这些方法差异,建议选用R软件中提供的逆概率加权法,可以得到更为合理的校正后生存曲线。
绘制生存曲线是生存分析中最基础的方法,通过将研究对象分组绘制生存曲线,可以比较生存概率在组间的差异。但是在非随机对照试验设计的情况下,生存概率可能受到在各组间分布不均衡的其他协变量的影响。随着分子诊断和靶向治疗的发展,以血液肿瘤为典型的恶性肿瘤不同个体在病理及临床方面呈高度异质性,患者对治疗的反应及预后也相差很大。原始的、未经校正的生存曲线图与Cox比例风险回归模型的相对风险结论有较大差异。近年来,校正后的生存曲线因其可以直观展示比较结果和各组生存概率,越来越受到研究者们的重视。
很多学者提出了校正生存曲线的方法,或对现有的校正生存曲线方法进行了归纳和比较[1-4]。如谷鸿秋等介绍了6种校正生存曲线的方法,并比较了这些方法的优势和局限[4]。然而,大部分临床研究人员尚未掌握校正生存曲线的绘制,或在实施统计方法进行数据分析时,仅依赖于统计软件提供的功能,在研究中采用哪种方法进行生存曲线的校正,很大程度上取决于研究者常用的统计软件中提供哪种方法。但是,不同的统计软件,在进行校正生存曲线的时候,所用的方法并不相同。本文的目的就是理清常用软件(SPSS,Stata,R)中提供的生存曲线校正方法,详细描述各软件操作过程,并展示不同调整方法得到结果的差异,供临床研究者掌握校正生存曲线的绘制与解释。
资料与方法
本研究演示数据来自欧洲骨髓和血液移植学会(EBMT)开源数据,由R软件中mstate包中加载获取,数据具体信息可见文献[5-6],本研究使用的是数据名为ebmt2的数据。该数据中共有8966例接受骨髓移植的患者,时间起点为患者接受移植的时间,事件定义为患者死亡,最长观察时间设置为60个月。我们选取预处理是否清除T细胞(tcd)作为本次研究关注的分组变量,选取患者年龄、移植年份、供体受体性别匹配作为需要校正的协变量。在排除分组变量缺失的患者后,共有6110例患者纳入最终分析,患者基本信息见表1。该数据仅供演示目的,不代表任何真实情况,也不应由此数据得出任何临床结论。

表1 患者基本信息表
tcd:预处理是否清除T细胞
实例与程序
1.SPSS软件中提供的方法
SPSS作为简单易用的统计分析软件,常为临床研究者的首选。SPSS中提供的校正生存曲线方法是协变量均值替代法,也可以输入具体数值替代均值。这种方法首先建立一个Cox模型,然后将需要调整的协变量的均值带入Cox模型中,得到不同研究组的生存曲线。根据在Cox模型中如何处理研究变量(作为协变量或者作为分层变量),又可细分为两种方法。
(1)研究变量作为协变量
此方法将研究变量与其他协变量一起,作为协变量建立Cox模型。在SPSS(版本25)中的实现的方法如下:
Analyze→Survival→Cox Regression
Time框:t_60
Status框:s_60,Define Event选项Single value=1,Continue
Covariates框:dissub、match、tcd、year、age
Plots选项:勾选Survival,Separate Lines for框填入tcd,Continue
OK
也可通过下列语句实现:
COXREG t_60
/STATUS=s_60(1)
/PATTERN BY tcd
/CONTRAST (age)=Indicator
/CONTRAST (year)=Indicator
/CONTRAST (tcd)=Indicator
/CONTRAST (match)=Indicator
/METHOD=ENTER year match age tcd
/PLOT SURVIVAL
/CRITERIA=PIN(.05) POUT(.10) ITERATE(20).
根据此方法生成的校正后生存曲线见图1B。
如果不想用均值,而是给定的值,只需要在PATTERN命令中加入variable(value)即可,比如固定年龄组为1(≤20岁),在/PATTERN与BY tcd之间加入age(1)即可实现。
(2)研究变量作为分层变量
将研究变量作为协变量建立Cox模型,需要研究变量也满足比例风险假设,所以被认为是所有校正方法中最差的方法。可将研究变量作为分层变量建立Cox模型,此方法在SPSS中也很容易实现,只需要将研究变量填入Cox模型中的Strata项即可。或运行下列语句:
COXREG t_60
/STATUS=s_60(1)
/STRATA=tcd
/CONTRAST (age)=Indicator
/CONTRAST (year)=Indicator
/CONTRAST (match)=Indicator
/METHOD=ENTER year match age
/PLOT SURVIVAL
/CRITERIA=PIN(.05) POUT(.10) ITERATE(20).
根据此方法生成的校正后生存曲线见图1C。
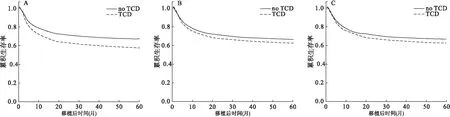
A原始生存曲线;B研究变量作为协变量;C研究变量作为分层变量
2.Stata中提供的方法
与SPSS类似,Stata(版本15)中校正生存曲线方法也是协变量均值替代法,但是在如何处理研究变量上略有不同,也可细分为两种方法。
(1)根据研究变量分亚组
Stata中校正生存曲线是通过sts graph命令中的adjustfor选项来实现的[7],具体方法如下:
stset t_60,failure(s_60==1)
sts graph,by(tcd) adjustfor(year match age)
这种方法类似于SPSS中将研究变量作为协变量的方法,但是不是拟合一个Cox模型,而是根据研究变量的分类,将数据分为N个亚组(N=研究变量分类数),在每个亚组中分别拟合一个Cox模型[7]。在每一个亚组模型中,协变量的系数可以不同。根据此方法生成的校正后生存曲线见图2A。
需要注意的是,Stata中协变量并不是取均值,而是取值为0。对于连续型协变量,如果想要根据具体参考值进行校正,需要提前生成一个新的协变量generate var_new=var_old - reference_value,这里reference_value为参考值。
(2)研究变量作为分层变量
将Stata中根据研究变量分五组进行校正生存曲线的程序中的by()命令改为strata()命令,就可以将研究变量作为分层变量,拟合1个Cox模型,协变量在每个分层中的系数相同,但是每个分层有不同的基础风险函数。根据此方法生成的校正后生存曲线见图2B。
stset t_60,failure(s_60==1)
sts graph,strata (tcd) adjustfor(year match age)
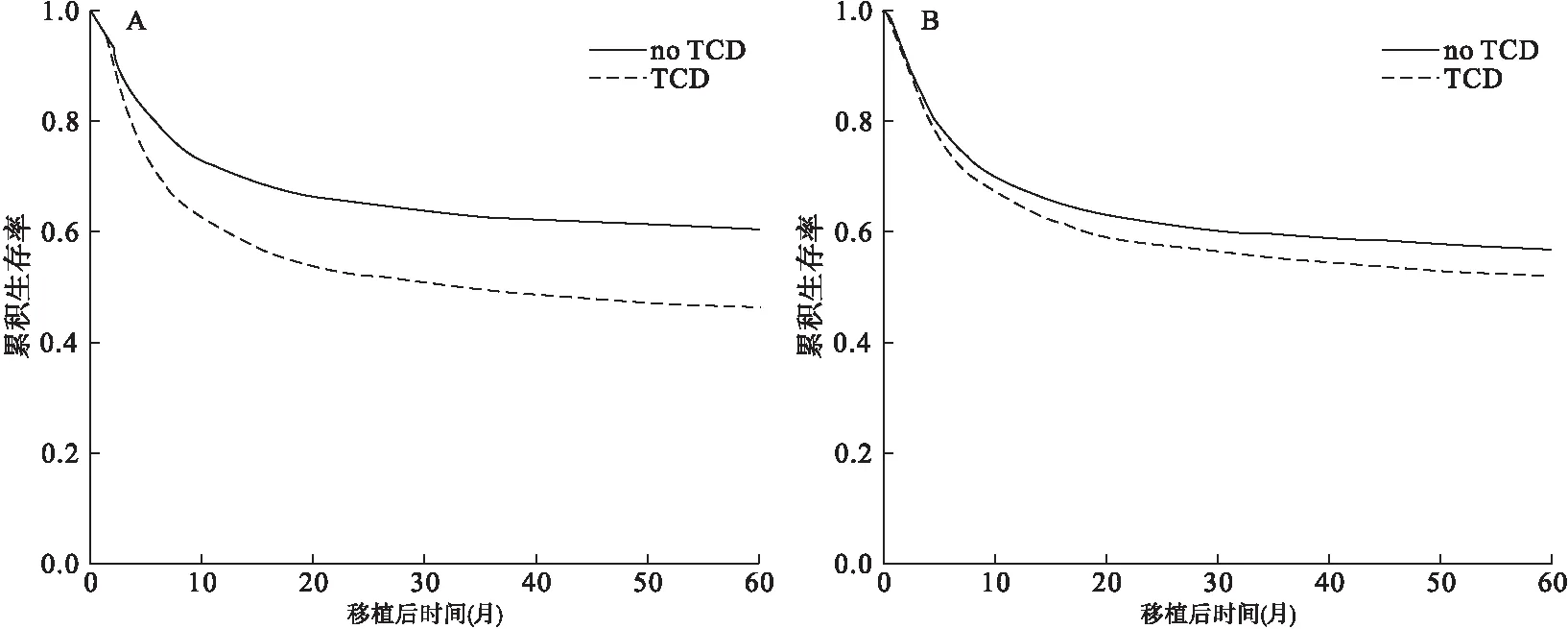
A根据研究变量分亚组;B研究变量作为分层变量
3.R软件中提供的方法
R软件由于其强大的功能和扩展能力,备受统计研究者的推崇。R软件的统计分析主要是基于功能包(package)来实现的,所以R软件进行生存曲线校正的方法,将按照不同的功能包来介绍。
(1)survival包中survfit命令
与前面所介绍的其他软件相同,在R软件最常用的survival包的survfit命令,也提供了协变量均值替代法进行生存曲线校正。在利用coxph命令建立Cox模型之后,只需在survfit命令中newdata选项给出新的输入数据,就可以得到协变量均值替代法校正后的生存曲线。
(2)survminer包中ggadjustedcurves命令
在R软件的survminer包中,提供了更多对生存曲线进行校正的方法[8]。在早期的survminer包中,这个命令叫做ggcoxadjustedcurves,从0.4.1版本以后,旧的命令被ggadjustedcurves命令取代,并且加入了更多新的功能选项。survminer包中ggadjustedcurves命令主要是根据Therneau,Crowson和 Atkinson文章中讨论的生存曲线校正方法[9],在R软件中进行实施。在当前版本中(0.4.3),共提供了四种校正方法:单一曲线方法(single),平均方法(average),条件方法(conditional)和边际方法(marginal)。需要特别注意的是,由于survminer包的开发者的失误,在ggadjustedcurves命令中条件方法和边际方法的调用被互换了,与Therneau原文中的定义刚好相反。本文作者已经与survminer开发者取得联系,并得到确认,这一现象确实是开发过程中发生的错误,将在之后的版本中进行更正。所以当使用ggadjustedcurves命令时,请注意版本号和解释文档,以免误用。本文为保持与Therneau文章的一致性,将以该文中的方法名称为准。
单一曲线方法仅绘制一条生存曲线,无法比较研究变量的各个分组,平均方法与前文中的均值替代法相同,所以这里只着重介绍条件方法和边际方法。
①条件方法
ggadjustedcurves中所谓的条件方法,来源于Therneau的文章,代表先计算每个研究对象的生存曲线,然后计算每组平均生存概率,并不是谷鸿秋文章提到的条件概率校正法。
mod1<-coxph(Surv(t_60,s_60>0) ~tcd+year+match+age,data=data)
ggadjustedcurves(mod1,data=data,method=″conditional″,variable=″tcd″,ylab=′Survival probability′,xlab=′Months′,size=1.5)
由于前文中提到的功能包的开发者的错误,这里如果想要调用条件方法,在当前版本中,应该选择method=”marginal”。用条件方法进行生存曲线校正的结果见图3A。
②边际方法
ggadjustedcurves中的边际方法,应用逆概率加权方法平衡研究变量各组研究对象的分布。
mod1<-coxph(Surv(t_60,s_60>0)~tcd+year +match+age ,data=data)
ggadjustedcurves(mod1,data=data,method=″marginal″,variable=″tcd″,ylab=′Survival probability′,xlab=′Months′,size=1.5)
同样,由于前文中提到的功能包的开发者的错误,这里如果想要调用边际方法,在当前版本中,应该选择method=″conditional″。用边际方法进行生存曲线校正的结果见图3B。
(3)RISCA包中ipw.survival命令
R软件中的RISCA包(0.8.2)也提供了逆概率加权法进行生存曲线校正的功能,可以用ipw.survival命令绘制生存曲线[10],由于与4.2.2中的边际方法相同,这里就不做演示了。值得一提的是,在RISCA包中,除了校正生存曲线,开发者还提供了相应的校正log rank检验的命令ipw.log.rank,可以根据校正后的生存曲线用log rank检验比较生存曲线的差异。
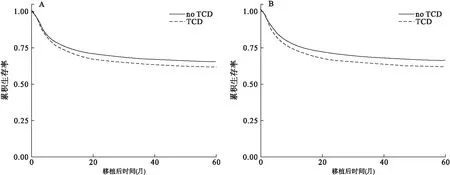
A 条件方法;B边际方法
结 论
从以上的展示和比较中,我们可以看到,不同的统计软件,在进行生存曲线校正时使用的方法并不相同。如果不加说明地使用校正生存曲线汇报研究结果,可能会产生误解。研究者在论文中使用校正生存曲线时,应报告使用的软件,以及具体的方法,以便于审稿人、编辑和读者更好地理解。如使用SPSS或Stata进行均值法校正生存曲线,应尽量避免使用均值,而是使用有实际意义的特定值。然而,均值法校正生存曲线由于方法本身的缺陷,并没有起到很好的校正作用[4],得到的校正后曲线的意义有限。所以在有条件的情况下,笔者建议选用 R软件中提供的逆概率加权法,可以得到更为合理的校正后生存曲线。本研究为绘制校正的生存曲线图提供了很好参考,可以解决我国相当一部分科研人员的实际问题。
