一种改进卷积神经网络的逆变器故障诊断
2020-06-28赵丹阳董唯光高锋阳
赵丹阳,董唯光,高锋阳
(兰州交通大学自动化与电气工程学院,兰州 730070)
目前我国电力机车、风力发电、电力网和工业设备的逆变器故障诊断研究大部分针对简单故障进行检测和定位,很大程度依赖于计划维修,使得检测效率低、难以实现实时检测[1-5]。因此,提出新的逆变器故障诊断方法对提高诊断准确率和效率具有十分重要的现实意义。
常用逆变器故障诊断方法为:基于小波变换[2,14]和压缩感知 CS(compressive sensing)[4,16]理论的故障特征提取,结合BP神经网络[2,15]和支持向量机SVM(support vector machine)[3,15]的故障分类诊断方法。 文献[2]针对双器件开路故障,采用小波变换提取特征,并以端电压主流分量、基波幅值、基波相位和二次谐波构成故障特征向量,作为BP神经网络分类器的输入,有效提高了逆变器故障诊断准确率。文献[3]利用相空间重构技术提取不同形状电流图像作为SVM训练样本,实现了故障元的准确定位。文献[4]分别将小波与SVM、CS与SVM、小波与BP神经网络、CS与BP神经网络结合用于电力机车逆变器故障诊断对比实验,结果表明:SVM故障分类明显、准确率高,不局限于诊断数据少的情况,但诊断较耗时;BP神经网络诊断迅速,但准确率不及SVM;2种特征提取方法中,CS更能应对高维“海量”信号的简化处理,但硬件实现困难[16]。
大数据背景时代,深度学习理论的成功应用成为人工智能技术得以实现的关键[6-12],在图像识别[11]、工业[12-15]、信息业[16]、故障检测等复杂问题中尤为突出。文献[13]王丽华等将SDAE应用到异步电机故障诊断中,较传统SVM检测方法,准确率提高了6%;文献[11]余永维等将CNN应用到射线图像缺陷识别中,较传统直接多类支持向量机DMSVM(direct multiclass support vector machine)检测方法,得到了更高的识别率和更强的自适应性;文献[12]杨望灿等将改进DBN模型应用到齿轮箱故障检测中,相比BP和SVM方法,实现了直接从原始震动信号提取深层特征,从而大大提高了故障诊断效率。究其原因,相较BP神经网络和SVM,深度学习网络有效克服了浅层网络表达能力不足、局限于少量低维数据的缺陷,同时可以实现实时智能分类,有效提高了图像识别准确率[13]。
针对三相二极管钳位式三电平逆变器主电路多复杂开路故障,以桥臂电压为电路检测信号[2-4],提出一种新的基于卷积神经网络的智能诊断方法。该方法根据损失函数梯度变化,自适应调节CNN正则化系数,以提高诊断准确率和模型实时智能检测水平,减少网络训练时间。
1 逆变器拓扑结构分析和故障分类
图1是由3个单相半桥式三电平逆变器组合而成的三相二极管钳位式三电平逆变器拓扑结构电路[2-7]。为方便研究,定义桥臂中点a与中性点o(即电容电压中点)之间电压为中桥臂电压,下文称桥臂电压;上桥臂中点au与o之间电压为上桥臂电压;下桥臂中点ad与o之间电压为下桥臂电压[2,4]。
三相二极管钳位式三电平逆变器主电路主要故障为12个功率开关管IGBT的开路故障。根据IGBT的数量和位置,三电平逆变器故障类型有:单管开路,如 Sa1、Sa4、Sb2、Sc3,共=12种;双管开路,如 Sa1Sa2、Sb1Sb4、Sa1Sb1、Sa3Sc3、Sb2Sc4, 共=66种;同理,三管开路共=220种[2-9];四管及以上开路概率极小,忽略不计;将逆变器正常运行状态也视为1种特殊故障。三管及以下共299种开路故障是目前逆变器主要研究的故障状态,部分故障类型如表1所示。
输入直流电压400 V、负载功率50 kW,图2~4分别为无故障及3种单管开路典型故障、双管开路典型故障和三管开路典型故障的A相输出电压(线电压)仿真波形。

表1 故障分类Tab.1 Fault classification
2 基于自适应正则化系数的卷积神经网络故障诊断方法
深度学习模型主要有深度置信网络DBN(deep belief network)、卷积神经网络CNN(convolutional neural network)、堆叠自编码 SAE(stacked auto-encoder)网络和循环神经网络 RNN(recurrent neural network)。DBN是一种通过逐层贪婪学习算法直接对低层信号得到高层特征信息的模型,具有灵活易拓展的结构特性,主要应用于图像处理和语音识别领域,完成特征提取和故障分类任务;SAE是一种通过级联多个自动编码器AE(auto-encoder)完成低维输入数据的降噪滤波、特征提取和故障分类任务的模型,与DBN同样采用无监督训练和BP神经网络微调,但SAE训练只需少量样本即可获得较高故障分类效果,多用于语音识别;RNN是动态性记忆网络,可充分利用样本间的关联性使状态数据循环传递在网络中,提高故障诊断准确性,适用于动态时序和有关联性数据,但不宜单独引用;CNN与DBN模型在图片识别和故障诊断领域均可实现自适应故障特征提取和智能分类,对高维和非线性数据具有强大的处理分析能力,CNN更是在保持一定降噪滤波效果的同时保证特征提取不变性[5-11],因此在大数据背景的故障诊断领域广为应用。卷积神经网络是卷积操作和反向传播算法相结合的产物,是完成卷积核参数自学习训练的程序化操作,主要特点是充分利用图片相邻区域信息,通过局部感知域、稀疏连接和共享权值的方式大大减少参数矩阵规模,从而减少计算量,提高收敛速度,避免算法过拟合[5,10]。
2.1 卷积神经网络基本结构
典型卷积神经网络LeNet-5结构如图5所示,最左侧为输入层Input,接着为卷积层C、池化层S和全连接层F,最右侧为输出层Output[5-9]。
输入层通常是数据图或特征图的原始像素四维矩阵,由批量大小、图片宽度、高和彩色通道构成。
卷积层是CNN的核心层。通过不同卷积核对上层特征图进行不同特征提取,利用激励函数构建输出特征图,每一层输出都是对多输入特征的卷积操作[13]。数学模型可表示为
式中:Hi为网络第i层特征向量图,当i=1时,Hi代表CNN输入层;Wi为第i层卷积核权值向量;卷积运算符⊗完成卷积核与第i-1层特征图的卷积运算,添加一定偏移量bi,再通过激励函数f(x)构建出第i层输出特征图Hi。目前,为避免梯度爆炸和梯度消失、加快收敛速度,激励函数常采用不饱和非线性的 ReLU 函数[17]:f(x)=max(0,x),其输出值小于0则为0,否则保持原值,这是对原始数据进行强制稀疏化的简单方法[9,10]。
为完成二次特征提取和降维操作,池化层须交替设置在卷积层两侧。常用池化方法有:最大值池化、均值池化和随机池化,随机池化由于其随机性可避免大量关键信息遗失,同时降低网络过拟合,成为目前最常用的池化方式。若Hi为池化层,则
式中:βi为网络乘性偏置矩阵;down()为池化函数。
经多个交替相连的卷积层和池化层完成特征提取后,为方便准确分类,分类器和最后1层池化层之间会增加1个或多个全连接层来整合所有提取的低维特征中具有目标类型区分性的局部信息,输入目标分类层进行故障分类,通常采用softmax分类器[11-13]。数学模型可表示为
式中,ω0为权值矩阵。
2.2 正则化系数自适应调整
LeNet-5结构在手写数字识别领域的巨大成功,使其成为当前普遍采用CNN结构的原型,但严重的过拟合问题一直影响其应用前景[10-12]。所谓过拟合是指测试集准确率远低于训练集准确率的差异表现[12]。通常是由于模型参数或结构过于复杂,过分拟合了数据的噪声和离群值,从而影响了目标识别准确率和模型收敛速度。对此,Krizhevsky等提出的包含5层卷积神经网络的Al-exNet结构[5],以及VGG、NIN、VGGNet、GoogLeNet、ResNets 等 一 些 新型结构都一定程度缓解了过拟合,但并不彻底,且复杂的结构在模型建立上增加了新的困难。目前,除增加样本量外,还可通过以下方式间接改变CNN内部结构进行去拟合:Dropout,通过随机隐藏每轮训练的部分节点来削弱节点间的联合适应性,使权值更新不再依赖有固定关系的隐含节点的共同作用,从而增强网络泛化能力;随机池化;正则化,通过损失函数添加正则化项来自动削弱不重要的特征变量,降低模型复杂度,获得更简洁抽象的特征表示,此过程常采用带l2正则化项的损失函数实现,数学模型可表示为
式中:C0为原始目标损失函数,通常选为均差函数,用来描述网络训练过程中样本损失情况;后半部分为带l2正则化项;n为样本量;λ为正则化系数,λ越大,正则化作用越明显,过程是所有权重系数平方和开方,所以在每次迭代过程中都会使权重系数在满足最小化C0的基础上逐渐趋于0,最终得到权重系数很小的矩阵模型,达到去拟合作用。
神经网络训练的目的就是将目标损失函数值C0降低至趋于0的最小值,以达到接近100%的识别准确率。传统CNN模型先用均方误差损失函数训练完整个模型后,再尝试加入正则化项进行全局去拟合,直到损失函数值不断减小至0,此时模型预测或分类准确率将达100%,说明模型过拟合完全被消除。但实际操作中效果并不理想,因为此过程采用全局统一的常数型参数进行优化,势必造成部分关键特征遗失和非关键特征冗余,并且λ的选取需依靠大量单一先验经验且不断试错,泛化性不强。由式(4)可看出,正则化系数λ大小的选择体现了给出的接近最优解的可信度:若λ取很小的正整数,正则化项将不起任何作用,说明所求解有很大的不确定性,甚至不可信;若λ取值很大,一旦越过接近最优解,就会使原本持续下降的损失函数值反升,使网络重新陷入过拟合。
因此本研究提出了引入自适应正则化系数的CNN 模型 Are-CNN(adaptive regularization CNN):在每轮样本训练后均添加正则化,正则化系数λ的调整根据随机梯度下降法中当前迭代目标损失函数的梯度值自适应更新。当目标损失函数下降的梯度值较大时,说明当前网络训练状态较好,拟合程度低,此时要求正则化作用小;当下降的梯度值逐渐减小时,网络学习的特征逐渐复杂,此时要求正则化作用大。这相当于给正则化添加了约束关系,继而使带l2正则化项的损失函数值更灵活、快速、稳定的趋于0。本研究设计的自适应正则化系数的调整策略为
式中:λi+1为第i+1次迭代时刻的正则化系数;K为初始常量,用来保证系数非负且有界;为 i次迭代时刻损失函数梯度值。
由式(5)可知,损失函数梯度值与正则化系数变化值呈反比,为保证该策略的有效性,应设置较大的正则化系数初始值,本研究选择λ0=100。在迭代初期,较大的正则化系数使目标损失函数值快速下降;随着迭代次数增加,损失函数值下降变缓,这将引起正则化系数反向增大,正则化作用增强,继而加速目标损失函数值的下降,最终正则化系数逐渐减小并趋于最小值。可见,随着迭代进行,正则化系数的自适应变化最终体现在样本训练损失值的变化快慢和稳定值大小上,继而影响网络的收敛速度和诊断准确率。
3 实验验证
针对新型无接触网轨道列车中常用的二极管钳位式三电平逆变器[15]三管及以下299种开路故障, 输入电压分别设为 400 V、450 V、500 V、550 V、600 V、650 V、700 V, 负载功率分别设为50 kW、52 kW、55 kW、57 kW、60 kW、65 kW,通过上述方式获得3 000组原始样本[2],随机选取样本总量的80%,即2 400组样本作为训练集,剩余600组样本作为测试集。当输入电压分别为500 V、600 V,负载功率分别为65 kW、50 kW时,采集到的Sa1开路故障波形如图6所示。
得到预计数量的样本后,再将其进行聚类划分,故障标签 1 位(如 0、1、2、3、C 等)划为一类,故障标签 2 位(如 12、13、14、23、A4、BC 等)划为一类,依次类推。
为验证Are-CNN模型的有效性,先设计传统CNN模型和文献[2]采用的小波变换与BP(反馈调节)网络结合的对比实验,建立CNN模型的软件工具为tensorflow1.2.1,Windows7,GPU计算方式。据文献[2]的方法,将原始数据样本经小波变换所得的故障特征向量作为BP神经网络输入;隐含层选用2层,第1层神经元个数为 400,第 2层为200,各层激活函数采用ReLU函数[13]。传统CNN模型搭建中,根据采样频率,每组样本采样点为1 000,故输入层神经元个数设为1 000;根据逆变器研究的故障类型数,将Softmax输出层的神经元个数设为299;每层卷积核个数均设为32,卷积核大小采用3×3、5×5;池化方式为随机池化;超参数学习率 η 设为0.001;连接权重初始值ω0设为0.01;算法采用随机梯度下降算法;各层激励函数均采用不饱和非线性ReLU函数;正则化系数的设置采用二分法,即按 100、50、25(75)、…方式手动尝试。 网络深度通常根据待测目标特征的复杂度、样本大小、卷积核大小及数量、池化方式、激活函数、算法等因素自行设置,图7为随网络层级加深,训练集准确率变化情况。结果表明:样本识别准确率随网络层级的加深而逐渐提高,这说明CNN模型可通过增加网络层级来挖掘更深层次的逆变器周期性故障波形特征;但这种深层挖掘效果并不会无限增强,当层级加深至16~34范围内时,故障诊断准确率保持在90%以上,之后便大幅下降;深度为24时效果最佳,包括输入、输出层、10层卷积层、10层池化层和2层全连接层,其中10层卷积层的前5层采用5×5卷积核,其余采用3×3卷积核。
在CNN和小波与BP结合的2种模型对比实验中,训练和测试集的准确率及训练时间情况如表2所示。
由表2可见,CNN模型较传统的小波与BP神经网络结合的故障诊断方法具有更优的诊断精度和效率。在实验过程中,CNN模型避免了人工学习特征和手动选取典型特征量的过程,从根本上实现了自适应、智能化的特征提取和故障识别,大大提高了故障诊断准确率,缩短了模型训练时间。同时,针对逆变器故障类型复杂的特点,CNN模型表现出这种传统故障识别方法不可比拟的深层挖掘能力和特征关联抽象能力,这对故障预测及实时诊断具有十分重要的意义。
为进行实验对比,Are-CNN模型的正则化系数初始值λ0也设为100,其他参数不变,λ按式(5)自适应更新。由于篇幅限制,表3仅列出后20次迭代过程中,λ随损失函数梯度值变化而自适应更新的情况。

表2 不同方法的诊断结果Tab.2 Diagnostic results of different methods

表3 正则化系数随梯度值自适应变换情况Tab.3 Adaptive transformation of regularization coefficient with gradient values
由表3可见,正则化系数随损失函数梯度变化而自适应更新,在迭代后期,目标损失函数梯度下降缓慢且不断出现不降反升的现象,导致诊断准确率处于较低水平,模型严重过拟合。第220次迭代后,损失函数梯度下降值为0.000 7%,几乎接近于0,此时诊断损失值保持在0.45%,意味着诊断准确率为99.55%,但正则化的加入使梯度下降值逐渐增加,损失函数值持续下降,从而加快了样本训练的收敛速度;第223次迭代后,损失函数值为0.486 6%,较前1次迭代损失函数值0.407 3%升高了0.079 3%,梯度值为-0.079 3%,损失函数不降反升,模型出现明显过拟合,此时根据梯度值自行调整的正则化系数为10.999 7,较前1次10.885 3有所增加,并且之后随着梯度下降值的变化持续增加,说明此时正则化作用逐渐增强;第224、225次迭代后,损失函数梯度值虽然仍在上升,但上升幅度逐渐减小;第226次迭代后,损失函数梯度值恢复为正向下降过程,拟合程度减小,训练状态恢复良好,此时正则化系数11.073 6,较上1轮的11.557 0减小了0.483 4,正则化作用相应减小但不为0,使得损失函数整体保持较快稳定下降状态,最终模型经240次迭代后准确率稳定在99.67%。由此,正则化系数随损失函数梯度值自适应调整的策略得到验证。
图8和表4列举了样本训练整体过程中,传统CNN和Are-CNN模型的训练集与测试集的诊断误差值随迭代次数变化而变化的对比情况。
由对比结果可知:2种模型的训练集损失值随迭代次数的增加而不断减小并逐渐趋于稳定;引入自适应正则化系数的Are-CNN模型的训练集损失值在迭代次数达60次后明显低于传统CNN模型;当迭代次数达到80次时,Are-CNN模型的训练集损失值为3.71%,训练时间为29.72 s,传统CNN模型训练集损失值为4.24%,训练时间为36.97 s,这说明目标损失函数在迭代过程中,根据当前梯度值自适应的调节正则化系数的变化趋势,使加在目标损失函数中的正则化项对网络的优化程度不断提高,最终表现在模型诊断准确率的稳定上升;当迭代次数达240次时,Are-CNN模型的训练集损失下降至稳定值0.33%,相比传统CNN模型在迭代次数达300次时损失值才逐渐趋于稳定的0.86%,Are-CNN模型在收敛速度加快近1倍的基础上,故障诊断精度提高了0.53%,最终准确率达到99.67%。充分说明,这种每轮迭代均引入自适应正则化系数的方法有效特高了CNN模型的收敛速度和识别准确率。
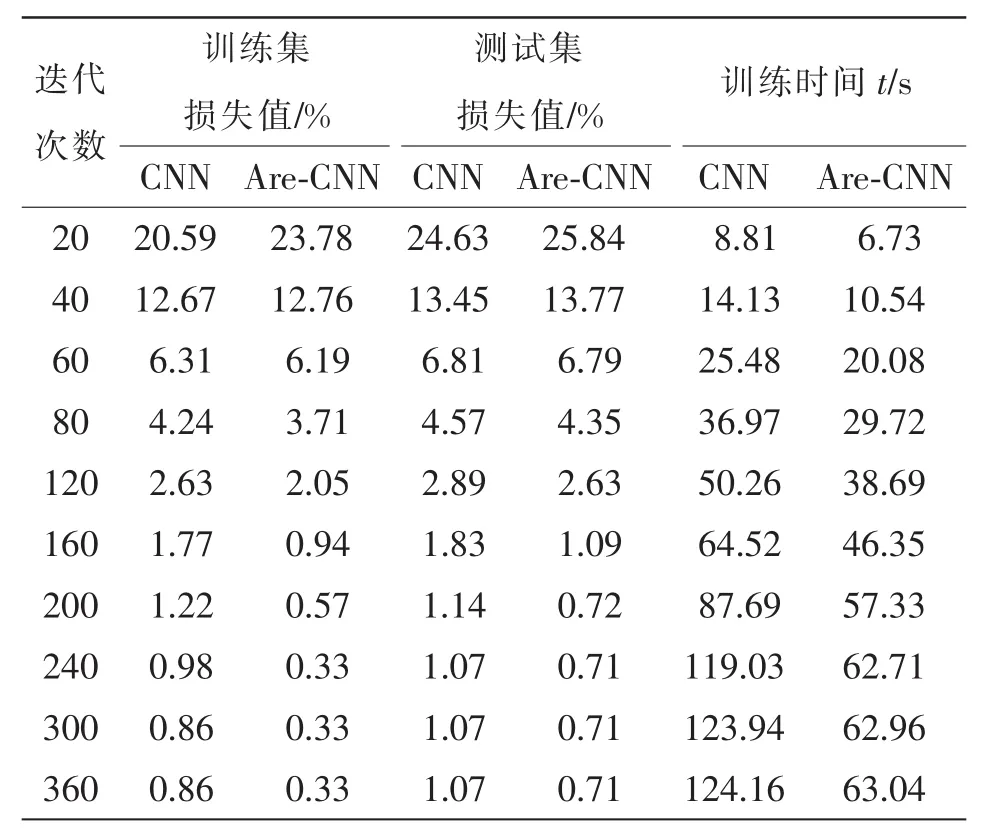
表4 不同方法下不同迭代次数的损失值Tab.4 Loss values with different iteration times when using different methods
4 结论
本文提出了一种引入自适应正则化系数的卷积神经网络逆变器故障诊断方法,利用CNN强大的特征提取能力和分类效果,实现无接触网供电轨道列车三电平逆变器复杂及多混合故障的智能化诊断。Are-CNN模型相比传统CNN和BP神经网络具有以下优势:
(1)层层去拟合优化,大大加快数据稳定表达,提高了CNN模型收敛速度。
(2)自适应正则化的方式,避免了人工优化和依靠单一先验经验取值的过程;不再采用全局统一参数的方式,大大增强了CNN网络泛化能力,从而提高分类准确率。
(3)实时智能检测的方法不仅缩短了模型训练时间,还实现了故障位置准确定位。
但Are-CNN模型仍需大量数据样本训练网络,针对逆变器周期性故障波形如何利用较少数据样本获得高级特征表示有待进一步研究。
