农业大数据分类算法探讨与研究
2020-06-21邹承俊
李 敏,叶 煜,文 燕,陈 琳,邹承俊
(成都农业科技职业学院,成都 温江 611130)
民以食为天,食源于农业。我国幅员辽阔,是农业大国,传统农业在中华大地上养育了几千年的祖祖辈辈。古人常说,农业收成是靠天吃饭。而在当今信息技术爆炸及物联网技术的指数级发展下,农业也和其他产业一样,利用现代技术,由传统农业向着智慧农业发展。
农业生产活动过程中,产生大量的农业数据,俗称农业大数据。如农业种植、养殖、农产品加工处理、天气状况、市场行情以及通过自动化网络监控系统产生的监控数据等。对于这些海量的原始农业数据,看似杂乱却包含着巨大的价值,若能对这些数据进行有效的分析处理,在杂乱中寻求其规律,就能为农业预测及发展决策提供科学依据和参考。[1]
农业大数据挖掘是农业数据分析的最关键工作。大数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知识的过程。收集到的数据首先就要进行分类管理。所谓分类是找出数据中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到某个给定的类别中。农业大数据的挖掘中常用的分类算法有贝叶斯分类算法、K最近邻分类算法、决策树分类算法等,这些方法从不同的角度对数据进行挖掘。
1 朴素贝叶斯算法
1.1 算法介绍

1.2 农业数据举例应用
对历史发生的情况进行统计,估算出生病的鸡为母鸡或公鸡的概率。
第1步,构造一个历史发生的情况表,如表1:

表1 鸡生病情况
第2步,计算出每一个组成部分的概率,构造出频率表,如表2:

表2 生病频率
如果历史中没有出现的事件,即发生的概率为0的情况,导致整个结果也为0。但未来不一定不发生。可以利用拉普拉斯估计,给频率表中的每个计数加上一个较小的数,这样就可以保证每个特征发生概率非零。一般将0变成1,增加一个小的概率,让它的占比很小,将0的情况覆盖掉。而对整个结果影响不是很大。如上一个例子,历史数据中,公鸡没有生病,也就是公鸡生病的概率为0的情况,如表3:
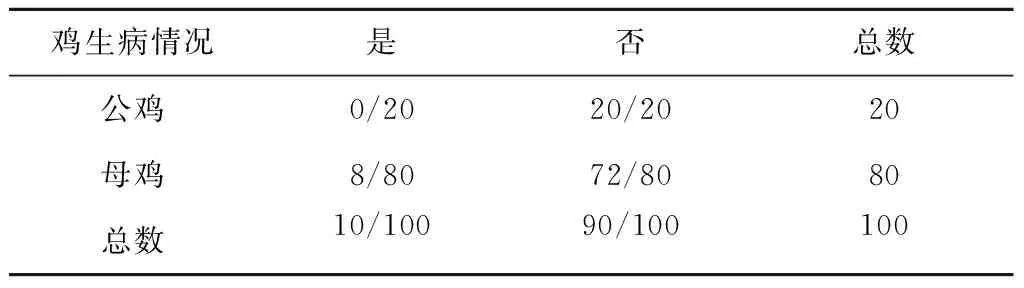
表3 生病频率有0的情况
改为增加公鸡数为4,如表4:

表4 修改生病频率
如果有多重特征,则p(B|A) = p(B0|A) ×p(B1|A)×p(B2|A)× .... ×p(Bn|A)。
2 K最近邻分类算法(KNN)
2.1 算法介绍
2.1.1 KNN(K-Nearest Neighbor)算法的思路 如果一个样本在特征空间中的K个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。
2.1.2 KNN三要素
(2)K的选择 指定一个K值(K值的选择一般低于样本数据的平方根,一般是K<=20的整数),按照距离依次排序,选取当前点距离最小的K个点,确定前K个点所在类别的出现概率。
(3)分类决策规则 根据少数服从多数的原则,返回前K个点出现频率最高的类别作为当前点预测分类。
2.1.3 KNN算法的缺点 当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。可以采用权值的方法。根据和该样本距离的远近,对近邻进行加权,距离越小的邻居权值越大,权重一般为距离平方的倒数。
2.2 案例
通过收集含玉米象小麦籽20g与正常小麦籽20g的发育过程中含虫数据,从种植的第3天开始,共测1个月。玉米象的发育过程如表5:

表5 玉米象的发育过程
通过小波降噪,特征的选择与优化后,计算均值、标准差、光子统计熵等特征参数得到数据库,从数据库中实验组和对照组中各取60%作为样本训练集,40%作为测试集,利用欧式距离,K取5,使用KNN及其加权的KNN,来检验分类的效果。通过比较,KNN的正确率为90%,加权KNN为92.5%,加权分类法的效果最好。[3]
3 决策树
3.1 算法介绍
决策树是通过对训练集的研究,挖掘有用的规则,用于对新集进行预测分类的一种算法。基本算法是贪心算法,自顶向下递归方式构造决策树。在其生成过程中,如何将属性进行度量分割尤为重要,直接影响到最终分类效果。
3.2 步骤
(1)开始时,所有的数据都在根节点,属性需要离散型字段值,如果是连续的,则将其离散化。
(2)用离散化的属性进行递归分裂所有记录,直到分裂停止。
决策树的分裂原则:数据的每一次分裂,尽可能让类别一样的数据在树的一边,当树的叶子节点的数据都是一类的时候,则停止分类,可以用if-else语句来实现。
(3)分类划分的优劣用不纯性度量来分析。将纯粹度用数据进行量化,度量信息混乱程度的指标:
类别越少,信息熵和基尼系数越低。
条件熵:在某个分类条件下某个类别的信息熵叫做条件熵,类似于条件概率,在知道Y的情况下,X的不确定性。条件熵一般使用H(x|y)表示,代表在Y条件下,X的信息熵。哪个条件熵相对信息熵下降的最快,就选择谁做为分类,用信息增益来表示条件变化的程度,分类前的信息熵减去分类后的信息熵。选择信息增益大的属性作为分类节点的方法叫ID3分类算法。例如特征Y对训练集D的信息增益为g(D,Y)=H(X)-H(X|Y)。 但这种方法会出现过拟合问题。所以用条件熵作为顶层分类有弊端。
信息增益率gr(D,Y)=g(D,Y)/ H(X):使用信息增益率来做为顶层分类将消除当某些属性比较混杂时,使用信息增益来选择分类条件的弊端,这种分类法也叫做C4.5。如果最后一个条件依然没能将数据准确进行分类,则在这个节点上就可以使用概率来决定。看哪种情况出现的多,就做为该节点的分类结果。
(4)用决策树来做预测值(回归),可以求一个平均值做为预测结果。
3.3 决策树的构建算法
主要有ID3、C4.5、CART三种,其中ID3是决策树最基本的构建算法,而C4.5和CART是在ID3的基础上进行优化的算法。常用的是C4.5。
3.4 决策树的优化
决策树如果太复杂,很可能出现过拟合,造成预测不准确的分类,因此需要对决策树进行优化,优化的方法主要有2种,一是用信息增益率(C4.5)来做。二是剪枝。
3.5 案例[4]
下表为某些地区第三季度雨水洪涝数据训练集样本属性,如表6。
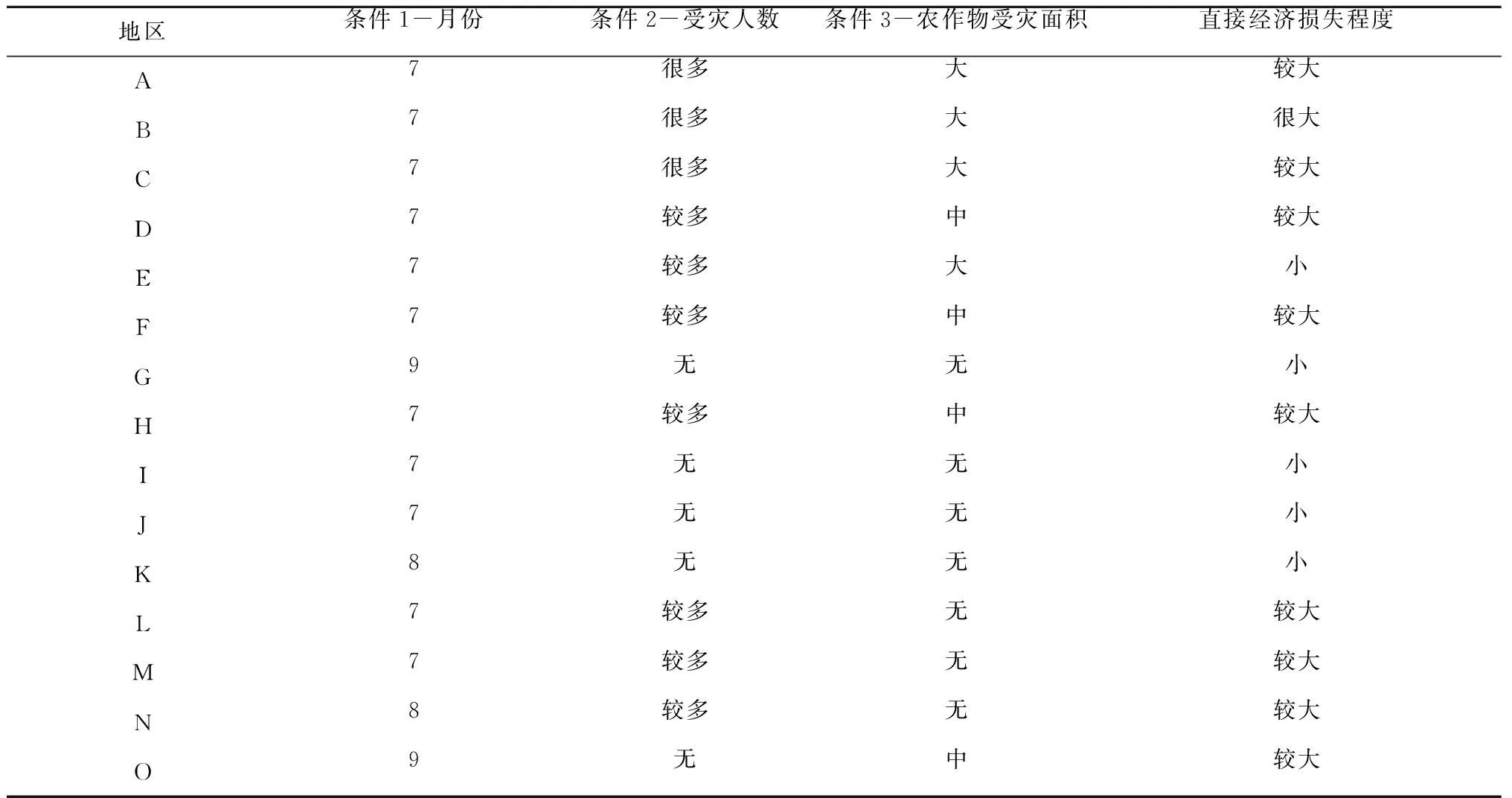
表6 雨水洪涝数据训练集样本属性
3.5.2 条件熵的计算
3.5.3 信息增益的计算
(1)以月份为前提条件的信息增益G1=H-H1=1.23096-1.04316=0.1878
(2)以受灾人数为前提条件的信息增益G2=H-H2=1.23096-0.70042=0.53054
(3)以农作物受灾面积为前提条件的信息增益G3=H-H3=1.23096-0.85977=0.37116
用ID3的算法,即用信息增益作为标准,通过对比,以受灾人数作为条件使原来的信息熵下降最快,则将它作为顶层划分。
3.5.4 信息增益率的计算
(1)以月份为前提条件的信息增益率Gr1=(H-H1)/H=(1.23096-1.04316)/1.23096=0.1526
(2)以受灾人数为前提条件的信息增益率Gr2=(H-H2)/H=(1.23096-0.70042)/1.23096=0.4310
(3)以农作物受灾面积为前提条件的信息增益率Gr3=(H-H3)/H=(1.23096-0.85977)/1.23096=0.3015用C4.5的算法,即用信息增益率作为标准,通过对比,以受灾人数作为顶层条件划分。
ID3和C4.5这2种算法均得出相同的结果,再进行规则剪枝,最后生成决策树,如图1。

算法名称收敛时间是否过度拟合是否过渡拟合缺失数据敏感度训练数据量朴素贝叶斯算法快存在不敏感无要求KNN快存在敏感数据量多决策树快存在不敏感小数据集
4 3种算法比较
在农业大数据中,根据实际情况选择不同的分类算法或多种算法相结合的方式,使数据分类更为准确。
