基于特征分析的职工离职预测
2020-06-21
(上海大学 悉尼工商学院,上海 200444)
1 引言
随着现代科技的不断发展,企业所处的环境在不断变化,企业本身也在不断变化。在现代竞争激烈的社会中,职工离职的现象越来越普遍。很多企业认为员工流失所造成的成本只包括离职成本和招聘成本,却忽视了职工离职引起的其他流动成本,比如重要客户的流失、商业机密的泄露、企业竞争力的下降等。在如此情况下,公司的人力资源部门应该如何减少职工的离职倾向,从而降低公司经营成本是极其具有现实意义的[1]。
国内外学者对于职工的离职现象开展了大量的研究工作[2-4],主要包括三大方向,即职工离职因素研究、降低职工离职率的措施研究和职工离职的预测研究。目前与本文研究方向类似的,即关于职工离职预测的研究,主要是基于机器学习的方法,着眼于模型算法的比较和探讨,忽视了对数据处理的研究。然而,目前一些比较成熟的机器学习模型算法,都对被处理的数据集合有一定要求,比如较好的完整性、较少的冗余性等。但现实海量数据中无意义的成分居多,严重影响了模型的性能和效果。因此,本文的重难点在于如何对原始数据提取并挖掘有效特征,突出数据预处理技巧对职工离职预测模型性能的影响,以弥补现有研究中对数据处理部分的忽视。
2 数据来源
本文数据来自于IBM Watson Analytics 分析平台分享的数据,共1 470 条记录,35 个字段信息。原始数据集描述的是影响员工流失的因素,对字段信息的详细说明如表1所示。
3 数据处理与分析
对各特征数据统计发现,数据存在高度倾斜和一些无用的唯独特征,还存在很多属性变量等。因此,在建模之前需要对数据进行处理[9]。
3.1 处理数据不可用
经过统计分析发现,数据集中存在两个常量特征,它们是Over18 和StandardHours。数据集中还存在一个无关特征,即EmployeeNumber。显而易见,他们对模型决策来说是无用的维度,为了模型计算更快,应删除这些变量。
3.2 特征处理
3.2.1 新特征构建
3.2.1.1 LM_Involved(是否为中低参与度)
通过对原数据中JobInvolvement 列的分析,发现工作参与度低的员工和工作参与度中等的员工的流失率相对较高。因此构建新特征LM_Involved,该特征属性值为0 和1。若员工的工作参与度为中或低,则该员工LM_Involved 特征取值为1,否则为0。
3.2.1.2 like_moving(是否热衷换公司)→Time_in_each_comp_level(每家公司工作年数)
通过生活经验猜测,有些员工频繁跳槽是为了在不断尝试的过程中寻求最适合自己的工作。基于此,构建了like_moving 新特征。以工作过4 家公司为阈值,若员工工作过的公司超过4 家,则该员工被定义为热衷换公司的人,该员工的like_moving 特征将被赋值为1,否则为0。
图1 为新特征like_moving 与员工流失率关系图。通过图1 柱状图高度分析得出,热衷换公司的员工流失率为0.21,非热衷换公司的员工流失率为0.14%。0 类与1 类在流失率中的差距不显著,猜想可能的原因是一些员工是由于自身工龄长导致在很多家公司工作过,并不是因他热衷换公司。因此提出特征Time_in_each_comp,该特征的计算公式为(员工年龄-20)/(工作过的公司+1),得到该员工在每个公司工作的平均年数,由此得到Time_in_each_comp。再对平均年数离散化,得到Time_in_each_comp_level。新特征Time_in_each_comp_level 的属性值为0、1、2。若平均年数小于3 年,则Time_in_each_comp_level 取值为0;若平均年数小于12 年,则取值为1;其余为2。

表1 数据集字段描述
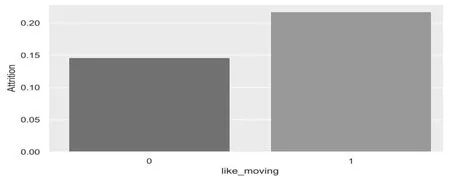
图1 like_moving 与流失率关系图
图2 为新特征Time_in_each_comp_level 与员工流失率关系图。
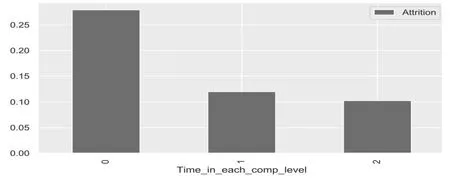
图2 Time_in_each_comp_level 与流失率关系图
从图2 柱状图高度看出,平均年数小于3 年的员工的离职率是剩余员工的2 倍,具有区分度。
3.2.1.3 Total_satisfication(总体满意度)&NotSatisfied(是否不满意)
观察原数据得出,满意度分为Environment Satisfaction、Relationship Satisfaction、Job Satisfaction,即环境满意度、关系满意度和工作满意度。而与员工满意度相关的因素还有WorkLifeBalance 和JobInvolvement。员工参与度过低说明该员工对工作没有热情,也是总体满意度的一方面。有时候某一方面的满意度低但总体满意度高并不会导致员工离职,因此计算总体满意度更为合适。Total_satisfication(总体满意度)计算公式为:

同时构建新特征Not Satisfied,该特征属性值为0 和1。若员工的平均满意度小于2.5,则该员工NotSatisfied 特征取值为1,否则为0。图3 为新特征NotSatisfied 与员工流失率关系图。

图3 NotSatisfied 与流失率关系图
从图3 看出,总体不满意的员工的流失率超过0.3,而总体满意的员工离流失不到0.15,差了2 倍之多。
3.2.1.4 LongDistance&ImBance(是否由工作距离导致的生活工作不平衡)
通过对原数据中DistanceFromHome 列的分析,发现距离的远近和员工流失率并没有明显关系。但根据生活经验,通过同时考虑DistanceFromHome 特征和WorkLifeBalance特征,来识别出那些因为工作距离导致家庭生活不能平衡的员工。新特征LongDistance&ImBance 的属性值为0 和1,若员工的 DistanceFromHome 特征大于 11 且员工WorkLifeBalance 特征为low,则该员工LongDistance&ImBance 特征值为1,否则为0。
图4 为新特征LongDistance&ImBance 与员工流失率关系图。

图4 LongDistance&ImBance 与流失率关系图
从图4 看出,由距离远导致工作生活无法平衡的员工的流失率是剩余员工的2 倍之多。
3.2.1.5 LongDistance_&_joblevel1(是否是工作距离远且职位级别低的人)
从对原数据的分析来看,单纯的职位级别特征和工作距离特征对于员工的流失没有特定关系。但根据生活经验,如果一个人的职位很高,那他会舍不得放弃摸爬滚打了几十年才得来的高职位,哪怕工作路途遥远。而当一个员工级别很低,他离职的机会成本也比较低。那他为何不找一份距离近的工作?因此,新特征LongDistance_&_joblevel1 的属性值为0 和1,若员工的DistanceFromHome 特征大于11 且员工joblevel 特征为1,则该员工LongDistance_&_joblevel1 特征值为1,否则为0。
图5 为新特征LongDistance_&_joblevel1 与员工流失率关系图。

图5 LongDistance_&_joblevel1 与流失率关系图
从图5 看出,职位级别低且工作距离远的员工的流失率是其余员工的2 倍之多。
3.2.1.6 LongDistance_&_Singl(e是否是工作距离远且单身的人)
通过对原数据中MaritalStatus 列的分析,发现在所有离职的员工中,单身的员工占了最大比例。因此,再根据生活经验,单身的人不用承担养家糊口的压力,他们的试错成本比较低。若他的工作单位距离较远,那他有充分理由去尝试一家离家近的公司,因此这类人的流失率比较高。新特征LongDistance_&_Single 的属性值为0 和1,若员工的DistanceFromHome 特征大于11 且员工MaritalStatus 特征为Single,则该员工LongDistance_&_Single 特征值为1,否则为0。
图6 为新特征LongDistance_&_Single 与员工流失率关系图。

图6 LongDistance_&_Single 与流失率关系图
从图6 看出,单身且工作距离远的的员工的流失率是其余员工的2 倍之多。
3.2.1.7 Young_&_Badpay(是否年轻且收入低)
根据经验,刚入职场的年轻人往往敢于尝试,且对收入的期望值很高。但由于刚刚开始工作,薪水无法一下子满足他们的期待,于是年轻员工就流失了,去寻求更令他们满意的发展。新特征Young_&_Badpay 的属性值为0 和1,若员工的Age 特征小于24 且员工MonthlyIncome 特征小于3 500,则该员工Young_&_Badpay 特征值为1,否则为0。
图7 为新特征Young_&_Badpay 与员工流失率关系图。
从图7 看出,年轻且收入低的员工的流失率大约在0.35,而其余员工流失率在0.1 左右,差距显著。

图7 Young_&_Badpay 与流失率关系图
3.2.1.8 MonthlyIncome_level(工资水平)
原始数据MonthlyIncome 列的数值众多,因此想到对MonthlyIncome 列离散化,构成新特征MonthlyIncome_level。新特征MonthlyIncome_level 的属性值为0、1 和2,若员工的MonthlyIncome 小于3 725(3 725 为第一四分位数),则该员工MonthlyIncome_level 特征值为0;若员工的MonthlyIncome 小于11 250(11 250 为第三四分位数),则该员工MonthlyIncome_level 特征值为1;其余为2。
图8 为新特征MonthlyIncome_level 与员工流失率关系图。

图8 MonthlyIncome_level 与流失率关系图
从图8 看出,处在低收入档的员工的流失率是其余员工的2 倍之多。
3.2.1.9 Income_Distance(收入的距离代价)
新特征Income_Distance 所代表的含义是,挣得一元钱所需要付出的上班距离代价,因为距离的远近可以看作另一种成本(包括交通成本、时间成本等)。
Income_Distance 的计算公式是(MonthlyIncome)/(DistanceFromHome),之后再对得到的值离散化。根据经验,(MonthlyIncome)/(DistanceFromHome)值越大,员工流失率越低。新特征Income_Distance_level 的属性值为0、1、2 和3,若员工的Income_Distance 小于420(420 为0.3分位数),则该员工Income_Distance_level 特征值为0;若员工的Income_Distance 小于1 200(1 200 为二分位数),则该员 工Income_Distance_level特征值为1 ;若员工的Income_Distance 小于2 700(2 700 为0.8 分位数),则该员工Income_Distance_level 特征值为2;其余为3。
3.2.1.10 Income_YearsComp(收入的时间代价)
同理,新特征Income_YearsComp 所代表的含义是,挣得一元钱所需要付出的工龄代价,因为时间成本也是重要的考量因素。Income_YearsComp 的计算公式是(MonthlyIncome)/(YearsAtCompany)。根据经验,(MonthlyIncome)/(YearsAtCompany)值越大,员工流失率越低。
3.2.1.11 Stability(稳固性)
根据经验,有些员工在公司的年数已经很长了,但是总是在岗位之中换来换去,因为该员工在大部分岗位都无法按要求完成工作,但公司却不能把他辞退,只能让他不停尝试新岗位,直到找到一个合适的岗位。而有些人在短时间内就找到了自己擅长的岗位,并长期做了下去。显然,后者的流失率会更低。因此,新特征 Stability 的公式为YearsInCurrentRole/YearsAtCompany。
3.2.1.12 Fidelity(忠诚性)
新特征 Fidelity 公式为 NumCompaniesWorked/TotalWorkingYears。该值越小,代表该员工越忠诚,流失的概率也越小。
3.2.1.13 Has_stock(是否持股)
根据经验,有些公司为了激励员工,会赠送股权,这是一种将员工利益与公司利益捆绑的手段。原数据中StockOptionLevel 代表持股等级,但笔者认为是否持股才是决定员工流失的关键因素,不论持股的数量是多少。因此,构建新特征Has_stock,该新特征的属性值为0 和1,0 代表员工没有股权,1 代表员工有股权。
图9 为新特征Has_stock 与员工流失率关系图。

图9 Has_stock 与流失率关系图
从图9 看出,未持有股份的员工的流失率是持有股份员工的2 倍之多。
3.2.1.14 cluster_result(聚类结果)
最后根据 KMeans 聚类结果增加了新特征cluster_result[5]。KMeans 中k取值(即聚类数)的设定是通过循环的方式得到。当k=2 时,聚类模型的轮廓系数最高。因此,将该聚类标签作为新特征。
3.2.2 特征相关性分析及筛选
原始数据的特征有31 个,除去3 个无用特征之后,又经过挖掘加入的新特征有15 个。表2 是部分特征与标签列Attrition 的相关性排序(罗列前十位和后五位)。从中看出,新增加的特征 Young_&_Badpay、Fidelity、MonthlyIncome_level、Has_stock、Total_satisfication、NotSatisfied、Time_in_each_comp_level等都与标签列Attrition 密切相关,因此新特征的挖掘是有效的。
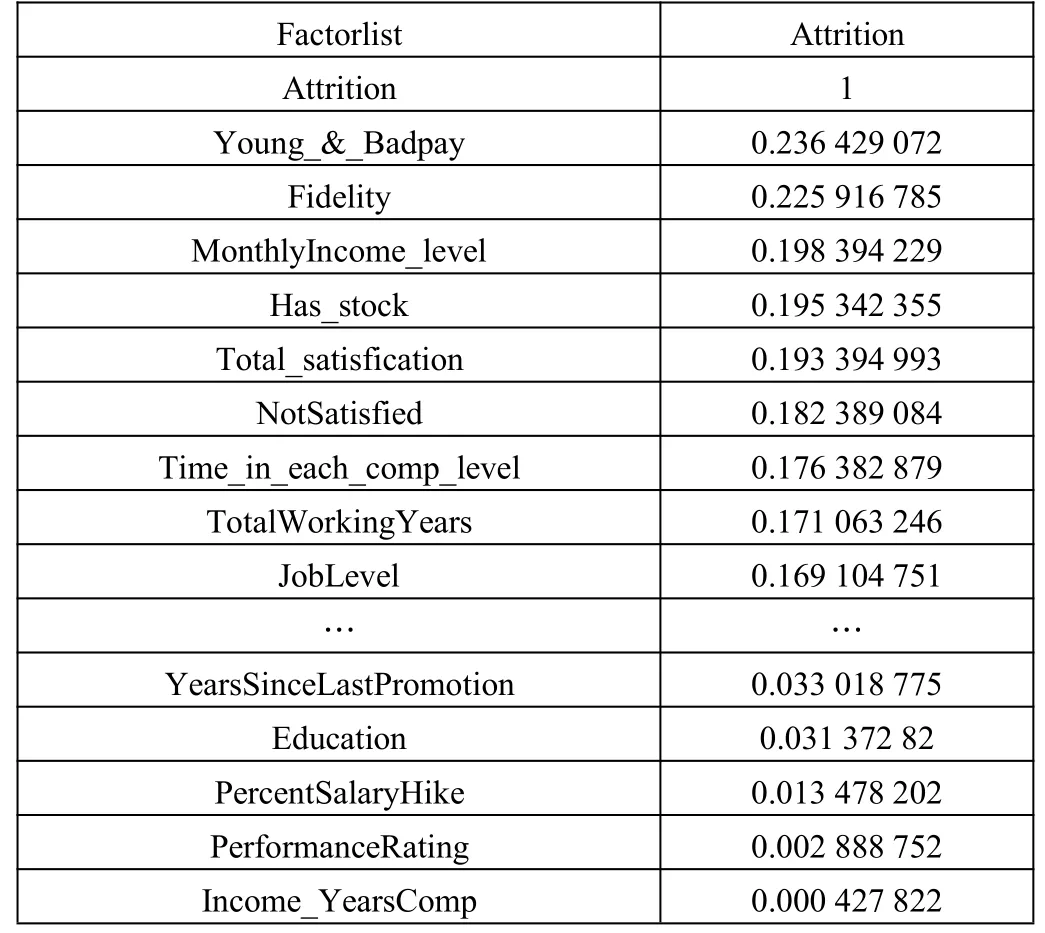
表2 部分特征与标签列Attrition 的相关性排序(前十位和后五位)
根据表2 删除一些排名倒数,对标签列贡献度小的特征,删除标准是该特征与标签列Attrition 的相关性小于0.05(即 Income_YearsComp、PerformanceRating、PercentSalaryHike、Education、YearsSinceLastPromotion、NumCompaniesWorked、RelationshipSatisfaction)。
3.3 独热编码处理
基于此,本文对经上述处理后的数据采用get_dummies方法对离散型数据进行独热编码,如Gender、JobRole 等。采用one-hot 编码后,一方面可以使样本之间能够直接进行距离的计算,另一方面能够扩充样本特征的数目。
3.4 归一化处理
为消除数据中各指标之间的量纲和取值范围差异的影响,采用归一化对Age、MonthlyIncome、Stability、Fidelity、DistanceFromHome 等特征进行线性变换,将数值映射到[0,1]区间。
3.5 样本倾斜处理
样本不平衡是指数据集中各个类别分布不平衡,某一类别的样本个数远少于其他类别。绝大多数机器学习方法对不平衡的数据集都没有很好的预测效果。在本文的数据集中,流失样本237 个,占总样本的16.1%,未流失的样本为1 233个,占总样本的83.9%。流失的个数远小于未流失的个数,因此在建立模型之前,需要对数据进行样本不平衡处理。
一般处理数据不平衡的方法有上采样、下采样。由于本文的数据集相对较小,因此采用上采样的方法处理数据不平衡。表3 为针对同一处理后的数据,在决策树模型下,通过不同采样方式得到的准确率、精确率、召回率和F1 值。可以看出,随机上采样法对本文数据集处理效果最优。

表3 不同采样方式的比较
4 分类算法的比较及分析
在开始训练模型之前,把数据集划分为训练集和测试集,用来检验模型的泛化能力。本文选取80%的数据作为训练集,20%的数据作为测试集。基于决策树、支持向量机、随机森林和LightGBM 算法,分别在训练集进行模型训练,后在测试集上进行结果预测。
4.1 模型结果对比及分析
表4 是将平衡之后的样本代入机器学习模型中训练的结果。其中用到的模型有决策树、支持向量机、随机森林和LightGBM。

表4 模型结果对比分析
整体而言,虽然集成模型以花费更多时间为代价,但其预测性能较单模型而言更优[6]。就集成模型比较来看,LGBM总体预测效果最好,在测试集上达到97%的准确率。除此以外,还尝试基于集成学习的stacking 方式构建以LGBM 和SVC 为基学习器,逻辑回归为二层学习器的LSL(LGBM-SVC-Logistic)模型。从训练结果看,LSL(LGBM-SVC-Logistic)模型在准确率、精确率、召回率和F1 值上的表现仅与单个LGBM 模型相持平。因此考虑到集成学习stacking 的时间成本,且未带来更优的模型表现,遂放弃stacking 集成算法。
4.2 特征重要性
对LGBM 模型预测结果进一步分析,将输入模型的特征进行重要性排序,得到与员工流失倾向相关的主要因素。最具影响力的流失因素重要性排序如图10 所示,影响流失的主要因素为月收入、收入的距离代价、在每个公司工作年数、年龄、总体满意度等。在这最重要的10 个因素中,本文所构建的新特征排在第二、三、五、七、八位,以此可以推断新构建的特征是有效的。而对于企业决策者来说,可以根据这些重要的影响因素制订相关的政策,如:①制订合理的薪酬制度,提高员工相应的收入,激发员工的工作积极性,以保证为企业发展贡献力量[7];②对于一些距离企业远的员工,给与他们更多交通费上的支持,或者允许路途遥远的员工远程上班;③对于那些在每个公司都停留时间不长的员工,给予他们更多的关心和人格需求的关注,让他们在IBM公司感到足够的安全感,并愿意长期在IBM 公司工作。

图10 特征重要性排序图
5 结论
员工的流失对于企业来说,不论是财务还是非财务方面,都会产生较大负面影响。因此如何降低员工流失率、保留住高效员工已经成为了人力资源部门面临的最棘手的问题。因此,本文根据IBM Watson Analytics 分析平台上分享的员工流失数据进行实证分析,着重于数据预处理中的特征挖掘来对员工的流失情况进行预测。实验结果显示,新特征的挖掘对于模型的精度提升有较大帮助,模型的预测准确率为0.97。同时,本文识别出了影响员工流失的重要因素,其中包含薪酬、职位稳定性、员工忠诚性等,企业可以根据以上关键因素采取有效措施避免企业人才流失。同时,本文还存在一定的不足,在未来的研究中,可以通过调整不同的参数组合,获取精确度更高的模型。
