基于航拍图像的人员实时搜寻机制与分析
2020-06-18梁永春田立勤朱洪根
梁永春,田立勤,陈 楠,朱洪根
(华北科技学院 计算机学院,北京 东燕郊 065201)
0 引言
在突发性自然灾害或旅游、探险等活动中,经常发生人员失踪或被困需要救助的情况。野外人员搜救过程中,判断被困人员的位置通常是困难和耗时的一项工作。传统人工寻找的方法,需要大量的人员参与,效率低下。随着无人机技术的发展和成熟,依托它具有的成本低,方便灵活和可以在空中悬停的优势,通过无人机进行被困人员的位置确定成为一种高效可行的方法。但是,只是通过肉眼观看视频,进行人员的搜索和查找,容易受人的注意力、情绪和经验等因素的干扰,影响搜索效果。当前,由于神经网络算法在图像特征提取和相似度比较方面的突出表现,通过计算机辅助,进行被困人员的搜索和查找已经成为可能。通过计算机视觉技术进行航拍图像中人的查找,将减少人主观因素引起的干扰,提高搜索效率和准确性,对提升突发事件应急处置能力有一定的帮助。可是,由于航拍器与目标间观测角度和距离变动的影响,使得航拍图像中目标外观和大小变化较大。正是因为航拍图像的特殊性和重要性,使它成为计算机视觉领域中图像识别方向的难点和热点[1-4]。
计算机视觉中的目标检测主要由两个相反的操作部分组成:“目标到模型”和“模型到目标”。目标到模型是训练阶段,通过已经标注过包含识别目标的图像训练获得含有这些目标特点的模型;模型到目标是检测阶段,通过训练好的模型在没有标注的图像中检测是否含有与模型特征相似的区域。这两部分操作都包含图像中目标的特征提取,因此它也是图像识别的基础和计算机视觉领域核心问题。早期主要通过人工建模和半自动化的方式寻找和收集图像特征。这些方法包括颜色直方图、纹理特征图、比例特征等。例如,可以从多个视觉特征、LBP(local binary pattern)和方向梯度直方图(Histogram of Oriented Gradient,HOG)结合起来,实现航拍图像数据的目标检测[5]。还有人提出先使用SIFT(Scale Invariant Feature Transform)检测图像,先确定图像中特定背景区域,再通过支持向量机(SVM)分类检测特定背景中的目标[6]。随着计算机硬件性能大幅提升和以区域卷积神经网络(Region-CNN)算法为代表的机器学习算法研究的深入,使得计算机视觉快速发展和应用领域不断拓宽。其中,与传统人工建模的方式相比,运用神经网络可以从原始图像中自动提取特征、分离目标和背景[10-12]。这些方法虽然实现了目标识别,但准确性和实时性方面还有提升的空间。Redmon等人提出的YOLO(You Only Look Once)目标检测算法是通过深度卷积神经网络实现快速、准确的通用目标检测算法[13]。
综上,本文针对在野外环境中,无人机航拍图像与目标检测技术结合进行人员搜寻任务中,由于航拍器的观测角度、拍照环境中光照强度的影响和被困人员的服装颜色和姿势的差异等原因,导致航拍图像中的目标检测识别率不高,通过扩充训练数据集和对YOLO 算法中的卷积神经网络结构的调整和参数的优化,提高了航拍图像中特定目标的检出率。
1 卷积神经网络与目标检测
YOLO 系列目标检测算法包括V1、V2、V9000和V3等版本,它们的网络结构是通过卷积层(Convolutional)获得特征,池化层(Maxpool)融合特征,多层、多次迭代生成特征图模型,见图1。它们都可以在多框架下实现,包括Darknet[15],caffe[16]和PyTorch[17]等。
在YOLO算法体系中,V3公开测试结果显示在小目标识别的速度和识别率方面都优于其它算法。因此本文在V3算法的基础上,结合其它算法,提高航拍图片中目标被正确识别的准确率。支持YOLO目标检测的框架都提供了样本图片通过特定网络结构训练后,获得特征模型文件,进行目标检测。视频在这些框架中是将视频拆分成帧图片进行识别。
YOLO系列目标检测算法都是将图片整体读入,分批次取成特定等分尺寸的S×S个小区域。根据不同的算法对这些小区域进行特征提取,将具有相同或相似特征小区域进行连接形成具有某些共性的大区域。这些区域中的某些特征与权重文件中的特征进行比对,给出这两种特征的相似度。通过这个相似度,判断某区域中,存在特定物体的概率。最后选择含有某待检测物体最高概率的区域进行矩形标注,输出识别结果,见图1。
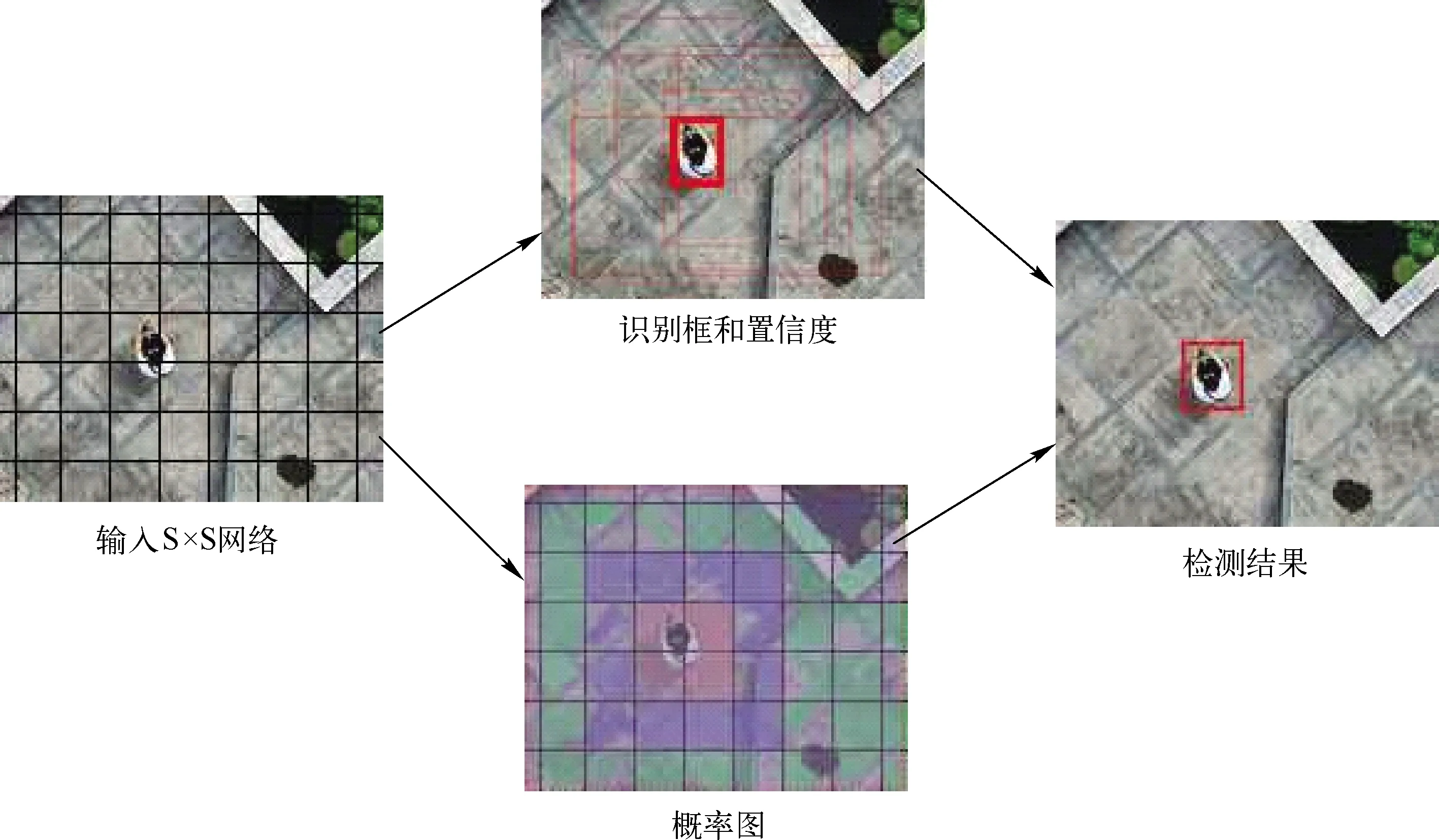
图1 YOLO目标检测方法

图2 训练样本旋转扩充和标注框生成
2 训练样本数据集的扩充
卷积神经网络进行目标检测,检出率是由训练样本和网络模型结构决定。航拍图像有两个突出的特点:观测角度多变和目标较小。第一个特点要求训练数据集要足够的全,第二个特点要求设计的卷积网络模型对图像特征提取更加准确全面。
样本的数据规模和质量都直接影响机器学习算法最终识别的正确性和准确性,通过卷积神经网络算法进行目标检测也具有这样的特点。航拍图像通常是从上向下拍摄,航拍器束缚较小,拍摄角度更加灵活,因此图像的表现形式也更丰富,也给识别增加了难度。其中,拍摄视角灵活多变是造成航拍图像识别率较低的主要原因。扩大旋转样本的数量,是解决这一问题直接有效的方法。但大量的符合要求的样本收集是非常困难的。传统的通过图像特点半自动的方式建立模型,进行目标识别虽然通用性方面落后于卷积神经网络,但应用它进行训练样本的扩充还是非常实用和高效的。在本实验自建的数据集中,部分照片中的识别对象比较分散,并且周围背景也比较单一,这样的图片可以通过旋转生成新的训练样本。
图像的自动标注,主要由前景提取、计算轮廓和计算标识框三个主要部分组成。数字图像是由像素点构成,像素点可以看作由代表RGB三色的数字组成。前景提取就是根据数字图像的特征实现特定数值范围内的像素点与其它像素点进行分离。为了轮廓计算的准确性和排除异常像素点的干扰,需要对图像进行二值处理,即图中的前景为转换为一色,其它部分转换为另一种颜色。轮廓计算是通过图像中的前景与背景交接处两边像素的数值有跳变这一特点计算获得。标注框的计算是计算轮廓中的点在横坐标与纵坐标方向的最大和最小值。因为在这一系列的图像像素数值计算过程中,图片中的前景位置没有改变,所以得到的标注框就是识别目标的标识框。图3展示了从航拍图片选取的部分含有检测目标的图片进行旋转与标注的过程。数字图像可以看成矩阵数据,因此旋转与矩阵变换综合应用对训练数据集扩充效果会更好。

图3 SR-YOLO 网络超清部分的网络结构
对于人的目标识别,通过旋转进行样本集扩充时不能违背人类活动的特点。通过对航拍图像中人各种姿势和生活经验的总结,卧姿时因为人体和地面近似平行,所以可以360°旋转,但其它姿势人体大多与地面垂直,因此摄像机的拍摄角约等于90°时才有实际意义。
3 SR-YOLO网络结构
通常航拍成像设备离目标较远,造成目标较小,通过传统卷积神经网络提取到的特征信息也较少,降低了目标被检测到的可能性。因此,提高航拍图像中目标物体的检出率,可以通过增加卷积神经网络提取到的特征信息实现。其中,图像的超分辨率就是其中有效方法。本文提出的SR-YOLO(Super-Resolution You Only Look One)算法,将图像先进行超分辨率在进行目标检测。
3.1 图像的清晰度增强处理
图像的超分辨率可以看成由低像素矩阵向高像素矩阵的函数对映问题,因为神经网络在数据拟合方面有着非常优异的表现,所以可以由神经网络实现从低清晰度图像数据向高清晰度图像数据的对应。图像清晰化加强的建模训练时需要将生成的超清图片与输入图片对应的清晰度较高图片进行相似对比。本文判断两个图片的相似性应用结构相似法。
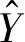
(1)
图像清晰度加强部分的网络结构主要功能包括特征提取、上采样、特征融合、残差修正和图像输出,网络框架如图4所示。Conv是卷积层,功能是特征提取;ReLu是激活函数,见公式(2),小于0的值被设为0,其它值保持不变。Dropout层是为了防止过拟合,随机对部分神经元进行删除。 Up-Sampling层进行上采样,即按当前的数据的结构特征进行数据扩充。Merge层是融合层,将上采样数据加入原数据特点。Residual Learning是残差层,防止多层神经网络性能的衰退,进行的计算方式的转换。
ReLu(x)=max(0,x)
(2)
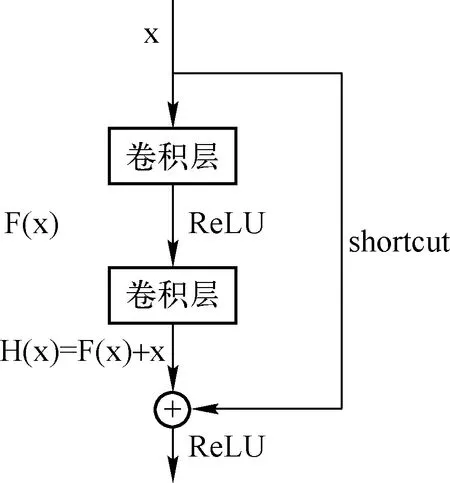
图4 残差块
3.2 SP-YOLO算法的目标检测部分
SR-YOLO目标检测部分输入图像大小为608×608,此数值越大每次读取的像素点越多对训练和识别越有利,但它受到显存和其它硬件性能的制约,在工程实践中通常需要根据具体情况进行调整。在一定范围内更深的网络结构可以提升检测效果,但随着网络层数的增加,效率也会随之下降,同时,带来的还有训练困难。为了网络更好的收敛,通常在网络结构中加入批量归一化层(Batch Normalization,BN)[18]和残差层[19]。
在通过梯度下降思想训练卷积神经网络模型过程中,传统的模型训练过程是将每层的卷积得到的特征结果直接提供给下一网络运算层,可是每次卷积的结果差异可能非常大,造成收敛速度慢。根据中心极限定理[20]的思想,卷积运算得到的特征总体分布符合正态分布。在YOLO 算法中BN 层实现将正态分布的特性引入到卷积神经网络中,加速模型收敛。式(3)和式(4)中,γ为缩放因子,xconv为卷积层,μ为一组图片卷积特征值的平均值,σ为一组图片卷积特征值的方差,Δ为标准方差的微调(通常为10-6),β为偏置值。式(3)是BN层数学表达式,式(4)为普通正态分布转化为标准正态分布的公式。对比这两个公式可以发现,BN层的作用是实现卷积层提取到的特征转化成标准正态分布。当卷积提取到的图像特征转化成近似符合标准正态分布,实现数据的中心化和标准化,更有助于激活函数对其特征的处理,减小梯度消失或梯度爆炸发生的可能性。同时,一批数据的均值和方差并不能代表全体数据的均值和方差,如果BN层严格按照公式(4)对卷积提取到的特征进行中心化和标准化将会消除真实分布的差异性,增加发生过拟合的风险。因此,在公式(3)中通过设置γ,β和Δ 参数,实现总体近似服从标准正态分布,但并不严格。
(3)
(4)
随着神经网络层数的增多,梯度消失越明显,而且某些隐藏层可能存在恒等映射,导致拟合效果不断降低。这里引入残差的概念,如图4所示,将原始输入x不做任何改变和输出H(x)进行相加处理,即H(x)=F(x)+x,其中x表示输入,H(x)表示输出,F(x)表示通过神经网络去拟合输入与输出之间的残差。引入残差后网络产生了短连接(浅层网络),网络中数据的正向传递路径更多样和网络参数的反向传递优化能力更强。
通过上述讨论可以发现,BN层通过将卷积后的特征转换成标准正态分布,实现抑制损失函数值大幅波动,但这样的方法对提取到的特征是有损失的.在小目标检测的任务中,损失的特征将给目标的识别率带来较大负面影响。因此,在SR-YOLO网络结构中,增加残差块的使用减少BN层的使用。
在目标检测训练阶段,损失函数帮助实现目标和非目标相互分离。在航拍图片“人”的识别中,选择通过误差损失的平方和为基础实现目标特有特征的提取。
(5)
(6)
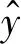
4 实验过程和实验结果分析
4.1 实验过程
(1) 试验设备与检测系统搭建
本实验前期模型训练和目标检测都是针对 RGB图像数据[21],即算法处理的是图片对应的矩阵。但是图像矩阵规模非常巨大,CPU缓存很小,如果用CPU进行这样的计算需要不断从内存读入数据和将计算的中间结果保存到内存,大量的时间被消耗在CPU对内存的访问。因此,目前针对这样大规模矩阵类数据的计算常通过显卡(GPU)进行。本实验,也选择是在Ubuntu18.04系统配置GPU版的PyTorch神经网络框架,进行模型的训练和检测,选择的显卡处理芯片是NVIDIA品牌Tesla P40,显存24G。
(2) 试验构建
在本论文目标检测模型的选择上采取相关因素比较法,检测结果与训练阶段使用数据集相关。由于公开的数据集较少有航拍图片针对“人”作为检测目标的训练图库。本实验,采取将多段航拍视频拆分成帧图片,并从中挑选部分作为训练样本。如果只应用这些样本进行模型训练,数据量是不够的,容易产生过拟合现象。本实验采取分步训练的方式解决这个问题。先通过ImageNet图片库进行训练[22],得到第一步的训练模型。虽然不同的观测角度会产生不同的物体外形特点,但同类目标不同的观测角度也有很多相似的特点。ImageNet图片数据量巨大可以较为全面的获取人的各种外形特征。第二步训练在自己标注的数据集和通过旋转生成的数据集上进行,目的是通过航拍图片数据,对第一步训练的模型加入更多航拍图片特征,提高在航拍场景中的识别率。
实验目的是验证通过航拍图片进行人的识别,训练样本选择户外地形复杂的地区。华山因其险而闻名全国,选择它作为本实验的样本数据是有代表性的。但是,由于华山旅游视频是冬天拍摄,游客穿深色衣服较多,训练样本特征不够多样,将会影响训练模型对不同衣着颜色的人识别率差异增大。为了增加样本的多样性,又在样本中增加了夏季贵州德江大龙阡景区旅游视频。这个数据样本的特点是人们服装颜色更多样,增加水面为背景的样本。样本标注在Ubuntu系统下采用标注工具labelImg软件。所有样本数据,按照训练样本占80%,验证验证样本占20%进行随机选择。
4.2 实验结果分析
根据卷积神经网络的特点,训练集的扩充和网络结构的调整都会改变目标检测的效果。图5说明的是通过训练集图片进行有选择的旋转数据扩充对目标识别效果的影响,图中是学生在操场摆拍——学生在操场上围成圆圈,人为创造一种航拍图像下目标可以多角度任意旋转变换。
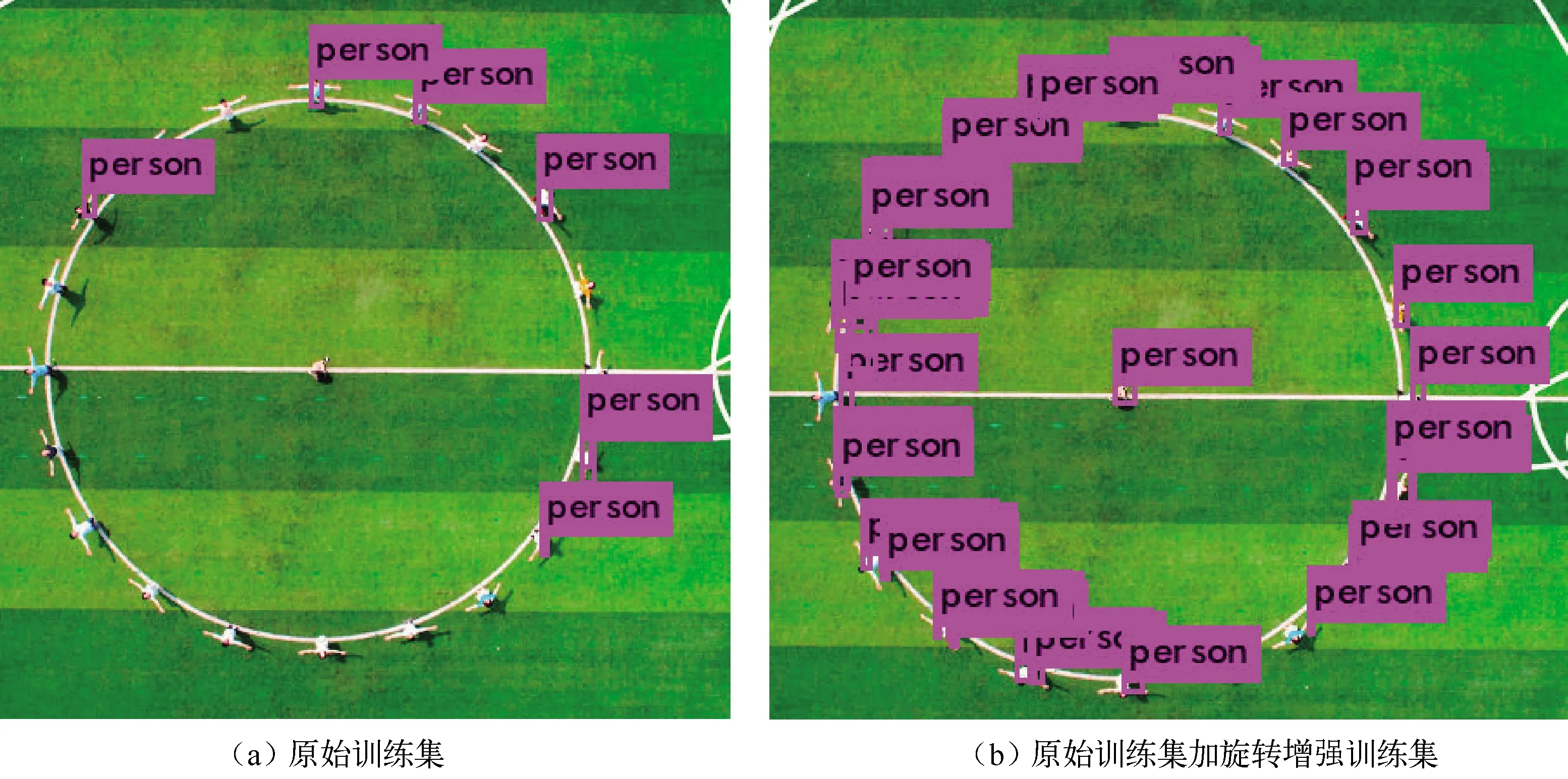
图5 不同训练集获得的模型目标检测结果对比
损失函数值的变化是对训练过程间接评价,训练得到的模型评价,通常由目标检测结果图直观展现。从识别结果可以看出,训练数据集中加入对已有部分样本的旋转扩充数据,可以解决航拍视角下由拍摄角度多变和识别目标人的姿态变化带来的识别困难。图6 是原YOLO算法与SR-YOLO在真实场景中人的识别对比。由于拍摄距离的影响,目标(人)在航拍图像中通常比较小,小目标提供的特征信息也较少增加目标检测的难度。图6 (a)是航拍直接获得的图片,图6(b)为原图在YOLO下的识别结果,图6(c)为原图经过SR-YOLO超分辨率处理后的中间效果,图6(d)为航拍图在SR-YOLO下识别结果。实验结果显示,图6(c)只检测到一个目标;图6(d)检测到4个目标。表1是SR-YOLO与YOLO v3目标检测性能对比数据,通过数据可以看出SR-YOLO目标检测算法对小目标人的正确识别的性能相比YOLO 有提升。

图6 SR-YOLO 与 YOLO 目标检测结果对比

表1 性能指标对照表
5 结论
(1) 将目标检测引入到户外环境下基于航拍图像的人员搜寻任务中,发现与传统的目标检测任务相比航拍图像由于拍摄距离较远和拍摄角度多变,造成航拍图像中的目标较小,目标外形变化较大,影响目标的检出率。
(2) 针对被检测目标人在航拍图像中姿态多变,提出通过传统数字图像处理方法进行照片旋转、前景目标分割、图像二值化、轮廓计算和标识框获取的流程对训练数据集进行扩充。实验数据表明经过旋转扩充后训练得到的识别模型对航拍图像中人的姿势多变识别效果更好。
(3) 针对航拍图像中目标小,不利于卷积神经网络进行特征提取,提出在原有YOLOL算法的基础上加入超分辨率处理部分形成SR-YOLO算法,此算法通过对卷积获得的特征进行上采样补充部分特征实现提升小目标的检出率。
