考虑排班的人力资源投入问题的建模与优化
2020-06-16陆志强许则鑫任逸飞
陆志强,许则鑫,任逸飞
(同济大学 机械与能源工程学院,上海 201804)
资源投入问题(resource investment problem,RIP)是一种经典的项目调度问题,其目标是优化人力资源的投入,使其成本最小化。然而人力资源作为一种重要的生产资源,在实际生产中,如飞机移动装配线,是以排班的形式进行生产作业的,因此资源的投入会受排班的影响。此时,调度的关键在于合理地安排作业和排班,从而确定每个班次的作业调度计划和资源投入情况,使得总体的人力资源投入最小化。在本文中,这一问题被称之为考虑人力资源排班的人力资源投入问题(resource investment problem based on employee-timetabling,RIP-ET),其本质上是资源投入和人力资源排班(employee timetabling problem,ETP)的整合问题。与传统的RIP问题相比,RIP-ET问题有以下几项难点:RIPET需要考虑工人排班的约束;RIP-ET不仅要决策作业的开始时间,而且还要决策作业投入的每个工人;对于RIP-ET问题,每个班次的资源投入是可变的,由于排班约束,班次之间存在资源占用情况;与RIP问题优化目标为资源峰值不同,该问题的目标是降低投入整个项目的人数。由于RIP-ET问题与传统RIP的决策范围与约束范围不同,现有的模型和算法无法适用,因此,对RIP-ET问题的建模与算法研究具有重要的理论与实际意义。
RIP是从经典的项目调度问题(resource constrained project scheduling problem,RCPSP)中衍生而来,问题的目标是在给定工期的情况下求解资源投入的最小值。Möhring[1]首先提出了资源投入问题,证明了该问题是NP-hard问题,同时证明了RIP与单模资源约束项目调度问题(single mode resource constrained project scheduling problem,SMRCPSP)的对偶关系。Demeulemeester[2]将 RIP转化为多个SMRCPSP,提出了MBA(minimum bounding algorithm)精确算法。Rangaswamy[3]提出了一个分支定界算法,进一步提高了算法的求解效率。由于精确算法在求解大规模问题上具有局限性,很多学者在此问题上设计了不同的启发式算法来进行求解。Yamashita等[4]将RIP转化为RCPSP问题,通过基于Scatter Search的元启发式算法求解该问题;Shadrokh等[5]采用遗传算法求解带有延迟惩罚的资源投入问题,分别对作业优先级和资源容量进行编码。Ranjbar等[6]首次在没有将RIP问题转化为RCPSP的基础上,通过路径重连和遗传算法来求解该问题。但是其算法可能会产生优先级不可行的作业列表,也会产生算法效率问题,而且在对作业进行调度时,并没有考虑到当前选择对全局资源投入的影响。Zhu等[7]在此基础上提出了一种多启动迭代搜索算法(multi-start iterative search method),该算法有效地提高了RIP解的质量。针对资源投入问题,许多学者还在此基础上进行了扩展性的研究[8-10]。本文提出的考虑排班的人力资源投入问题就是其中的一种。
人力资源排班是将具有特殊技能的人力资源分配到特定的班次,以满足特定时间段的服务需求。随着人力资源排班用于各种领域,人力资源排班的形式也呈现多样化。由于工作内容的不同,Baker[11]首次提出了人力资源分配的分类方法,将其分为轮班调度、日程安排和行程安排三类。Kletzander等[12]针对排班问题中的各种约束提出了一种适用性框架,并在此框架上提出了一种通用的模拟退火算法。但是在现有的文献中,大多只关注于人力资源的轮班顺序或工作时间表,很少将人力资源调度与其他调度(例如机器调度、车辆调度、生产调度、手术室调度等)结合在一起研究。然而,在一个实际的生产活动中,人力资源的排班往往需要与生产项目的调度结合起来统筹考虑,正如Bergh等[13]提到的,这也是未来一个主要的研究方向。Daniels等[14]假定每个作业必须由作业人员操作机器才能执行,将流水作业调度与人力资源排班整合起来。Drezet等[15]在资源受限的项目调度环境中考虑了人力资源排班,并提出一种预测算法来处理该问题。Artigues等[16]和Guyon等[17]采用了不同的精确算法对车间调度和人力资源排班的整合问题进行了求解。Smet等[18]将作业调度与排班问题结合起来,将任务与班次同时分配给员工。Eeckhout等[19]提出了一种新的迭代局部搜索方法,解决资源受限项目调度中的人员配置问题。由于车间调度、作业调度与资源投入项目调度具有一定的相似性,这对研究项目调度与人力资源排班的整合问题具有借鉴意义。不过,目前还没有关于RIP与人力资源排班的整合问题的研究。
RIP作为RCPSP的一个衍生问题,也是一种经典的项目调度问题,经常应用于实际项目决策中,它本身也对RIP-ET的研究具有很重要的意义。本文研究的RIP-ET除了考虑RIP的特性之外,还需要考虑人力资源排班约束,具有较高的复杂度,精确算法在求解这类大规模的问题时效率较低。遗传算法由于具有较好的全局搜索能力,在RIP中得到了很好的使用[20-23]。由于排班约束会导致班次间的资源抢占,故采用作业优先级和资源编码的方式对于该问题无法取得较优解。因此,本文采用了对作业开始时间进行搜索的遗传算法。
在分析现有文献中人力资源投入问题与人力资源排班问题和遗传算法的基础上,本文以最小化人力资源投入作为目标,从实际生产活动的决策需求出发,建立了RIP-ET的数学模型。通过分析,将该整合问题拆分为了人力资源投入和人力资源排班问题,并且设计了一种新型编码方式的遗传算法,通过对作业延迟时间进行编码的方式,对作业的开始时间进行全局搜索,此外还对作业延迟时间和开始时间进行局部优化。
1 问题描述及建模
记一个项目由若干项作业构成,j={1,2,3,…,n}为项目的作业集合。其中,1、n为虚任务不占用时间和资源,j∈J为作业编号,其标准作业时间为tj;全部作业共需要K种人力资源进行作业,资源集合R={1,2,…,K},k∈R为人力资源种类编号,其中第k种人力资源对应的单价为ck;定义m∈Mk为第k种人力资源中的工人编号,集合Mk={1,2,…,M}表示第k种人力资源的集合,同时假设同类资源下的所有资源不具有差异性。
项目的总工期为-T,每个班次8 h,将项目分为U个班次,定义班次集合为W={1,2,…,U},w∈W为班次编号,对于每个工人,规定在连续的3个班次中只能工作1个班次。假设作业从开始到结束不得中断,当班次结束时,若当前作业未完成,不允许工人加班,必须换上相同数目的同类工人继续该工作。在实际的人力资源排班中,很多情况下使用的是三班制排班。在文本中,不妨也使用三班制排班,假设每个班次8 h,将1 d分为3个班次。
Pj为作业j的紧前作业的集合,i∈Pj表示作业i为作业j的紧前作业;rjk表示作业j对第k种人力资源的需求量。对时间进行离散化,d∈D为离散时间点,D={1,2,…,T},T为项目的实际完工时间。
定义决策变量如下:
xjd——0,1变量,作业j在d时刻处于执行状态为1,否则为0;
hjdkm——0,1变量,第k种人力资源中的第m号工人在时间d执行作业j则为1,否则为0。
定义中间变量如下:
λwkm——0,1变量,第k种人力资源中的第m号工人在第w班次中进行作业则为1,否则为0;
ℓkm——0,1变量,第k种人力资源中的第m号工人投入了整个项目则为1,否则为0。
RIP-ET问题P1的数学模型如下:
目标函数为
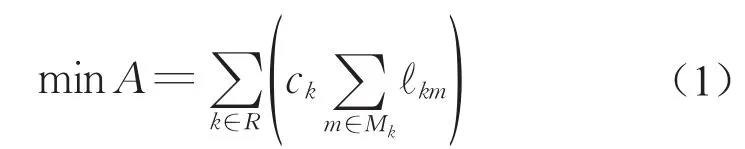
传统RIP约束为

排班约束为
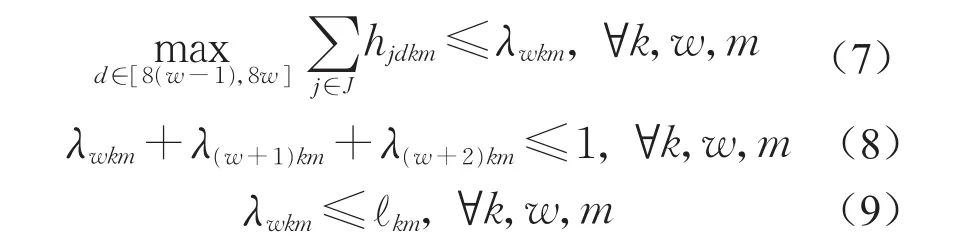
决策变量可行域为
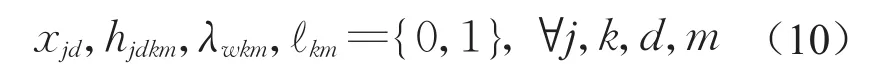
其中,式(1)为最小化人力资源的投入;式(2)表示作业的执行时间等于作业工期;式(3)为优先关系约束;式(4)为项目工期约束;式(5)表示任务一旦开始就不能中断;式(6)为资源约束;式(7)为决策变量hjdkm与中间变量λwkm的关系;式(8)为人力资源排班约束,单个个体的人力资源在连续3个班次中只能工作1个班次;式(9)表示中间变量λwkm与中间变量ℓkm的关系;式(10)表示定义所有决策变量中间变量的可行域。
2 问题分析与简化
上节给出问题P1的数学模型,是对作业调度与人力资源排班进行同时决策,需要在满足排班约束下求出人力资源投入的最小值。然而,通过分析发现,由于同种人力资源中每个个体之间不存在差异性,因此对于k类人力资源,总有:
性质1 考虑排班约束下的总投入总是等于不考虑排班约束下最大的连续3个班次的总投入。即,其中lkw为第k种人力资源在班次w的投入数量。
证明 假设所有作业的开始和结束时间已经确定,对于k类人力资源,假设有,其中w'为一个特定的班次,令。首先证明lkw'+lk(w'+1)+lk(w'+2)的人数在满足工人休息的情况下能够满足作业要求,即lkw'+lk(w'+1)+lk(w'+2)≥mk。由已知可得:lkw'≥lk(w'+3),表示对于w'+3班次对人力资源的需求可以由w'班次释放的工人来满足,从而可以推理得到lk(w'+4)≤lkw'+lk(w'+1)-lk(w'+3),lk(w'+5)≤lkw'+lk(w'+1)+lk(w'+2)-lk(w'+3)-lk(w'+4),由数学归纳法可以得到,对于w∈W,lk(w)≤lkw'+lk(w'+1)+lk(w'+2)-lk(w-1)-lk(w-2),即lkw'+lk(w'+1)+lk(w'+2)≥mk,得证。第二步,证明lkw'+lk(w'+1)+lk(w'+2)≤mk,使用反正法证明。若lkw'+lk(w'+1)+lk(w'+2)>mk,由于不等式两边都是正整数,可以假设mk=lkw'+lk(w'+1)+(lk(w'+2)-1),此时在w'+2班次中由于人力资源不足,无法进行作业,则是错误的,即,得证。从而可得。
根据性质1,发现求解原问题P1可以转化为:先根据项目调度计算每个班次需要投入人力资源的数量,进而计算最终的人力资源投入。本文将这个问题称之为问题P2。得到最优的人力投入之后,再根据每个班次的需求量对人力资源进行排班,这个问题称之为问题P3。因此,对原问题P1的求解,变成了求解问题P2与问题P3。针对问题P2,建立如下的数学模型。
定义决策变量如下:
xjd——0,1变量,作业j在d时刻处于执行状态为1,否则为0;
ykd——整数变量,第k种人力资源在时间d的投入数量。
定义中间变量如下:
lkw——整数变量,第k种人力资源在班次w的投入数量。
目标函数:
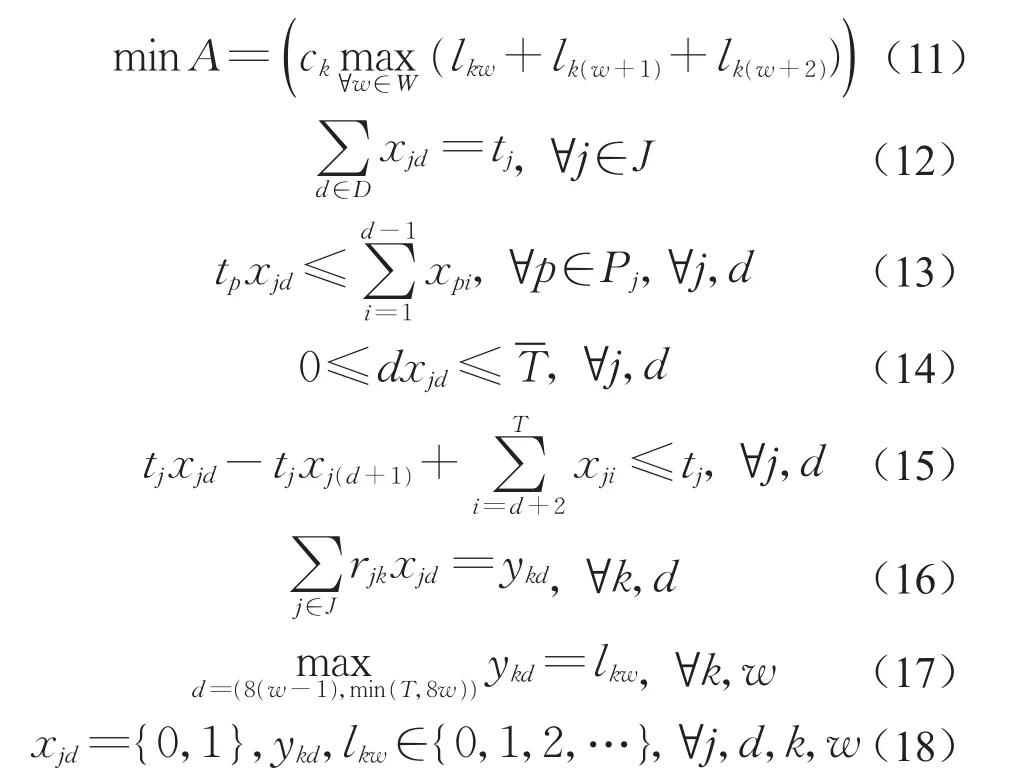
其中,式(11)为最小化人力资源投入;式(12)表示作业的执行时间等于作业工期;式(13)为优先关系约束;式(14)为工期约束;式(15)表示任务一旦开始就不能中断;式(16)为资源约束;式(17)表示中间变量lkw与决策变量ykd之间的关系;式(18)表示决策变量xjd、ykd和中间变量lkw的定义域。
问题P3是对工人的工作班次进行分配,在不考虑资源均衡的情况下,并没有目标函数。问题的决策变量和模型如下:
λwkm——0,1变量,第k种工人中的第m号工人在第w班次中工作则为1,否则为0。
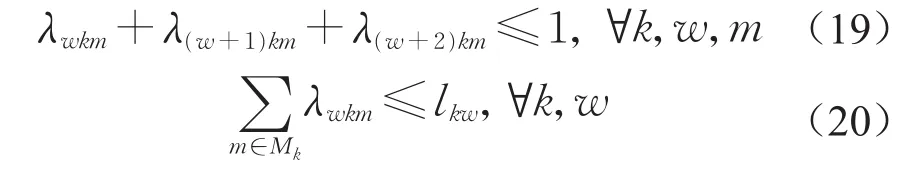
其中,式(19)表示单个工人在连续3个班次内只能工作1个班次;式(20)表示决策变量λwkm与问题P2中间变量lkw的关系。
为了验证问题简化的有效性,使用CPLEX对测试问题库中的小算例进行求解,来对比两种建模方式求解的速度。设定资源种类K=4,任务工期-T设置为由关键链方法(critical path method,CPM)得出的项目工期的1.2倍。表1和表2分别表示在10 jobs、14 jobs下两种建模方式求解结果。其中,jobs表示项目的作业数量。A1和A2分别为对问题P1和转化后问题P2、P3计算所得的目标函数值。T1为求解P1花费的时间,T2为求解P2和P3一共花费的时间,设置算法的最大运行时间为3 600 s。表2中,A列中“—”表示CPLEX没有求出最优解,T列中“—”表示CPLEX运行时间超过3 600 s自动停止。
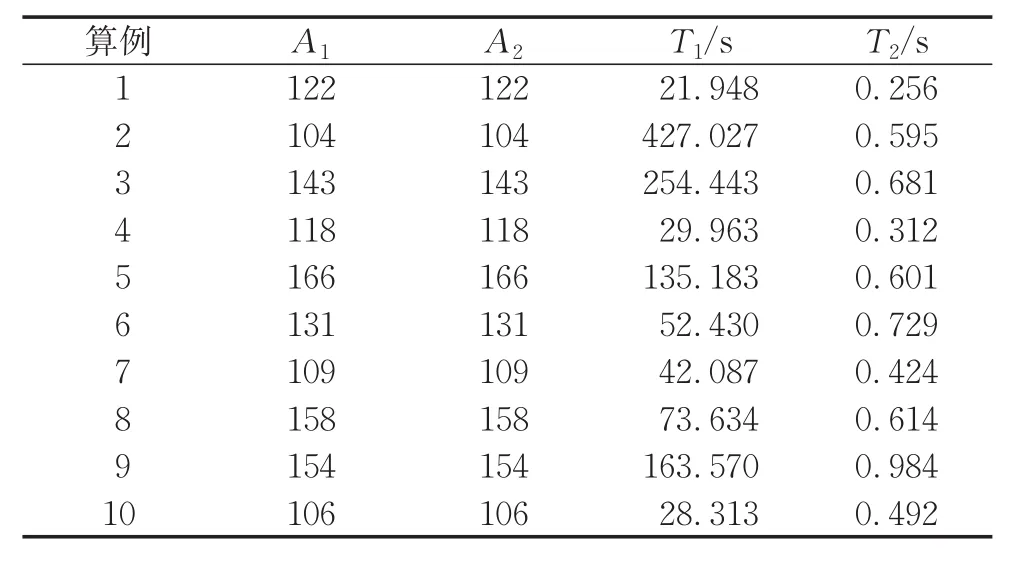
表1 10 jobs实验结果Tab.1 Scheduling result of 10 jobs
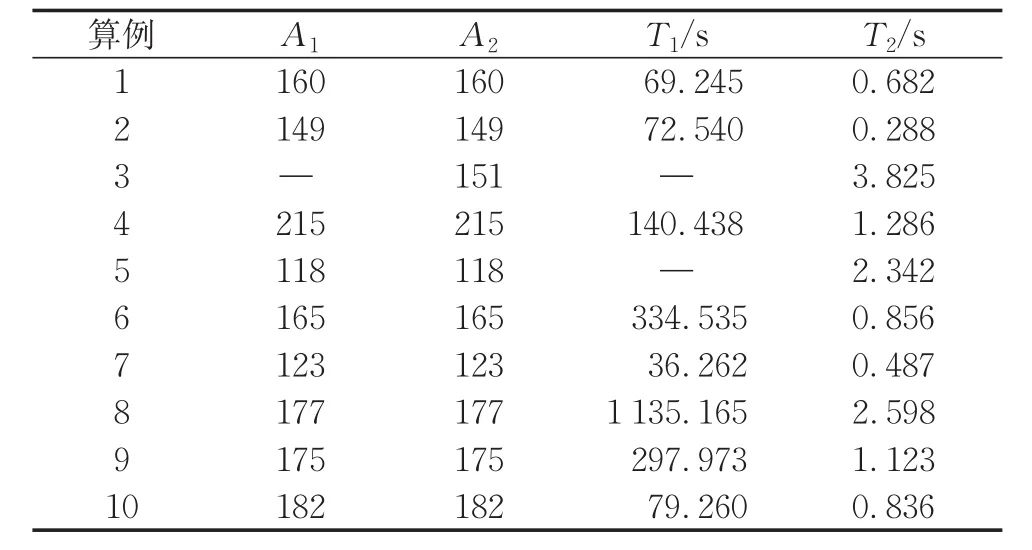
表2 14 jobs实验结果Tab.2 Scheduling result of 14 jobs
从实验对比可以发现,将问题转换之后,使用CPLEX求解的速度显著提升,因此将原问题转换为问题P2与问题P3在小规模的求解中是很有必要的。
3 算法设计
针对RIP-ET的特点,本文设计了一种对作业开始时间进行搜索的遗传算法,可以有效避免RIP在考虑工人排班时带来的难点。采用这种编码方式可以通过解码直接求出各个作业的开始时间,进而根据式(11)求出人力资源的投入量,解码过程中并不需要通过控制可用资源和作业的优先级来决策作业的开始时间。
Najafi等[24]通过CPM求出所有作业的最早开始时间,提出了对作业最早开始时间的浮动时间的编码方法。这种编码方法解决了基于现金折现的RIP,同时还提出了如何在解生成中避免出现不可行解。对作业开始时间的浮动时间进行编码,虽然可以有效避免排班带来的资源抢占问题,但是在生成下一代解时,变动性较小,容易陷入局部最优解。因此,本文采用对作业延迟时间进行编码的方式,并对作业延迟时间和开始时间同时进行局部优化。基于该问题设计了新的遗传算法,有效地解决了该问题。对比文献[24]的编码方式,这种编码方式能够有效地避免解陷入局部最优。需要强调的是,下文算法优化的是总人力资源投入,即针对问题P2所设计的算法,由于问题P3是一个简单问题,因此求解不加以赘述。
3.1 染色体编码
本文采用实数编码方式,对每个作业的延迟开始时间进行编码,编码长度为n,分别对应每一个作业的延迟开始时间,如图1所示。通过确定每个作业的延迟开始时间调度项目中的所有作业。

图1 作业延迟时间编码Fig.1 Coding with work delay time
关于延迟开始时间的相关定义如下:
定义1 在作业1~(i-1)已经调度的基础上,作业i的延迟时间等于作业i的最早开始时间与实际开始时间tSTi的差值,即
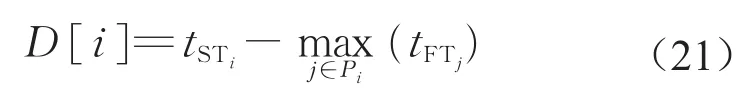
式中:tSTi、tFTi表示作业i实际的开始、结束时间。
定义2 在所有作业的延迟时间D给定的情况下,作业i的最早开始时间tESi等于其最晚紧前任务的结束时间,即令D[i]=0时,作业i的开始时间,即
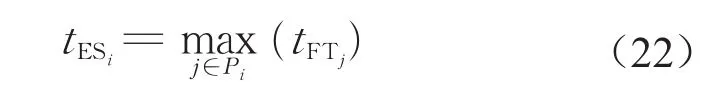
定义3 在所有作业的延迟时间D给定的情况下,作业i的最晚开始时间tLSi等于令最后一个任务的结束时间为项目工期,倒序所求出的作业i的开始时间,即
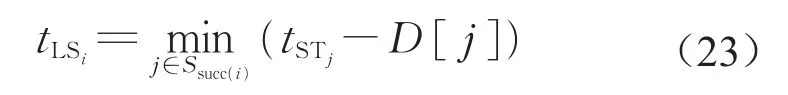
式中:Ssucc(i)表示作业i紧后任务的集合。
当所有的延迟时间D都为0时,或者未赋值时,所有作业的最早(晚)开始时间tESi(tLSi)为不考虑资源使用的情况下,由关键链方法所求得的最早(晚)开始时间,当某个作业延迟时间D给定时,其他作业的最早(晚)开始时间也会发生改变。
对于图2所示的例子,假设作业的延迟时间为(0,2,1,1,0,1,0,0),可以得到如图 3 所示的项目调度。
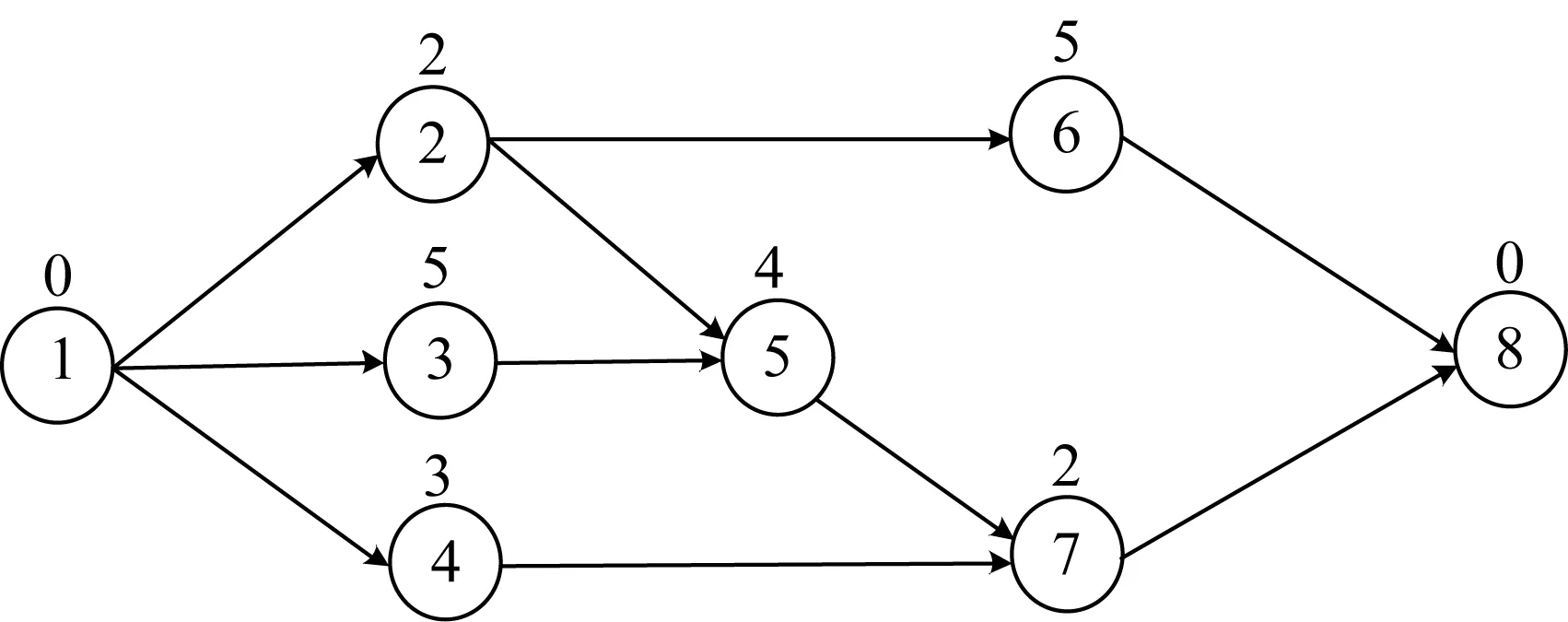
图2 项目的AON网络的一个实例Fig.2 An example of AON network of a project
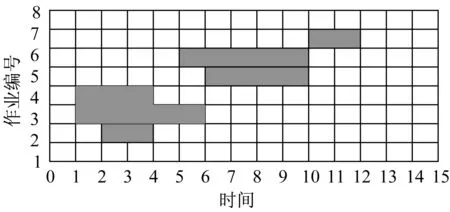
图3 项目调度时间图Fig.3 Scheduling time map of a given project
假设此项目的工期为15,通过逆向调度,将截止时间视为开始时间,结束任务作为开始任务,可得到项目逆向调度图,如图4所示。图中作业的开始时间,即为上文所定义的最晚开始时间。
于是,项目中所有作业的最早开始时间、实际开始时间等见表3。
此外,考虑到解的可行性,对于一组延迟时间D,它必须满足:对于任意作业i,该作业的延迟时间不能超过该作业的最晚开始时间与最早开始时间之差,即
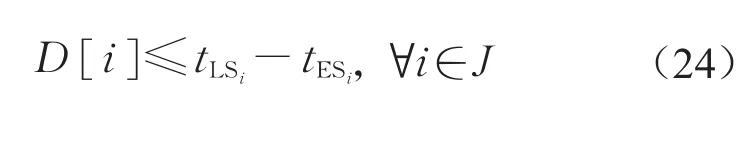
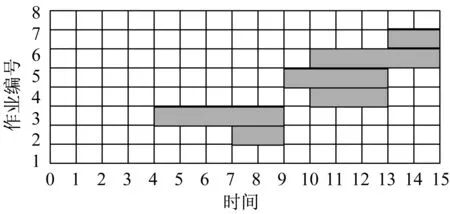
图4 项目逆向调度时间图Fig.4 A project time map with reverse scheduling
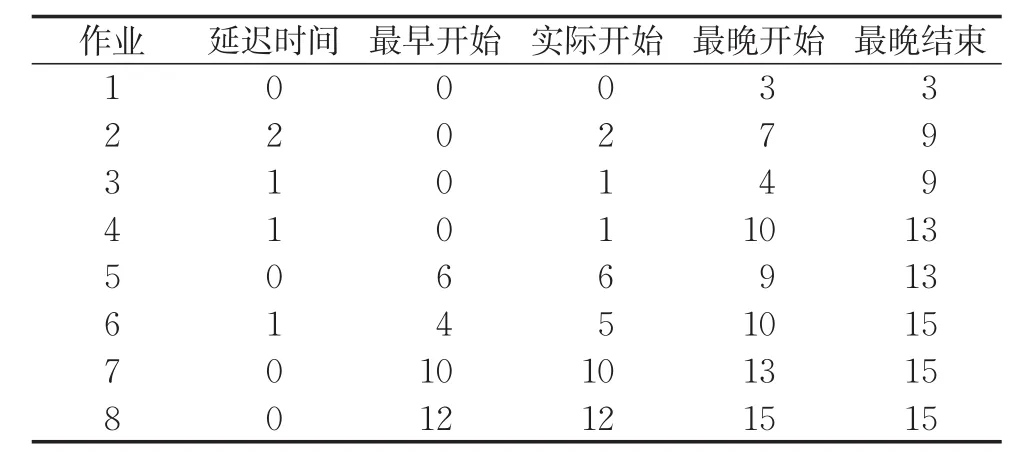
表3 项目中各作业的时间Tab.3 Time of all works
对于染色体的评估,可以根据目标函数计算染色体的适应值。本文所采用的对作业延迟时间编码的方式,可以有效地搜索所有作业可能的开始时间,通过确定所有作业的开始时间,来确定每个班次需要分配的资源。
3.2 初始解生成
采用正向和逆向两种方法生成初始的染色体群。根据上文所提到的,要保证解的可行性,基因D[i]∈[0,tLSi-tESi]。于是,需要先求得作业i的最早开始时间与最晚开始时间,然后再给基因D[i]随机赋值。为了防止先生成的D[i]过大,导致后续D[i]的取值受限。本文采用如图5所示的三角分布对基因进行随机赋值。下文中采用三角分布都是这个原因。
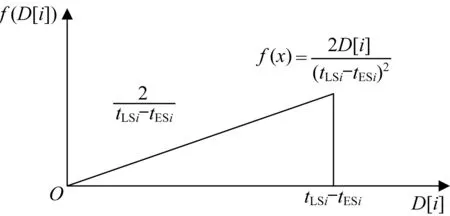
图5 产生基因i的三角分布图Fig.5 Triangular distribution for gene i generation
3.2.1 正向生成染色体
从作业1到作业n顺序生成每个基因的值。算法步骤如下:
步骤 1 初始化D[i]=0,∀i∈J,计算所有的tESi、tLSi。
步骤2 令i=1,在[0,1]中随机选取一个小数θ
步骤3i=i+1,计算作业i的最早开始时间tESi,在 [0,1]中随机选取一个小数θ,令
步骤4 若i=n,则停止运算,否则转步骤3。
3.2.2 逆向生成染色体
从作业n到作业1逆向生成每个基因的值,算法的具体操作与正向生成染色体的操作类似。
3.3 染色体交叉
选取父代染色体P1、P2进行交叉,生成子代染色体C1、C2。子代染色体中的一部分直接复制父代的染色体,另外一部分通过2条父代染色体交叉得到。
定义4 在给定的调度基础上,作业延迟时间的可减少值等于作业的实际开始时间减去作业最早的开始时间,即
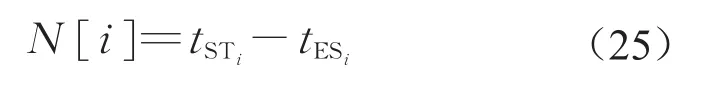
定义5 在给定的调度基础上,作业延迟时间的可增加值等于作业的最晚开始时间减去作业的实际开始时间,即
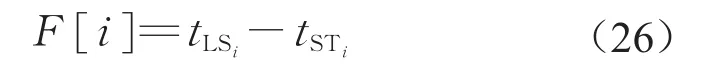
染色体交叉的算法步骤如下:
步骤1令C1[i]=P1[i],C2[i]=P2[i],∀i∈J。
步骤2 对于父代P1、P2,计算所有作业延迟时间的可减少值和可增加值,记为NP1、FP1、NP2、FP2。
步骤3 在范围[2,n-1]内随机生成一个整数q。
步骤4 在范围[0,1]随机生成一个小数ρ。若ρ>0.5,转步骤5,反之转步骤9。
步骤5 令i=q。
步骤6 令i=i+1,对于子代C1、C2,计算作业i延迟时间的可减少值和可增加值,记为NC1[i]、FC1[i]、NC2[i]、FC2[i]。
步骤7 染色体的交叉步骤,根据上面得到的结果不同,可以分为几下几种情形。
情形1 当NP2[i]>0,FP2[i]>0,即父代P2中作业i的可减少与可增加时间都大于0,令
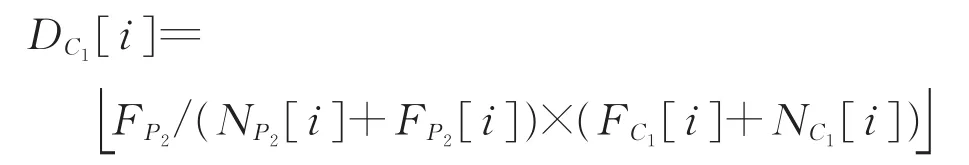
情形 2 不满足情形 1,并且NC2[i]>0,FC2[i]>0时。此时与C2交叉。即令
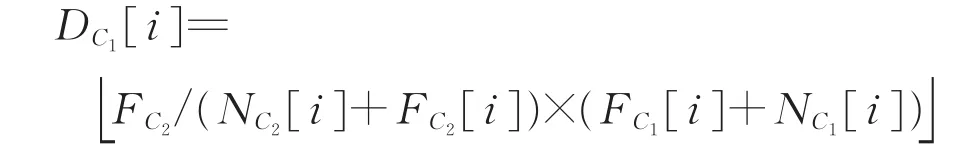
情形3 即不满足情形1与情形2,此时DC1[i]取[0,NC1[i]+FC1[i]]中的随机一个整数。
按照生成DC1[i]的交叉操作生成子代C2的第i个基因DC2[i]。
步骤8 若i=n停止运算,否则转步骤6。
步骤9 令i=q。
步骤10 对于子代C1、C2,计算作业i延迟时间的可减少值和可增加值,记为NC1[i]、FC1[i]、NC2[i]、FC2[i]。
步骤11 重复步骤7的操作。
步骤12 若i=1则停止运算,否则令i=i-1转步骤10。
3.4 染色体变异
选取染色体C进行变异,随机选择该染色体一部分的基因进行变异,其他部位的基因保持不变。与染色体的生成相似,计算作业i的F[i]、N[i]。采用三角分布对D[i]重新赋值。
染色体变异的算法步骤如下:
步骤1 从[1,n-1]随机选择两个整数q1、q2,其中q2>q1。
步骤2 从[0,1]随机选取一个小数ρ,若ρ>0.5,转步骤3,否则转步骤7。
步骤3 令i=q1。
步骤4i=i+1,对于染色体C,计算所有任务延迟时间的可减少值和可增加值,记为NC[i]、FC[i]。
步骤5 在[0,1]中随机生成一个小数θ,D[i]=θ2·(FC[i]+NC[i])。
步骤6 若i=q2,运算结束,否则转步骤4。步骤7 令i=q2。
步骤8 对于染色体C,计算作业i延迟时间的可减少值和可增加值,记为NC[i]、FC[i]。
步骤9 在[0,1]中随机生成一个小数θ,。
步骤10 若i=q1,则停止运算,否则令i=i-1,转步骤8。
3.5 局部优化
为了提高解的适应性,本节采用两种局部优化方法对作业的延迟时间和作业的开始时间进行优化。
3.5.1 对作业延迟时间优化
对于一个已经给定的调度,每个作业都有一个延迟开始时间,改变作业延迟时间可以改变目标函数的值。例如,对于图3所示的项目调度时间图,作业的延迟时间为(0,2,1,1,0,1,0,0),作业2延迟时间的可增加值和可减少值分别为5和2。减少或者增加作业2的延迟时间,可以得到一个新的目标函数值。
该局部优化的算法步骤如下:
步骤1 令i=1,计算当前调度下目标函数值为A。
步骤2 计算作业i延迟时间的可增加值和可减少值F[i]、N[i]。
步骤3 从D[i]∈[0,F[i]+D[i]]中选择使得目标函数值最优的D[i],更新D[i],A。若i=n,停止运算,否则令i=i+1转步骤2。
3.5.2 对作业开始时间优化
对于一个给定的调度,提前或推迟作业的开始时间可以改变目标函数的值,通过对每个任务开始时间的优化可以优化整个项目的资源投入。
定义6 表示作业i在不影响其他作业的基础上最早的可开始时间,等于所有紧前任务最晚的完成时间,即
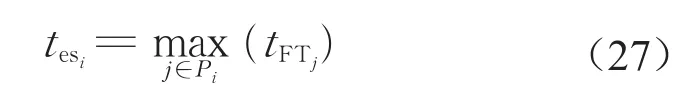
式中:tFTj表示作业的实际完成时间。
定义7tlsi表示作业i在不影响后续作业开始时间的基础上最晚可开始的时间,等于所有紧后任务最早的开始时间减去作业i的持续时间,即
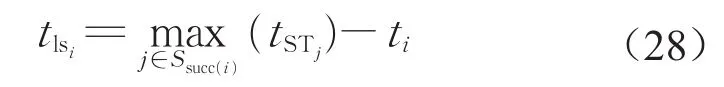
该局部优化的算法步骤如下:
步骤1 令i=1,计算当前调度下目标函数值为A。
步骤2 计算作业i最早开始时间和最晚开始时间tesi、tlsi。
步骤3 从tSTi∈[tesi,tlsi]中选择使得目标函数值最优的tSTi,更新tSTi、A。若i=n,停止运算,否则令i=i+1转步骤2。
4 数据实验
为了验证本文设计的采用对作业延迟时间编码的遗传算法(DTGA)的有效性,选取10 jobs、14 jobs、18 jobs、30 jobs、60 jobs、90 jobs,各10个算例进行数值实验,与文献中对采用作业浮动时间进行编码的遗传算法(FTGA)[24]进行比较。数值实验在C#(Visual Studio 2017)语言环境下编程实现,测试平台为Intel Core i5 4th处理器,2.40 GHz主频,4G内存,结果如表4至表7所示。其中,AD、AF、AC分别为该组算例在DTGA、FTGA和CPLEX下所求得平均目标函数值,TD、TF、TC分别为平均运算时间,G1、G2分别为DTGA、FTGA所求目标函数值与CPLEX最优解的差距,G为DTGA和FTGA之间的差距。遗传算法的种群数为50,交叉概率为0.8,变异概率为0.3。
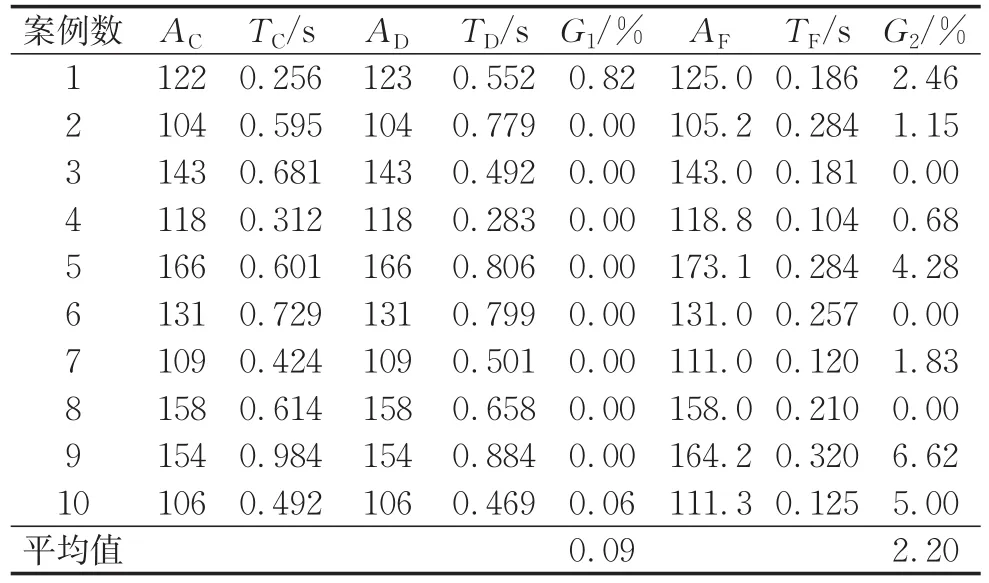
表4 10 jobs实验结果Tab.4 Scheduling result of 10 jobs
表4至表6显示了小规模的算例结果,算例规模分别为10 jobs、14 jobs、18 jobs,每组包含10个案例。从表中可得到:当作业数量为10 jobs和14 jobs时,本文所设计的算法求得的最优解基本等于CPLEX得到的最优解,而对比算法的结果与最优解有明显的偏差,在求解时间上3个算法都在同一个数量级范围。当作业数量为18 jobs时,本文所设计的算法与CPLEX得到的最优解仅为1.6%,对比算法的偏差却达到了10%,而求解时间上本文算法与对比算法在同一个数量级内,远远小于CPLEX的求解时间。因此,得出以下结论:在小规模的算例中,本文所提出的遗传算法在一定误差范围内均能求解出较好的结果。

表5 14jobs实验结果Tab.5 Scheduling result of 14 jobs
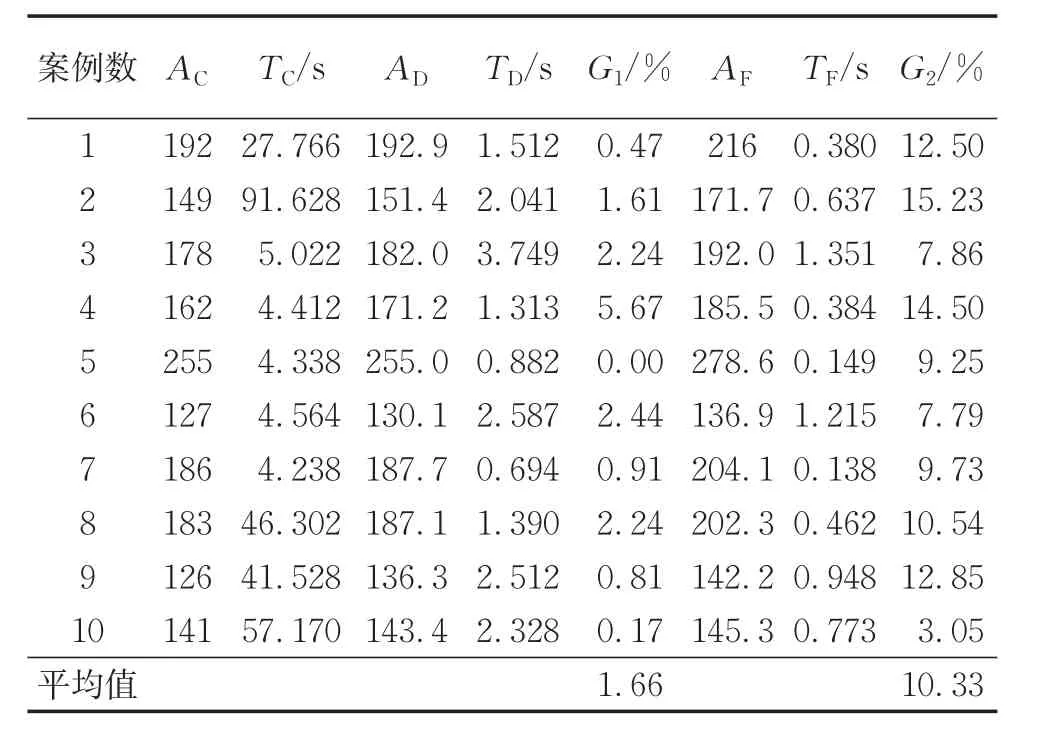
表6 18 jobs实验结果Tab.6 Scheduling result of 18 jobs
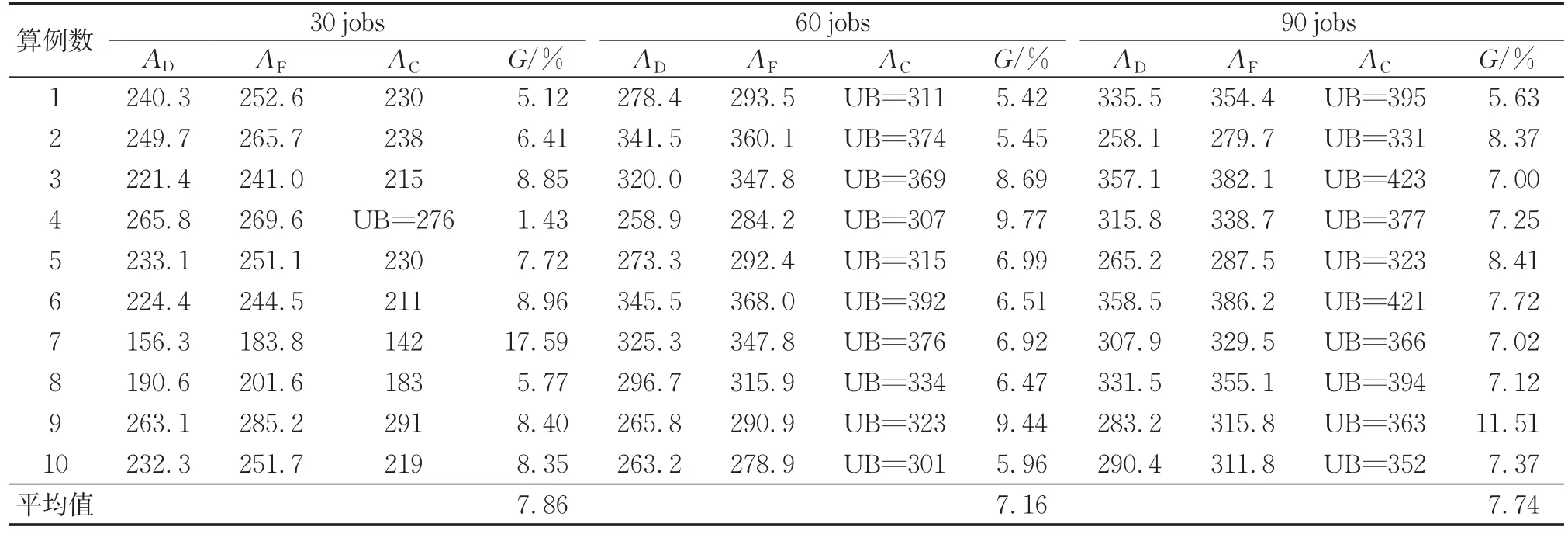
表7 中规模、大规模案例实验结果Tab.7 Scheduling result of middle and large scale
为了对比两种算法的优劣性,在其他设置参数相同的情况下,对比两种算法在不同的迭代次数下的求解结果。在3种不同规模下,各取10个案例,记录每个案例在不同迭代次数下的平均值,再对10个案例取平均值。图6至图8表示作业数目为30 jobs、60 jobs、90 jobs的情况下,两种不同算法的比较。横坐标为迭代次数,纵坐标为10个算例的平均值。通过图可以发现,随着迭代次数增加,两种算法的值逐渐降低,并且在不同的迭代次数下,本文设计的算法DTGA都明显优于对比算法FTGA。
表7显示了30 jobs、60 jobs、90 jobs 3种情况下本文设计算法与CPLEX及对比算法之间的对比。两种遗传算法的设置参数相同,迭代次数均为200。每组选择10个案例,为了实验结果更具代表性,每个案例求解10次并取平均值。针对大部分大规模算例,由于CPLEX无法求得精确解,因此与CPLEX在7 200 s内所求上界UB进行对比。从表7中的数据可以看出,在作业数目为30 jobs情况下,CPLEX能求得一部分算例的精确解,本文算法与精确解之间相差百分比平均约为4.75%,而对比算法与精确解之间相差百分比平均约为12.15%。与对比算法相比,本文算法在求解大规模算例问题上更加有效。
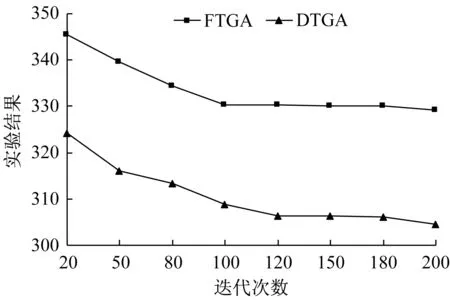
图6 30 jobs实验数据对比Fig.6 Comparison of scheduling result of 30 jobs
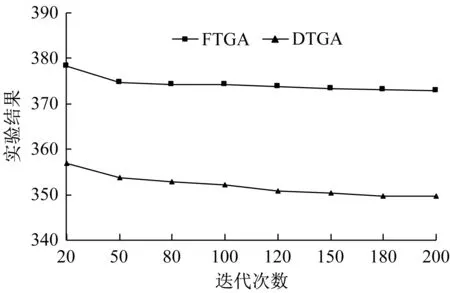
图8 90 jobs实验数据对比Fig.8 Comparison of scheduling result of 90 jobs
5 总结与展望
本文在考虑实际生产过程中存在的换班情况下,提出了以最小化人力成本投入为目标的考虑排班的人力资源投入问题,建立了人力成本投入最小化为目标的数学模型。此外,本文将所提出的数学模型进行拆分,使得小规模问题可以直接用CPLEX进行求解。为了解决大规模问题,本文又提出了对作业延迟开始时间进行解码的遗传算法,并且对作业开始时间和延迟时间进行局部优化,从而得到最佳目标值。算例实验结果表明,无论是小规模的模型拆分还是大规模算法的构建都取得不错的效果。
在实际中,同一种人力资源之间,由于个体的不同也可能存在差异,然而本文中并没有考虑这种差异性,这也是本文未来的研究方向之一。
