基于过程数据分析的彩色滤光片产线故障机台定位
2020-06-13刘仁俊孙兆辉明新国
刘仁俊,孙兆辉,张 莉,程 光,明新国+
(1.上海交通大学 机械与动力工程学院,上海 200240;2.上海仪电显示材料有限公司,上海 201108)
1 问题的提出
生产线故障定位技术是生产故障修复的基础,是保证生产系统高效、稳定运行的前提[1-2]。在当今彩色滤光片定制化、小批量、多产品、高规格的新常态化生产模式下[3],面对繁杂的生产工序、生产排程以及大量检测设备产生的海量数据,传统的质量分析技术在故障定位的效率和精度提升上已面临瓶颈[4]。
如图1所示,彩色滤光片由玻璃基板、黑色矩阵、彩色光阻层、透明导电膜和间隔柱组成[3],复杂的产品结构导致制造工艺也比较复杂,包括拆包(unpack)、黑色矩阵(black matrix)、彩色光阻层(color resist red, green, blue)、透明导电膜(Indium Tin Oxide, ITO)、间隔柱(photo spacer)、包装(pack)6个工艺,每个工艺的制造流程高度自动化,排除了人的影响,使产品的质量缺陷和工艺间具有强相关关系。

彩色滤光片的质量缺陷可以通过宏观肉眼观察和微观机器图像识别来检测,但作为其根本原因的特性缺陷则需要追溯生产的机台。传统彩色滤光片质量追溯流程如图2所示,通常采用基于人工经验的方法查询对应生产机台的加工记录和警报信息,对比加工工序是否存在时间异常。

传统质量追溯流程存在几个主要的问题瓶颈:
(1)分析困难 全自动化生产导致的数据爆炸,复杂工艺及流程带来的样本维度不一,以及外部干扰导致的数据噪声大、异常警报多等问题,给人工分析带来了巨大困难。
(2)判断主观,存在矛盾 在复杂的实际业务情景下,技术人员经验的差异性和部门间信息的不对称性,导致了不同的故障分析标准和流程。
(3)时间滞后 由于无法实时检测机台的运行状态,判断故障积累水平,传统的质量追溯流程要在出现滤光片缺陷时才发起,拉长了平均故障修复周期,增加了生产线不稳定运行的风险。
针对传统流程已有的瓶颈,在缺陷样本的评价分类上,庄进发[5]采用拒绝式转导推理多类支持向量域数据描述(Rejected Transductive Inference Multi-class Support Vector Data Description, RTIM-SVDD)方法,通过应用M+1个超球体处理M分类问题,并使用转导推理原则评判模糊样本点归属,相对于距离式M-SVDD(Multi-class SVDD),该方法的性能有所提升。在建模分析方面,吴娟[6]建立了神经网络故障观测器模型,基于多源特征信息输出端与传感器故障参数的映射,通过实时趋势描述基元比对专家故障知识库进行故障定位;郭金玉等[7]通过局部离群因子K近邻算法(Local Outlier Factor-K-Nearest Neighbor, LOF-KNN)建立模型,对检测出的故障计算基于K近邻法(K-Nearest Neighbor,KNN)的变量贡献,对贡献矩阵进行量化得出故障定位图;涂光辉[8]针对样本分布不均衡的过程数据上存在的模型失配问题,采用新的引力质心模型,在宏平均误差和微平均误差两个指标上超越了基于质心的网络故障分类器。在信息融合综合判断方面,作为一种不确定性推理方法,D-S(Dempster-Shafer)证据理论[9]比传统概率理论能更好地把握问题的模糊性和不确定性,而且提供了一个非常有用的综合工时,可以将多种证据来源融合为一个综合结论;Yager[10]和孙全等[11]针对D-S证据理论合成高度矛盾的证据时会产生不合理结果的缺陷,提出了改进方法;陈非[12]通过定义基于过程信息融合的信息来刻画过程状态变化,从而判断故障位置和故障烈度。
目前,已有的故障定位研究主要基于传感器数据,对与缺陷同样强相关的加工参数和机台警报信息利用得较少;同时对多个过程数据源做出的独立判断,缺乏有效的信息融合手段来定位综合故障。因此,本文提出新的彩色滤光片生产线故障机台定位模型,该模型基于缺陷类型和面积权重评分确定多缺陷共存时的滤光片主缺陷标签,通过Xgboost[13]集成方法训练加工过程数据与缺陷的关联模型,以信息熵增益确定各个过程数据源的贡献度;基于K-means[14]聚类机台警报划分每个故障问题子集,以警报来源反推机台故障概率,进而以D-S证据理论融合两者判断,确定综合问题机台概率。该模型解决了数据量大、维度高情况下分析困难的问题,并基于多源数据的融合判断方法使判断更加客观而全面,而且通过自动化的分析改善了传统方法的时间滞后性。实际案例应用表明,该模型能够帮助专业技术人员更好更快速地定位问题机台,加速故障分析流程。
2 基于过程数据分析的故障定位模型
图3所示为基于过程数据的故障定位模型,整个流程的输入为彩色滤光片缺陷检测数据,模型针对成品的单片彩色滤光片常包含多个不同类型不同大小缺陷的情况,基于缺陷类型和面积的权重进行缺陷类型评价分类,以确定玻璃片的主要缺陷类型作为训练标签。然后,通过统计过程控制(Statistical Process Control, SPC)系统查询该玻璃片加工时所在的产线,进一步查询产线上的机台获得加工过程数据和机台警报信息。加工过程数据通过数据降维和Xgboost方法训练出过程数据与玻璃片缺陷的关联决策树模型,以信息熵增益得到特征贡献度评价并反推得出机台可能有问题的概率。机台警报通过警报代码和警报产生时间两个维度进行聚类,对每一个类团确定主要警报并反推出机台可能有问题的概率。最后,通过分别产生的两条问题机台概率证据,以D-S证据理论进行信息融合产生综合的问题机台概率结论。
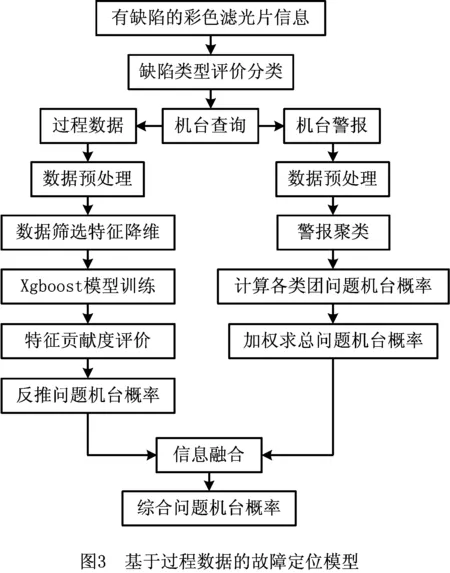
整个故障机台定位流程分为缺陷类型评价分类、过程数据建模分析、机台警报聚类分析、信息融合4部分分别讨论。
3 基于过程数据分析的故障定位流程
3.1 缺陷类型评价分类
彩色滤光片由大量像素点构成,在生产过程中容易产生像素坏点,这些坏点都会成为成品的质量缺陷,目前生产企业主要通过彩膜自动光学检测(Automated Optical Inspection, AOI)技术结合分区检测技术[15],针对不同的工艺和矩阵图形分区比较,根据各分区基本灰阶设定阈值来自动化检测彩色滤光片缺陷,其检出的缺陷类型包括反射黑(RB)、反射白(RW)、透射黑(TB)、透射白(TW),缺陷大小包括小(S)、中(M)、大(L)、超大(OL)。
单片彩色滤光片在生产加工过程中往往会产生多处不同类型不同面积的缺陷,很难对滤光片定义唯一的缺陷标签,因此提出基于缺陷类型和面积权重评分的主类型评价分类方法。在实际生产中,鉴于中等及以下缺陷占比高(80%以上)但对质量影响不大,定义S和M大小的缺陷为1分和2分;对于L和OL大小的缺陷,一旦出现就很有可能导致激光修补或者返工,其影响程度明显高出一个数量级,因此分别记为10分和20分。
表1所示为某片滤光片上所包含的所有缺陷。一般可以得出RB缺陷影响最大、TB次之、TW可以忽略,因此RB是该滤光片主要缺陷的结论。同理根据本文缺陷评价分类方法,4种缺陷RB,RW,TB,TW对应的评分为25,0,4,10,滤光片应标记为最高分的RB,与经验判断相同。算法流程如下:
算法1缺陷类型评价分类。
输入:彩色滤光片样本X,样本个数n,样本缺陷数nk。
输出:分类后的彩色滤光片样本。
1:function缺陷类型评价分类(X)
2: [S,M,L,OL].weight=[1,2,10,20]
3: for i=1→n & j=1→nkdo
4:if Xij.label=[OK,RB,RW,TB,TW,Other] & Xij.size=[S,M,L,OL] then
5:label.score←label.score+size.wight
6: endif
7: Xij.label←max(label.score)
8: Endfor
9: return X
10:end function

表1 单片彩色滤光片缺陷举例
3.2 过程数据建模分析
彩色滤光片生产制造涉及多条生产线和数量众多的机台,产生的大量信息可以作为过程数据的属性(如表2),包括预先设定的加工工艺参数(如RGB层涂层厚度、洗净机清洗液流速、曝光机曝光强度等设定)、机台各工序的实际加工时间(如实际涂布、清洗、显影时间),以及机台传感器感知的环境信息(温度、湿度、压力、振动等)。在现实情况中,大部分机械结构故障如电机运作不良、机械手运动不到位,机械破损如液体泄漏导致的余量不足、气密性被破坏导致的污染物流入等,会与过程数据相关联并最终导致滤光片产生缺陷。通过建立彩色滤光片过程数据与缺陷关联模型,可以从缺陷的产生反推对应的过程数据属性,从而为确立具体机台问题提供重要数据支撑,因此提出基于Xgboost与信息熵增益的缺陷根因特征评价方法,其主要流程如下:

表2 过程数据包含的信息
(1)数据预处理
过程数据的属性总量非常大,而且属性里存在缺失数据或者恒定值的情况,因此必须进行数据预处理。假设有n片彩色滤光片,一片彩色滤光片加工时流经所有机台的工艺参数、加工时间等过程数据特征有m维,则经过数据采集并聚合可得样本矩阵X∈n×m,其行向量Xi∈m表示第i片彩色滤光片样本,列向量fj∈n表示第j项过程数据特征。使用Z标准化[16]对所有属性的数据进行标准化,对彩色滤光片的标签OK,RB,RW,TB,TW,Other分别编码为0,1,2,3,4,5。
(2)数据筛选与特征降维
过程数据部分属性存在耦合、变化趋势高度一致、数据冗余的情况,为了后续高效训练,必须对数据进行降维。本文分别采用正则化自表示[17](Regularized Self-Representation, RSR)和拉普拉斯评分[18](Laplacian Score, LS)的特征选择方法,相比于皮尔森相关系数、L2正则化等其他特征选择方法,这两种方法在算法复杂度上有一定优势,适用于数据维度高、样本量大的工业场合。
RSR方法的目的是要找到最能代表其他特征的特征,从而将特征选择问题转为以下最小化问题:
(1)
式中:X为彩色滤光片样本矩阵,W为自表示权值矩阵,故有‖X-XW‖2,1越小W越准确;λ为正则化常数;‖W‖2,1为对W的正则化项,用于增强W对异常样本的鲁棒性以及防止W成为单位矩阵。最终计算出第j项特征的自表示评分为
vj=‖Wj‖2。
(2)
显然对于数值恒定和数值缺失的特征,其代表其他特征的能力很弱,反映到自表示权值矩阵W,即对应行向量的平方和很小,自表示评分很低。因此通过自表示特征选择可以有效去除冗余的特征,实现数据降维。
LS方法的目的是找出最能反映样本局部结构的特征,以增强样本区分性并提高后续模型的准确率。LS方法首先构造了基于样本K个邻居的邻近图G,图中一个节点表示一个彩色滤光片样本,如果两个节点互为k个最邻近节点之一,则在两个节点之间建立一条边,于是将特征选择问题转化为以下目标函数:
(3)
式中:Lr为第r项特征的拉普拉斯评分;fri为第i个彩色滤光片的第r项特征,i∈{1,…,m};
(4)
Sij是对第i个和第j个节点相似性的估计;Var(fr)为第r项特征的方差。显然,对于区分性良好的特征,任意有边相连的两个节点,其该特征的差值的平方(fri-frj)2较小,而且相似性估计Sij趋近于1,任意不相连的两个节点因为Sij=0不统计,所以综合而言拉普拉斯评分较小。通过拉普拉斯评分可以有效筛选出区分性能好的特征。
(3)Xgboost模型训练
可以用于建立彩色滤光片过程数据与缺陷关联模型的方法有许多,如逻辑回归、KNN、支持向量机(Support Vector Machine,SVM)、卷积神经网络(Convolutional Neural Networks,CNN)等,本文选用Xgboost方法的原因是其具有解释性强、准确性较高、抗过拟合和训练速度快、可分布式计算适应工业大数据场景的特点。Xgboost是通过梯度提升树的方法建立一系列决策树来拟合彩色滤光片过程数据与缺陷的关联性。
针对彩色滤光片的多分类问题,使用二叉平衡树作为Boosting方法的基学习器,以指数损失函数计算多分类错误率来确定误差,利用GridSearchCV依次确定树的最大深度、最小叶子值、后剪枝参数、列采样率、样本采样率、正则化系数等。多次试验取最佳参数,对所有彩色滤光片样本进行训练得到过程数据与缺陷关联模型。
(4)特征贡献度评价
在Xgboost训练出的梯度提升树模型中,每一个节点通常将该节点样本子集的分类准确率提升最大的特征作为节点分裂判断条件。分裂后的两个样本子集分类准确率比分裂前更高,样本组成更单一,不纯度更小。采用基尼系数[19]作为决策树的不纯度计算标准:
(5)
(6)
Importance(A)=Gini(D,A)-Gini(D)。
(7)
式中:D为一棵决策树中某一个枝干对应的彩色滤光片样本子集;N为D中缺陷类型的个数;pn为第n个缺陷类型占整个样本子集的比例;D1和D2为D通过某个特征A的值a进行分割得到的两个样本子集。一个特征的重要度通过统计模型决策树中该特征作为判断条件的次数得到。
显然,一个特征的重要度越高,即在越多决策树中作为判断条件出现,其对不纯度的提升越大,其与缺陷的关联性越强。因此,重要度反映了该特征与彩色滤光片缺陷的关联关系,即重要度越大,与缺陷的关联程度越高,特征对应的机台越可能有问题。
(5)反推问题机台概率
因为彩色滤光片样本的每一个特征都来自其加工流程上对应的某一个机台,所以可以将某机台对应的多个特征的重要度累加起来作为该机台的重要性,即问题机台概率,其大小反映了加工机台与彩色滤光片缺陷之间潜在的因果关系。
算法流程如下:
算法2过程数据建模分析。
输入:彩色滤光片样本X,样本特征F,样本特征数t,机台M。
输出:问题机台概率。
1:function过程数据建模分析(X)
2: for X.label=[OK,RB,RW,TB,TW,Other] do
3: X.label←[0,1,2,3,4,5]
标签编码
4:end for
5:F.RSRScore=RSR(X,nambda,iteration,epsion)
6:F.LSScore=LS(X,neighborNumber,tVariance)
7: for i=1→t do
特征筛选
8: if Fi.RSRScore
9: X.filter(Fi)
10: end if
11: end for
12: train,val←split(X, testSize, RandomState)
Xgboost训练
13: params←[gbtree, multi:softmax, gamma, seed]
14: model←xgb.train(train, params, numRounds)
15:preds←model.predict(val)
16:F.importance←model.booster().getFscore()
17:for i=1→t & j=1→m do
18:if Fi.machine=Mjthen
19:MPj←MPj+Fi.importance
20:end if
21:end for
22:return MP
23:end function
3.3 机台警报聚类分析
机台警报信息是能高度反映机台故障的另一个重要数据源。通过机台嵌入式系统和SPC系统检测和分析,可以输出机台警报信息,包括设备代号、警报级别、警报代码、警报内容、受影响彩色滤光片列表、发生时间等。
在实际生产中有成百上千种警报类型,每种类型的数量从几个到几千个不等,导致人工故障定位非常困难。在此情况下提出的基于K-means聚类的警报信息分析方法基于两个假设,一是警报类型代码相近则故障表现相似,二是警报发生时间相近则警报根因相同,使用警报类型代码和发生时间两个维度进行k均值聚类来确定反映同一个机台问题的子类团,找出子类团中的主要警报并反推为其对应的机台,以子类团警报数量的对数为权重综合各子类团求得问题机台概率。具体流程如下:
(1)数据预处理将以年月日时分秒记录的发生时间转化为秒,将警报类型代码转化为可运算的数字,例如将16进制的警报类型代码转化为10进制。
(2)警报聚类首先采用Calinski-Harabasz准则[14]确定最佳类团数量,并判断聚类的有效性。以下函数取最大值时的类团数量即为最佳类团数量:
(8)
式中:B和W分别为类间方差矩阵和类内方差矩阵;N为所有机台警报的个数;C为类团的个数。矩阵B的迹
(9)
式中:ni为第i个类团中警报的个数;mi和m分别为子类团和整个警报样本的中心点。矩阵W的迹
(10)
式中ci为第i个子类团中的不相交子集。
找出最佳类团数量后,通过K-means方法进行聚类得到各个警报子类团,将警报级别为低和高的警报分别记为1分和2分,然后加和计算第i个警报子类团第j个机台的分数Sij,以此得到第i个子类团中的问题机台概率:
(11)
MPi=(MPi1,…,MPiM)。
(12)
为了关注影响程度大、影响时间集中的机台问题,对子类团取其数量的对数作为权重求出整个机台警报对应的问题机台概率
(13)
算法流程如下:
算法3机台警报聚类分析。
输入:机台警报样本A,警报个数n,机台M,机台个数m。
输出:问题机台概率。
1:function机台警报聚类分析(A)
2: A.alarmCode←hexToInt(A.alarmCode)
3:A.alarmTime←timeToSecond(A.alarmTime)
4:A←Standized(A)
预处理
6:CHi←KmeansClustering(A)
7:end for
8: K←argmax(CH)
最佳类团数量
9:for i=1→K & j=1→m do
10: M[j].score←M[j].score+A.levelScore
11:Ci.MP←M.score/sum(M.score)
12: end for
13:Pi←log(ni)
子类团权重
15:return MP
16:end function
17:
18:functionKmeansClustering(A,k)
19:est←Kmeans(k,‘k-means++’)
20: A.clusterLabel←est.fitPredict(A)
类标签
21: C,Ci←est.clusterCenters
全部及子类团中心
22:ni←est.clusterCount
子类团警报数
23:for i=1→k do
24:traceB←traceB+ni*‖Ci-C‖2
25:end for
26:for i=1→k & x∈Cido
27:traceW←‖x-Ci‖2
28:end for
29: CH=traceB/traceW
30:returnA.clusterLabel, CH
31:end function
3.4 信息融合
通过过程数据建模分析和机台警报聚类分析,得到某些机台可能存在问题的两条证据,需要通过信息融合方法综合两条证据判断后,在矛盾的地方进行取舍,得到机台存在问题的概率。因此提出基于D-S证据理论的过程数据与机台警报判断融合方法。
对于以上两条概率证据,辨识框架θ={machinej},j={1,…,M}是参与彩色滤光片生产制造过程的所有M个机台的集合。作为D-S证据的基本概念,基本概率分配(Basic Probability Assignment, BPA)函数定义为

(14)
即辨识框架外的问题概率为0,以及框架内所有机台存在问题的概率之和为1。基于此,两条证据的融合规则可以定义为
(15)
式中:
(16)
为规范化系数;A为θ中任一机台machinej,B和C为θ任一子集。另外,为了应对实际情况中可能出现的高度矛盾的情况,例如对于某一机台j,过程数据分析出的概率为0,机台警报分析出的概率为1,则融合概率为0,而一般人工经验判断会认为取均值0.5,将融合规则定义为
m1(A)⊕m2(A)=R×p(A)+(1-R)×q(A)。
(17)
式中:
(18)
(19)
规范化系数R反映了证据之间矛盾的大小,当R→1即矛盾轻微时,融合结果接近经典D-S证据理论;当R→0即矛盾严重时,融合结果接近平均值。通过使用上述规则融合两条证据,得到所怀疑机台存在问题的综合概率用于故障机台定位。算法流程如下:
算法4信息融合。
输入:证据样本E,机台M,机台个数m。
输出:综合问题机台概率。
1:function信息融合(E)
2: recognitionFrame←[Mi],i=1→m
识别框架
3: for i=1→m do
4:R←R+E[1,i]*E[2,i]
规范化系数
5:end for
6:p,q.MP←zeros((1,m))
7:for i=1→m do
8: pi←pi+E[1,i]*E[2,i]/R
9: qi←qi+(E[1,i]+E[2,i])/2
10:MPi←R*pi+(1-R)*qi
11:end for
12: Uncertainty=1-sum(MP)
不确定性
13:return MP,uncertainty
14:end function
4 应用案例验证
Y公司是一家显示材料制造公司,生产包括多种玻璃基板厚度、不同尺寸范围的近60种彩色滤光片产品,每月生产数万片彩色滤光片成品。然而,机台故障导致的彩色滤光片污染、破片事件时有发生,能否快速定位问题机台并解决机台故障、减少进一步产生缺陷产品,对制造生产活动有巨大的影响。该公司采用的传统质量分析流程在进一步提升质量上存在瓶颈,因此在蓝色光阻层产线上尝试使用本文提出的基于过程数据分析的故障模型。
4.1 过程数据获取
应用模型的蓝色光阻层BL1产线的工艺流程如图4所示,工艺产线包括紫外照射机、洗净机、热盘脱水机、光阻涂布机、预烘烤机、曝光机、显影机、光学检查机、巨观检查机、烘烤机共10个机台。试验样本选取该产线一个月内加工的30 895片彩色滤光片,采集每片彩色滤光片的工艺参数、加工时间、环境信息、缺陷判断等信息,以及10个机台在同一时间段内产生的34 295个机台警报信息。

4.2 实验设计与结果
4.2.1 缺陷类型评价分类实验
对于每一片彩色滤光片,查询光学检查机检测出的RB,RW,TB,TW 4类缺陷信息,每一类缺陷采用S,M,O,OL分别计1,2,10,20分的规则进行计分,取分值最大的作为该彩色滤光片的缺陷评价结果。处理后的玻璃片标签如图5所示。

4.2.2 过程数据建模分析实验
经过数据预处理后,每一行数据对应一片彩色滤光片,包含215个特征,特征值经过Z标准化后处理为0-1自然分布。
通过RSR算法计算出的自表示特征矩阵值为对称矩阵,如图6所示,图中:横纵坐标为215个特征;坐标(i,j)的值表示引入正则化后第i项特征表示第j项特征的能力,值越大说明表示能力越强,两者相关性越大;对角线(i,i)的值表示第i项特征自表示的能力,对角线上的浅色特征对部分其他特征也有较强的表示能力,即与区域内其他特征存在互相耦合的关系,可进行特征聚合以进一步降维。因此第i行的值表示第i项特征表示所有215个特征的能力,该行的二范数表示第i项特征的综合表示能力,其中冗余特征的综合表示能力接近0。为过滤值显著为0的特征,并保留合适的特征数量,取RSR阈值为10-3。最终每个特征的RSR重要程度如图7所示,筛选后的特征数量为189个。接着通过LS算法计算LS重要度(如图8),根据LS算法的值越小越好的特性,取LS筛选阈值为0.1,筛选后的特征数为149个。


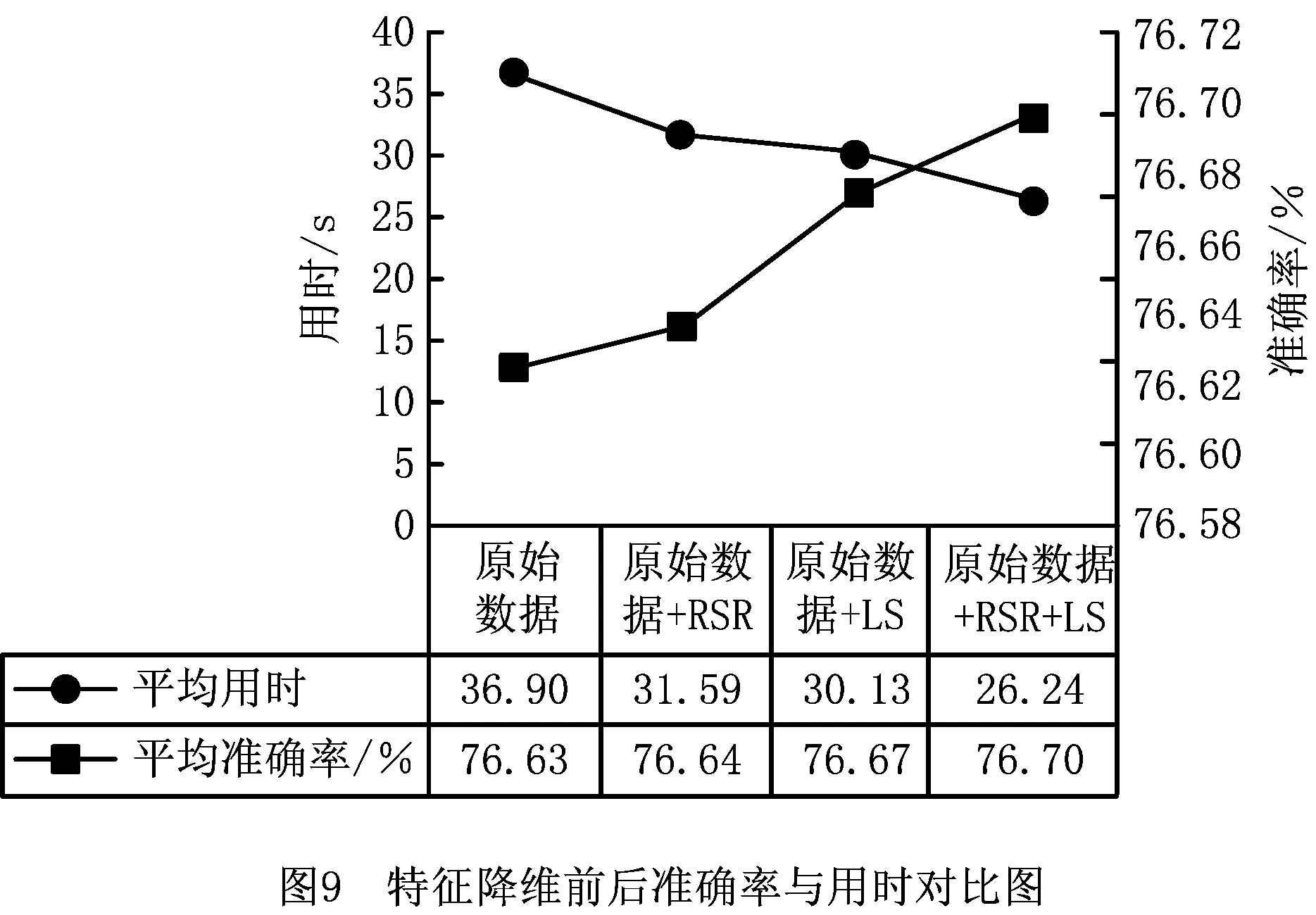
完成特征降维后使用Xgboost训练过程数据与滤光片缺陷的关联模型。设定学习目标为multi:softmax,标签类别数为6,以gpu_exact作为树方法,mlogloss作为评价函数。通过GridSearchCV依次确定学习速率为0.1,树最大深度为3,叶子最小权重为5,γ为0.1,reg_alpha和reg_lambda正则化系数均为3。如图9所示,通过多次实验,确定采用RSR和LS特征选择后的数据集训练出的模型,在准确率提升0.07%的基础上使训练时间减少了28.9%,有效地提高了模型的训练速度。
关联模型由一系列梯度提升决策树组成,训练后的决策树如图10所示。对于每一个测试样本,从每一棵决策树的根节点开始,根据根节点判断条件选择走向左子节点还是右子节点,直到走到叶子节点,每一棵决策树获得的叶子节点值之和即为预测的类别,从而实现了基于彩色滤光片过程数据的缺陷预测。统计每个特征在一系列决策树中作为判断条件的出现次数,得到每个特征对彩色滤光片缺陷的贡献度,如图11所示。可见f4特征的贡献度最高,f51次之,然后是f21,f22,f18。对产线上每一个机台所属特征的贡献度求和并归一化处理后,得到各个机台的可疑概率,如表3所示。由表3可见,曝光机(EXP)是最有可能存在问题的机台,其概率为58%,其和洗净机(CLN)、光学检查机(AOI)、烘烤机(OVN)一起占90%以上,意味着如果滤光片突然出现大量缺陷,则极有可能是这4个机台存在一个或多个问题。


表3 过程数据的可疑机台概率

序号机台重要度序号机台重要度1EXP0.587 5106COA0.025 7442CLN0.178 3007DHC0.015 8133DEV0.015 8138DUV0.012 3554AOI0.084 3569PHC0.001 0225OVN0.078 39010SMA0.000 698
4.2.3 机台警报聚类分析实验
在现实生产中,某些机台故障常会导致一段时间内大量出现某类滤光片缺陷,同时产生多个类型相近的警报。例如由于机台冷却水泄露导致的彩色滤光片大面积圆形水渍污染,会在一段时间内使滤光片大量检测出RB类型缺陷,同时故障机台会经常发出与冷却相关的冷却水流量异常100023A0、系统工作温度异常100023B5等警报。因此基于警报类型代码近似及发生时间相近的警报代表同一个机台故障的两个假设,使用警报类型代码和发生时间两个维度进行k均值聚类以确定反映同一个机台问题的子类团。
首先通过数据预处理对时间字段和警报类型进行转化。例如,原时间“03-11月-17 02.53.10.000000上午”转化为“564893590” s。原警报类型代码是8位的16进制数,因为代码编写需要保留余量,目前只使用了第1位和后4位数,而且有意义的警报类型代码相对稀疏,所以需要省略未使用的部分类型代码,使警报类型间隔不会过大,以保证聚类的有效性;同时,因为16进制不方便计算欧式几何距离,所以转化为十进制,最终转化规则为A000BCDE→3·A·163+B·163+C·162+D·16+E,例如“100012DA”转化为“21210”。经过0-1标准化后,使用CH(Calinski-Harabasz)准则确定合适的类团数量。如图12所示,一开始CH评分的增长主要得益于类间方差的增加,但随着类团数的增加,类团数的影响增大并导致CH评减少。CH评分在类团数量为10左右时取得最大值,此时是聚类效果与聚类数的良好折中,因此类团数为10是该机台警报样本集的最优类团数。使用K-means聚类,得到每个警报对应的警报类团标签,如图13所示。每个类团对应一个问题子集,类团内各个警报的数量反映了其在该问题子集中的重要性,间接反映了警报来源机台存在问题的概率。取警报级别“L”为1,“H”为2,在每一个警报类团中对10个机台(AOI,CLN,COA,DEV,DHC,DUV,EXP,OVN,PHC,SMA)分别计分。对于每一个警报类团,以评分除以总分得到每一个警报类的机台概率,因为更希望关注持续时间长、跨越多个类团的问题,所以以警报类团的警报数量的自然对数作为类团权重,从而削减短时间随机波动问题造成的干扰。最终得到的机台警报生成概率如表4所示。


表4 机台警报的可疑机台概率

序号机台重要度序号机台重要度1AOI0.330 8576DEV0.037 6472COA0.317 6377OVN0.009 1893DUV0.171 3318PHC0.008 3024EXP0.079 3139CLN0.005 4085DHC0.037 64710SMA0.002 667
4.2.4 信息融合实验
将BL1产线上的10个机台作为D-S信息理论的识别框架,即有
θ={AOI,CLN,COA,DEV,DHC,DUV,EXP,OVN,PHC,SMA}。
根据过程数据和机台警报得到的可疑机台概率,使用改进的D-S证据理论进行信息融合,中和证据中矛盾的部分,得出疑似问题机台的综合概率,如表5和图14所示。可以看出,过程数据分析出的结果认为问题主要集中在EXP和CLN,机台警报分析出的结果认为问题主要集中在AOI和COA,通过信息融合给出一个综合判断意见,确定了EXP,AOI,COA的排查顺序,并给出了8%的不确定性以供参考。同时,信息融合可以方便地引入其他模型,得到更多怀疑机台存在故障的证据进行综合判断,具有强大的扩展能力。结合实际应用情况,还可以对各个证据引入不同的权重,例如过程数据的证据实际使用效果好,经常命中问题机台,可以相应地增加其权重,使得综合判断更加准确可靠。

表5 疑似问题机台的综合概率

4.3 结果分析
由实验结果可知,本文提出的基于过程数据分析的彩色滤光片生产线故障机台定位方法,能够对数万片滤光片、数百个特征的样本进行分析,得出疑似问题机台的综合概率,其基于数据的流程标准统一,符合技术人员由经验规律推导出的结果。整个流程可以通过系统自动完成,将传统人工查找的几十分钟到几小时的搜索时间缩短到10 min以内,从而大大提高故障机台定位的效率,缩短产线非计划停机时间,增加企业利润。
5 结束语
本文分析了传统故障定位方法在工艺复杂的彩色滤光片产线上遇到的瓶颈,提出基于过程数据分析的彩色滤光片生产线故障定位模型,基于缺陷类型和面积权重评分确定多缺陷共存时的滤光片主缺陷标签,并通过Xgboost集成方法训练加工过程数据与缺陷的关联模型,以信息熵增益确定各个过程数据源贡献度;基于K-means聚类机台警报划分每个故障问题子集,以警报来源反推机台故障概率,进而以D-S证据理论融合两者判断,确定综合问题机台概率。
本文提出的针对多种过程数据源得出故障定位判断并进行信息融合的故障定位模型,改进了传统模型在分析能力、判断标准及定位速度上的缺陷或不足,提升了故障定位的有效性与时效性,特别是在制造业从自动化、信息化向数字化、网络化转型的新时代,面对未来智能制造产生的海量数据,人工判断故障已不现实,而本文基于数据进行故障定位将成为未来智能运维中的一环,具有巨大的应用前景。同时由于生产线上加工参数和机台警报的通用性与普遍性,本文模型可以推广到其他复杂电子产品的生产线,具有广泛的实际应用价值。
