非周期长码直扩信号PN码盲估计
2020-06-12喻盛琪张天骐赵健根
喻盛琪,张天骐,赵健根,张 天
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.重庆邮电大学 信号与信息处理重庆市重点实验室,重庆 400065)
0 引 言
直接序列扩频(direct sequence spread spectrum,DSSS)作为一种重要的调制技术,因其具有较强的抗干扰能力和保密性能,以及低截获率等优点而广泛应用在电子对抗,航空航天,通信监测等通信领域[1]。在非协作通信中,由于发射的是经过PN码调制后频谱得到展宽的信号,而在接收端需要知道用于扩频的PN码才能实现信号的盲解扩,因此对DSSS信号PN码的盲估计研究已成为DSSS通信系统参数估计的研究热点[2]。非周期长码直扩信号最大特点就是用一周期的PN码调制非整数个信息码元,PN码的周期性遭到严重破坏,盲估计难度大。就公开发表的文献来看,对非周期长码直扩信号的PN码盲估计研究较少。
针对长码直扩信号的PN码盲估计研究,文献[3-5]将长码直扩信号建模为多用户短码直扩信号模型,实现了PN码的有效估计,并根据特定约束条件完成了PN码片段的拼接,但是都没能有效解决在拼接时产生的相位模糊问题。文献[6]先用聚类方法对PN码分段估计,再用游程检验进行恢复,解决了相位模糊问题,但随着数据量的增大,算法复杂度随之升高,性能急剧下降,以上文献所使用的方法只能对周期长码直扩信号PN码进行盲估计。对非周期长码直扩信号的PN码盲估计,使用较多的方法就是文献[7-11]中的m序列三阶相关函数法,但是该方法只适用于PN码为m序列的情况,而对于Gold等其它PN码序列不再适用。其次就是将非周期长码直扩信号建模为含有缺失数据的短码直扩信号[12],但是当缺失数据比例较大时,估计性能严重下降。
针对上述问题,本文提出基于分段特征值分解和梅西算法的非周期长码直扩信号PN码盲估计方法。首先,在伪码周期内根据扩频调制比对信号进行非重叠分段。然后,利用分段特征值分解估计出PN码片段并进行拼接,其中每个片段都会独立地取正负号。最后,从二进制伪随机码的产生规律及特性出发,通过滑动搜索窗,利用梅西算法得到PN码的生成多项式,消除在拼接时产生的相位模糊,从而估计出正确的m序列和Gold序列。
1 信号模型
不失一般性,假设信号的PN码周期及码片速率已通过文献[13]得到,则接收机端接收的基带非周期长码直扩信号经码片速率采样后,可以表示为
(1)
其中
(2)
(3)

为方便起见,假设根据文献[4]已经完成信号的盲同步,即τ=0,此时式(1)可记作为
y(n)=s(n)+v(n),n=1,2,…,N
(4)
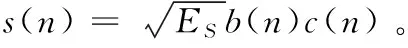
2 算法原理
2.1 信号分段特征值分解


图1 分段特征值分解
定义Yj如下
(5)
其中
(6)
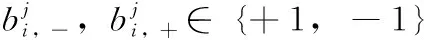
对Yj的自相关矩阵Rj进行特征值分解,由式(5)可得信号自相关矩阵Rj的估计值为
(7)
由于s和v相互独立,当M→∞时,式(7)中第一项和第四项趋于0,则式(7)可进一步化简为
(8)
即
(9)
将(6)式代入式(9)中得
(10)

(11)
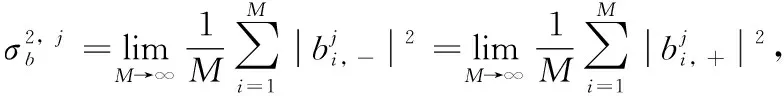
(12)

由矩阵分解知识可知,式(12)就是矩阵Rj的特征值分解式,即
(13)
其中
(14)
(15)
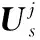
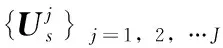
(16)
由式(16)可看出,根据特征值分解法估计得到的PN码的每一段都可以独立地取正负号,因此存在分段相位模糊的问题,这使得输出序列有2J种选择,要从2J种选择中恢复出一整周期完全正确的PN码绝非易事。下面通过梅西算法求PN码生成多项式从而对PN码进行恢复,消除相位模糊。
2.2 梅西算法
梅西算法是用来求产生二元序列的最短线性移位寄存器的一种迭代算法[14],即通过归纳的方法从校验子中找出一系列的移位寄存器:〈fnx,ln〉,n=1,2,…,B,使每个〈fnx,ln〉都是产生序列前n项的最短移位寄存器,最终得到的〈fBx,lB〉就是产生B长二元序列的最短线性移位寄存器,其中fBx为寄存器的联结多项式,lB为寄存器的级数,也是多项式的阶数。利用梅西算法求给定二元序列的最短线性移位寄存器的过程如下:
任意给定一个序列a0,a1,…aB-1,用数学归纳法定义一系列的寄存器〈fnx,ln〉,n=1,2,…,B。
(1)取初始值:f0x=1,l0=0。
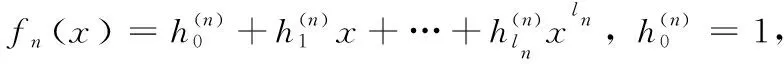
(17)
其中,dn为第n步差值,并区别以下两种情形:
1)若dn=0,则令
fn+1x=fnx,ln+1=ln
(18)
2)若dn=1,则需要区分以下两种情形:
当l0=l1=…=ln=0,取
fn+1x=1+xn+1,ln+1=n+1
(19)
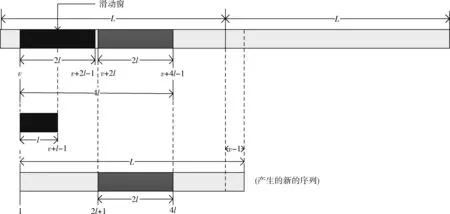
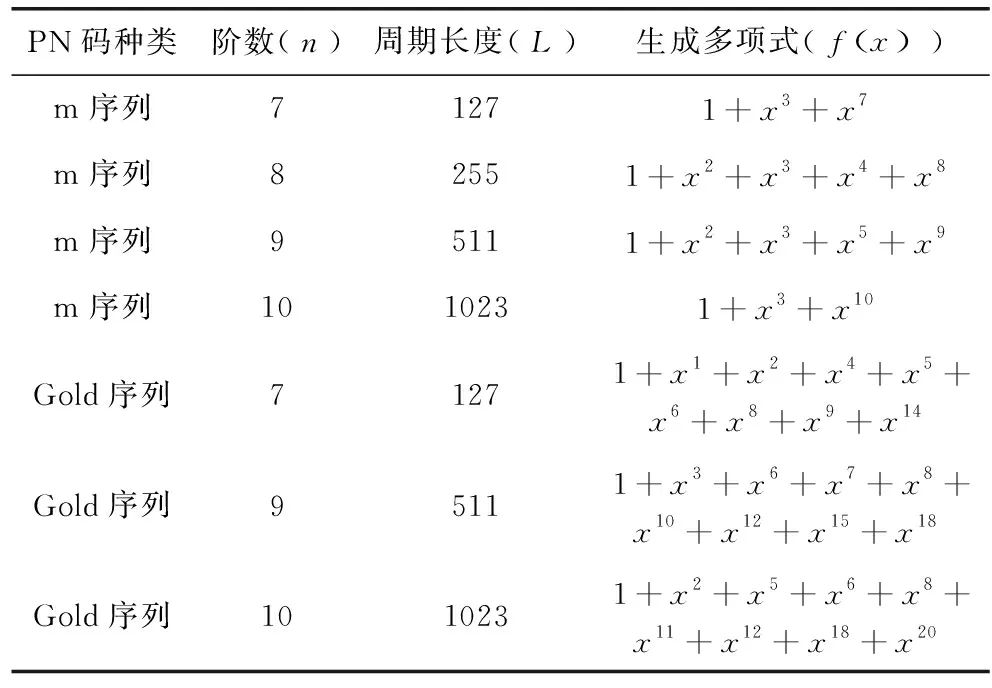
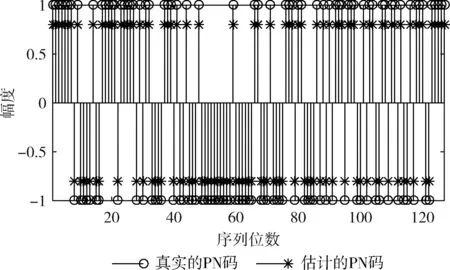
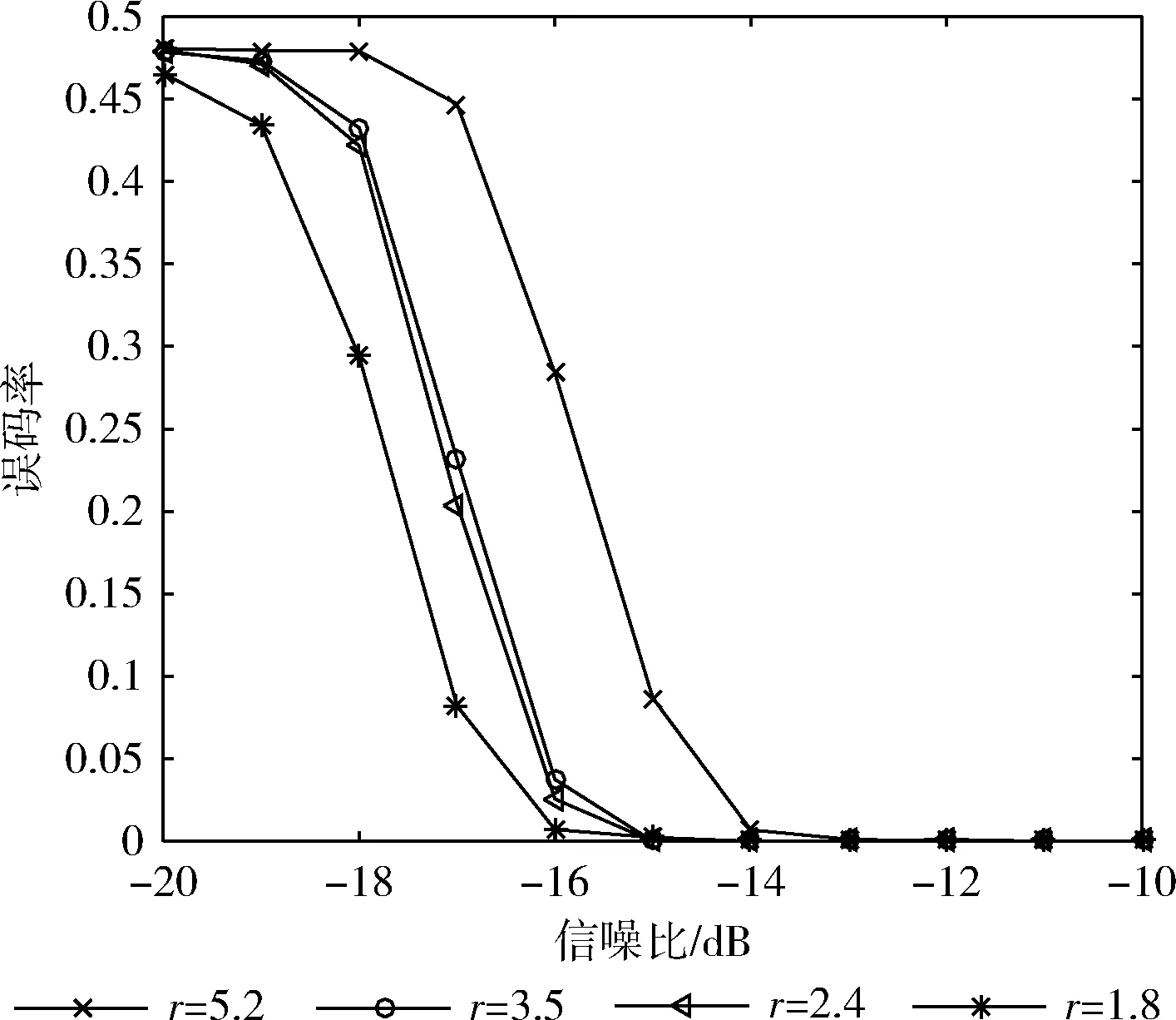
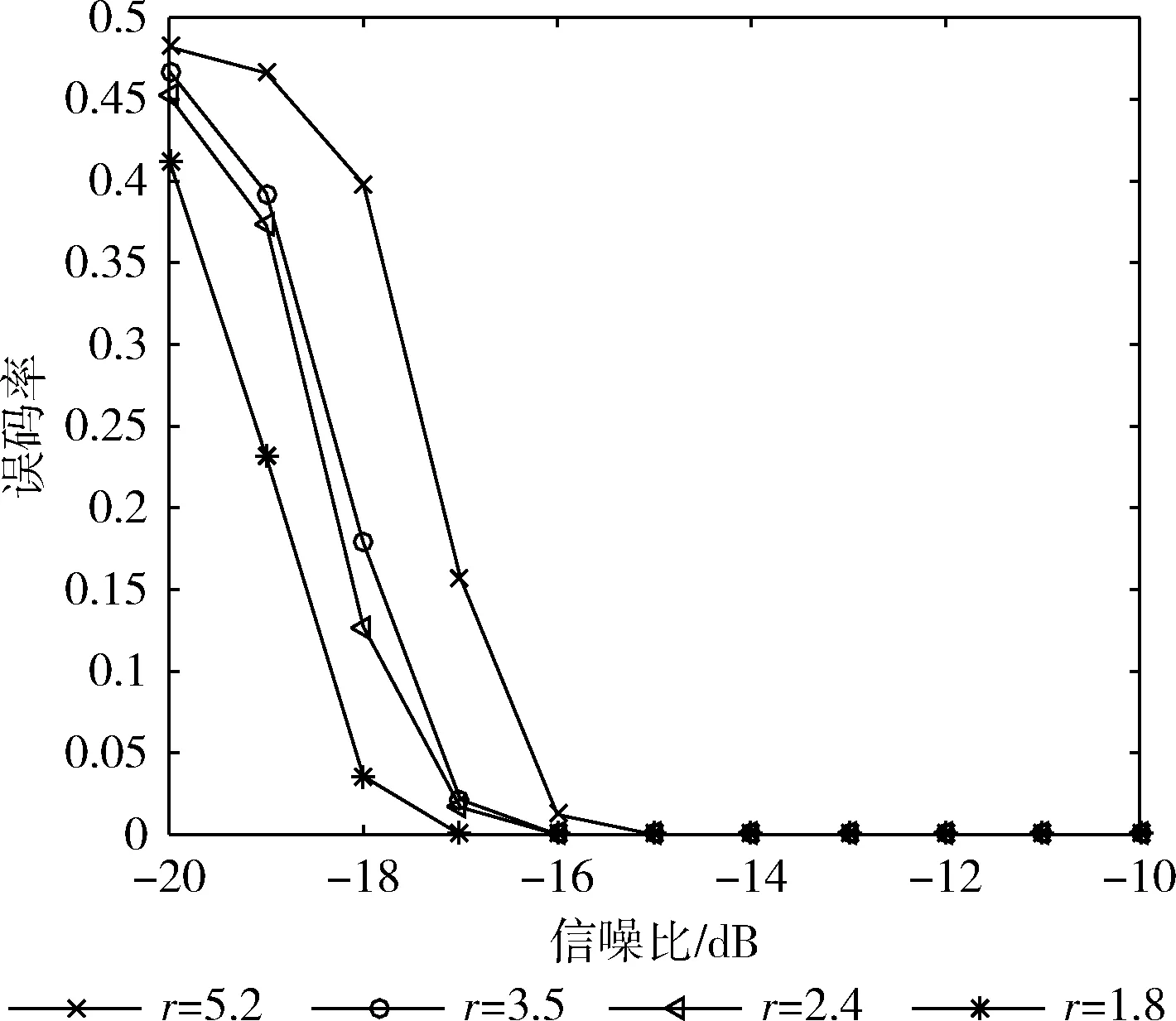
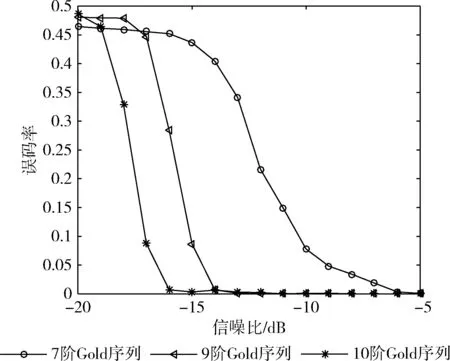
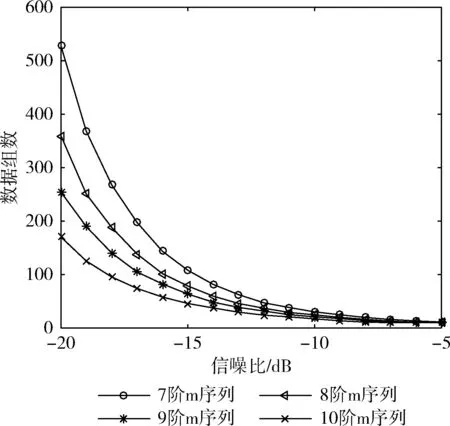
当有m0≤m fn+1x=fnx+xn-mfmx (20) ln+1=maxln,n+1-ln (21) 通过该过程最后得到的〈fBx,lB〉便是产生序列a0,a1,…aB-1的最短线性移位寄存器。其算法流程如图2所示。 扩频通信中使用的PN码大部分是由线性反馈移位寄存器(LFSR)产生的二进制伪随机序列,如式(22)所示 ak=hlak-l+hl-1ak-l+1+…+h2ak-2+h1ak-1 (22) 即PN码序列的第k位,可由前l位线性表示,其中,l为生成多项式阶数。h0,h1,…hlh0=1为生成多项式的系数。 根据文献[14]可知,利用梅西算法求无误码(跟原序列相比完全同相或反相)的二进制伪随机序列的生成多项式时,不需要知道完整的周期序列,只需要知道其中连续正确的2l位即可。以m序和Gold序列为例,当截取的序列长度大于或者等于2l时,利用梅西算法均可100%求出该序列的生成多项式。 图2 梅西算法流程 根据这一结论,把式(16)作为待求生成多项式的序列,如图3所示,按照一定的步长滑动搜索一个无误码矩形窗(窗长为2l),利用梅西算法求其对应多项式,该多项式就是m序列或Gold序列生成多项式。由式(22)可知,根据求得的生成多项式和矩形窗中连续的l位,可以产生一周期长度的新的序列,然后选取滑动窗后的部分序列同与之对应的部分新序列相比较,通过判断其对应位置相同的概率是否达到一个阈值,来判断求得的生成多项式是否正确,从而判断出产生的新序列是否为恢复的PN码序列。显然,阈值越大,恢复的PN码序列误码率越低,但滑动窗需要滑动搜索的次数也越多。通过合理设置阈值,可以达到不同的实验要求,本文将阈值设置为80%,其实验效果将在后面给出。 综上所述,利用梅西算法识别序列生成多项式从而恢复出无相位模糊的PN码的具体步骤如下: 步骤1 将式(16)作为接收序列; 步骤2 选取接收序列的第v位(假设v的初始值为5,v≤L-4l-4)到第v+2l-1位,也就是接收序列中连续的2l位,作为一个矩形滑动窗,利用梅西算法求序列的生成多项式; 步骤3 根据生成多项式及矩形窗中连续的前l位,产生一周期长度的新的序列; 步骤4 将新序列的第2l+1位到第4l位与接收序列的第v+2l位到v+4l-1位进行比较,如果对应位置相同的概率达到80%,那么求得的多项式就是PN码序列生成多项式,然后执行步骤5,恢复出对应的序列;如果对应位置相同的概率未达到80%,滑动矩形窗,将v的值加5,重复步骤2、步骤3、步骤4,直到这两段对应位置相同; 图3 生成多项式求解 步骤5 根据序列的周期性,对新的序列向右循环移动v-1位,就可以恢复出一整周期不存在相位模糊的PN码。 实验中,信息码采用BPSK调制的随机序列;PN码采用由线性移位寄存器产生的m序列和Gold序列,其具体阶数、周期长度及生成多项式见表1;误码率计算公式为 (23) 式中:nm表示第m次蒙特卡洛仿真中估计的PN码误码个数,M表示蒙特卡洛仿真次数,L表示PN码的周期长度。 表1 仿真实验选取的PN码 实验1:验证本文方法的可行性。PN码采用表1中的7阶Gold序列,设接收信号样本长度N=200L,G=53,扩频调制比r=L/G=2.4,信噪比SNR=-10 dB,利用分段特征值分解对PN码进行估计如图4所示,利用梅西算法对PN进行恢复如图5所示。 图4中估计的PN码是各段PN码按式(16)进行组合得到的一整周期的PN码序列的估计值(未取符号函数),由于各子段的码序列是独立估计的,组合后就会出现分段相位模糊的情况,从图4可看出,估计出的第2子段PN码(第54位到第106位)的相位与对应的真实PN码的相位完全反相。 图5是特征值分解结合梅西算法估计出来的PN码估计值,为了便于和真实PN码进行比较,在图5中将估计的PN码幅度值缩小为原来的0.8倍。由图5可知,图4中存在相位模糊的PN码经过梅西算法处理恢复后与真实PN码完全相同,不再存在相位模糊的问题。 实验2:比较不同扩频调制比对PN码的估计性能的影响。PN码分别采用表1中的9阶Gold序列和m序列,接收信号样本长度N=200L,扩频调制比分别为r=1.8,r=2.4,r=3.5,r=5.2,信噪比变化范围从-20 dB~-10 dB,变化间隔为1 dB,蒙特卡洛仿真400次得到PN码的误码率曲线如图6和图7所示。 图4 估计PN码与真实PN码对比 图5 估计PN码与真实PN码对比 图6 不同扩频调制比下9阶Gold序列误码率 图7 不同扩频调制比下9阶m序列误码率 从图6和图7中可看出,无论是对m序列还是Gold序列的估计,r越大,对PN码的周期性破坏越大,分段特征分解的性能越差,最终恢复出的PN码序列的误码率也就越高。 对比图6和图7还可以看出,在相同的扩频调制比和相同阶数下,估计的m序列的误码率低于Gold序列的误码率。这是因为产生m序列的LFSR的级数是产生Gold序列的LFSR的级数的一半,在利用梅西算法进行m序列恢复时,矩形滑动窗的长度及相比较的数据长度也是Gold序列的一半,这样在一个PN码周期长度内,矩形窗具有更多的滑动次数,对比得到的数据也越精确,从而恢复出序列的误码率也就越低。 实验3:比较不同阶数对PN码的估计性能的影响。设置接收信号样本长度N=200L,扩频调制比分别为r=5.2,PN码分别采用表1中的7、9、10阶Gold序列以及7、8、9、10阶m序列,信噪比变化范围从-20 dB~-5 dB,变化间隔为1 dB,蒙特卡洛仿真400次得到PN码的误码率曲线如图8和图9所示。 从图8和图9中可以看出,不同阶数下,随着信噪比的增加,估计的m序列和Gold序列误码率逐渐减少,在信噪比SNR=-15 dB和SNR=-17 dB下,可以实现对10阶Gold序列和10阶m序列的正确估计。在相同信噪比下,阶数越高的序列恢复出的PN码序列的误码率越低。这是因为阶数越高,序列的周期长度越长,算法处理的数据越多,包含有用信息越多,估计出的序列越准确,但数据的计算量也就越大,算法执行时间也就越长。 图8 不同阶数的Gold序列误码率 图9 不同阶数的m序列误码率 实验4:比较在不同阶数下,正确估计出PN码序列所需要的数据组数,每组数据长度为PN码周期长度L。设置扩频调制比r=2.4,采用的PN码序列及信噪比变化范围同实验3,蒙特卡洛仿真300次,得到不同阶数下完全正确地估计出PN码所需要的数据组数随信噪比变化曲线如图10和图11所示。 图10 Gold序列数据组数与信噪比关系 图11 m序列数据组数与信噪比关系 从图10和图11可以看出,不同阶数下,随着信噪比的增加,完全估计出PN码序列所需要的数据组数在不断减少;在信噪比SNR=-5 dB下,大约只需要10组数据就能完全估计出各阶的Gold序列和m序列。在同一信噪比下,阶数越高,序列周期长度越长,完全估计出PN码序列所需要的数据组数越少。 针对非周期长码直扩信号PN码盲估计问题,本文提出了特征分解与梅西算法相结合的方法。首先利用特征值分解估计出每一小段的PN码,对每一小段PN码进行拼接得到一整周期长度的PN码。对于拼接产生的相位模糊问题,利用梅西算法估计PN码生成多项式,根据生成多项式对序列进行恢复,从而得到完全正确的PN码。实际上该方法适应于多种PN码的估计,仿真实验以常用的m序列和Gold序列为例进行研究,结果表明,本文方法能够在较低信噪比下对这两种序列进行有效估计,并且序列的阶数越高,性能越好。2.3 PN码生成多项式求解

3 仿真实验与分析



4 结束语
