基于弹性网的深度去噪自编码器异常检测方法
2020-06-12谭敏生李行健
谭敏生,吕 勋,丁 琳,李行健
(南华大学 计算机学院,湖南 衡阳 421001)
0 引 言
与传统有线网络相比,无线网络更容易受到恶意攻击。由于无线通信中的传感节点缺乏监督,恶意攻击很容易入侵系统并浪费大量资源。为此,学者们从各个角度对异常检测方法[1,2]进行了研究,如多尺度主成分分析算法(MSPCA[3])、支持向量机(SVM)、K最近邻算法(K-NN)等。深度学习作为一种很有前景的解决方案[4,5],在处理复杂大规模数据方面有着更出色的性能,一方面,深度学习算法[6]可以揭示输入数据之间更深层的关系;另一方面,深度学习算法具有更强大的特征提取和表示能力,同时尽可能地保留有关信息。自编码器[7]作为深度学习的一种新颖降维方法[8],通过使用神经网络[9]可以找到最佳子空间,捕获特征之间的非线性相关性。例如,V.L.Cao等[10]提出了结合自编码器和密度估计的异常检测方法;Zong等[11]提出了用于无监督异常检测的深度自编码高斯混合模型,能避免陷入局部最优;Zhou等[12]提出了一种鲁棒深度自编码器(RDA)来用于异常检测,但是误检率较高;Hong等[13]提出了一种用于高维数据的混合半监督异常检测模型,降低了计算复杂度;L.Bontemps等[14]提出了基于长短时记忆递归神经网络(LSTM-RNN)的集体异常检测方法,但存在过拟合现象。
现有研究成果在处理维度不高的数据时,效果不错,但在处理多元和高维数据时,算法的误报率较高,性能达不到预期效果。为此,本文提出一种基于弹性网的深度去噪自编码器异常检测方法,用正常数据对基于弹性网的深度去噪自编码器进行训练获得数据的重构误差阈值,来对数据进行异常检测。
1 深度自编码器
自编码器(AE)是一种无监督[15]的三层神经网络,将输入压缩成潜在的空间表征来重构输出,利用反向传播算法使输出值尽可能等于输入值。自编码器由编码器和解码器构成,如图1所示。

图1 自编码器模型
深度自编码器(DAE)是由多个自编码器端到端连接组成的神经网络,前一层自编码器的输出作为下一个自编码器层的输入,以获得输入数据的更高级别特征表示,逐步将特定特征向量转换为抽象特征向量,实现从高维数据空间到低维数据空间的非线性转换。深度自编码器结构如图2所示。

图2 深度自编码器结构
深度自编码器的工作过程可分为两个步骤:编码和解码,这两个步骤可定义为:
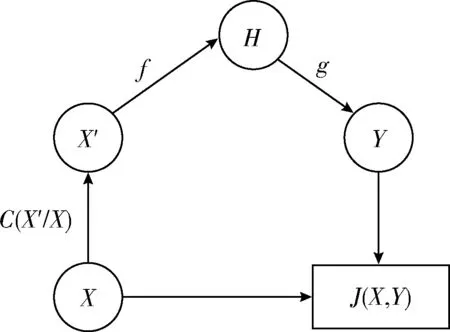
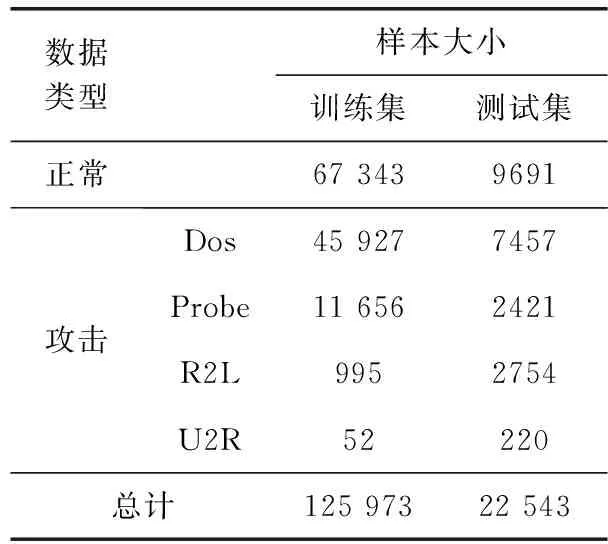
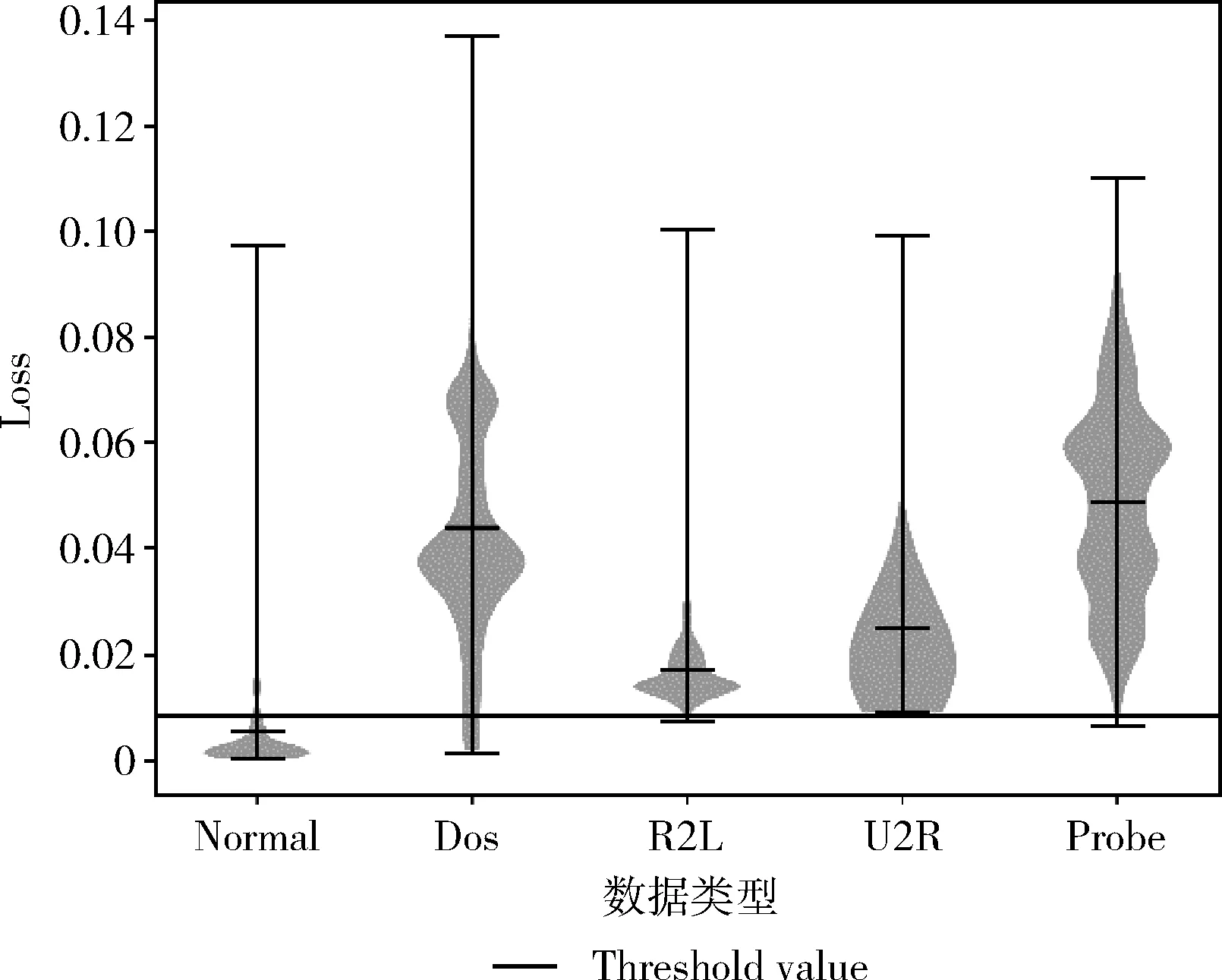
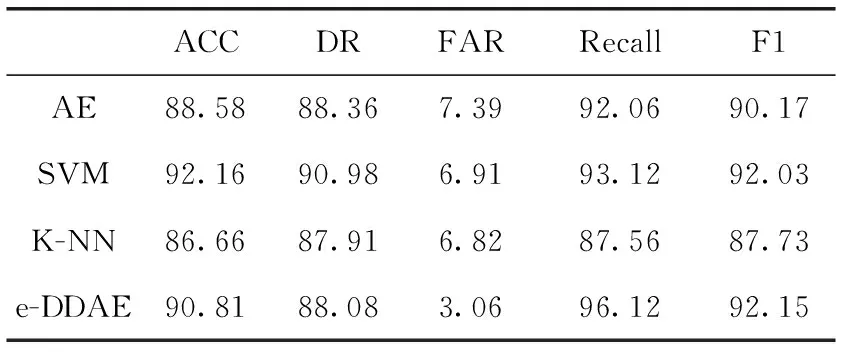
编码:输入向量(Xn∈Rd)被压缩成构成隐藏层的mm (1) 其中,X为输入向量,θ为参数Winput,φinput,W表示大小为m×d的编码器权重矩阵,φ表示维数为m的偏置向量。 解码:将得到的隐藏层输出Hi解码回原始输入空间Rd,映射函数如下 (2) 其中,解码器的参数θ′=Whidden,φhidden,Y是输入数据后的重构向量,fθ(·)和gθ′(·)分别表示隐藏层神经元和输出层神经元的激活函数,激活函数是非线性函数,用以揭示输入特征之间的非线性相关性。本文采用relu函数和tanh函数作为激活函数,relu函数和tanh函数表达式如式(3)和式(4)所示 (3) relu(x)=max(0,x) (4) 通过训练自编码器来重构原始数据,调整编码器和解码器的参数,使输出重构数据和输入数据之间的误差最小化,即误差函数最小,把编码器最后一层隐藏层的输出数据作为输入的最佳低维数据。重构误差函数JE(W,φ)用式(5)所示均方差函数表示 (5) 深度自编码器是由多个自编码器端到端连接而形成的神经网络,相比简单的自编码器,深度自编码器能更好的逐层学习原始数据的多种表达,刻画更复杂的特征。θ,θ′用均方误差函数来优化深度自编码器的参数 (6) 其中,n表示样本数量,JE表示均方差函数。将训练集中一部分标签为“正常”的数据去训练基于弹性网的深度去噪自编码器,对重构误差进行阈值处理,利用正常数据与异常数据的重构误差值,来对不同数据特征进行分类。 为了提高网络的泛化能力和抗扰动能力,使结构风险最小化,在深度自编码器的隐藏层输出值加入某种约束,降低不重要特征的权重。一般在自编码器中加入正则化,可用L1范数来正则化,L1范数符合拉普拉斯变换,是指权值向量W中各个元素的绝对值之和,可以产生稀疏权重矩阵即产生一个稀疏模型,用于特征选择,这样式(6)更新为如下表达式 (7) 也可以利用L2范数来正则化,L2范数符合高斯分布,是完全可微的,指权值向量W中各个元素的平方和然后再求平方根,也就是欧几里得距离之和,这样式(6)更新成如下表达式 (8) 而弹性网的正则化是L1和L2惩罚函数的线性混合,所以基于弹性网的深度自编码器的重构误差函数如式(9)所示 (9) 利用参数λ2可以控制稀疏性,利用参数λ1可以防止网络过拟合,最小化重构误差,提高网络的泛化能力。 自编码器是高度非线性的,通过在输入层添加噪声,可以提高自编码器的重构能力。如图3所示,引入一个损坏过程C(X′/X)将输入X进行处理后产生一个损坏样本X′,然后再对数据X′进行重构。本文使用加性高斯噪声作为对输入数据进行处理,通过引入噪声使学习到的特征更具鲁棒性,从而给深度自编码器带来更好的性能。 图3 去噪自编码器训练过程 考虑到网络中存在约束,对不同参数使用不同的学习速率,例如降低不频繁特征的更新频率。然而,大多数传统流行的梯度下降算法包括随机梯度下降和小批量梯度下降,对网络中所有需要更新的参数使用相同的学习速率,使得难以选择合适的学习速率以及容易陷入局部最小。因此,为了训练更好的深度网络,本文使用自适应矩估计(Adam)梯度下降算法[16]来实现不同参数的动态自适应调整,Adam算法通过计算梯度一阶矩估计mt和二阶矩估计vt来实现不同参数的动态调整,调整方法如式(10)~式(15)所示 mt=β1mt-1+(1-β1)gt (10) (11) (12) 计算mt和vt的偏差矫正 (13) (14) (15) β1和β2分别表示一阶和二阶的矩估计指数衰减率,gt表示损失函数中时间步长t的参数梯度,γ表示更新的步长,ξ表示采用一个很小常数来防止分母为零。 本文把[122-110-90-10-90-110-122]作为深度网络的结构。由于输入数据是122维,所以把输入层的神经元数设为122,在神经元数为10的隐含层中采用relu函数作为激活函数,其余层的激活函数采用tanh函数。 在训练阶段使用标签为“正常”的数据进行训练,则相应的测试集中正常数据的重构误差会较小,而异常数据将具有相对较高的重构误差。通过对重构误差进行阈值处理,可以对恶意数据进行分类,如式(16)所示 (16) 基于弹性网的深度自编码器网络异常检测算法(e-DDAE)主要步骤如下: 步骤1 数据预处理。使用独热(one-hot)编码对NSL-KDD数据集进行符号特征数值化,然后对数据进行最小最大归一化处理,将所有特征转换为[0,1]的范围。 步骤2 构建弹性网正则化的深度自编码器。根据式(7)-式(9),在深度自编码器的损失函数中加入弹性网正则化即L1和L2范数的线性混合,使得重构误差函数最小化。 步骤3 对弹性网正则化的深度自编码器的输入数据加入高斯噪声,提高深度自编码器重构能力,根据式(10)-式(15),用Adam算法对网络进行优化,对输入数据进行降维重构,把输入数据压缩降维到10维,再重构为122维数据。 步骤4 自编码器训练。在训练阶段,抽取NSL-KDD训练集中90%的标签为“正常”数据样本作为基于弹性网的深度去噪自编码器的训练集,剩下的10%的“正常”数据作为验证集,并结合BP算法来训练基于弹性网的深度去噪自编码器,用验证数据集进行测试,使其能够捕获正常数据的特征。通过训练基于弹性网的深度去噪自编码器,构建正常数据的重构误差阈值。 步骤5 自编码器检测。将测试数据集输入到自编码器网络中并根据式(16)进行分类,把训练集的重构误差作为异常阈值,重构误差低于阈值的数据将被分类为正常,高于阈值的数据则被分类为异常。 使用NSL-KDD数据集来评价基于弹性网的深度去噪自编码器异常检测算法(e-DDAE),NSL-KDD数据集在KDD99数据集基础上得到了改进,消除了KDD99数据集中的冗余数据。NSL-KDD数据集包含125 973个训练样本和22 543个测试样本,包括拒绝服务攻击(Dos)、探测攻击(Probe)、远程到本地攻击(R2L)、用户到根攻击(U2R)这4种攻击样本类型,具体分布见表1。 表1 NSL-KDD数据集攻击数目和分类 NSL-KDD数据集包含41个属性特征,使用独热(one-hot)编码来对数据集数字化。NSL-KDD数据集的符号特征包括“Protocol_type”,“Service”和“Flag”,其中“Protocol_type”包括TCP,UDP,ICMP这3种不同的协议类型,“Service”包括70种不同的符号特征值,“Flag”包括11种不同的符号特征值。因此,在完成数字化处理后,NSL-KDD数据集的41维特征数据扩展为122维。 为了将特征统一量纲,提高算法收敛速度和精度,使用式(17)归一化方法来处理NSL-KDD数据集中的特征值,将特征线性映射到[0,1]区间上。xmax和xmin分别表示原始特征最大值和最小值,x表示原始特征值 (17) 本文使用基于混淆矩阵的方法来评估实验结果,混淆矩阵的定义见表2,TP(true positive)表示预测为正常的正常数据,TN(true negative)表示预测为攻击的攻击数据,FP(false positive)表示被预测为正常的攻击数据,FN(false negative)表示被预测为攻击的正常数据。 表2 混淆矩阵 本文使用的度量指标主要包括ACC(准确度)、FAR(误报率)、DR(检测率)、Recall(召回率)、F1值(F1 score),定义如下 (18) (19) (20) (21) (22) 实验采用Adam优化算法,学习率取0.001,batch-size设置为128,网络迭代次数设置为20,惩罚项系数λ1=0.0001,λ2=0.00001,β1=0.9,β2=0.999,ξ=10e-8。 e-DDAE算法构建一个深度去噪自编码器,在损失函数中加入弹性网正则化,抽取训练集中标签为“正常”的数据来训练网络以获得重构误差阈值,利用阈值和自编码器来对测试集数据进行分类。实验通过正常数据和异常数据的重构数据值的分布来评估e-DDAE算法的有效性。 图4的提琴图显示了测试集中所有数据样本的重构损失值的分布,从图中阴影部分也就是数据的分布密度可以明显看出,异常数据(攻击数据)的重构值基本要高于阈值,而正常样本的数据要低于阈值。 图4 不同数据重构误差值分布 图5是NSL-KDD数据集中不同训练集比例下5种不同数据重构误差值,可以明显看出,随着训练集比例的增加,正常数据的重构误差值明显低于其它4种攻击类数据,其中R2L攻击和U2R攻击数据的重构误差值要比其它两种攻击的重构误差值低,说明本文提出方法可以有效地对异常数据进行检测。 图5 不同训练集比例下5种数据的重构误差值 为了更好地分析本文e-DDAE算法的性能,从准确率、误报率、精确率、召回率和F1值方面与AE算法(自编码器算法)、SVM算法(支持向量机算法)、K-NN算法(K最近邻算法)进行对比,实验结果见表3。 表3 不同分类算法性能比较/% 从表3可以看出,e-DDAE的召回率比AE、SVM、K-NN分别提高了4.06%、3%、8.56%;e-DDAE的F1值比AE、SVM、K-NN分别提高了1.98%、0.12%、4.42%;e-DDAE误报率比AE、SVM、K-NN分别降低了4.33%、3.85%、3.76%;e-DDAE分类准确率比AE提高了2.23%,比SVM略低了1.35%、比K-NN提高了4.15%;e-DDAE检测率比AE略低了0.28%,比SVM略低了2.90%,比K-NN提高了0.17%。 e-DDAE算法的灵敏度高,总体性能良好,在保证较好的分类准确率和检测率的情况下,召回率和F1值明显提高,误报率明显降低。 e-DDAE等4种算法对数据集中4种攻击类数据被分类为异常数据的准确率见表4,可以看出,在Dos攻击类数据方面,e-DDAE比AE、SVM、K-NN分别提高了0.18%、1.09%、4.23%;在U2R攻击类数据方面,e-DDAE比AE、SVM、K-NN分别提高了7.47%、5.65%、11.29%;在R2L攻击类数据方面,e-DDAE比AE、SVM、K-NN分别提高了2.10%、5.33%、9.21%;在Probe攻击类数据方面,e-DDAE比AE、SVM、K-NN分别提高了0.19%、4.67%、10.67%。e-DDAE算法对不同攻击类数据被分类为异常数据的准确率明显高于其它同类算法。 表4 不同算法对不同攻击数据的分类准确率比较 本文提出了一种基于弹性网的深度去噪自编码器网络异常检测方法,在构建深度去噪自编码器中加入弹性网正则化,用经过预处理的训练集中的一部分“正常”标签数据去训练网络,获得数据的重构误差阈值,通过自编码器和阈值来检测网络异常数据,避免了人为操纵阈值带来的主观影响。实验结果表明,该方法的检测性能优于其它的异常检测方法,在保持了较高分类准确率和检测率的同时,降低了误报率,提高了召回率和F1值,对不同攻击类数据被分类为异常数据的准确率也优于其它算法。2 基于弹性网的深度去噪自编码器构建
3 基于弹性网的深度去噪自编码器异常检测方法
4 实验与结果分析
4.1 实验数据集
4.2 数据预处理
4.3 实验评估指标与设置

4.4 实验结果分析


5 结束语
