基于随机森林的航空发动机工作状态识别
2020-06-12李鼎哲彭靖波赵泽平王玮轩
李鼎哲, 彭靖波, 赵泽平, 王玮轩, 赵 彪
(空军工程大学航空工程学院, 西安, 710038)
航空发动机工作状态识别属于模式识别中的多分类问题。目前,已有学者将SVM与SVDD方法用于航空发动机工作状态识别,文献[1]基于最小二乘支持向量机(LS-SVM)将一对一、一对多以及纠错输出编码3种分类方法进行了比较,并采用纠错输出编码方法对某架次发动机工作状态进行了识别。但所提方法在追求分类速度的同时牺牲了一定的分类精度,并且数据缺失对分类性能有较大的影响。文献[2]构建了一种基于超椭球分类面支持向量数据描述(HE-SVDD)分类器,具备了快速从大规模飞行数据中识别航空发动机工作状态的能力。但所提方法的分类性能依赖于核函数的选取,且核函数的选取只能依靠经验。文献[3]针对HE-SVDD方法存在的部分缺陷进行改进,提出了一种改进BA优化的多核支持向量数据描述(CRBA-MKSVDD)分类算法,进一步提高分类器的性能。但所提方法作为一种单分类器,存在响应时间长等缺点。
随机森林(Random Forest, RF)作为一种统计学习理论,利用Bootstrap重抽样方法从原始样本中抽取多个样本,对每个样本建立决策树模型,然后组合多棵决策树的预测,通过投票得出最终预测结果。该方法内部执行交叉验证,对于复杂和非线性数据,有很好的预测效果,并且有训练速度快、不易过拟合等优点[4-5],近年来广泛应用于故障诊断[6-7]、聚类识别[8-9]、回归预测[10-11]等领域。PCA法作为一种数据处理分析方法,主要应用于图形、语音等方面的处理和识别以及特征选择[12-14]。为此,本文将主成分分析法(Principal Component Analysis, PCA)与随机森林(RF)结合对航空发动机工作状态进行识别。
1 状态识别方法
1.1 主成分分析方法
PCA是一种常用的数据分析方法,其原理是通过一个向量矩阵将原始数据从高维空间投影到一个低维的向量空间[15-16]。换言之即通过线性变换将原始数据变换为一组各维度线性无关的表示,以此提取数据的主要线性分量。PCA法的流程为:①样本向量集;②计算矩阵X的协方差矩阵C;③计算协方差矩阵C的特征值和对应特征向量;④将所得特征向量从大到小排列对应的特征向量组成特征矩阵U;⑤使用特征矩阵U将样本特征矩阵X进行变换;⑥输出主成分。
设一个n维样本向量集X={x1,x2,…,xn},则X⊂Rm×n,令:
(1)
得到样本集的协方差矩阵为:
(2)
将矩阵C正交分解,得到:
C=U·Λ·UT
(3)
式中:Λ=diag(λ1,λ2,…,λn)是对角阵,由C的n个按降序排列的特征值λi组成。特征矩阵U=[u1,u2,…,un]由特征值λi对应的特征向量ui(i=1,2,…,n)组成的特征矩阵。λk对应的贡献度为:
(4)
为了提取样本集中信息量大的主元,用贡献率θ来表示,得到前d个主元的贡献率为:
(5)
设定阈值为P,使得θ≥P,确定主元,可得到主元模型:
V=UTX
(6)
原先的矩阵X可以重构为:
(7)
这样就可以将前d个特征向量构成的PCA子空间的大部分特征信息体现出来,实现了属性约简的目的。
1.2 决策树
决策树(Decision Tree)[17]方法可认为是一棵分类模型树,包含根节点、内部节点和叶节点,图1为决策树的基本构成。
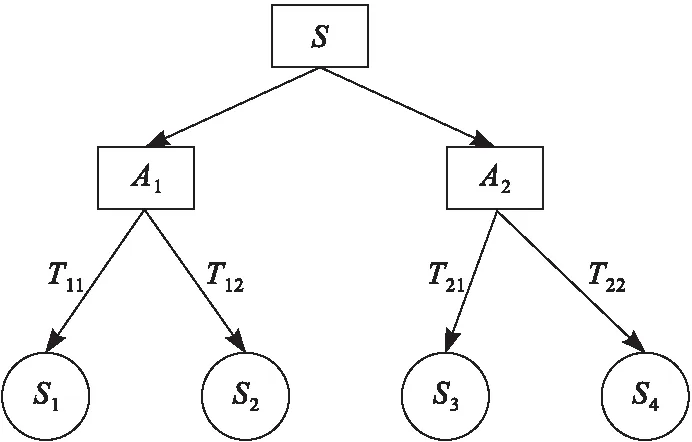
图1 决策树基本构成图
其中,根节点包含整个数据集,每个内部节点是一个判断条件,它将根据判断条件的测试结果,将数据集分配到2个或多个子节点,子节点继续分裂直至产生叶节点,包含最终的数据类别。但决策树生长过渡会使其产生过拟合的问题,且对于不平衡样本的分类性能较差,信息增益容易偏向样本量大的特征。
1.3 随机森林算法
随机森林是由多棵决策树组成的组合分类器,图2为随机森林的算法流程图。通过训练多个树状分类器,将多棵决策树的预测组合,最后经过投票的方式得到预测结果。其基本思想是先采用Bootstrap抽样从原始训练集中抽取k个样本,其次建立k个决策树模型,获得k种分类结果,最后对所有结果投票表决,确定最终归属于哪一类别。其模型函数为:
(8)
式中:k为决策树的数量;Y为输出变量(目标变量);I为示性函数;H(x)表示组合分类模型;hi(x)表示第i棵决策树的分类模型。
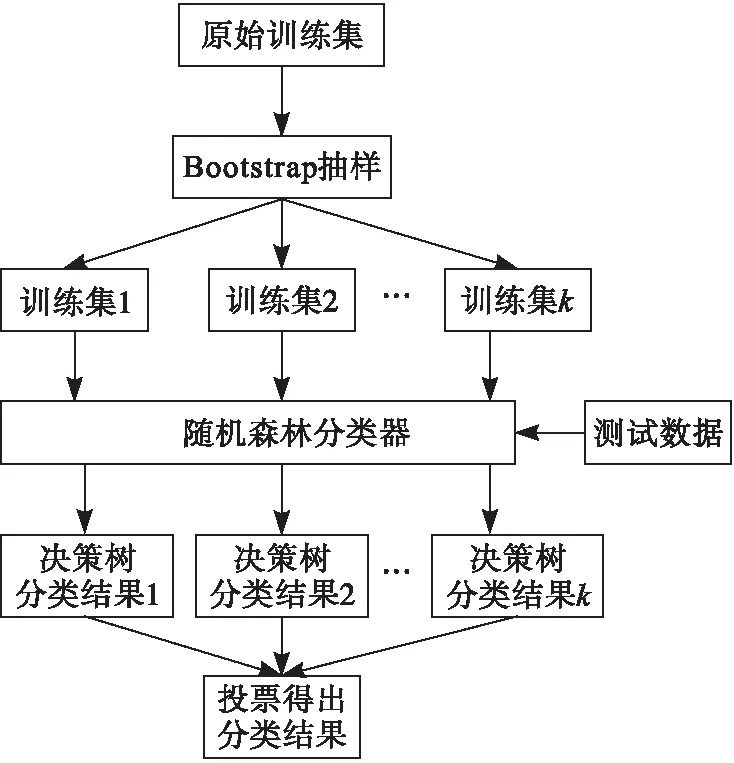
图2 随机森林流程图
随机森林通过构造不同的训练集增加分类模型间的差异,从而提高组合分类模型的外推预测能力[1]。其随机性主要体现在以下方面:第一,训练样本选择具有随机性,即通过多次有放回抽样形成子集;第二,特征子集的选择具有随机性,即随机抽取特征集合;第三,所有决策树模型不进行剪枝,自由成长。因此,随机森林很好地解决了过拟合的问题,将多个弱分类器集成一个强分类器。
1.4 算法步骤
算法设计流程主要包含了某型发动机飞参数据的采集与预处理、特征提取以及工作状态识别。
首先,将相关发动机参数从飞参记录器转录至地面处理设备(通常是便携式计算机),进行数据的预处理,随后按一定比例选取训练集和测试集。再采用PCA方法对数据集进行特征提取,利用降维后的训练集对随机森林分类器进行训练,再导入测试集进行发动机工作状态的分类识别,并计算分类准确率和测试时间。
1)采集飞参数据,提取相关特征参数并进行预处理。
2)通过PCA方法将所提取的飞参特征数据进行降维,根据贡献率选择n个主成分,输出对应的特征向量矩阵,组成训练数据集。
3)在训练数据集中通过Bootstrap方法有放回抽取k个样本集,构建k棵决策树。
4)在每一棵树的各节点处随机抽取m个特征属性(m≤n),对评估效果最佳的属性在对应节点处遵循节点不纯度原则进行分裂生长。
5)每棵决策树充分生长,不进行任何剪枝。
6)将生长得到的k棵树组成随机森林,根据分类器的投票数量得到相应分类结果。
上述算法设计流程如图3所示。
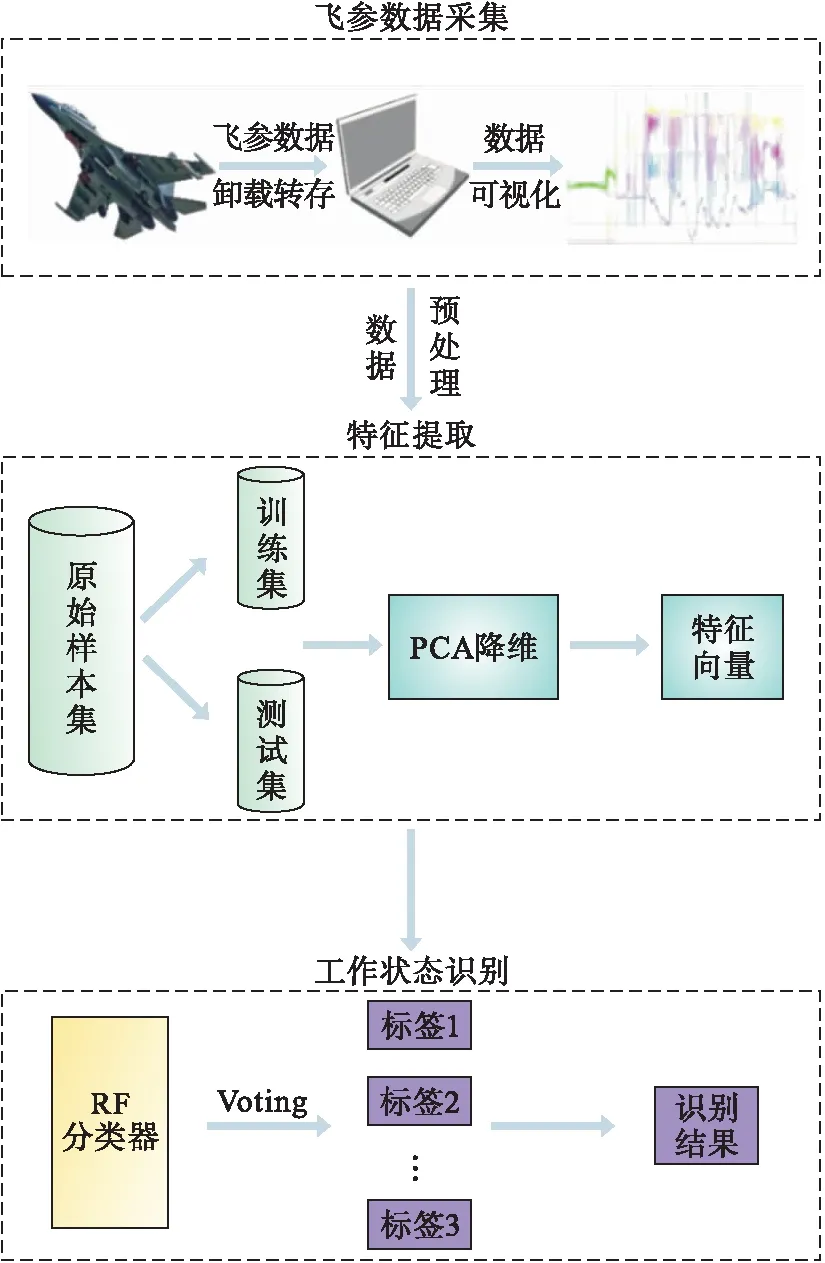
图3 算法流程图
2 航空发动机工作状态识别
2.1 飞参数据选取与预处理
某型发动机的稳定工作状态包含慢车、节流、中间、小加力和全加力(最大)状态,在外场工作中,通常需要将油门杆角度与其他同发动机相关的参数结合起来人工判读发动机工作状态,因此在特征飞参数据的选取上将会以此作为参考。
以下原则将会在参数选取过程中被考虑:①以该型号发动机技术说明中明确规定的相关技术指标以及对应参数为准。②若飞参数据之间存在较强的相关性,则选择相对工作状况强相关的参数,如换算转速与转速之间存在关联,考虑到转速作为发动机工作状态划分的主要依据之一(如慢车状态转速通常为中间状态转速的0.4~0.6倍),而换算转速更多的用于发动机相关参数的控制规律,那么就选择转速作为特征参数。
综上,最终选择油门杆角度(APL,(°))、低压转速(n1,%)、高压转速(n2,%)、滑油压力(Pm,MPa)、主燃油量(Wf,kg)、涡轮后温度(T6,℃)、涡轮后压力(P6,kPa)、发动机排气温度(T9,℃)、喷口面积(A9,cm2)以及加力接通信号(K)共计10个特征参数。
从外场收集该型航空发动机2018年5月日常飞行训练中的飞参数据。随机选中4个无故障飞行架次,对上述的特征参数进行提取,根据文献[18]所提方法进行如下预处理:
1)异常值剔除。对于明显偏离参数正常变化范围且同一时间点其余参数均正常的点,为避免影响分类效果,应当剔除。
2)同步性处理。某型飞机飞参记录器1 s记录4帧飞参数据,但由于不同的参数采样频率不同,在时间上并不同步,需要进行同步性处理,处理的办法是对各参数在1 s内求均值。
3)数据归一化。由于所选参数的测量精度以及量纲的不同,需要进行归一化处理,将所有参数归一化至0~1之间。
按照上述原则和处理方法最后得到原始样本数据38 826个,其中慢车、节流、中间、小加力、全加力数据数量分别为10 416、9 892、12 208、2 398和3 912个。
2.2 属性约简和决策树数目选择
为降低特征维数以及减少各特征间相关性,采用PCA方法对选取的10个特征进行融合和约简。
5个状态下的样本各取70%作为训练集,余下30%作为测试集。对所取训练集进行PCA处理,可以得到10个特征值矩阵Λ以及对应的特征向量U。选取主元累计贡献率θ为95%,得到相应的k值为5。前6个主元的累计贡献率分别为59.1%,69.6%,79.4%,87.8%,95.2%,96.6%。
在进行状态识别前,需要选择最优的决策树数目。决策树数目与分类准确率的关系如图4所示。可以看到当决策树棵树为15时,分类准确率达到98.43%,且随着决策树数目增多,准确率趋于稳定。但决策树增多会使计算复杂度随之上升,伴随着计算时间的增加。因此,选择15棵决策树组成随机森林分类器,进行发动机工作状态的识别,既能保证分类精度,又能合理的减小计算复杂度,缩短计算时间。
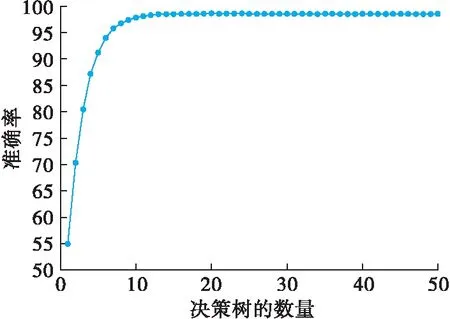
图4 分类准确率与决策树数目关系图
表1比较了未使用和使用PCA方法进行属性约简后的随机森林分类器(决策树数量同为15)分类准确率和训练时间。可以看出,对数据进行属性约简后,训练时间将会显著减少,而且分类精度仍然较高。

表1 2种方法准确率比较
2.3 基于随机森林的训练与测试
实验过程中,选择属性约简后的训练集对不同的分类器(BP-ANN、LS-SVM、BA-MKSVDD和RF)进行训练,用同样经过属性约简的测试集对训练后的分类器进行分类精度检验。图5为反映分类器识别效果的受试者工作特性(ROC)曲线。
对比分析图5可知,所提出的PCA-RF方法在发动机的5种工作状态下都具有比较优异的分类性能,相比于其它3种识别方法尤其是BP神经网络和LS-SVM而言,其对5种工作状态下的特征数据,在较低的异常样本接受率下都能够正确的接受大部分目标样本,更适合用作状态识别分类器。
表2和表3分别为使用PCA降维前后4种分类器分类精度和测试时间。从表2可知,RF的识别准确率最高,明显高于LS-SVM与BP-ANN,尤其表现在发动机进入加力工作状态之前的3个工作状态上。由于发动机进入加力状态工作时间较少,以及加力状态下飞参数据具有波动性强、稳定性低的特点,因此造成识别准确率的下降。由表3可知,使用PCA降维后,能够显著减少识别时间,但同时会使识别准确率有小幅下降。综合看来,本文所选的PCA-RF方法既可以有效提高识别效率,又能够保证较高的识别精度。
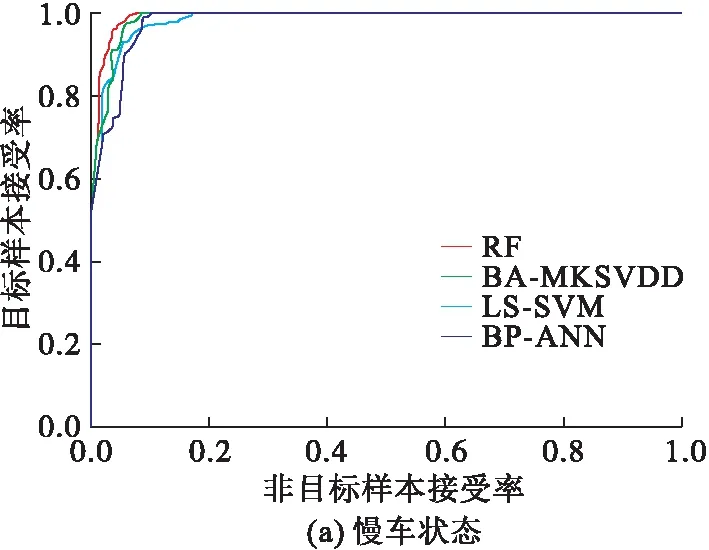
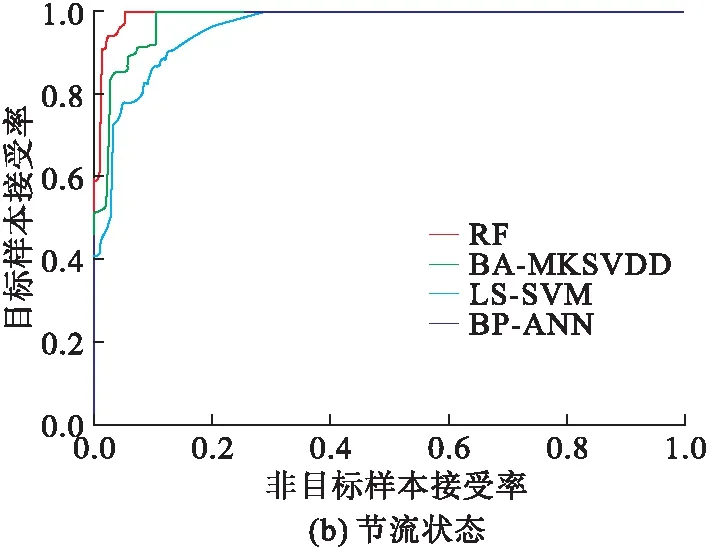
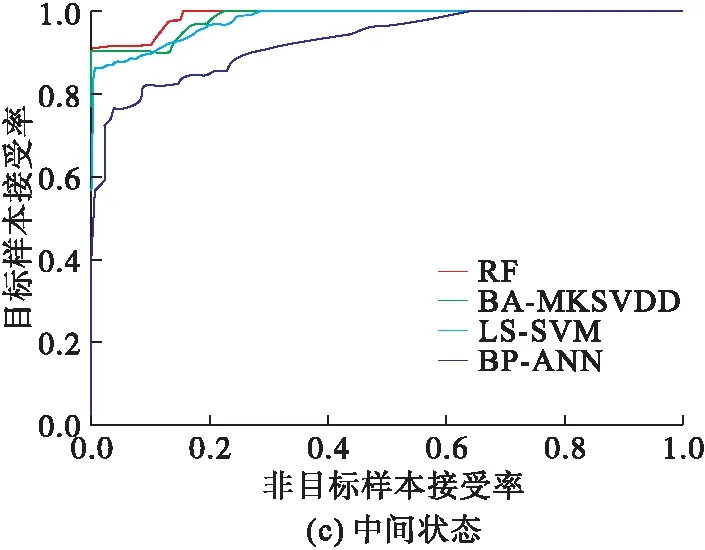

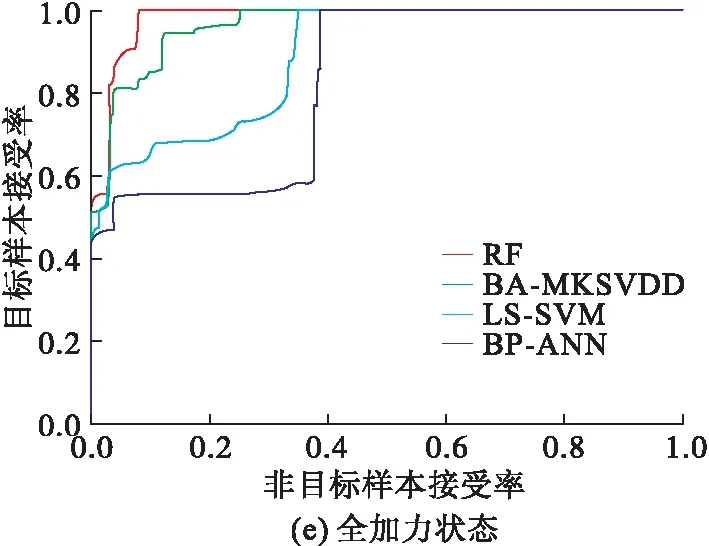
图5 不同工作状态的ROC曲线
表2 使用PCA降维前各分类器的分类精度与测试时间

表3 使用PCA降维后各分类器的分类精度与测试时间
2.4 状态识别实例
使用本文提出的算法,节选该型发动机的某次飞行训练中的一段飞参数据进行工作状态识别,在进行发动机工作状态状态识别前需要利用2.1节中提出的原则对飞参数据进行预处理。
在选取的这段飞参数据内,该型发动机先后经历了慢车、节流、慢车、中间、节流、小加力、全加力、最大、节流和慢车状态,图6为识别结果。
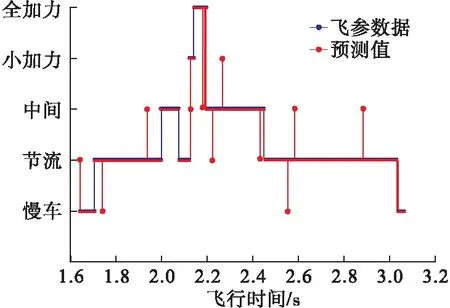
图6 某架次发动机工作状态识别结果
可以看出,预测结果同实际结果吻合度较高。使用本文所提方法对该段发动机工作状态识别准确率达到97.89%,已经基本符合发动机的实际工作状况,可以体现本文方法的有效性。
3 结论
本文提出了一种基于PCA的特征提取方法和RF的航空发动机工作状态识别方法。通过对某型发动机工作状态的识别实例,得出以下结论:
1)利用PCA方法进行属性约简对识别准确率影响较小,同时能提高识别效率。
2)经过对比实验,本文所提方法具有较高的识别准确率和识别效率。
3)节选某架次航空发动机飞参数据进行工作状态识别,结果表明本文所提方法对发动机工作状态能有效识别,具有研究应用价值。
此外,随机森林分类器的分类性能易受样本数量影响,对于小样本数据的分类效果仍有提高的空间。
