输入模态与练习频次对口译质量的影响
——一项基于认知负荷理论的研究
2020-06-11周忠良
周忠良
(宁波财经学院人文学院,浙江宁波)
1.引言
模态是指人类通过感官(如眼睛、耳朵等)跟外部环境(如人、机器、物件、动物等)之间的互动方式。用单个感官进行互动的叫单模态;用两个的叫双模态,三个或以上的叫多模态(顾曰国,2007:3)。多模态话语是指运用听觉、视觉、触觉等多种感觉,通过语言、图像、声音、动作等多种手段和符号资源进行交际的一种话语现象(傅晓玲,2014:14)。根据上述定义,口译是一个以跨语信息传递为目的的多模态话语协同交互过程:译员接受以文字、声音、动作、表情和图像等模态或组合模态输入的源语信息,通过大脑语言认知与信息加工系统对接收到的信息进行记忆、解码与重新编码,最后以语音模态用目标语将信息传达给听众。
认知负荷是指人在学习或任务完成过程中进行信息加工所耗费的认知资源的总量,包括三种类型:(1)由学习材料的结构和复杂性引起的内在认知负荷,(2)由信息呈现的形式和方式施加的外在认知负荷,(3)由学习者努力地加工并理解材料所造成的有效认知负荷;在大脑进行信息加工时,三种认知负荷相互叠加、交互作用(Sweller,1988:261)。现有研究发现,不同的信息输入模态对二语学习者的语篇理解(戴劲,2007)、词汇记忆(杨学云,2009)、词义习得(范烨,2014)和听力解码能力(邱东林 李红叶,2010)均有直接的影响。这是因为信息呈现方式直接影响着认知负荷的消耗;认知负荷的消耗量与信息加工的准确性和效率呈负相关,认知负荷消耗越大,信息解码能力就越弱(Leeser,2004:589)。
频次在二语习得领域是指学习者语言接触的经历或语言练习的次数。频次效应是指重复的语言练习给学习者语言能力变化和发展所起的作用(Harrington & Dennis,2002:261)。重复练习引起的频次效应能有效提高学习者的二语能力(周丹丹,2010:55)。频次理论的倡导者Ellis(2002:186)将频次视为语言学习的决定性因素。2002年,System出版专号讨论频次作用,Ellis(2002)、Hulstijn(2002)和Larsen-Freeman(2002)等学者从不同角度阐释了频次对二语习得的作用机制,涉及语言心理、语言认知、语言教学和语言学习策略等诸多方面。现有研究证实,频次效应有助于学生掌握外语语音韵律特征(陈桦 孙欣平,2010),增强学生听力理解能力(Jensen & Vinther,2003),改善学生口语流利性和表达质量(谭晓晨 董荣月,2007),提升学生词汇与短语学习效率(周丹丹 徐燕,2014),提高学生的阅读理解与分析能力(Gorsuch&Taguchi,2010),增进学生整体的二语写作水平(周丹丹 黄湘,2015)。
口译是衡量大学生外语应用、双语转换和专业实践能力的重要指标。口译技能的获得和口译质量的提高需要大量的重复训练。因此,频次效应对学习者口译技能的提高有重要作用。口译是一个集听辨、记忆、解码、重新编码和输出于一体的高认知负荷活动(王建华,2015:14)。口译的质量很大程度上取决于译员对源语信息的解码、整合和转换的能力(Gile,1999:168),也与源语发言的输入方式密切相关(王斌华,2012:94)。有鉴于此,我们有必要从认知负荷视角研究练习频次和输入模态对口译质量的影响。
本研究拟考察不同模态的输入方式与练习频次对英语专业大学生口译质量的影响,呈现学生的口译质量诸指标在不同的输入模式和频次作用影响下的细微变化和进步,并基于认知负荷理论揭示输入模态与练习频次对口译质量产生影响的作用机制,以便为理解学生口译能力发展机制和提高口译教学质量提供参考。
2.研究设计
2.1 研究问题
本研究设置2个自变量:源语信息输入模式和口译练习频次。本研究设计了3种输入模式:第一种为多模态输入(字幕+视频+语音);第二种为双模态输入(视频+语音);第三种为单模态输入(纯语音);练习频次设计为3次。本研究主要回答以下问题:(1)在不同的输入模式下,各频次间的口译质量存在何种差异?何种输入模式下的口译质量最好?原因何在?(2)不同频次下的各输入模式间的口译质量存在何种差异?哪一个练习频次下的学生口译质量进步最大?
2.2 被试
被试为宁波某高校本科英语专业大三学生。样本数为60,从3个平行班中等数抽取。将被试随机按照输入模式分为三组:字幕视听组、视听组和纯听组,每组20人。
2.3 实验材料
实验所用材料为3个中译英讲话:李岚清的申奥陈述、胡锦涛在奥运会欢迎宴会上的祝酒辞和刘淇在奥运会闭幕式上的讲话,分别用于第一、第二、第三频次口译训练。三个讲话以带中文字幕视频、不带字幕视频和纯语音等三种输入模式分配给三组被试进行口译训练。这三个讲话话题相同,语言难度相当,语速大致相近。我们在不影响内容完整性的提前下对讲话长度进行了剪辑,确保其播放时间大致相同。
2.4 口译质量指标体系
传统的口译标准是准、整、顺、快(王斌华,2012:95)。本研究将之操作化为准确性、完整性、流利性和口译效率等4项口译质量评价指标。
准确性是指译语语言使用的准确程度,要求译语选词得当、语法正确、逻辑贴切,用译语语言表达错误的频数来衡量;错误越少,准确性就越高。
完整性是指口译内容输出的完整程度,要求译语与源语内容与意义一致,用错译漏译的频数来衡量;译语信息错译漏译越少,完整性就越高。
流利性是指语言输出的流畅程度,要求译语输出流畅通达,用非流利因素的频数来衡量;非流利因素的频数越少,流利性就越高。非流利因素分为不当停顿①不当停顿分为静默停顿和有声停顿两类。符荣波(2012: 439)将口译中超过.250秒的静默片段视为静默停顿。但目前关于静默停顿的阈值尚未有公认的标准(徐海铭,2010: 65)。有鉴于此,本研究未将静默停顿纳入考察范围。有声停顿主要指不当使用的、影响译语流利度的语气词,如中文的嗯、啊、呃,英文的err、ah、um等。、重复和修补三类,是造成口译表达不顺的常见原因(符荣波,2012:439-440;2013:199-200)。
口译效率是指单位时间内的口译量。口译效率=被试译文词数/以秒计量的口译时间*60,即被试每分钟的口译词数。得分越高,说明被试1分钟内的口译字数越多,口译效率就越高。
根据上述指标定义,我们对被试译文进行了人工赋码和标注:WZ用以标注漏译错译;ZQ用以标注各类语言表达错误;LL用以标注译语的非流利因素。标注方法示例如下:
源语:2800多年前在神圣的奥林匹亚兴起的奥林匹克运动,是古代希腊人奉献给人类的宝贵精神和文化财富。诞生于1894年的现代奥林匹克运动,继承了古代奥林匹克传统,发展成为当今世界参与最广泛、影响最深远的文化体育活动。
译语:The Olympic Movement started over 2,800 years ago①[WZ].It is a valuable, er②[LL],spiritual and, and③[LL]cultural asset provided to④[ZQ]the human race by ancient Greece, the people of Greece in ancient times⑤[LL].The modern Olympics, which⑥[ZQ]was born in 1894 and has taken on the ancient Olympic traditions and developed into the most influential cultural and sporting event in the world today⑦[WZ].
①源语中的“在神圣的奥林匹亚”未译出,⑦漏译原文的“参与最广泛”,故用WZ来标注;②为不当停顿,③为不当重复,⑤为回修,三者皆为非流利因素,故用LL标注;④短语结构不当,正确的结构应该是provided for或offered to,⑥为句法错误,二者均属语言表达错误,因此用ZQ标注。
2.5 实验步骤
在《英语口译》课的前三周每周一下午组织各组被试同时进行一次允许做笔记的不限时口译练习。被试被要求记录完成口译任务的时间。教师将口译录音转写成文字,并根据所设口译质量评价指标及赋码方法对转写文字进行人工标注。标注先由课题组三位老师分别进行,之后集中统计校对,以确保标注的准确性。
2.6 研究工具与方法
实施实验前,被试接受了统一的口译水平测试。试题为2015年5月份的上海市外语中级口译岗位资格证书考试试题的汉译英部分。我们采用单因素方差法在SPSS17.0上对各组被试平均成绩进行对比,结果显示三组成绩均值之间无显著差异(=.05,F=2.02,p=.143)。
本研究采用语料库统计软件BFSU PowerConc统计WZ、ZQ和LL的频数。为便于分析,我们将上述指标进行标准化处理,计算出每个被试译文各项观察指标每100词的统计得分。具体方法如下: Z=M/Y*100。Z代表观察指标得分,M代表观察指标的频数,Y代表被试译文总词数。以完整性指标为例,假如某个被试译文错译漏译频数为16,译文词数为377,则完整性指标Z得分为16/377*100=4.24。
本研究利用SPSS17.0对数据进行统计分析,使用一般线性模型重复测量方差法和单因素方差法,对被试口译质量诸指标得分和口译总分的均值进行逐项对比分析,以考察输入模态和频次对口译质量的影响。统计分析的显著性水平设定为=.05。
3.结果与讨论
3.1 实验结果

表1 口译质量完整性指标的实验结果
3.1.1 输入模态和练习频次对口译质量完整性的影响
根据表1,三组被试的完整性得分均值均随口译练习频次的增加呈下降趋势。使用一般线性模型重复测量方差法对各组不同频次均值之间的统计差异性进行检验,结果显示存在显著统计差异:字幕视听组F值为55.74***,视听组F值为55.10***,纯听组F值为32.98***,表明频次效应对各组被试口译内容传译的完整性作用显著。换言之,练习频次与各组完整性得分呈显著负相关,三组被试错译漏译数量随口译练习频次的增加显著减少,译语内容的完整性逐次大幅提高。
为比较第二频次和第三频次对口译完整性指标的提升作用,我们将各组第二频次与第一频次的均值之差的绝对值均(下文简称J1)和第三频次与第二频次的均差绝对值(下文称J2)进行对比,发现各组J1大于J2:字幕视听组J1为.98,大于J2的.93;视听组J1为.74,大于J2的.47;纯听组J1为1.59,大于J2的.82,说明第二次口译练习的频次效应对译语信息完整性的提升作用更大。
为了解各频次不同组别均值之间的差异,我们以频次为自变量,对各组均值进行单因素方差分析,结果显示均具统计差异性:第一频次F值为10.97***,采用LSD法进行的续后分析表明字幕视听组与纯听组均值存在显著差异,均值差为-1.58***,视听组与纯听组的均值也差异显著,均值差为-1.50***;第二频次F值为3.56*,续后分析表明视听组与纯听组均值差异显著,均值差为-.97*;第三频次F值为7.75**,字幕视听组与纯听组差异显著,均值差为-.57*,视听组与纯听组差异显著,均值差为-1.08***。上述数据说明,纯听组各频次完整性指标均值都显著大于其他两组;视听组均值大于字幕视听组,但差异不显著;也就是说,纯听组被试在各频次的信息错译漏译数量最多,视听组次之,字幕视听组最少,呈现出输入模态越多元,译语信息表达越完整的特点。
3.1.2 输入模态和练习频次对口译质量准确性的影响

表2 口译质量准确性指标的实验结果
根据表2,三组被试准确性得分均值在重复的口译练习中呈下降趋势。重复测量方差检验结果显示各组不同频次的均值之间均存在显著统计差异:字幕视听组F值为11.58***,视听组F值为11.83***,纯听组F值为9.94***,说明重复练习对各组口译目标语语言表达的准确性的提高发挥了显著的影响。不同输入模态的被试均通过重复的口译训练,大幅减少了语言表达错误的数量,极大地改善了译语输出质量。
对各组的J1和J2进行对比,发现各组J1均大于J2:字幕视听组J1为3,大于J2的1.47;视听组J1为2.64,大于J2的2.17;纯听组的J1为2.62,大于J2的1.15;这说明第二次口译练习时各组被试语言表达错误数量减少的幅度最大,因此第二次训练是频次效应发挥影响的最佳节点。
表2显示,不同频次各组的均值字幕视听组最小,视听组次之,纯听组最大。单因素方差检验结果显示各频次不同组间的均值不具统计性差异:第一频次F值为.58;第二频次F值为1.48;第三频次F值为1.17。
3.1.3 输入模态和练习频次对口译质量流利性的影响
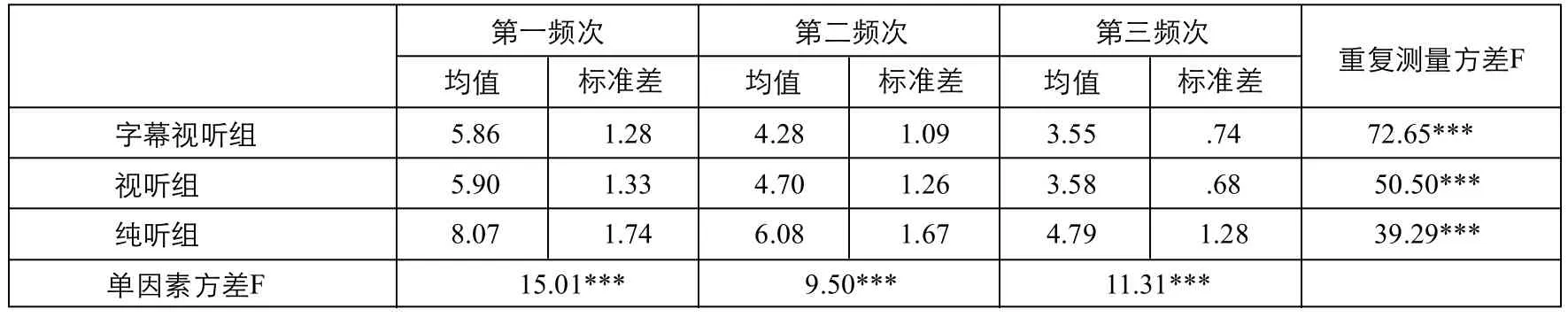
表3 口译质量流利性指标的实验结果
根据表3,三组被试流利性均值呈现逐次下降特点。重复测量方差检验结果显示各组组内不同频次均值之间存在显著统计差异:字幕视听组F值为72.65***,视听组F值为50.50***,纯听组F值为39.29***,表明不同输入模态的被试在实施重复性口译任务过程中不当停顿的数量大幅减少,语言表达的流畅度和连贯性不断增强,译语输出的流利性得到明显改善。
对各组J1和J2进行对比,发现J1均大于J2:字幕视听组J1为1.58,大于J2的.73,视听组J1为1.20,大于后者1.12,纯听组的前者为1.99,大于后者1.29,说明各组被试在实施第二次任务时译语表达流利度提升的程度最大。
单因素方差检验结果显示各频次不同组间的均值存在显著差异:第一频次F值为15.01***,LSD续后分析表明字幕视听组和视听组与纯听组差异显著,均值差分别为-2.21***和-2.18***;第二频次F值为9.50***,续后分析也显示字幕视听组和视听组与纯听组差异显著,均值差分别为-1.80***和-1.38**;第三频次F值为11.31***,续后分析同样显示字幕视听组和视听组与纯听组差异显著,均值差为-1.24***和-1.21***。上述数据说明纯听组被试的流利度最低,与其余两组在不同频次上的表现具有显著性差异。
3.1.4 输入模态和练习频次对口译效率的影响
根据表4,三组被试口译效率均值随练习频次的增加不断上升。重复测量方差检验结果显示各组内部不同频次的均值之间存在显著统计差异:字幕视听组F值为6.69**,视听组F值为8.59***,纯听组F值为16.77***,表明练习频次与口译效率之间存在显著正相关,重复练习对被试口译效率的影响效应显著,学生可通过持续的口译训练大幅提高单位时间内的口译量。

表4 口译效率指标的实验结果
对各组J1和J2进行对比,发现J1均小于J2:字幕视听组J1为.94,小于J2的16.17;视听组J1为6.29,小于J2的8.02;纯听组J1为6.89,小于J2的11.27;说明第三频次是提升口译的效率最佳节点。
以频次为自变量的单因素方差检验结果表明,各频次不同组别之间的口译效率无显著差异:第一频次F值为2.08,第二频次F值为.23,第三频次F值为2.19。
3.2 基于认知负荷理论的理据分析
3.2.1 练习频次对口译质量的提升效应
如前文所示,学生译语输出的完整性、准确性、流利性和口译效率均随练习频次的增加显著进步。从认知心理学上看,学习者的认知负荷与其工作记忆直接相关(Sweller, 1988: 261)。工作记忆分为经过深层认知加工的长期记忆与未经思维深度处理的短期记忆(Baddeley, 2003: 829)。研究证明,工作记忆对二语语篇理解有重要作用,影响着从词句解码到语篇意义构建的整个过程(Walter, 2004: 328)。信息和知识以图式形式存储于长时记忆;图式是根据信息的功能及其用途范畴化或经过归类的信息单元,是一种无需控制性过程的自动化加工单元,在工作记忆中只需极少的贮存空间(Sweller, 2006: 355)。所以,有意识地建构图式有助于贮存和组织长时记忆中的信息并减少工作记忆的负荷。学习者是在储存于大脑长期记忆中的前知识中建构概念的。在执行学习任务时,学习者利用前知识从各种以不同形式呈现的外部学习材料中选择相关信息,然后将所选信息与前知识相结合,最终形成自己的知识结构(Cook, 2006: 1084)。前知识有利于图式的形成,这些图式又可以帮助选择信息建立新的图式,从而减轻信息加工的内部认知负荷和有效认知负荷。
在重复的口译练习中,学习者逐渐熟悉了口译的主题内容和相关的语言表达形式与结构,使之形成相应的图式,这些图式以前知识的形态存储在长期记忆中。这样,在下次口译练习时,这些有关某个主题及其相应的语言表达形式就会以前知识的形态,被从长期记忆中迅速调用出来,参与新的信息加工过程,从而减轻了译员信息处理的内部认知负荷和有效认知负荷,使译员可以利用更多的认知资源来应对口译过程中的其他任务,从而使口译的信息的完整性、语言的准确性、表达的流利性和工作效率得到逐次进步。另外,频次效应对口译质量的促进作用也符合学习曲线理论。该理论认为,在一个合理的时间段内,当学习者重复同一学习过程时,其语言处理的自动化水平会不断地提高,错误率和反应潜时会呈负加速度下降趋势,形成“熟能生巧”效应,学习效能得到极大提高(Patten & Williams,2007: 252)。
3.2.2 输入模态对口译质量的影响
口译是一个集听、理解、记忆、表达于一体的高认知负荷的活动。译员需接受源语信息输入,通过大脑语言认知和信息加工系统对信息进行解码,最后将之以译语输出。在大脑对源语信息进行加工的过程中,认知负荷起着关键作用,是影响信息解码能力的重要因素(Paaset al, 2004:6)。认知负荷的消耗量与信息解码能力呈显著负相关,学习者认知负荷消耗量越大,解码能力就越弱(夏宁满,2014: 36)。认知负荷的消耗状况受语言信息输入方式的影响(Van Merrinboer & Ayres,2005: 12),不同的外部信息输入方式直接引起个体认知负荷的变化,从而影响英语信息解码的速度和效率(Mayer et al, 2001: 191)。
负责信息解码的人脑信息加工系统里存在两个独立的通道:听觉通道和视觉通道,前者加工听觉输入与言语表征,后者加工视觉输入与图片表征,每个通道的加工容量是有限的(Leahy et al,2003: 415)。有效的学习要求教学材料能最大限度地发挥模态效应(modality effect),即所呈现的教学内容可充分调动起学习者的各种感官通道对教学信息进行协同加工,以避免这些信息在工作记忆中“堵车”而出现认知超载,从而影响信息加工的质量与效率(Tindall-Ford et al, 1997:284)。因此,给学习者提供的教学信息应以多模态的形态加以呈现,使用具有文字、图像和声音等多模态整合功能的多媒体展示文件或工具,把教学信息多维度、实时、动态地呈现出来,为学习者提供认知支架,如此就能帮助学生有效地注意所呈现的材料,高效地将所呈现材料组织成一个有条理的结构,与大脑中的先知识进行整合,构建出新的理解图式,从而降低学习过程中认知负荷。
如前所示,三组被试相较,字幕视听组口译质量最好,视听组次之,纯听组各项指标均落后于其他两组。这是因为在口译中,采用文字、图像和声音等多模态整合的方式输入信息,能有效地降低译员的认知负荷。其基本理据是,在口译中采用多模态的输入方式,能使文字、图像和声音等信息模态实现协同互动,促进进入人脑认知系统的信息得到有效整合,极大地减少了学习者信息解码需要调取的认知资源,也就减轻了学习者信息加工所需的认知负荷,从而提高了学习者的信息加工能力。换言之,多模态的信息输入方式,因为形成了一个由文字、图像和声音等不同模态构成的有机信息呈现生态,不但没有增加译员的认知负荷,反而有助于译员充分利用听觉通道和视觉通道对输入的信息进行协同加工,在工作记忆中建立起文字、声音和图像之间的联系,形成图式,从而大幅缓解大脑的信息处理压力。较之于字幕视听组,视听组被试由于没有文字信息的提示作用,其口译信息处理所需的认知负荷更大,相应地,信息处理能力就更弱,因此口译质量次于字幕视听组。纯听组只能依靠单一的语音模态输入获取信息,无法像其他两组那样通过文字和/或图像捕获相关信息,因此信息处理所需的认知负荷消耗量最大,因而信息处理的准确性和效率最低,口译质量自然不如其他两组。这一点与辛自强、林崇德(2002)的研究结果不谋而合:组合型音频信息较之于纯语音信息具有不可比拟的优越性,其图形、图像等具象信息能激活大脑信息加工体系中的认知图式;图式是提高听力解码的重要因素,图式越充足,认知过程中耗费的认知负荷就越小,听力解码越容易。
人的认知资源和注意力资源是有限的。在口译中,译员要同时完成听辨、解码、记忆和输出等任务,各项任务均需要一定的认知资源和注意力资源来应对,因此认知资源和注意力资源在多任务处理过程中处于竞争状态。多模态、双模态的输入模式有利于减轻译员听辨、解码和记忆的认知负荷,减少其注意力资源的使用,使译员有更多的认知负荷和注意力资源来处理译语输出任务,提高译语的完整性、准确性、流利性,从而最终提高口译总体质量。总之,在教学中,较之于用单模态单媒体呈现内容,用多模态多媒体整合的方式呈现教学内容效果更佳。
4.总结与启示
本研究基于认知负荷理论,考察了输入模态与练习频次对口译质量的影响,研究结果总结如下:首先,练习频次对口译质量有显著的提升作用。第二次练习是发挥频次效应的最佳节点;其次,输入模态对口译质量影响显著,各频次不同输入模态间的口译质量差异显著;多模态输入方式对口译质量提升作用最大,双模态次之,单模态最小。第三,重复练习与多模态输入方式均能有效减轻译员的认知负荷,提升译员的信息处理能力和多任务协调能力,从而使口译质量得到提高。
上述研究给我们口译教学带来诸多启示:首先,应重视重复练习对提升口译教学质量的积极作用。口译课是一项实践性非常强的课程,口译技能的获得离不开重复练习。在口译教学中,要制定有效的练习计划,在合理的时段内安排学生进行重复性的专项练习,以充分调动学生的长期记忆资源和图式构建能力,减轻学生的口译过程中信息加工的内部认知负荷和有效认知负荷,提高学生总体的口译质量。其次,要注意教学材料呈现的模态效应,在口译教学中可多采用多模态多媒体的输入方式,以有效缓解学生信息处理过程中的外部认知负荷,增强学生的多任务协调能力,从而提高学生口译能力。
本研究基于认知负荷理论分析了输入模式与练习频次对口译质量的影响,对于我们理解学生口译能力发展机制有重要意义。尽管如此,本研究仍有许多问题尚未触及,例如,频次效应和输入模态的作用与学习者的语言水平和认知风格等个体因素可能存在密切关系,因此研究这些因素间的互动作用机制也极有意义。另外,本研究样本较小且来自同一高校,研究结果是否具有代表性有待进一步论证。
