基于K-Means 算法的Web 日志用户聚类研究*
2020-06-09陈洲陆南
陈 洲 陆 南
(江苏科技大学电子信息学院 镇江 212003)
1 引言
国际数据公司(IDC)曾经发布报告称[1],数字世界(digital universe)项目统计得出全球数据总量预测在2020 年达到44ZB。大数据时代,为了良好的用户体验及网络站点优化,需要对Web服务站点的日志文件进行挖掘,分析元数据规律,从中发现有用知识。
用户聚类是在对元数据进行预处理的基础上,对具有相同行为模式的用户进行聚类[2]。为了将具有相同浏览行为的用户分成一组,田园[3]等在通过对数据文本的预处理后,得到用户会话序列矩阵集合,然后对样本进行聚类分析。
刘琦[4]等通过建立Web 页面的用户访问矩阵,此会话矩阵是通过日志记录中用户对页面的访问情况为依据而建立,然后运用最大树算法将构造的模糊相似矩阵进行聚类,此方法适用于处理高维数据,简单快速。
K-Means 算法作为无监督学习算法,在商业、人工智能等领域异常活跃,随着Web 挖掘的发展,在数据挖掘领域也被广泛应用,虽然K-Means算法简单,但还存在着许多不足,其中最为严重的是初始中心点的随机选取,对此,韩凌波[5]等提出了一种改进的基于密度的寻找初始聚类中心的改进算法,该算法引入密度参数的概念,把Iris数据集的聚类测试结果提高到了83.33%。
后来,基于旋转算法的思想,崔丹丹[6]提出坐标旋转算法来寻找初始中心点,即通过找到的第一个初始中心点,根据所划分的类簇数目,通过坐标旋转的方式找到下一个中心点,该算法在一定程度上降低了噪声数据点的影响。
随着数据量的不断增加,基于K-Means的Web日志挖掘研究形势更加严峻,以上几种方法一定程度上提高了算法聚类精确度,但并没有解决在构建用户会话矩阵后存在的孤立点的问题,在分析大数据量的文本时也有一定的缺陷。
本文提出的ICKM 算法利用密度参数最大的对象作为第一中心点,利用KCR 算法寻找下一个中心点;为了提高大数据环境下的计算速度,算法与Hadoop的MapReduce计算框架[7]相结合,通过框架承载数据的计算压力;同时,该算法也充分考虑用户聚类过程中建立的会话矩阵孤立点的影响,在一定程度上提高了运算速度与准确度。
2 数据挖掘与K-Means算法
2.1 Web日志挖掘
Web 日志挖掘的目的是从大量的服务器日志文件中,通过各种挖掘算法,最终得到用户所需要的知识[8]。这个过程大概分成三部分,本文只涉及其中的数据清洗,即对日志数据进行用户访问日志的数据清洗从而建立用户会话矩阵[9]。
2.2 算法原理
K-Means算法简单,为聚类问题提供了一种解决方案:把数据集合中的n 个样本点(实例)划分到k 个集群中,使每一个点都属于离它最近的均值对应的集群中,使每个集群中的点(实例)存在高关联度,使每个集群之间的对象存在低关联度[10]。
算法开始之前,首先确定将数据集合划分为几个集群,然后确定初始中心点,而中心点是从数据集合中随机选取,随后再根据相似性度量函数计算集合中其他点到K 个初始聚类中心点的距离,将数据对象放到距离最近的集群中,其中常用的度量函数为欧式距离[11]:
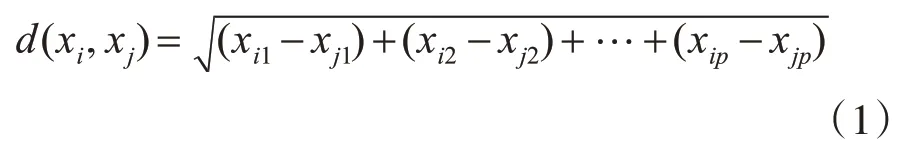
其中xi,xj代表集群中任意两个样本,接着更新每个集群的中心点:
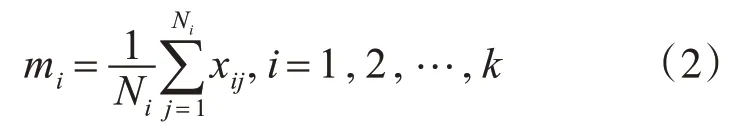
不断重复,直到误差平方和(SSE)准则函数收敛,即
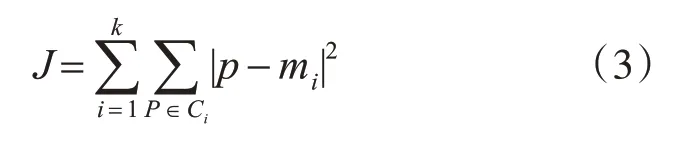
其中,P表示给定的数据样本点,m是第i个集群Ci的均值。
2.3 基于K-Means的用户聚类
用户聚类实质上是根据用户访问页面、服务器的行为,将相同行为的用户聚合为一类,进而分析讨论该类用户所具有的特点。而要实现用户聚类,首先通过数据预处理对Web日志进行相应操作,进而生成<用户集合,页面集合>的相关矩阵[12],然后将其转化为用户序列矩阵并采用K-Means 算法进行分析。
根据用户在一段时间内对页面、服务器的访问次数,构建会话矩阵即分析用户ci对页面pi的偏好程度,构造原始数据会话矩阵如下:
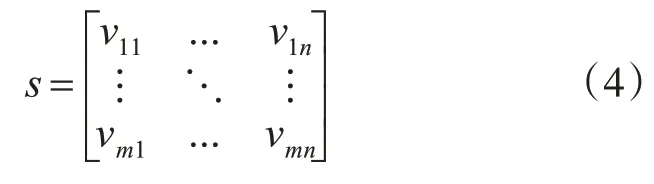
其中v表示一个会话记录,可以看到,在利用算法对矩阵进行分析时,孤立点的影响对分析结果有消极影响甚至是无用的,而在寻找初始中心点时,由于孤立点(噪声点)的存在,会使得寻找的初始中心点和真正的聚类中心点偏离较大。
3 改进的K-均值聚类算法
尽管K-Means具有很多优点,但算法需要随机选取初始中心点,初始点的选择不当、远离数据集的孤立点都可能会影响聚类结果,使结果陷入局部最优解[13]。为了解决以上问题,韩凌波等提出了基于密度参数的寻找初始聚类中心的改进算法,该算法引入密度参数的概念,可此算法并未考虑稀疏数据点及孤立点的影响,本文将坐标旋转算法与之结合,使中心点的选取不通过均值来选取,减少噪声点的影响。
算法解决的问题:通过ICKM 确定初始中心点,将数据样本点集合x{x1,x2,…,xn}划分到k个集合中,使得误差平方和最小且不再变化[14]。
定义1数据对象xi和xj之间的距离可表示为
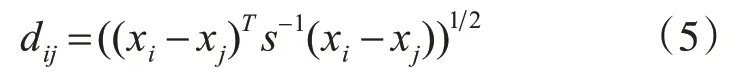
其中,S为样本协方差矩阵。
定义2以空间中任意一点xi为中心,半径为r画圆,此区域称为点xi的邻域,在空间点xi的邻域内点的个数称为点xi基于距离r的密度参数,记dins(xi,r)。
ICKM将马氏距离作为衡量数据对象间相似度的函数,空间内任意一点的密度参数越大,说明此点所在区域点数越多,选取此点作为中心点误差函数越容易收敛。
定义3误差平方和函数[15]:
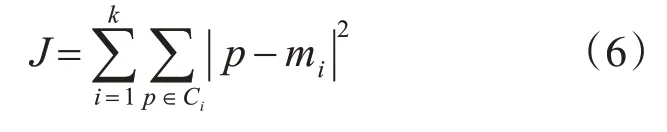
定义4准确率:

其中m为准确放到指定集合中对象的个数,N为集合中对象的总数。
利用ICKM 完成初始中心点的选取并进行聚类的步骤如下:
输入:数据集x{x1,x2,…,xn},聚类数目k
输出:完成聚类后的k个类簇及误差
Step1:初始中心点的选取
1)利用式(1),计算两对象之间的距离,记为d(xi,xj)。
2)计算每个对象的密度参数dins(xi,r),从小到大排列,记为集合D。
3)取集合D中最大密度参数对应的对象作为第一个中心点C1。
4)取距离C1最大且密度值较大的对象C2。
5)计算C1到C2的距离R12,并计算两点的中心点C12,以C12为圆心,R122 为半径,C1(C2)为起始点,顺时针旋转2π/k得到新的坐标点Cnew,取距离点Cnew最近的数据点作为第二个聚类中心。
6)判断聚类中心数是否等于k,等于则执行7),少于则以Cnew为参照点,执行5)。
Step2:执行K-Means算法
1)以这k个中心点作为初始簇中心,计算所有数据到簇中心的距离。
2)将数据对象分配到距离最近(相似度最高)的簇。
3)计算各簇内数据的平均值,更新簇中心。
4)不断重复,直到准则函数收敛,算法结束。
由算法原理可以看出,为了弥补制约坐标旋转算法的稀疏数据区域及孤立点的影响,ICKM 利用密度、距离相结合的方式确定第一个聚类中心,同时改进了旋转算法由最大距离点选取圆心的做法,该算法考虑到孤立点与中心点的相对距离,又充分考虑孤立点分布上的稀疏性,同时用马氏距离代替传统欧氏距离,保证同类簇数据间的相似度。
4 仿真实验
4.1 实验描述
用户聚类实际上是对拿到的服务器日志文件进行数据预处理,然后将处理过的数据运用聚类算法分析,最后得出结论。虽然数据预处理部分的数据噪音也会对结果产生一定的影响,本文为了证明ICKM算法的有效性,采用统一的数据集进行测试。
实验样本采用UCI 数据库中Iris 数据集,该数据集包含150 条记录,对应数据集的每行数据,Iris数据集是一个150 行5 列的二维表,为了保证实验的正确性,修改此数据集每行数据包含每个样本的两个个特征和样本的类别信息。
实验首先确定将此数据集分成的类簇数目,我们规定将此数据集分成3 个种类,运用传统算法及改进ICKM 算法进行共4 次实验,提取每个实验的样本初始中心点、SSE、迭代次数以及算法的准确率,以此作为算法有效性的标准。
为了验证大数据环境下ICKM 的计算能力,本文将 ICKM 算法和 MapReduce 计算框架相结合[16],共同承载计算压力,为了验证其有效性,实验采用不同大小规格的数据文件,对两种算法进行测试,提取聚类分析所需要的时间。
本文的实验性能参数主要有4 个:SSE、迭代次数、准确率以及大数据环境下得出结果所用的时间。
SSE:集合中心不再变化时,每个样本群的数据误差。
迭代次数:聚类结束时,集合样本所循环的次数,根据此参数,可有效判断算法性能。
准确率:能够正确到相应集合中的样本所占比数。
时间:聚类所需时间。
4.2 实验结果及分析
将150 个数据样本点作为传统算法的输入,将此划分为3个类簇,所得出的结果如表1所示。
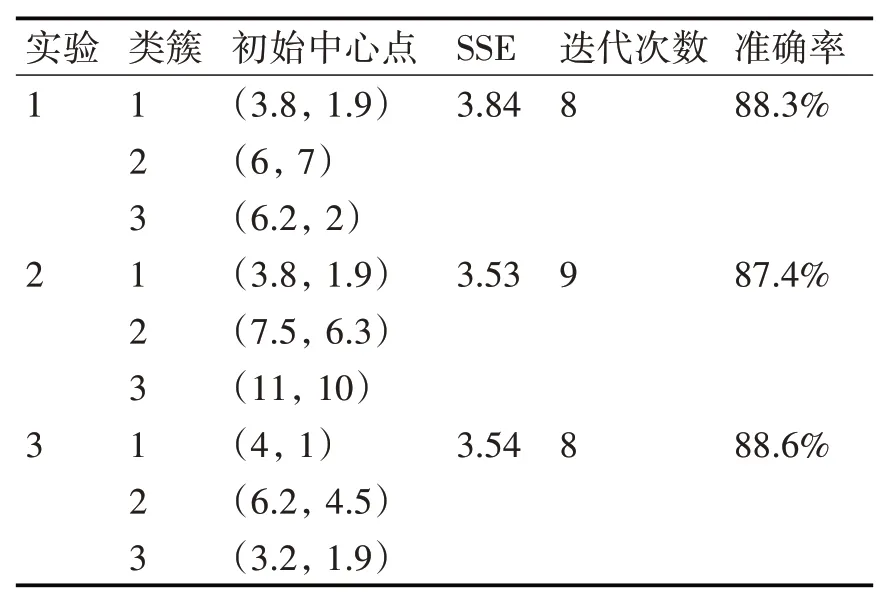
表1 KM算法对Iris数据集实验结果详情
由上表可以看出,针对传统聚类算法,在进行的3 次重复实验中,所需要的初始中心点都是随机生成,而误差最高达到3.84,聚类准确率较高,可达到88.6%,可得出此聚类结果却进行了9 次迭代过程,可以想象在大数据环境下此传统方法存在的计算速度缺陷。
以上实验,初始中心点都是随机选取,现将数据样本作为ICKM 算法的输入,同样划分为3 个类簇,所得出的结果如表2所示。
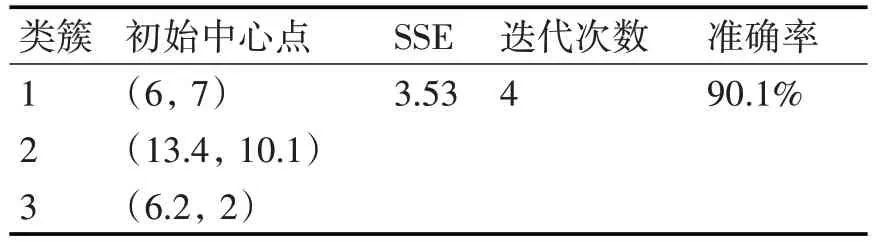
表2 ICKM算法对Iris数据集实验结果详情
由表可知,针对同样的数据集,改进的算法正确率高达90.1%;使用改进算法进行聚类的4 次迭代次数远远小于传统算法的9 次;改进的算法误差SSE 与传统算法的最小误差平齐,以上结果可得出,ICKM 算法在算法准确率及迭代次数上比传统算法理想,结合误差,改进后的ICKM 算法在效率及准确率上相对较好。
算法实现并行化的基本思路是[17]:每一次迭代启动一个计算过程,文件内数据按行存储,也可以按行分片,聚类分析的样本距离计算和数据归类步骤分别由Map、Reduce执行。
为了检验ICKM 的MapReduce 并行化即大数据处理能力,实验增加样本数量,采用了不同大小的数据文件,对ICKM 及传统聚类算发分别进行测试,最终提取得到聚类结果时所需要的时间,聚类结果的准确性,本实验暂不考虑,实验结果如表3所示。
由表可知,实验用不同大小的样本文件测试在大数据环境下不同算法的计算能力,可以看到,实现了 MapReduce 并行化[18]的 ICKM 算法在计算能力、计算速度上明显加快。
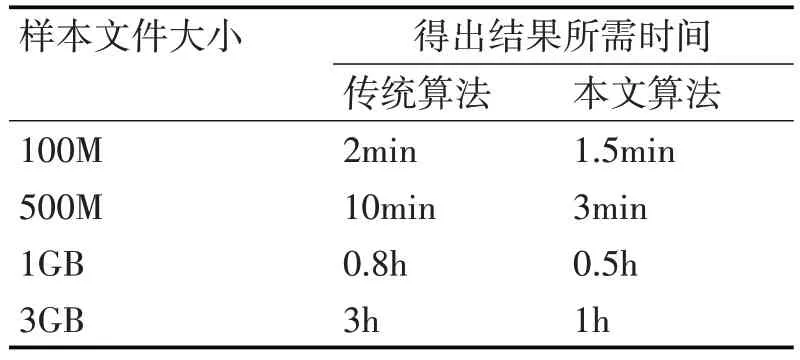
表3 大数据下算法处理能力实验结果详情
5 结语
本文针对K-Means 算法在选取初始中心点上存在的问题,以及在用户构建会话矩阵后存在的孤立点的问题,提出了密度参数与坐标旋转算法相结合的ICKM 算法,该算法利用密度参数最大的对象作为第一中心点,利用KCR 算法寻找下一个中心点,在一定程度上避免了孤立点对数据样本的影响,充分考虑用户聚类过程中建立的会话矩阵孤立点的影响的同时运用马氏距离改进了类簇内数据的相似程度。
为了提高大数据环境下的计算速度,通过借助MapReduce 计算模型实现算法的并行计算,通过框架承载数据的计算压力在一定程度上提高运算速度与准确度[19]。通过实验分析,改进后的算法较传统聚类算法有较高的准确性与稳定性。
本文利用密度参数和坐标旋转的思路,在一定程度上降低了孤立点对初始中心点选取的影响,但并未充分考虑算法处理高维数据的能力,再加上数据量的增加,可能存在大数据高纬度处理速度缓慢的问题,下一步工作中,可借助最大数算法[20]及在大数据环境下借助hive、spark等计算框架[21]进行优化,增加其大数据处理能力。
