云计算中基于遗传算法的数据布局策略*
2020-06-09覃伟荣
覃伟荣
(钦州学院资源与环境学院 钦州 535011)
1 引言
随着计算机业务应用程序的不断发展,数据量正在呈指数级增长,网络设备的增加和互联网的发展,使得数据的生成和存储容量爆炸式增长,数据中心面临着庞大的访问量[1]。传统的数据库管理无法满足数据的庞大和数据结构的复杂,进而难以实现数据存储和管理要求。分布式云计算系统架构可以为计算资源提供更高的性能,并且优化海量存储资源。然而,在分布式云计算系统中,数据密集型计算需要处理大量的数据,在多数据中心环境中,某些数据必须放在指定的数据中心内且不能传输[2]。云计算处理不可避免的引起数据中心之间的数据调度,由于数据量巨大且网络带宽有限,数据中心之间的数据调度已成为网络传输中的巨大问题[3]。
关于分布式系统中的数据布局已有很多研究[4~6],通常可以分为两种类型:静态数据布局[7]和动态数据布局[8]。大多数静态数据布局算法需要完全掌握网络环境负载信息,例如所有文件的存储时间和访问速率[9]。动态数据布局算法在线生成文件磁盘分配方案,并以此适应不同的网络负载模式,进而不必对分配文件进行先验处理。动态数据布局策略在每个请求上更新布局策略,当数据量相对较小时,Web代理缓存才会有效[10]。文献[11]基于数据相关性建立数据布局策略,但数据相关性的定义并不满足数据布局,且没有提出有效的方法来减少数据中心之间的数据调度量。
为了满足分布式云计算中数据布局的合理性,本文利用遗传算法合理布局数据策略。通过数据中心之间的数据调度建立分布式云计算的数学模型,结合适应度函数的倒数建立目标函数来评估每个个体的适合度。在初始种群按照优胜劣汰的原则生成后,每一代的进化产生更好的近似解,运用轮盘赌法则选择具有高适合度值的适当个体,并且消除具有低适应值的个体。通过遗传算法的交叉和变异操作改变数据集的布局位置。最终在在优胜劣汰的原则下找到最优个体。
2 云计算中的数据调度模型
在云计算系统中,数据存储通常达到PB 级规模,复杂多样的数据结构对数据服务类型和高级别要求的数据管理带来了巨大压力[12]。本文以数据中心之间的数据调度模型为基础,并建立精确数据布局的理论基础。
假设云计算系统具有l个数据中心,依据数据中心固有属性划分为N个不同的数据集。根据用户请求数据资源,将数据集不同的操作分配到M个计算中。数据调度的模型,如图1所示。
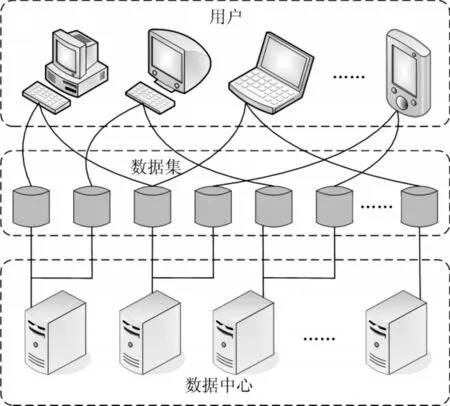
图1 数据中心之间数据调度的物理模型
假设云计算系统中的数据集合为
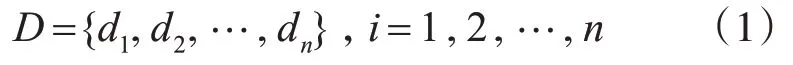
其中,n是数据集的数量,数据集di的大小为εi。
系统中的l个数据中心表示为
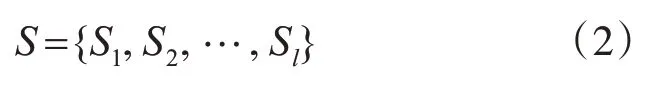
系统中的m个计算表示为
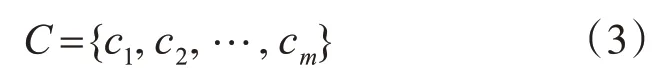
每次计算的执行频率可表示为
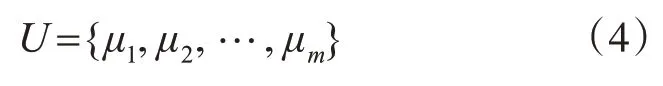
其中,μi是单位间隔内计算ci的执行频率。
本文定义一个处理因子αij,其中

因此,可以得到计算集C和数据集D的关联矩阵表示为

在本文中,数据副本不在考虑之列。同样,本文定义了一个布局因子βjk,其中
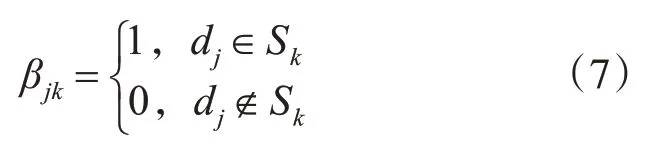
由数据集D和数据中心S之间的关联矩阵(布局矩阵)可以表示为

关联矩阵(布局矩阵)B用于表示数据中心S中存储数据集D的状态。其中,依据权重原则矩阵B中每行的元素之和为1:

其中,第k列的元素总和是数据中心Sk中存储数据集的数量,当数据集放入数据中心Sk时,存储的数据应满足Sk的基本容量,则

定义矩阵Z表示为
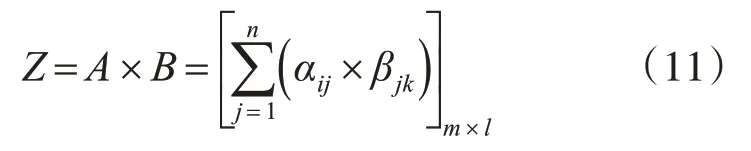
假设
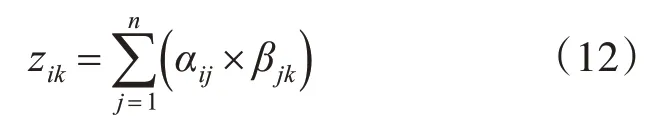
则矩阵Z=[zik]m×l,zik是数据中心一次计算ci时处理的数据集的数量。每个列中的元素的总和表示为,它是在所有的计算被执行一次时在数据中心Sk中处理的数据集的数目。定义一个函数u(zik)表示为
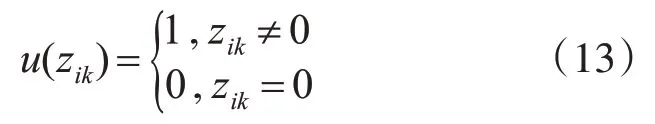
计算ci执行过程中访问的数据中心数量为计算c执行一次的数据调度次数为i当布局矩阵为B时,在单位区间内系统中所有计算的执行期间的数据调度总数可以表示为
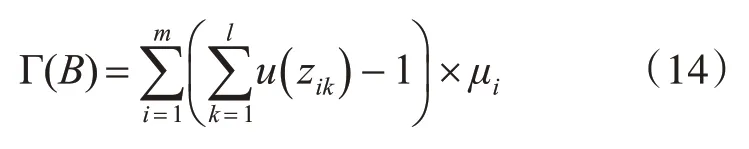
本文的目标是找到最佳的数据布局解决方案B*最小化Γ(B):
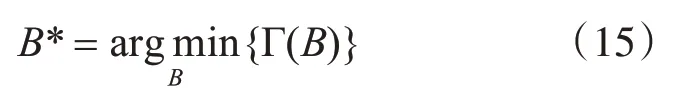
3 遗传算法
3.1 算法选择
在大数据布局问题中,由于B矩阵稀疏分布,则解空间非常庞大。传统的优化算法有穷举搜索算法、蒙特卡洛算法、遗传算法、模拟退火算法等。
穷举搜索算法[13]是搜索最优布局矩阵的直接方法。它计算出所有可能的数据布局B矩阵,然后遍历找到最小的Γ(B) ,此时布局矩阵是最优解。然而穷举搜索算法的计算复杂度很高,近似于(ln)。在分布式云计算系统中,数据集n的数量使得计算复杂度对系统求解更加困难。此外,还存在一些约束条件,如存储容量限制和无副本限制使得布局问题成为NP 难问题。因此,只有当数据集的数量很小时,才能使用穷举搜索算法。
蒙特卡洛算法[14]利用概率论和统计方法。在数据布局中,通过随机生成一定数量的B矩阵作为样本,计算每个样本矩阵B上的数据中心之间的数据调度,并找出具有最小数据调度的布局矩阵。与穷举搜索算法相比,蒙特卡洛算法的计算复杂度有所提高,但B矩阵在解空间中稀疏分布,蒙特卡洛算法的搜索效率仍然不高。它在生成布局矩阵时具有很强的规律性和约束条件。
遗传算法通过问题状态空间进行定向搜索,其比随机搜索算法[15]、枚举法[16]或演算进化算法[17]更加有效。因此,利用遗传算法可以解决大数据中的数据布局问题。
3.2 算法应用
遗传算法针对优化问题的候选解决方案群体(称为个体),每个个体适应环境的程度由适应度来表示,在每一代中,对种群中每个个体的适应值进行评估,从当前种群中随机选择具有较高适应值的个体,然后进行交叉和变异算子操作来形成新一代,最后在算法的下一次迭代中使用新一代候选解决方案[18]。
1)编码
数据中心的数据集由矩阵B表示可以表示遗传算法的数据布局,结合矩阵的字符串结构直接将布局矩阵作为基因型进行编码。
2)个体和种群
个体作为种群搜索空间中的点,数据布局的搜索空间由布局矩阵的集合组成。种群构成整个搜索空间的子集。
3)适应度函数
适应度函数在遗传算法的数据布局问题中,目标函数 Γ(B) 可以作为目标函数的倒数,即F=1/Γ(B)。
4)遗传算子
(1)选择:轮盘赌选择是遗传算法中用于选择潜在重组方案的遗传算子,更高的适合度的染色体更容易被选择。轮盘赌选择的步骤如下:
步骤1:在种群中获得N个个体的适应度值f(i)。
步骤2:假设存在个体k,其被选择的概率为p(k):
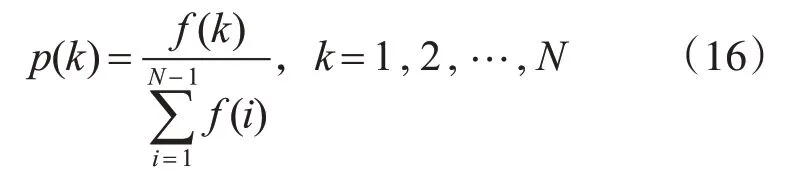
步 骤 4:生 成 随 机 数r(0 ≤r<1) ,如 果q(k-1)<r<q(k),则选择个体k。
(2)交叉:假设B1与B2配对,产生两个随机数r1、r2(0 <r1<r2<n)作为交叉点,则交换这两个点之间的基因产生子代。在布局矩阵上进行两点交叉算子的4×3布局矩阵,如图2所示。
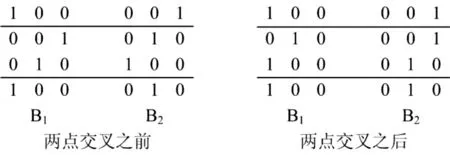
图2 两点交叉算子布局矩阵示意图
(3)变异:对于二进制字符串,染色体变异一个或多个基因。如果基因组位是1,则改变为0,反之亦然。当在布局矩阵中使用变异算子时,生成随机数r1(0 ≤r1<n),改变数据集的位置,然后生成两个随机数r2、r3(0 ≤r2≠r3<l),如果为1,则将其从1 变为0,从 0 变为 1;如果为0,则将其从0变为1,同时将同一行中的另一个1从1更改为0,以确保每行只有一个1,从而改变数据集dr1在数据中心的布局。在布局矩阵上进行两点交叉算子的4×3布局矩阵变异,如图3所示。

图3 在布局矩阵上进行变异算子
4 基于遗传算法的数据布局过程
步骤1:根据实际情况确定人口规模(G),交叉率(Pc)和变异率(Pm)。
步骤2:生成初始种群:初始种群BG(0)由G种位矩阵组成。矩阵的所有元素都设置为0,然后生成n个随机数 {r1,...,ri,...,rn} ,(0 ≤ri<l),进而生成矩阵Bi,随机数ri表示数据集di被放入数据中心,然后布局因子从0 变为1,如果生成的矩阵不满足式(10)中的约束条件,则放弃它并生成新的矩阵。
步骤3:计算种群BG(t)中每个个体的适合度MaxGen:通过矩阵乘法得到矩阵Z,即Z=A·B。矩阵Z中行i的非零元素的数目是计算ci期间访问所有数据中心的次数,当计算ci执行一次时,数据调度的数量为然后,可以计算出来在单位间隔内执行系统中所有计算期间B中的数据调度总数,即:
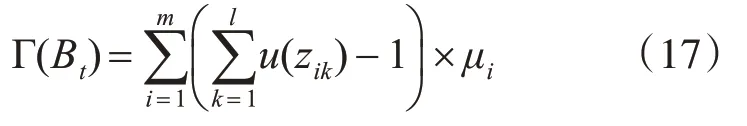
步骤4:计算种群BG(t)中每个个体的数据调度 Γ(Bt)的数量,Bt的适应值表示为F=1/Γ(Bt)。在计算每个人的适合度值和所选择的概率之后,通过轮盘赌从BG(t)中选择G个个体。
步骤5:利用交叉率Pc作为交叉操作的染色体百分比,对选定的布局矩阵执行交叉算子。
步骤6:利用变异率Pm作为参与变异操作的染色体百分比,对所选择的布局矩阵上执行变异算子。如果群体的大小是G并且每个个体具有n个基因,则待变异的基因数量为G·n·Pm。因此,可以生成随机数r(0 ≤r≤1),如果r<Pm,则相应的基因将发生变异。
步骤8:根据式(7)中的布局因子βjk的定义,在找到近似最优解B*之后,数据集dj的布局可以通过B*中的布局因子βjk来确定。
5 仿真实验
5.1 仿真环境
为了验证本文所提出的基于遗传算法的数据布局策略,构建了面向“Digital city”的数据存储和访问平台。该平台由20 个Dell Power Edge T410 服务器组成,每个都有8 个英特尔Intel Xeon E5606 CPU(2.13 GHz),16G DDR3 内存和 3TB SATA 磁盘组成。通过在数据中心部署独立的Hadoop 分布式文件系统和VMware,因此将每个服务器都充当数据中心。在千兆以太网环境下,用户可以通过Flex 4.5 开发的数字城市应用演示系统提交数据并进行计算。
5.2 仿真结果与分析
本文在数据布局中应用遗传算法对布局策略进行综合性能测试。为了验证遗传算法在数据布局中的可行性,比较了遗传算法和穷举搜索算法求解数据中心之间的数据调度,在数据集的数量很小时,不同数量的最小数据调度数和关系数据集之间的关系由折线图表示。为了比较数据集数量发生变化时,不同算法搜索的数据中心之间的数据调度。通过对3个数据中心进行400次测试计算。在遗传算法中,蒙特卡洛算法的迭代次数为106次,初始种群的规模设置为200,最大迭代次数设置为1000,交叉率和变异率分别为0.6和0.01。
数据中心之间的数据调度的算法对比,如图4所示。从图4 中,可以发现随着数据集的数量变化,三种算法的结果在每种情况下都是相同的。通过遍历得到穷举搜索算法的结果,相应的结果是最优的数据布局矩阵,因此,利用遗传算法和蒙特卡洛算法也可以找到最优的数据布局矩阵。
数据调度的最小次数,如图5 所示。数据调度的最小次数随着生成代数的增加而减小,并且优化结果更加接近最优解。其中,当数据集数量为8 个时,产生代数的收敛拐点在400。
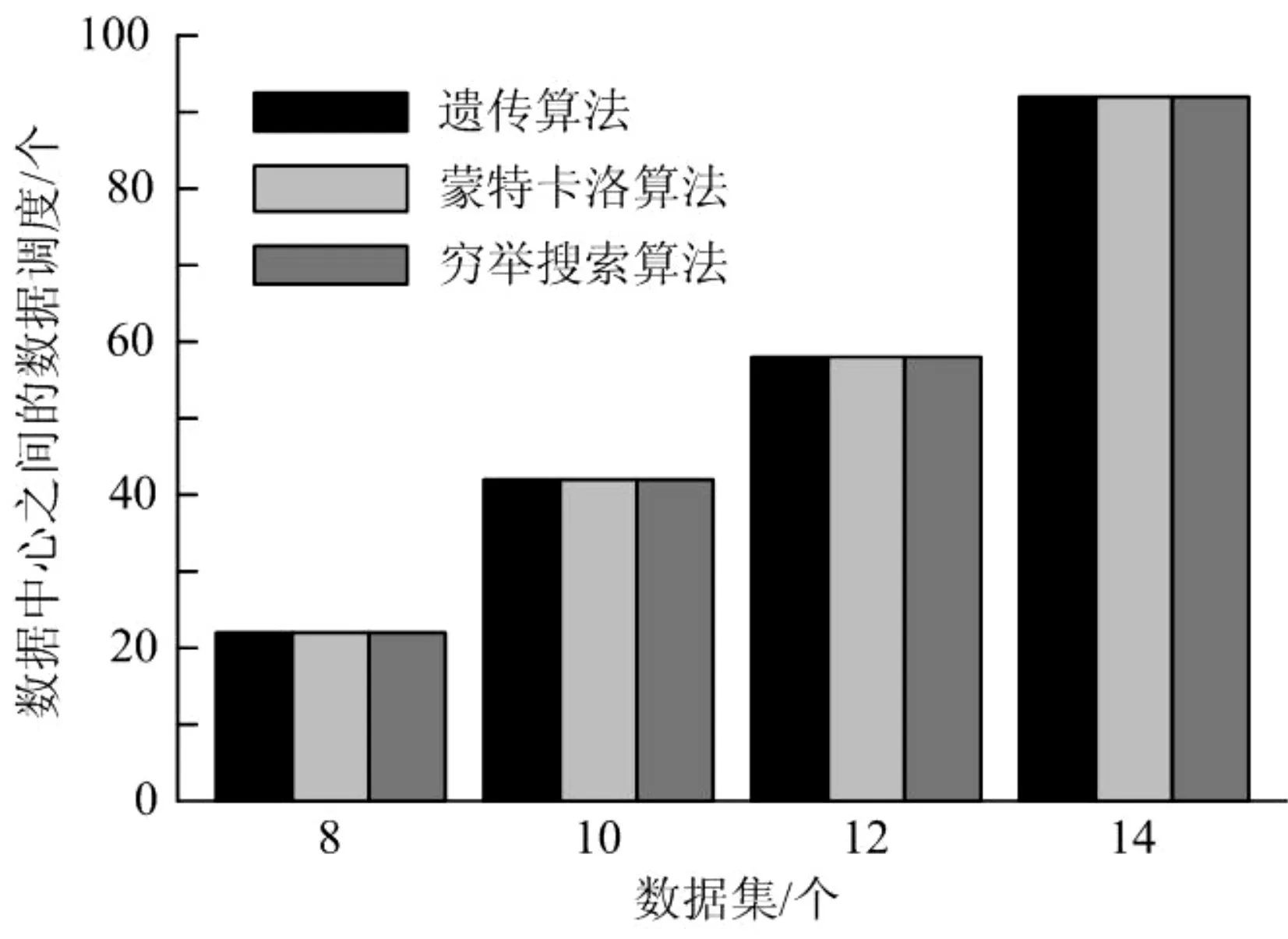
图4 三种算法在不同数据集的数据中心之间的数据调度
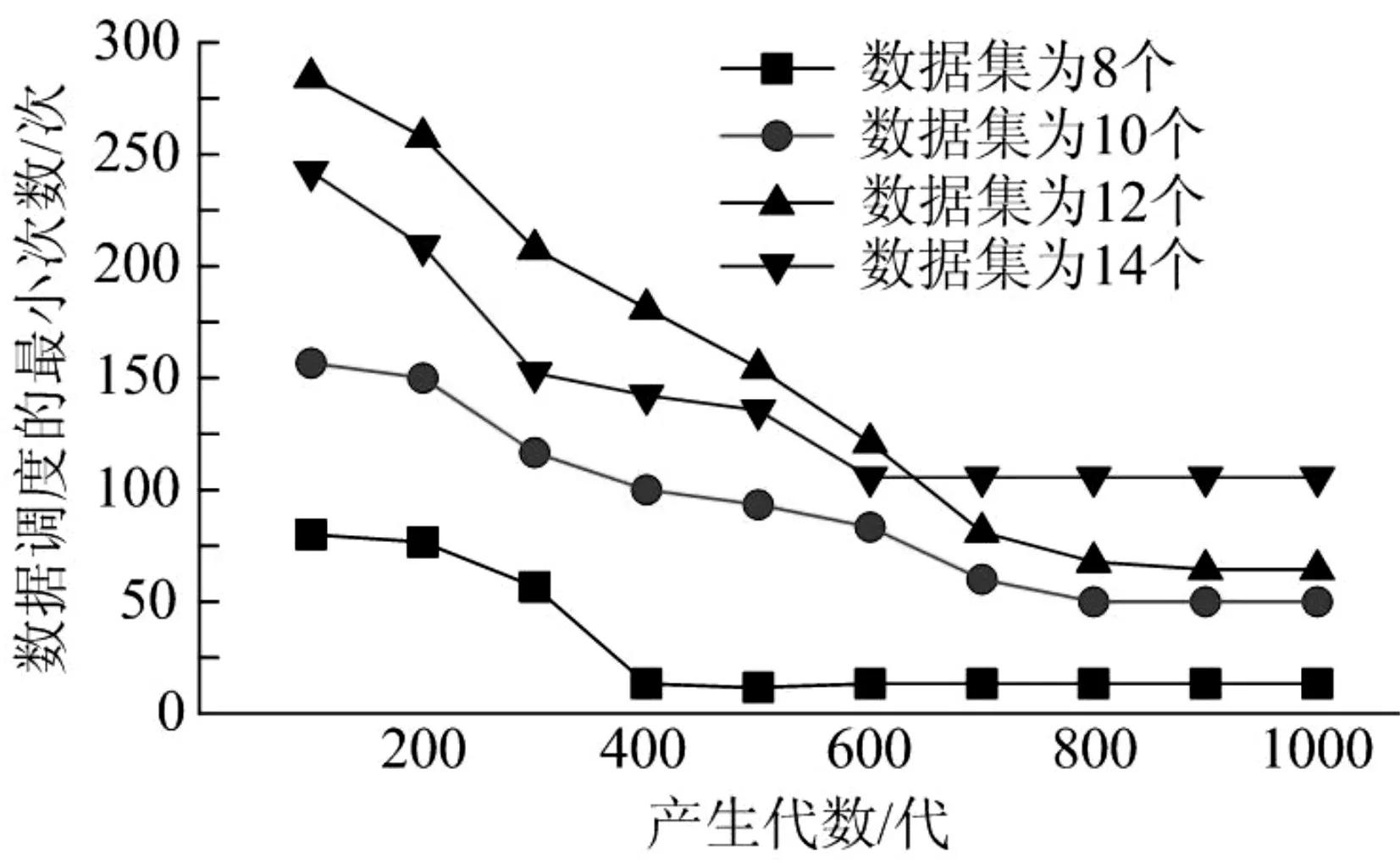
图5 数据调度的最小次数
在数据集数量较大的情况下,将遗传算法搜索的近似最优解数据中心的数据调度与蒙特卡罗算法搜索的结果进行了比较,并比较了各算法的优化时间。通过随机测试计算2500 次不同数据集的数据中心。在遗传算法中,蒙特卡洛算法的迭代次数为109次,初始种群的大小设定为5×103,最大代数设置为2000,交叉率和变异率分别为0.5和0.05。
从图6 和图7 中,可以看到数据集或数据中心的增加导致数据中心之间的数据调度的增长。通过对数据的比较,发现在遗传算法中近似最优数据布局矩阵的数据中心之间的数据调度总是小于蒙特卡洛算法。因此,对于数据布局问题,在大数据集的情况下,遗传算法的搜索结果优于蒙特卡罗算法。
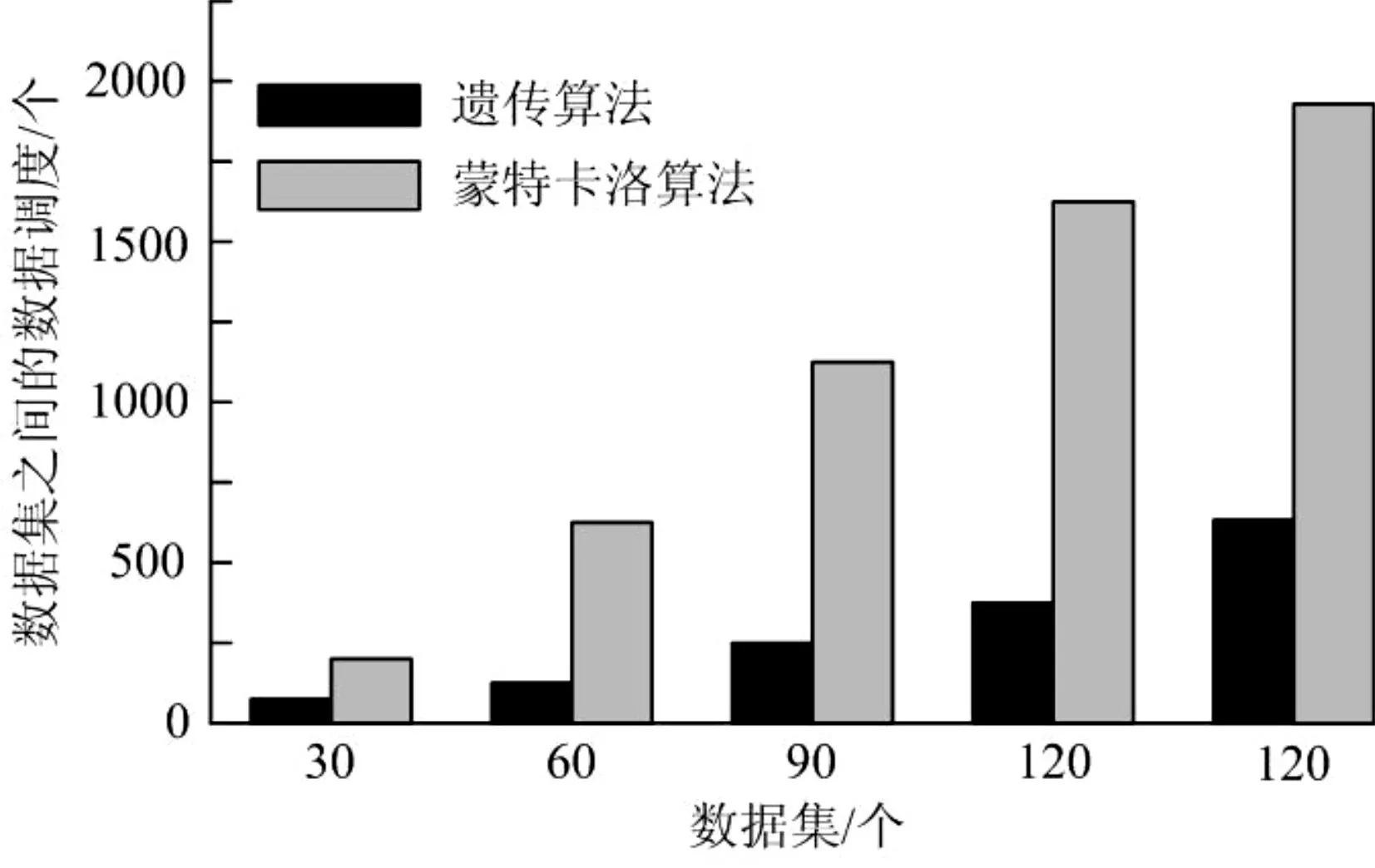
图6 不同数据集之间的数据调度
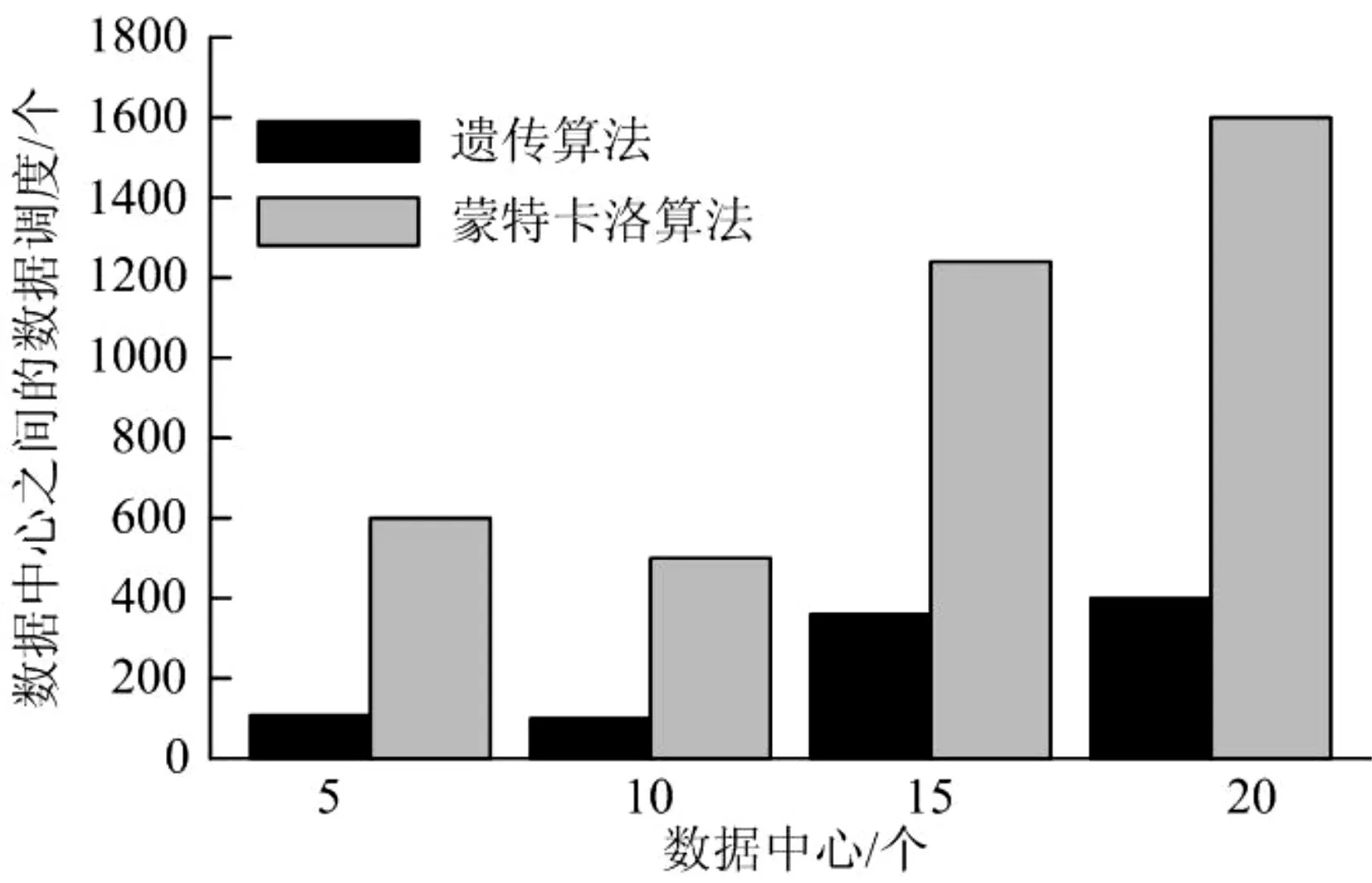
图7 数据中心之间的数据调度
图8 给出了不同数量的数据集的最小数据调度数与子代之间的关系。在实验中,数据中心的数量固定为5 个。数据集的数量固定为60 时,在30个数据中心上随机运行了2500次测试计算,如图9所示。随着子代的增加,数据调度次数变小,优化结果更接近最优解。
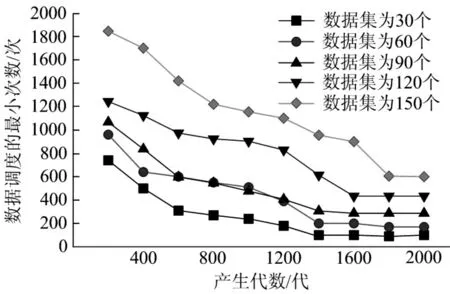
图8 数据调度的最小次数
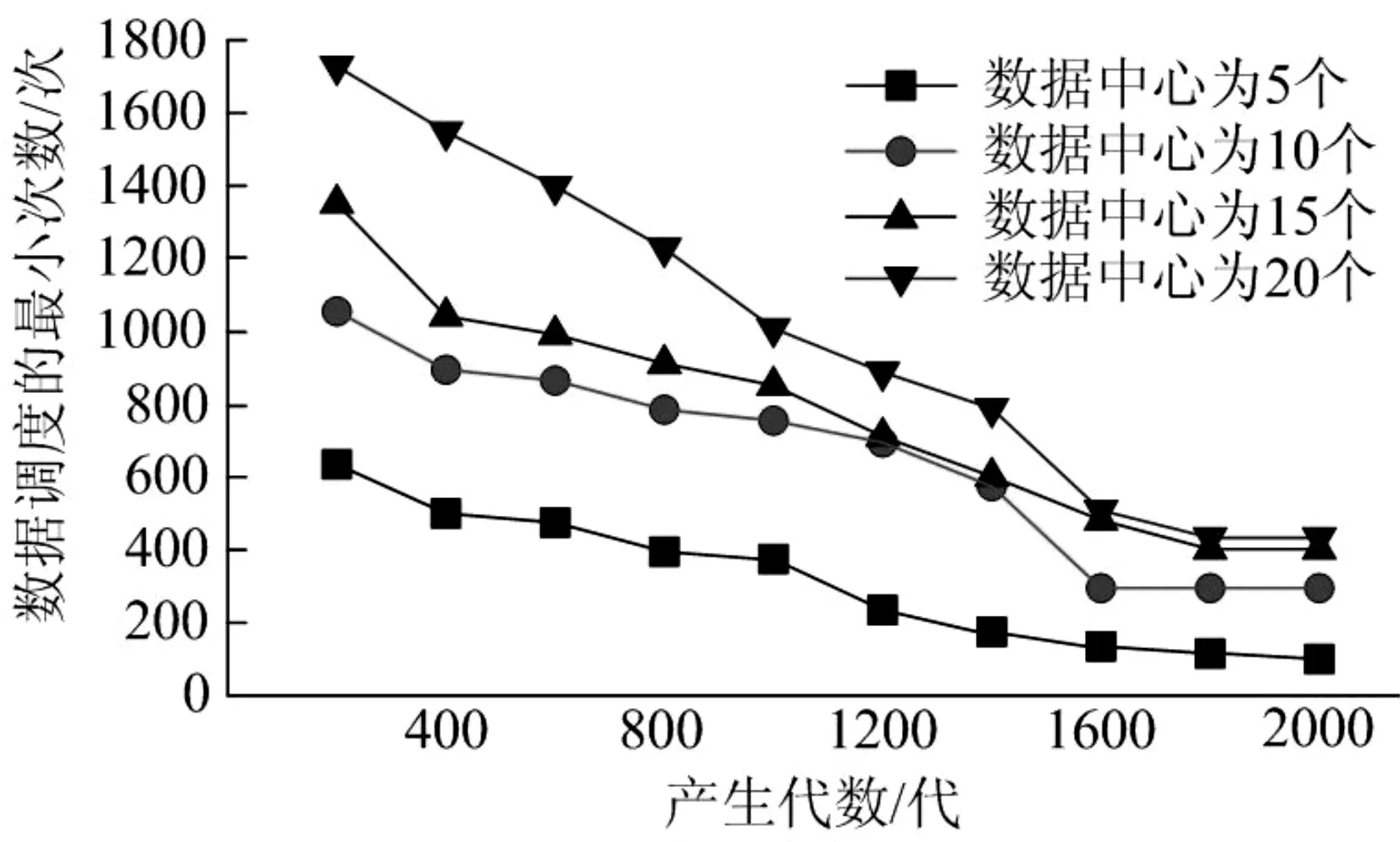
图9 数据中心中数据调度的最小次数
6 结语
在分布式云计算的环境中,将数据布局到合适的数据中心已经成为一个关键问题。本文建立了数据集、数据中心和计算之间的数学模型。利用三种不同的算法来搜索近似最优数据布局矩阵,通过将遗传算法与穷举搜索算法和蒙特卡洛算法进行比较可得,遗传算法可以找到最优的数据布局矩阵。
