一种基于大数据的出生人口预测优化算法*
2020-06-09王征征张卫钢孙道斌王培丞
王征征 张卫钢 孙道斌 张 鑫 王培丞
(1.长安大学信息工程学院 西安 710064)(2.西安网是科技发展有限公司 西安 710065)
1 引言
当前,随着社会经济的不断发展,人民生活水平和国民总体受教育程度的不断提高,人口自然发展规律已经和以前的人口自然发展规律发生了很大的变化[1]。由于人在社会中生活,所以,就会受到社会各类因素的影响,比如经济的变化,国家政策的变化,接受教育程度的变化,生活环境的变化等[2~3]。然而传统的出生人口预测算法中较为准确的分年龄组生育率算法只考虑了育龄妇女总人数、分年龄组,生育率、总生育率等因素。导致近年来的预测结果和实际结果存在较大偏差[4]。分年龄组生育率计算公式为[5]
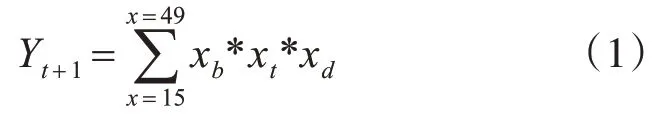
其中Yt+1表示t+1 年的总出生人口数,xb表示年龄为x岁的妇女的生育率,xt表示为t年年龄为x岁的妇女总数,xd表示年龄为x岁的妇女的死亡率。
依据近年来《中国人口和就业统计年鉴》中的相关人口数据,本文利用式(1)计算了近8 年预测出生人口数,并制作了实际出生人口数以及误差值表,如表1 所示(其中年鉴的全国抽样比为0.83‰)。
可见,预测值和实际值呈现出较大的误差而且预测结果不稳定,其平均误差率为7.7625%。2016年之所以误差很小是因为当年实施全面二孩政策,有生育二孩意愿的家庭进行集中生育[6~8]。2017年其误差值达到了2473 人,按全国抽样比0.83‰计算,其误差值达到了将近298 万人。因此,分年龄组生育率算法已经越来越不适用于当今的出生人口情况。其主要原因就是一些过去被忽略的客观因素对出生人口的影响越来越大[9]。故必须将这些客观因素考虑进来才能较为准确地预测未来出生人口数,进而掌握未来人口发展趋势[10]。
2 生育政策数字化方案
2.1 出生人口预测算法的优化思路
根据以上分析可知,不断增大的误差主要由客观因素引起。因此,本文提出一种优化算法的主要思想是,将传统的预测算法所预测的出生人口数量作为自变量X0,将客观因素中的生育政策、人均GDP、社会总抚养比、国民受教育分别作为自变量X4、X5、X6、X7。将实际出生数量作为因变变量Y0,进而通过相关算法分析得到自变量和因变量之间的确切关系。
本文从《中国人口和就业统计年鉴》和《中国统计年鉴》提取了2010-2017 年各年的人均GDP(美元)、总抚养比、受教育程度(其中受教育程度是按照历年六岁及六岁以上人口中大专及大专以上学历的人数所占的百分比进行计算)的值。由以上统计维度可知,其他客观因素都有确定的数值作为支撑,所以,要进行综合分析就必须对生育政策进行数字化处理。本文的数字化处理主要按照2010-2017 年我国生育政策所经历的三个阶段[11],一孩政策---单独二孩政策---全面二孩政策。因我国在制定一孩政策的时候允许农村户口夫妇在头胎是女孩的情况下允许其再生育一胎,故在对一孩政策进行数字化时要考虑此政策。
2.2 一孩政策的数字化
本文对一孩政策数字化结果定义为:该年头胎为男孩且为农村户口的人数占全国人数的百分比,加上2 倍的该年头胎为女孩且为农村户口的人数占全国人数的百分比,再加上该年城市户口人数占全国人数的百分比。
2.3 “单独二孩”政策的数字化
本文对一孩政策的数字化结果定义为:假设当年执行一孩政策的数字化处理结果,加上该年符合单独二孩政策的人口数占全国总人口的百分比。
2.4 “全面二孩”政策的数字化
由于全面二孩的放开,就不需要考虑第一胎为女孩且是农村户口的育龄妇女的情况,所以本文将全面二孩政策下的数字化结果定义为2。
2.5 生育政策数字化的优化及结果
众所周知,维持人口正常更替需要的总和生育率为2.1而不是理想中的2.0。其中多余的0.1是用来抵消疾病天灾人祸等突发情况[12~13]。因此为了更好地反映实际生育情况,本文对每种生育政策数字化结果再加上0.1。
结合以上分析和计算进而得到2010-2017 年近8年的自变量和因变量数据如表2所示。
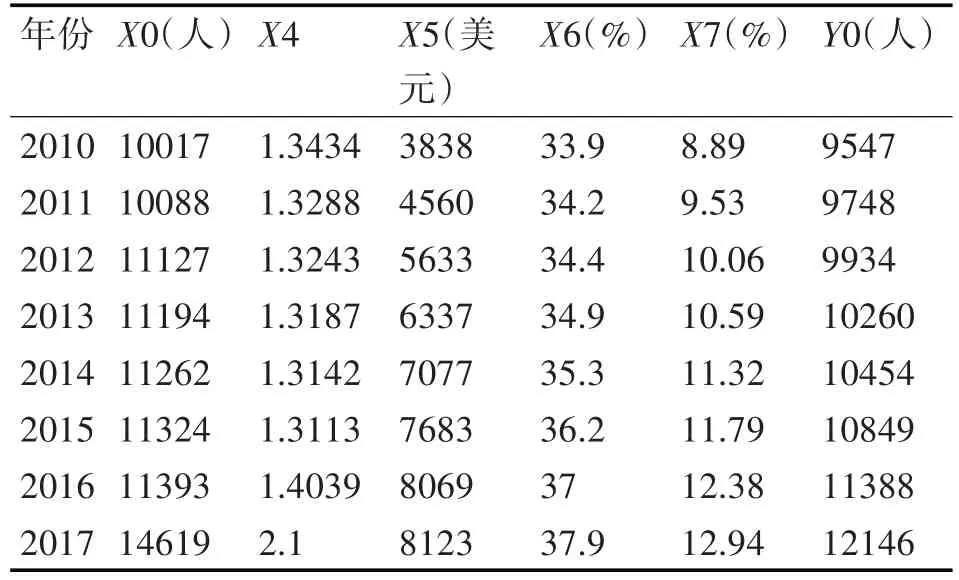
表2 历年自变量和因变量数据变化表
3 出生人口预测优化算法的设计与实现
本文利用SPSS 软件对各个自变量和因变量、自变量和自变量做相关性分析,计算出增广相关矩阵如表3所示。
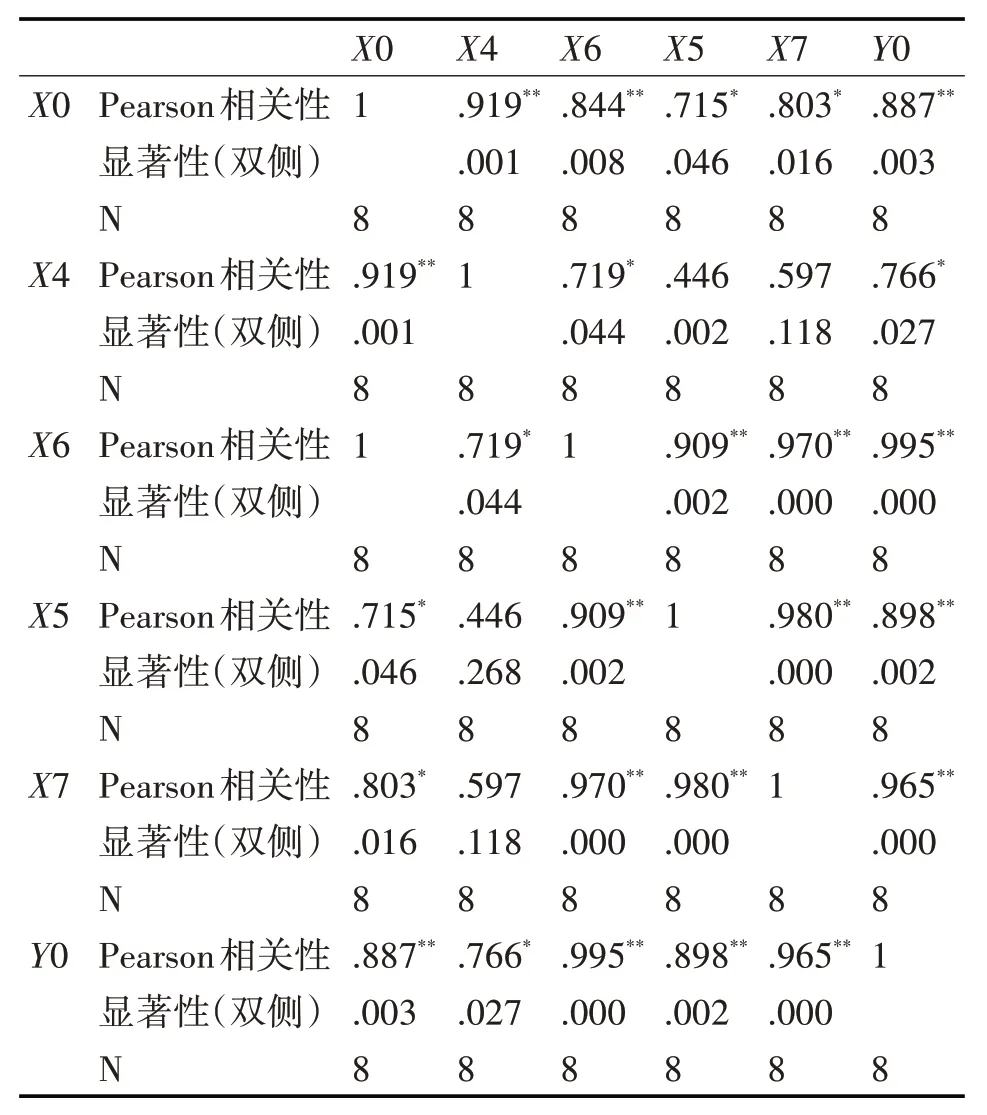
表3 计算得出的相关系数矩阵
根据**代表两个变量之间显著性非常强,*代表具有显著性可知自变量和因变量都有很强的相关性。因此,可以对其做多元线性回归处理,其输出结果如表4、表5、表6所示。

表4 模型汇总

表5 方差分析b
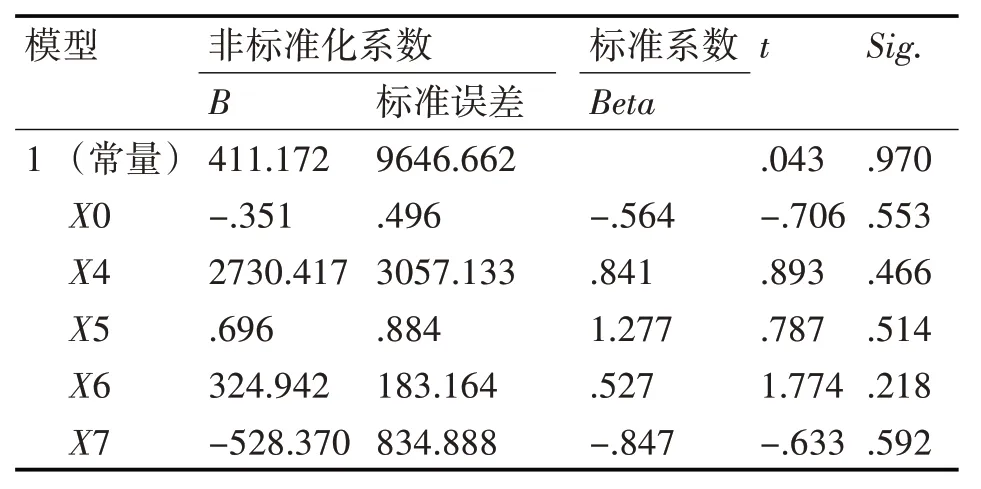
表6 系数a
由模型汇总可知,自变量一共可以解释因变量百分之99.6 的变化,由方差分析b可知Sig 小于0.05。表明回归方程是有用的。即就是说自变量整体上对因变量是可以进行线性拟合的。由系数a可知,回归系数的显著性检验最小的Sig 值是0.218,其已经远远大于0.05。由此可知自变量单独对因变量均无显著性影响。因此不能单纯地用多元线性回归方程进行回归拟合[14~15]。
由相关系数矩阵可知,自变量和自变量之间也具有较强的相关性。即就是说自变量之间有某种隐形的关联。因此接下来本文运用因子分析法对自变量和自变量进行公因子分析,输出结果如表7所示。

表7 解释的总方差
根据解释的总方差可知,最后获取的公因子有一个记为F0 ,其中F0 方差的累计贡献率为83.599。因此,这个公因子可以代替其它所有的自变量,并且能够体现出自变量包含的绝大部分信息。然后运用主成分分析法解得因子载荷矩阵如表8所示。
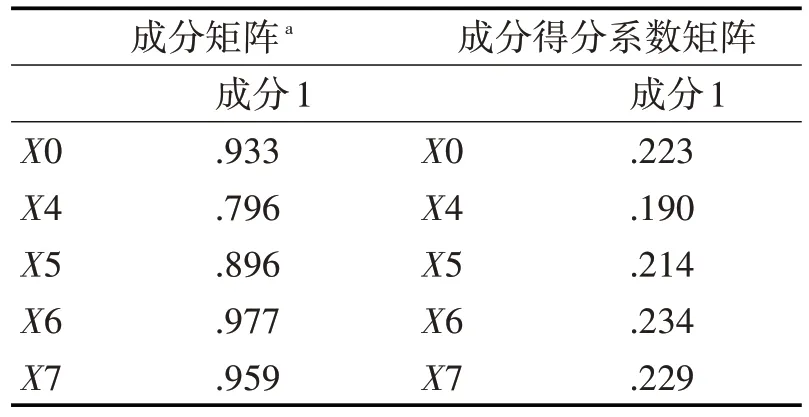
表8 成分矩阵a和成分得分系数矩阵
由成分矩阵a可得,所选出来的公因子F0 和自变量都有很强的相关性,其成分最小的为0.796,且大部分都在0.9以上。再根据成分得分系数矩阵可得因子和自变量的关系如下:

接下来利用公因子F0 对Y0 做线性回归,分析结果如表9、表10、表11所示。

表9 模型汇总
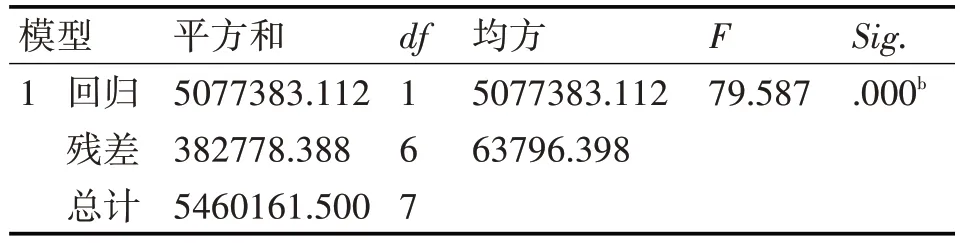
表10 方差分析b
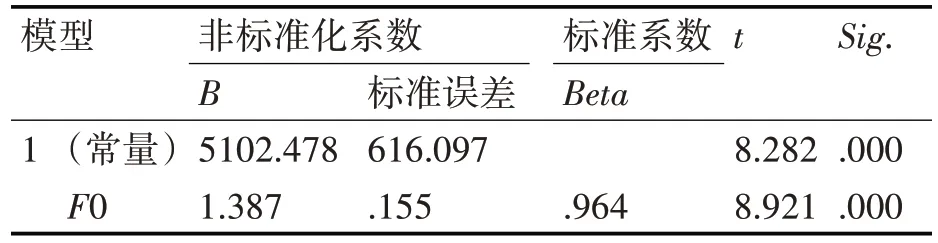
表11 系数a
由模型汇总自变量一共可以解释因变量91.8%的变化,因此得到的多元线性方程组具有较高的显著性。由方差分析b可得F0 的值为79.587其所对应的Sig 值为0.00,Sig 值小于0.05。表明回归方程是有用的。即就是说自变量整体上对因变是可以进行线性拟合的。由系数a可知,回归系数的显著性检验的Sig值是都是0.00。表明这个方程是合理的。进而得到自变量和因变量之间的关系为
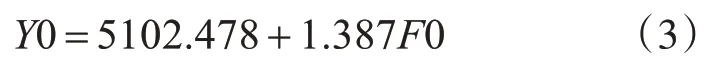
结合式(2),可得
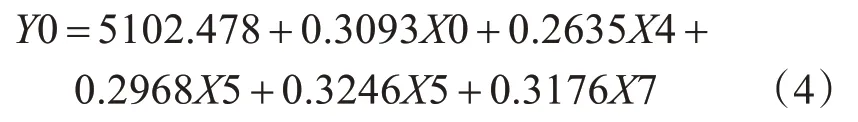
4 结果
通过结合优化后的算法可得2010-2017 年预测值的出生人口数和实际出生人口数以及差值如表12所示。
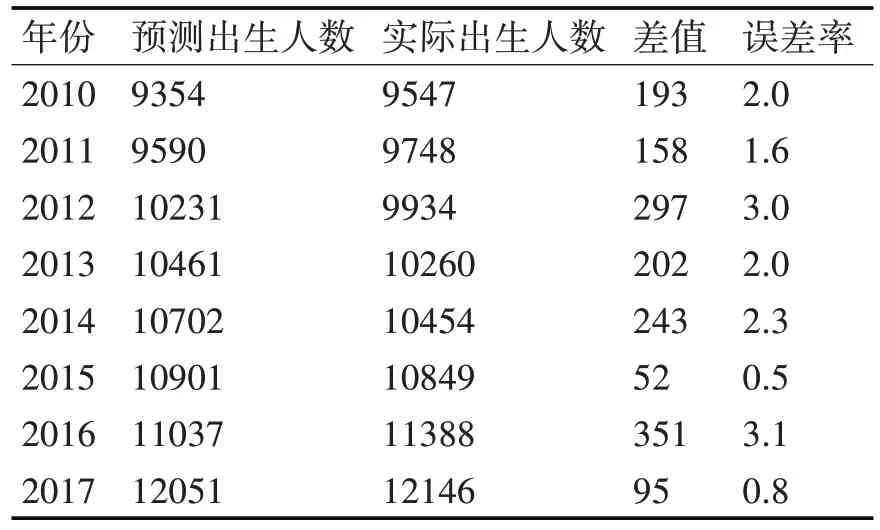
表12 优化后预测出生人口数和实际出生人口数据表
由表13可知,平均误差率为1.9125%。其中误差最大值为351 发生在2016 年,误差最小值为52发生在2015 年。而2010-2014 年都较为稳定。2015 和2016 之所以误差波动比较大,是因为2013年11 月和2015 年10 月国家分别实施了单独二孩和全面二孩政策。而2010-2014 年国家政策基本一致,其误差值趋于较平稳状态。因此,可以预见,假设在长时间内我国全面二孩政策不变的条件下,2017 年以后运用新的预测算法,其预测误差值将趋于较稳定状态。由此说明本文提出的优化算法更为准确,且其精确度由优化前的平均7.7625%提高到优化后的平均1.9125%,提高了5.85%。
5 结语
本文通过引入经济水平、文化程度、总抚养比等客观因素对常用的分年龄组生育率算法进行了优化,优化结果表明,精度得到了极大的提高,优化后的平均精度达到了1.9125%。由于我国是个人口大国,从而导致优化后的结果仍会引起几万的人口误差。因此下一步的工作应当是考虑更多的影响因素,进一步对算法进行优化。
