基于深度学习的图像显著性检测算法研究
2020-06-08杨劭然季彤宇杜聪李浩翔
杨劭然 季彤宇 杜聪 李浩翔


摘 要:现有基于深度学习的显著性检测算法中主要将条件随机场用于显著性图的后处理,并不参与整个深度学习网络的训练过程,因此,在网络训练中条件随机场并不能对网络产生反馈来优化结果,同时增加了网络训练的复杂度。本文提出了一种基于深度条件随机场网络的图像显著性目标检测方法,能够端到端地训练整个模型,同时将邻域对显著性值的影响融入网络,从而在加强显著性目标区域完整性的同时抑制背景噪声。实验结果表明所提方法取能够获得更好的显著性。。
关键词:深度学习;显著性;训练模型
引言:
随着近几年深度学习的大力发展,在众多计算机视觉领域上已经慢慢超越了传统的机器学习算法,如,图像分类、目标跟踪、语义分割等,但这并不意味着传统机器学习模型思想的过时,如何将这些传统模型融入到深度学习中并构成端到端的网络,从而兼顾深度学习和传统机器学习模型的优势是目前各领域学者讨论的热点。
本文在对传统条件随机场模型和深度卷积神经网络研究的基础上,首先对经典深度学习网络进行改进,使其更加适合显著性目标检测问题,在此基础上融入条件随机场思想,使得每个像素的显著性值不仅受到该点特征的影响,而且受到其邻域的影响,从而更好地优化目标轮廓和区域的准确性。
目前已有基于深度学习的显著性目标检测算法并取得了较好的效果,如文献直接借鉴图像分类的深度学习网络,并将提取的深层语义特征用于显著性目标检测,虽然能够准确定位显著性目标的位置并检测出目标的大部分区域,但是由于网络主要由图像分类任务训练得到,而且深层语义信息会丢失一定的低级图像特征和空间分辨率,因此在目标的边缘区域较模糊。因此一些文献从主网络中不同部分引出分支解决多尺度问题,另外有些文献从输入图像着手,将缩放剪切后原始图像的不同区域输入网络达到提取多尺度特征的目的。上述方法在结合了多尺度信息后,对于显著性目标提取有一定帮助,但仍然存在目标边缘区域显著性值较低甚至缺失的情况。为了获得更加准确的显著性目标分割结果,一些文献试图在得到网络输出的结果后,再使用 CRF 或超像素约束等方式进一步优化结果,但是这类算法中后处理往往与深度网络独立进行,这不利于整个网络的训练和收敛过程。
针对上述讨论的问题,本章目标是在提取有效多尺度特征,在高空间分辨率的低级纹理和高度凝练的深层语义特征间建立联系,相互影响与融合,得到对于显著性目标检测更具有区分性的视觉特征。在此基础上,将 CRF 融入深度网络中,利用每个像素的邻域信息共同估计该点的显著性值,从而增强目标边缘的准确性,消除目标区域的空洞,同时抑制背景区域的噪声。
本文的主要贡献可归纳为以下几点。
(1)设计了多尺度特征提取模块,用于帮助深层网络提高空间分辨率,同时加入低级纹理特征。
(2)为了充分利用深层网络的语义信息,设计了反向优化模块,进一步提高深度网络的特征表征能力。经过上述两部分网络后提取的多个特征张量中,均具有较高的空间分辨率和高级语义特征,但两者比例不同,对于不同类型的场景将发挥各自的优势。
(3)最后将 CRF 融入上述网络中,组成端到端的深度显著性目标检测网络,一方面增强了目标区域和背景区域的精度,另一方面端到端的网络也使得 CRF 的优化过程中对特征提取部分产生影响,有助于整个网络的收敛。
1.基于深度条件随机场的网络建模建立
本章提出了一种深度条件随机场(Deep Conditional Random Field,DCRF)模型来检测图像中的显著性目标。整个网络主要包含三个部分:多尺度特征提取模块(Multi-scale Feature Extraction Module,MFEM),反向优化模块(Back-Forward Optimization Module,BFOM)和 深 度 条 件 随 机 场 模 块(Deep Conditional Random Field Module,DCRFM),算法整体框图如图1所示。
其中 MFEM 在 VGG-16网络基础上扩展而来,用于捕捉图像的低级亮度、颜色和纹理特征和高级语义特征,具体细节见本章第一小节。BFOM 在 MFEM 基础上,将目标位置和形状等高级语义信息反向传播指导低级图像特征,进一步优化对图像的表征能力。最后 DCRFM 在图像特征空间建立条件随机场模型,考虑每个节点及其邻域特征和显著性值,共同优化得到最终显著性值,第 三小节给出了该模块的详细解释。
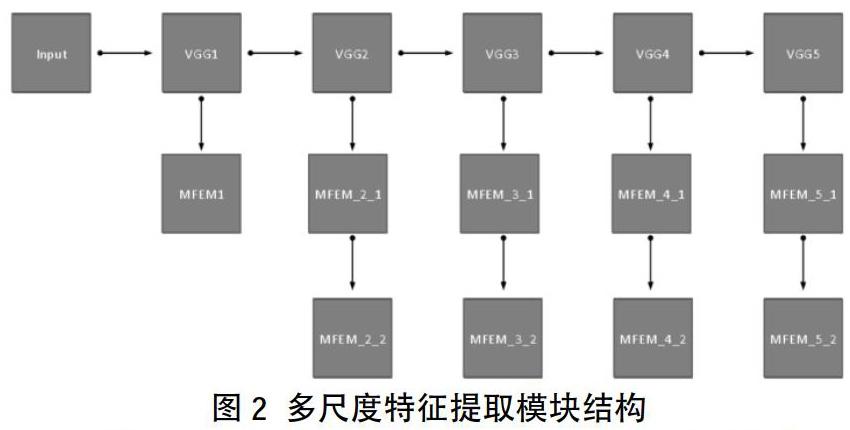
1.1 多尺度特征提取模块
多尺度特征提取模塊(MFEM)主要用于提取不同尺度下的低级图像特征和高级语义特征。众所周知,深度卷积神经网络在提取图像特征时是从低级到高级的递进过程,在浅层网络主要提取图像固有的,内在的低级特征,如亮度、颜色、纹理等,同时浅层网络具有较高的空间分辨率,能够保留图像的纹理和边缘细节信息。在较深层的网络则对浅层网络提取的初级特征进一步提炼,产生高级语义特征,但同时也丢失了大量细节信息,具有较低的空间分辨率。显著性目标检测任务需要精确分割出目标的完整区域,因此一方面需要浅层网络中的高空间分辨率信息保证目标边缘的准确,另一方面需要深层网络正确提取场景中最显著的目标区域。
基于上述考虑,本小节提出 MFEM 同时兼顾空间分辨率和高层语义信息。鉴于 VGG-16 网络在图像分类上的有效性和简洁性,使用 VGG-16 作为 MFEM 的基础网络。方便起见,统一定义卷积神经网络的输入为网络中训练参数和偏置参数,其中表示第l层网络,则第l层网络的输出可表示为其中为激活函数,?为卷积操作。我们首先将输入图像尺寸统一转换为 352×352,并设定网络输出的显著性图尺寸为 176×176,最后通过双线性差值(Bilinear Interpolation)将每幅图像转换为实际尺寸。整个多尺度特征提取网络结构如图2所示,首先去除原始 VGG-16 网络中的全连接层,并使用前五个卷积模块,为了兼顾空间分辨率和高层语义信息,分别对 VGG-16 网络的每个卷积模块进行进一步处理。具体而言,最浅层模块中包含丰富的低级图像特征和较高空间分辨率,在此只简单使用 128 通道的 3 × 3 卷积核进一步提炼特征。对于中间及深层网络模块,首先使用 128 通道的 3 × 3 卷积核统一每个模块输出的通道数,然后对每个模块输出的尺寸进行 128 通道的 5 × 5 卷积核的反卷积操作,恢复空间分辨率。经过 MFEM 模块得到了从浅层到深层总共 5 组 176 × 176 × 128 具有较高空间分辨率的卷积特征。
1.2 反向优化模块
上一节中MFEM在网络的不同部分提取了 5 组具有多尺度信息的卷积特征,主要赋予深层网络提取的语义特征较高的空间分辨率,但是对于浅层网络而言,并未受到高层语义信息的优化和引导。基于此,本小节试图将深层网络提取到的目标位置和形状等语义特征反向优化浅层网络,整体框图如图3所示。
定义第层模块第部分的MFEM输出为,第m层模块的BFOM 输出为,则第个模块的反向优化函数为:
其中⊕表示在卷积特征维度进行叠加。
经过 MFEM 和 BFOM 后的 5 组卷积特征均同时具有较丰富的低级纹理特征和高级语义特征,差异在于对低层和高层信息的侧重不同,在浅层网络更加侧重于低级纹理特征和高分辨率,而深层网络更加侧重语义信息和显著性目标的区域和位置特征,为了减少各层模块特征的损失,对 5 组特征分别使用 2 通道的 1 × 1 卷积核将其降为两个通道的特征,然后对所有通道的特征进行加权求和得到加权特征:
其中为第m个模块特征的权重。最后,将和模块的融合结果分别输入 Softmax 函数,将特征映射到二值显著性空间,并分别与真值类标图进行对比计算损失函数。假设估计的显著性图为,则可定义为:(式3)
本小节使用交叉熵函数计算显著性图与真值类标图中每个像素点的损失,则损失函数可表示为:(式4)
其中表示像素i的类标,表示像素i为显著性区域的概率,* 表示weighted和fuse两种特征下的结果。因此可以得到和两个特征层面的损失函数。
1.3 深度条件随机场模块
经过上述两节介绍的网络处理,从同时兼顾图像纹理特征和语义特征的特征模块中直接估计出了图像中每个像素显著性值,虽然这些特征能够较好地表示图像的内容,但是并未考虑像素及其领域之间的相互作用关系,因此容易出现目标边缘模糊或目标区域缺失等情况,如图5所示。为了克服上述问题,本小节在特征层上,以每个像素作为节点N,在相邻像素间,即以节点为中心的8领域上建立连接E,得到图模型。
在建立CRF之前,为了考虑模型的复杂性和有效性,本小节在22×22的特征图上建立CRF,具体而言,从上两节介绍的特征提取网络中选取VGG4模块和MFEM_5_2模块中第一次反卷积的结果共同组成22×22分辨率下的特征,在此基础上建立一元网络和二元网络分别提取深度特征作为CRF中一元和二元势函数的输入。
与传统CRF模型类似,在节点i上同时考虑一元势函数和二元势函数,对CRF的学习和优化过程实际是最大化似然函数或最小化能量函数,其中:
考虑到本章中建立的图模型是有环图而非树状结构图,因而在优化过程中较为耗时,同时由于深度学习网络的学习过程中存在大量迭代,因此如果使用传统的随机梯度下降(Stochastic Gradient Descent,SGD)算法优化 CRF 模型,整个网络的学习过程将会非常耗时。
基于上述考虑,本小节引入分段学习(Piecewise Learning)的方式优化深度学习网络中的 CRF 模型,因此条件似然函数可以定义为独立势函数的乘积:
其中,一元势函数和二元势函数可分别表示为:
其中为一元网络的输出,为二元网络的输出。可以看出,和均为在显著性类标上的传统 Softmax 函数,因此在网络迭代过程中能够很容易地计算其梯度并融合到整個深度网络中组成端到端的深度显著性提取网络。DCRFM 的损失函数可表示为求取最小负对数似然函数:
综上所述,本章提出的 DCRF 图像显著性目标检测算法总体损失函数为:
2.实验部分
本章算法在 Ubuntu 14 系统上的 Tensorflow 1.2 环境中完成。网络中 VGG1 -VGG5 模块使用参考文献 [2] 中的预训练模型初始化,其余所有新增卷积与反卷积层中的权重均使用随机截断正太分布(Truncated Normal Distribution)初始化,使用初始学习率为 10?6 的 Adam 优化算法进行训练。训练集参考文献 [3] 中的方式,从MSRA-B 中选取 2500 张图像作为训练,500 张作为验证,剩余 2000 张作为测试,本章不使用验证集,将 2500 张训练图像和 500 张验证图像共同组成本算法的训练集,同时为了增加数据量,再训练过程中对每幅图像进行四个角度(0°,90°,180°,270°)的翻转,最终总共获得 12000 张训练样本。此外,输入图像尺寸统一修改为 352 × 352,网络输出显著性图分辨率为 176 × 176,使用双线性差值还原为原始尺寸后再与真值类标图进行对比与评价。在每个循环中CRF训练部分每次迭代 3 次。在配置为单块NVIDIA Titan X GPU 上训练 20 个 epoch 所用时间约为 9.4 小时,测试阶段处理每幅图像的时间约为 0.14 秒。
本小节主要对比 9 种效果较好的算法,包括 DS,Amulet,MDF,KSR,UCF,HS,MR,BSCA和wCtr。其中最后四种为传统显著性目标检测算法,其余 5 种为基于深度学习的显著性目标检测算法。公平起见,上述对比算法均使用作者公布的代码和默认参数设置,或者直接使用作者提供的结果。如图 3.7 所示,在 PR 上可以看出在 HKU-IS,PASCAL-S 和 SOD 数据库上均取得了最好的效果,而在其余两个数据库上效果略逊于最好的算法。在 Fm 曲线对比结果中,DCRF 除在 ECSSD 上略逊于 Amulet 算法外,其余四个数据库上均处达到了最好的效果,此外 DCRF 的 Fm 曲线在大部分阈值中均能够保持较高且稳定的状态,说明在目标区域中均保持较高的显著性值。
图7五个数据库上 PR 曲线对比结果
总结
本文提出了一种端到端的基于深度条件随机场的图像显著性目标检测算法,主要包含多尺度特征提取模块,反向优化模块和深度条件随机场模块。其中多尺度特征提取模块用于增强深层网络的空间分辨率信息,反向优化模块则帮助浅层纹理特征融合高层语义信息,在此基础上,条件随机场模块的引入有助于优化显著性目标区域,增强目标边界的准确性,同时保证目标区域更加完整和均匀。五个数据库上的结果证明了 DCRF 算法在不同场景下的有效性和优越性。
作者简介:
杨劭然(1998年6月——),男,汉族,河南南阳人,本科在读,上海工程技术大学,电子信息工程方向。
季彤宇(1997年9月——),男,汉族,山西阳泉人,本科在读,上海工程技术大学,电子信息工程方向。
杜聪(1998年9月——),男,汉族,山西大同人,本科在读,上海工程技术大学,电子信息工程方向。
李浩翔(1998年2月——),男,汉族,河南安阳人,本科在读,上海工程技术大学,电子信息工程方向。
