基于领域词典与CRF双层标注的中文电子病历实体识别
2020-06-08龚乐君张知菲
龚乐君,张知菲
1) 南京邮电大学计算机学院、软件学院、网络空间安全学院,南京 210023 2) 江苏省大数据安全与智能处理重点实验室,南京 210023
近些年来,医疗信息化以及大批在线问诊网站、病例交流网站的迅猛发展产生了海量的电子病历. 电子病历中包含了大量重要的临床资源. 如何利用电子病历所包含的大量潜在信息,成为目前热门的研究方向之一. 作为文本挖掘的基础任务,命名实体识别在病历文本中需要识别的实体类型主要为疾病名称、症状、医疗人员采取的措施(包括检查措施和治疗措施)、药品名称等医疗实体.
有研究表明,在中文电子病历中,实体分布的密集程度远高于通用领域文本[1]. 中文电子病历语料中实体字符所占比例接近中文通用语料的2倍,这说明了中文电子病历是一种知识密集型的文本,其数据具有相当的研究价值.
命名实体识别任务,常常被作为序列标注任务来处理[2]. 机器学习中特征的选择情况将会直接影响实体识别的效果,因此大部分中文医疗实体识别研究集中于构造和选择不同特征. Wang等[3]利用字符位置信息和短分句对症状实体进行识别,在中医文本语料上达到了95.12%的F1值. 文献[4−7]研究了语言符号特征、词性特征、关键词特征、词典特征、分词特征、词块特征等多特征组合与多种学习器组合对病历实体识别的影响. 随着深度学习[8]技术的发展,利用深度神经网络对中文医疗实体识别的相关研究[9−13]也在进行,其模型基本为序列模型— —循环神经网络(Recurrent neural networks, RNN)及其变体.
英文电子病历命名实体识别的相关研究[14−19]已经形成了相当完善的模式. 相比之下,中文电子病历命名实体识别工作刚展开不久,缺少充足的标注语料. 除此之外,中文医疗实体识别仍存在以下难点:
(1)中文电子病历中的医疗实体数量众多、类型丰富,难以建立大而全的疾病、药品或是科室检查等医学关键词词典. 对于固定不变的医学词典而言,病历文本中将不断地有新的未登录词出现.这些新的医疗实体变化多样,更加难以收录.
(2)中文电子病历中的医疗实体长度不定,大部分医疗实体长度长于通用实体. 医疗实体构成结构较为复杂,存在大量的嵌套、别名、缩略词等问题,没有严格的构词规律可以遵循[20].
(3)在中文电子病历的不同部分,医疗实体的类别属性有所差异,进行命名实体标注时存在分类模糊的问题,无法清晰判断某些命名实体之间的界限. 常见的是症状表现的实体也经常出现在疾病实体名中,这种互相交叉包含的情况大量存在.
针对以上问题,本文提出了一种基于领域词典与条件随机场(Conditional random field, CRF)的预标注-二次标注双层标注模型(Double layer annotation model, DLAM). DLAM并不着眼于人工选择词法、句法特征,也并非单纯的基于词典的命名实体识别,而是将两者结合起来,通过一次预标注-二次精确标注的形式将人工构建的准确性和机器学习的自动性融为一体. 实验结果表明,该双层标注模型能够很好地完成中文医疗实体识别任务.
1 相关方法
中文医疗实体识别问题可转化为序列标注问题. 序列标注问题即对于输入序列A=a1,···,an和标签集合L,确定输出标签序列B=b1,···,bn(bi∈L,1≤i≤n). 其本质是对输入序列中每个元素根据上下文进行分类.
基于词典与规则的实体识别方法虽然人工开销大,但对登录词的识别效率极高,领域词典包含的领域特征信息也非常丰富. 因此考虑通过构建小规模的领域词典,将词典的准确性与机器学习发现未登录词的能力结合起来.
1.1 统计方法构建领域词典
中文病历文本的语言特征和用词构成与通用文本差异甚大,在由病历文本构建领域词典的过程中,为了使领域词典中收录的词更具有领域专业性,使用新闻语料作为筛选语料库.
病历文本经过分词后提取每份文本中TFIDF[21]值最大的前50词W={wi|1≤i≤50},计算wi在新闻语料库中的归一化词频tfi,m为预先设置的阈值,当满足tfi≤m时,将wi加入领域词典中.
1.2 基于领域词典和CRF的双层标注模型DLAM
CRF是一种无向概率图模型,其优点在于为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息[22]. 由于考虑了输出标签序列的联合概率分布,线性链条件随机场被大量应用于序列标注问题.
本研究中提出的基于领域词典与CRF的双层标注模型DLAM是在标准线性链条件随机场的前面增加一层基于领域词典匹配的预标注层.
中文电子病历医疗实体识别任务中,输入序列X为中文电子病历文本,输出序列Y为对应的标签序列. 在给定输入序列X=x1,···,xn的情况下,通过领域词典匹配得到预标注序列D=d1,···,dn,最大化输出标签序列Y的联合条件概率的似然估计. 对于输入序列X,最有可能的输出标签序列Y:

DLAM将预标注结果序列D和输入序列X共同作为CRF的输入. 因此,DLAM中的条件随机场为给定X,D条件下的联合条件概率P=(Y|X,D).在随机变量X取值为x的条件下,随机变量D取值为d,随机变量Y的条件概率如下:
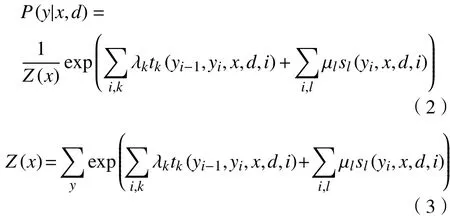
与标准线性链条件随机场类似,式(2)、(3)中tk和sl是特征函数,λk和µl是对应的权值.Z(x)是规范化因子,求和是在所有可能的输出序列上进行的. 模型的训练过程即是在特征函数下,训练其对应的权值.
DLAM算法步骤如下:
(1)输入:病历文本序列X=x1,···,xn;
(2)构建领域词典S;
(3)文本与词典进行匹配的结果为S∩X;
(4)打碎S∩X结果形成基元,得到一层标注序列:D=d1,···,dn;
(5)抽取文本的基本特征集F=f1,···,fn;
(6)将一层标注结果D及文本特征F投入CRF模型,得到二层标注序列Y=y1,···,yn;
(7)输出:标注结果.
详细过程如图1所示.

图 1 基于领域词典与CRF的双层标注模型Fig.1 Double-layer annotation model
2 实验数据
由于国内对患者隐私的保护政策,医院电子病历较难获得. 因此,选择从“爱爱医”网站上爬取了1064份呼吸科病历文本和30262份不限科室病历文本作为实验数据. 1064份呼吸科电子病历中的864份用于1.1节所述统计方法构建领域词典,200份在参考文献[23]以及英文I2B2、UMLS语义类型[24]的基础上,标注出疾病、症状、药品、操作四类医疗实体. 标注规范如下:
(1)疾病:医生对患者做出的诊断或以“病”、“症”作为结尾的实体统称为疾病. 如“肺内隔离症”.
(2)症状:由疾病导致的不适表现、异常表现、正常或异常的检查结果或者患者的不健康状态以及患者自述中的病史介绍. 如“声音嘶哑”、“无结核病史”.
(3)药品:诊疗过程中给予患者的具体药物名称或药物类别. 如“地塞米松”、“抗生素”.
(4)操作:包括检查项目和诊疗手段. 检查项目是指,为了发现、证实或是否认疾病,希望得到更多关于疾病的信息而施加给患者的检查项目.诊疗手段是指,为了缓解不适症状或者解决疾病而施加给患者的干预措施和治疗程序. 如“拍胸片”、“抗感染”、“胸腔穿刺术”.
表1所示为训练、测试语料数据分布.
另外,在本研究中,为了验证DLAM模型效果,选择注意力深度神经网络BiLSTM-Attention-CRF作为参照. 因此,30262份不限科室未标注电子病历使用Word2vec工具,采用skip-gram模型,基于字粒度分别训练出50维、150维、300维的字嵌入.

表 1 训练集、测试集实体分布情况Table 1 Distribution of entities among the training set and the test set
对于实体识别的序列标注任务,标签由两部分构成:实体类别和实体中的位置. 本研究采用BIO表示法以字符为最小标注单位来表征该字符的标签. BIO表示法中,B代表位于实体的开始位置,I表示位于实体内部,O代表不为实体. 因此,标注语料中共包含4类实体,9类标签.
领域词典的构建除了1.1节所述统计方法外,还借助了外部专业资源,来源有:
(1)互动百科“呼吸系统疾病”全部词条以及每个词条“概述”部分的分词结果;
(2)“中国公众健康网”上“肺和呼吸相关疾病”全部词条以及每种疾病页面的“相关症状”和“相关药品”;
(3)CHPO“呼吸系统异常”全部条目,不仅包括实体本身,还包括其HP编码.
以上多种途径构建出的初始词典经过去重、人工去除噪音、人工分类,最后整合成共3943词的“呼吸科领域词典”,其中包括疾病、症状、操作、药品、关键词、器官、位置、否定八类. 表2展示了该领域词典的构成.
除与医疗实体识别任务中目标实体相同的四类外,领域词典中还额外定义了四种类型的关键词. 这是因为中文病历文本存在复合实体较多、短句内句子成分缺失严重的问题. 为了更好地识别出医疗实体,考虑在利用领域词典进行的预标注部分采用范围更广的关键词匹配策略,不仅标注出目标实体类型,也标注出对目标实体的修饰关键词. 具体含义如下:
(1)关键词:提示将出现症状,因对关键词的症状描述多样,所以单独列出. 如:“食欲”.
(2)器官:指人体器官或部分肢体,因同一症状可能发生于不同器官或器官的不同范围而单独列出. 如:“肺”.
(3)位置:为了描述器官的某部分而单独列出,在句子成分缺失的短句中也能直接代指器官的某部分. 如:“左下”.
(4)否定:病历文本中常有描述患者并未出现某些症状或并未患某种疾病的情况,直接通过词典匹配无法判断这种情况,可能造成语义相反.如:“无”、“未闻及”.
3 实验结果及讨论
为了综合考虑模型在整个数据集上的性能,本文中采用宏平均指标(Macro-Average). 宏平均是指每一类性能指标的算数平均值,具体可分为:宏精确率(Macro-P)、宏召回率(Macro-R)和宏F1值(Macro-F1).
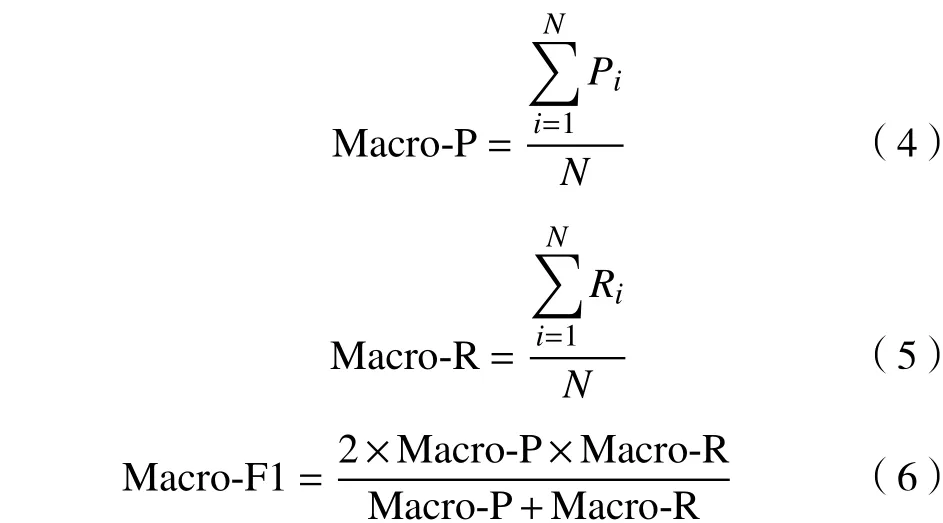
其中,N表示实体类别总数,Pi表示每一类实体的精确率,Ri表示每一类实体的召回率.
以不采用预标注层、仅使用语言符号特征和上下文特征的单层CRF作为基线,首先讨论领域词典是否对CRF标注产生积极影响. 上下文窗口大小均设置为5. 表3所示为该组对比实验结果.
可以看到,双层标注模型DLAM同时结合了领域词典的准确性和CRF的自动学习能力,将中文医疗实体的识别效果得到了极大提升. 不同于单层CRF宏精确率和宏召回率相差较大的情况,DLAM的宏精确率和宏召回率几乎相等,达到了一个很好的平衡.
第二组对比实验是研究采用了注意力机制[25]的深度神经网络BiLSTM-Attention-CRF[26]对中文医疗实体的识别效果. 根据预训练的不同字嵌入维度和一组随机初始化embedding向量进行对比.表4为该组对比实验结果.

表 2 领域词典构成情况Table 2 Distribution among the domain dictionary
从实验结果可以看出,预训练字嵌入的质量对深度神经网络的识别结果会产生较大影响. 字嵌入维度过小,会导致丢失隐含的语义信息;字嵌入维度过大,则会带来噪音. 字嵌入维度应如何设置与训练语料的大小、语料的语言特点有关.

表 3 CRF对比实验结果Table 3 Comparison experiment results of CRF %

表 4 BiLSTM-Attention-CRF对比实验结果Table 4 Comparison experiment results of BiLSTM-Attention-CRF %
值得注意的是,深度神经网络相比单层CRF能明显提高医疗实体的召回率.
以150维字嵌入的结果作为BiLSTM-Attention-CRF进行中文医疗实体识别的最好结果,从实体级别以精确率P和召回率R作为标准,比较DLAM模型与BiLSTM-Attention-CRF的识别效果. 如图2,图3所示.
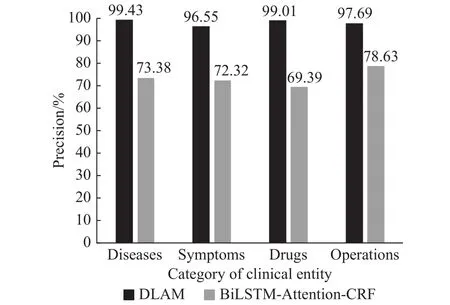
图 2 DLAM与BiLSTM-Attention-CRF实体级别精确率对比Fig.2 DLAM and BiLSTM-Attention-CRF precision comparison on entity
由图2,图3可看出,虽然关于通用语料的研究表明:采用了注意力机制的深度神经网络对句间的长期依赖有较好学习能力[25]. 但在具体的专业领域中,BiLSTM-Attention-CRF仍然难以学到复杂的专业特征. 而DLAM采用领域词典预标注的方式很好地解决了这一问题.
本文识别的四类实体中,BiLSTM-Attention-CRF与DLAM识别效果相差最大的是药品实体.这是因为药品名大多较生僻,其构词方式与病历中其他部分的自由文本相差较大,深度神经网络很难学到其上下文关系. 而领域词典中一旦登录了某种药品,就能够很好的识别出来. 对于呼吸科病历,常见药品出现的频率高,作用相似的药品其名称构词方式也类似,因此识别效果较好.
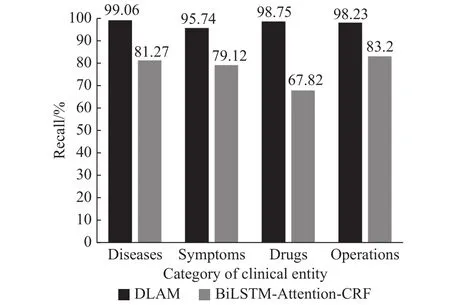
图 3 DLAM与BiLSTM-Attention-CRF实体级别召回率对比Fig.3 DLAM and BiLSTM-Attention-CRF recall comparison on entity
本文还对DLAM识别结果中的错例进行了进一步的分析. DLAM对四类实体的识别效果趋于稳定. 因长实体缺少部分构词成分而造成的错例主要存在于疾病实体和症状实体中,具体表现在对长实体中的修饰成分识别效果不佳. 例如,“间变性B细胞非霍奇金淋巴瘤”仅能识别出“非霍奇金淋巴瘤”,“肋以下呈大片状致密影”被识别为“大片状致密影”. 修饰成分中的器官指向通常携带了重要的医疗信息,目前DLAM仍会丢失部分此类信息. 值得注意的是,DLAM通过结合机器学习自动学习文本上下文特征的能力,能容错医疗文本中的错别字,如成功识别“腹不(部)平软”.
此外,如表5所示对比了DLAM与文献[27]中基于多特征融合的CRF以及以字嵌入和分割信息作为BiLSTM-CRF输入特征的医疗实体识别方法. 由于两项研究都是基于自标注语料完成的,导致单纯的结果对比并无意义. 但文献[27]中为了达到较好的识别效果,融合了如词袋、词性、位置等多项特征;而DLAM在CRF阶段仅使用上下文特征,主要是通过第一层预标注来获取更多的语义隐含信息.
4 结论
本文针对中文电子病历文本复合实体较多、实体长度较长、句子成分缺失严重、实体边界不清的语言特点,对中文电子病历中的四类实体——疾病、症状、药品、操作进行命名实体识别研究.
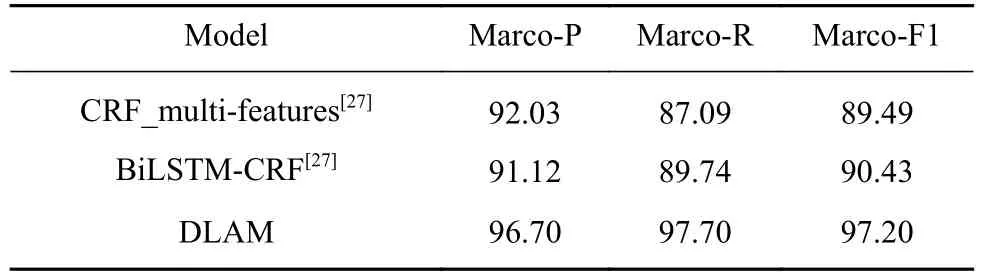
表 5 DLAM与现有模型结果对比Table 5 Comparison of DLAM and existing model results %
(1)结合电子病历文本通过统计分析构建了一个小规模的医疗领域词典.
(2)将经典序列标注算法CRF与富含领域知识的词典相结合,提出了一种预标注-二次标注的双层标注模型DLAM. 通过一次预标注-二次精确标注两种不同粒度的标注完成对中文医疗实体的识别. 经过实验验证,DLAM在测试集上的宏精确率为96.7%、宏召回率为97.7%、宏F1值为97.2%,可准确地对中文医疗实体进行识别.
(3)对比分析采用注意力机制的深度神经网络的识别效果,结果表明提出的双层标注模型DLAM在测试数据集上表现优越于深度神经网络.
