基于本体的协同过滤信息推送算法研究
2020-06-08王红霞钟爱琳
王红霞,钟爱琳
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
计算机行业的迅速发展使得互联网渗透到了生活中的方方面面,是人们获取信息最有效的途径,但海量的网络信息在给予方便与快捷的同时也使大众进入了信息碎片化的时代,冗余的信息往往会降低用户的体验感。面对如此现状,用户如何能从中阅读到真正满足其需求的信息是迫待解决的关键问题。
协同过滤推送算法是最为常用的信息推送算法之一。通过用户的行为特征构建用户兴趣模型,根据协同过滤推送算法找到用户的兴趣爱好。协同过滤推送算法分为基于用户的协同过滤推送算法[1]和基于项目的协同过滤推送算法。前者通过计算用户间的相似度,找到与目标用户相似度较高的其他用户所喜爱的项目进行推送。而基于项目的协同过滤推送算法[2],关注点则是项目之间的相似度,首先找到用户评分历史中评分较高的项目,然后通过计算项目之间的相似度,把相似度较高的其他项目作为待推送结果。
尽管协同过滤推送算法有较高的使用率,但不得不承认该算法依然存在弊端。在实际生活中往往用户评分这一项会有大量空缺,导致用户项目评分矩阵稀疏,另外也因为新商品的冷启动导致推送结果的覆盖范围不够广泛。因此,针对这种推送方法的弊端,本文提出了基于本体的协同过滤信息推送算法,在推荐过程中引入本体,通过本体的概念层次结构关系和概念之间的关系与用户兴趣词之间产生关联,进而对用户的兴趣词进行词义扩展,使推荐内容更为精确丰富。
1 书籍模型及用户兴趣模型建立
本文以图书阅读网站的个性化推送作为研究背景。用户兴趣模型是对用户爱好的准确描述,是服务推送过程中的重要一环。而书籍建模是用户兴趣建模的基础,二者缺一不可。
1.1 书籍模型建立
书籍建模采取基于向量空间[3]的模型表示方法。
Project={(project1,style1,author1,pub1),…,(projectm,stylem,authorm,pubm)}
式中:project为书籍编号;style为书籍类别;author为书籍作者;pub为书籍出版社。
1.2 用户兴趣模型建立
用户兴趣模型的建立采取改进的向量空间模型表示方式,因为用户的兴趣不是一成不变的,在不同的时间段用户的兴趣可能不同,因此在基本的向量空间模型中加入时间元素,表现形式如下。
User={(userID1,action1,score1,time1),…,(userIDn,actionn,scoren,timen)}
式中:userID为用户ID;action为行为类型,分为浏览、搜索、收藏,对应数值设为1、2、3来表示其感兴趣的程度;score为用户对书籍的评分;time为以t为单位时间,表示用户的感兴趣程度,若用户的操作行为发生在过去的t时间段内,设time为5;若用户的操作行为发生在过去的t~2t时间段内,设time为4;若用户的操作行为发生在过去的2t~3t时间段内,设time为3;若用户的操作行为发生在过去的3t~4t时间段内,设time为2;若用户的操作行为发生在过去的4t~5t时间段内,设time为1。
2 协同过滤推送算法与本体的结合
2.1 领域本体的构建
本体[4]是概念模型形式化的规范说明,具有概念性、明确性、形式性和共享性。
(1)书籍领域本体的构建
初步决定使用protege4.3,按照中图分类法[5]构建部分书籍领域本体。对于部分书籍领域实体可分为出版商、作者、类别,详细分类如下。
部分书籍领域整体本体图如图1所示

图1 部分书籍领域本体图
图中:BookAreas为部分书籍领域本体类;Book表示书籍种类;Publication表示书籍出版商;Author表示书籍作者;Thing表示事物。
2.2 本体与用户协同过滤推送算法的结合
(1)采用改进的基于向量的空间模型表示方法构建用户的兴趣模型。
(2)根据公式(1),计算用户之间的相似度。
sim(Useri,Userj)=cos(Useri,Userj)=
(1)
式中:Useri、Userj为用户i、j的兴趣模型向量。
(3)最近邻居集的构建:将相似度最高的前r个用户筛选出来,组成用户的最近邻居集Ue(U1,U2…Ur)。
(4)选取邻居集中用户的所有历史项目作为待推送商品集。
(5)预测项目评分:计算待推送集合中书籍的评分,不同用户对目标用户的影响不同,因而选取邻居用户的加权评分值作为权重因子[6],计算公式(2)如下,S(a,i)表示用户a对书籍i的评分。
(2)
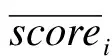
根据评分预测选取评分最高的前j个书籍构建兴趣书籍集G1(g1,g2…gj);
(6)根据建立的商品模型提取兴趣书籍集中商品所包含的特征词。
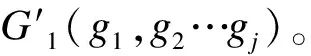

2.3 本体与书籍协同过滤推送算法的结合
(1)根据建立的用户兴趣模型,选取书籍用户在3t时间内评分书籍最高的前k个书籍。
(2)通过公式(3)计算书籍之间的相似度,得到k个书籍的商品邻居集P。

(3)
式中:Projecti、Projectj表示书籍i、j的模型向量。
(3)据公式(4)计算邻居集P中各个项目的预测评分
(4)

(4)根据评分预测选取评分最高的前k个书籍构建兴趣书籍集G2(g1,g2…gk)。
(5)将特征词映射到本体模型中,通过搜索找到特征词在本体中的位置,若本体中没有该特征词,则将该特征词添加到本体中,然后搜索该特征词同一父类下的特征词,以及相邻父类下的特征词,通过特征词找到与之对应的书籍。构成书籍集G′2(g1,g2…gk)。
(6)将G′2做为待推送书籍集。
3 本体与协同过滤信息推送算法的结合
3.1 算法具体流程
图2所示为本体与协同过滤信息推送算法结合的具体流程图。

图2 算法流程图
3.2 算法步骤如下
(1)下载BookCrossingDataset数据集[7]。
(2)采用空间向量模型的方法构建商品模型,在空间向量模型方法之上有所改进,加入time因素,构建用户兴趣模型。
(3)将本体结合到协同过滤推送算法中。
(4)选取绝对平均误差和覆盖率作为评价指标,验证融入本体后的协同过滤算法的有效性。
4 仿真实验
4.1 数据收集
本课题需要的数据选自BookCrossingDataset数据集,该数据集包含三张表:用户信息表、书籍信息表、用户对书籍的评价。

表1 数据集基本信息
4.2 数据的预处理
(1)原始的书籍数据表中imageURL属性并不需要,可以将其删除。
(2)原始的出版时间数据,其中有一些错误条目(如出版商的名字被错误地加载为出版日期),将对这些错误进行更正。
修改后的结果如图3、图4所示。

图3 删除imageURL后的书籍数据

图4 更正后的出版时间数据
4.3 算法准确性的验证
本课题选取绝对平均误差(Mean Absolute Error,MAE)[8]和覆盖率(F)作为评估指标来验证算法的准确性。
(1)MAE值度量预测打分与实际打分的绝对平均误差。
(5)
式中:pi表示信息推送系统对书籍i的预测打分;ri表示用户对书籍i的实际评分;N为测试集中书籍个数。
表2为传统的协同过滤推送算法与结合本体后推送算法的MAE值比较,100-100表示100个用户对一百本书评价,以此类推。
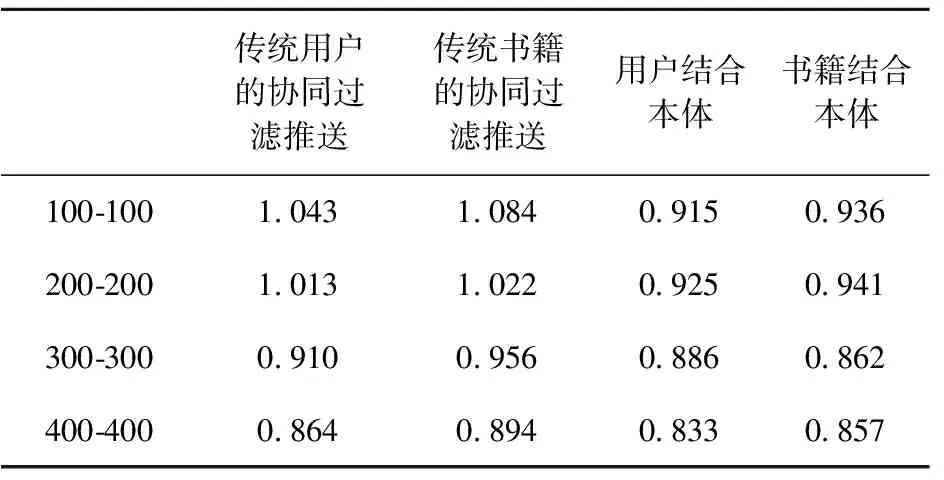
表2 与本体结合的协同过滤推送算法的MAE值
由表2的MAE值可得出如下结论:用户协同过滤推送算法的效率要高于书籍协同过滤推送算法;与本体结合后的推送算法比传统的协同过滤推送算法准确性更高。
(2)根据精确度(Precision)、召回率(Recall)、和覆盖率(F)[9]来进行验证。覆盖率的高低能反映出推送系统推送信息的丰富性,覆盖率越高推送的内容覆盖范围就越广。
(6)
(7)
(8)
式中:PreSet为预测的待推送的项目集合;RefSet为真实的用户购买的项目集合;F为最终的评价标准。
表3为几种推送算法的精确度、召回率和覆盖率的结果比较。
由表3可看出,与本体结合后的协同过滤推送算法覆盖率更高,说明本文提出的基于本体的协同过滤信息推送算法准确性更高,推送内容也更为丰富。

表3 不同算法的精确度、召回率、覆盖率的比较 %
5 结论
提出基于本体的协同过滤信息推送算法,采取经典的绝对平均误差及覆盖率作为评价指标,经实验结果表明,与本体结合的协同过滤推送算法较为有效的解决了传统协同过滤推送算法存在的用户兴趣矩阵稀疏问题及新商品的冷启动问题。
