基于DBN模型的高职学生行为特征分析
2020-05-29杨瑞请
杨瑞请
(闽江师范高等专科学校 计算机系,福建 福州 350108)
随着网络科技的迅速发展,互联网已经成为人们学习、工作和生活的一部分[1],越来越多的大学生通过微博、微信、论坛、BBS、门户网站等传播信息,这些新媒体的使用每天都会产生海量的数据,而这些数据可以在一定程度上反映学生的行为特征.通过使用与大数据相关的技术对学生的行为数据进行收集、整理,利用DBN(Deep Belief Network,简写为DBN)模型对这些数据进行挖掘、分析,既可发现学生的兴趣、爱好、特长等,为教师因材施教提供帮助,又可发现思想有问题的学生,让相关人员及时介入辅导,避免学生的极端行为,这对校园稳定具有重要意义.
1 基于DBN的行为特征分析方法
1.1 RBM简介
受限玻尔兹曼机[2](Restricted Boltzmann Machine,简写为RBM)是由Hinton和Sejnowski于1986年提出的一种由两层神经元组成的生成式随机神经网络.RBM的两层分别称为显层(v层)和隐层(h层),其中,显层由显元 (visible units) 组成,用于输入训练数据;隐层由隐元 (hidden units) 组成,用作特征检测.RBM的结构如图1所示.
图1中的第一层称为隐层,由神经元h1,h2和h3组成,隐层中的神经元称为隐元;第二层称为显层,由神经元v1,v2,v3,v4和v5组成,显层中的神经元称为显元.显层与隐层中神经元的个数可以根据实际需要增加,显元与隐元之间的连接为全连接,每一层内的神经元间相互独立,不存在连接.RBM中的每一层都可以用一个向量来表示,每个神经元对应一维数据,分别用0和1表示神经元是打开还是关闭,∀vi,hj,其中vi,hj∈{0, 1},而神经元的具体值则由概率统计法则决定.
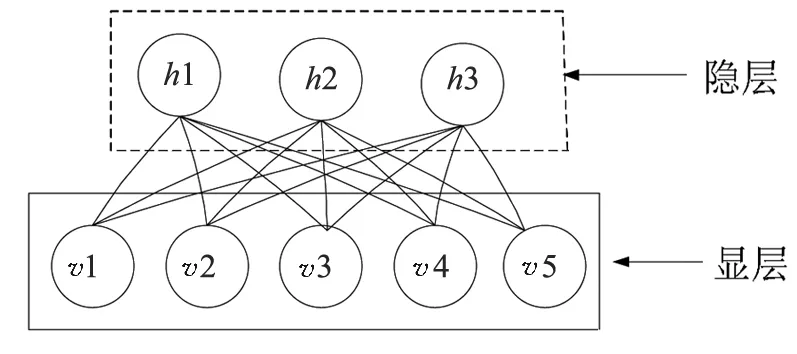
图1 RBM结构图
1.2 DBN概述
DBN[2]是由多个受限玻尔兹曼机堆叠而成的深度信念网络,它属于深度学习算法的一种.它由多个RBM堆叠而成,前一个RBM的隐层可以作为下一个RBM的显层.DBN的训练过程是一层一层进行的,训练DBN的过程实际上就是训练各层RBM的过程.每一个RBM都可以使用上一个RBM的输出进行单独训练,与传统的神经网络相比,DBN的训练更加简单.通过这种训练方法,DBN也能够从无标记数据中获取深层次的特征.
DBN模型的建立过程包含有监督学习和无监督学习两个学习过程[3],如图2所示.无监督学习过程由RBM完成;有监督学习过程由反向传播网络(Back-propagation,BP)完成,也可以是其他分类器.通过训练神经元间的权值,可以让整个神经网络按照最大概率来生成训练数据.因此,DBN不仅可以用于特征选择、数据分类,还可以用于数据生成.

图2 DBN结构图
1.3 DBN特征分析方法
将获取到的学生行为特征的原始数据进行清洗、转换等预处理.预处理后的数据作为DBN的第一层神经元,构成DBN网络的第一个显层,根据初始权值即可计算出第一个隐层中各个神经元的值,由第一个显层和第一个隐层即可构成一个RBM.
DBN网络的训练过程如下:
(1)充分训练第一个RBM,固定第一个RBM的权重和偏移量;
(2)将第一个RBM的隐层作为第二个RBM的输入向量进行训练;
(3)充分训练第二个RBM后,将第二个RBM堆叠在第一个RBM的上方,并固定其权值;
(4)重复以上三个步骤任意多次;
(5)如果训练集中的数据有标签,那么在顶层的 RBM 训练时,这个 RBM 的显层中除了显性神经元,还需要有代表分类标签的神经元一起进行训练;
(6)DBN训练完成后进入反向微调阶段,达到设定的精度,算法结束.
2 实验设计及分析
2.1 数据来源
随着互联网的快速发展和高校数字化校园建设的逐步推进,各高职院校已经建立了各类管理信息系统.例如,从一卡通管理系统中可以获取学生学习和生活相关的行为数据,包括图书借阅信息、宿舍门禁信息、食堂和超市消费信息等;从学生管理系统中可以获取学生的基本信息,包括个人基本情况、特长、兴趣、爱好等;从教务管理系统中可以获取学生的出勤情况、学习课程及成绩、奖惩情况等学习行为数据;从学校网络信息中心可以获取学生的上网访问日志,包括学生访问的网站类型、内容、时长等信息.这些数据资源为研究学生的行为特征提供了依据.
2.2 特征提取
从学生的基本信息中提取的行为特征包括学号、姓名、性别、特长、爱好等;从教务系统获取的行为特征包括科目名称、成绩,选修课名称、成绩等;从图书借阅信息中提取的特征包括图书类型、名称等;从搜索引擎访问日志中提取的特征有网站类型、标题、频次等信息.将这几种不同数据源中学生的历史行为数据融合在一起,即可形成学生的行为特征向量.每个学生对应的行为特征向量可表示为:学生1(特征1,特征2,特征3,…,特征n);学生2(特征1,特征2,特征3,…,特征n)……
2.3 数据预处理
数据预处理就是将原始数据转换成符合数据挖掘要求的数据格式的过程.深度学习模型所能处理的数据通常是符合一定标准和规范的数据,而从各个数据源中获取到的数据可能包含噪声数据、重复数据、类型不同的数据、不完整的数据和不一致的数据,这些不规范数据若直接输入到学习模型中,会严重影响模型的学习结果,因此,数据的预处理在研究过程中起着非常重要的作用.而在高职学生行为的研究中,由于数据具有多样性和复杂性,数据的搜集和预处理阶段通常是工作量最大、需要人力资源最多的[4].
数据预处理[5]一般包括对数据的清理、集成、转换等.在本研究中,通过数据清理操作,可以清除无用的、无效的、重复的数据及噪声等;通过数据集成操作,可以将多个数据源的数据合并成一个新的数据集;通过数据转换可以将文本、网络地址等类型的数据转换成DBN模型能够处理的数据类型.
2.4 基于DBN的模型框架
首先从学生管理系统、一卡通管理系统、教务管理系统等数据源中,采集学生的基本信息、考试成绩、选修课程、图书借阅信息、搜索引擎访问日志等信息,对采集到的数据进行特征提取,将提取到的各个特征进行转换、归一化等预处理,并清除噪声数据、重复数据等[6],形成学生行为特征向量,然后将学生行为向量输入到DBN模型中进行训练,分析模型框架如图3所示.将学生学习的主要科目、图书借阅信息等作为不同的类别,输出结果中概率比较高的类别就是学生最关注的方面,教师可以根据输出结果对学生进行个性化培养,如,可根据结果动员不同的学生参加各种比赛或活动,为其提供更好地展示才华的机会,进而为社会培养更多的优秀人才.

图3 学生行为特征分析模型框架
2.5 实验结果及分析
实验采用的数据以闽江师范高等专科学校17软件和18软件1-2班学生的成绩数据为主,每个学生(一学年)有两条数据,可以形成一个280×10的成绩矩阵.例如,根据学生学习的科目,将结果归为五类,分别是.NET、Web前端、Java、数据库和其他,对应称其为第一个数据、第二个数据、第三个数据、第四个数据和第五个数据.采用本文所构建的DBN模型对学生行为进行分析预测,输出结果为五个概率数据,若某个概率数据最大,就认为该学生比较喜欢学习该方向的内容.若预测结果中第一个数据最大,则表示该学生比较喜欢学习.NET方向的内容;若第二个数据最大,则表示该学生比较喜欢Web前端方向的内容;若第三个数据最大,则表示该学生比较喜欢Java方向的内容;若第四个数据最大,则表示该学生比较喜欢数据库方向的内容;若第五个数据最大,则表示该学生关注的方向不好确定.对其他数据的分析亦采用此方法.
3 结论
(1)使用DBN模型对学生的历史行为数据进行分析,可以推断出学生的行为状态,确定学生关注的内容,帮助教师更全面地了解学生,为教师基于学生的兴趣和特长来因材施教提供帮助.
(2)通过学生行为特征分析,可以发现一些思想存在问题的学生并采取对应的教育措施,对学校的稳定发展具有十分重要的意义.
(3)研究中存在数据获取、清洗问题.因为数据来源于多个不同的数据源,需要进行多部门沟通协调,因此数据获取有一定的难度.数据的清洗结果会直接影响DBN模型的分析结果,因此,清洗技术的选择很重要.另外,学生的行为特征数据涉及其隐私保护问题,要处理好其中的关系.
