基于LSTM模型的海洋水质预测∗
2020-05-15李彦杰贺鹏飞冯巍巍刘巧利杨信志
李彦杰 贺鹏飞 冯巍巍 刘巧利 杨信志
(1.烟台大学光电信息科学技术学院 烟台 264005)(2.中国科学院海岸带研究所 烟台 264003)
1 引言
近年来为了推动经济的快速发展,世界各国均加大对海洋资源的利用与开发,但是带来经济效益的同时,一系列海洋生态环境问题频发,海洋资源遭到严重破坏。最近我国海域内赤潮发生频率在逐年增加,海平面升降、海岸侵蚀等灾害也频频发生,因此必须加大海洋环境监测技术的研究和开发来应对和预防突如其来的海洋水质灾害[1]。
中国是水产养殖的大国,中国的水产养殖占全世界总量的70%[2]。因此,对于海洋水质情况的有效预警对我国来说尤为重要。海洋环境监测的数据能够精确地反映海洋环境质量状况和污染程度,进一步通过数据分析技术能够提前预知海水水质的变化或异常情况,从而做到及时防范和处理,可大大减少海洋灾害带来的经济损失[3]。
现阶段我国对海洋水质的监管多局限于运用无线传感器技术实现对海洋数据进行采集和多传感器之间的数据融合上,缺乏对采集到的数据做进一步的大数据分析[4]。本文针对以上不足,对采集到的数据进行二次利用,运用SVR算法和LSTM算法对数据进行分析处理,并实现对未来海洋水质精准预测的目的,当水质参数出现波动时,可提前预知是否会出现异常,从而为海水监管单位提供精确预警。
2 数据采集与处理
2.1 数据来源
本文中所用的实验数据来自于烟台中国科学院海岸带研究所实验基地,主要采集了2018年4月24号和4月25号两天从0点到24点海水含油量的6048条数据,如2018-04-24,23:42:41,4.0943,该数据是时间序列数据。
2.2 数据预处理
采集的数据是按照时间序列排序的,对于时间序列数据最主要的特征就是其数据之间在时间上的前后相关性,该特征包含了很多隐藏的规律和信息,这也是我们数据挖掘的目的。为了将时间序列数据可视化,我们用折线图画出,如图1所示。
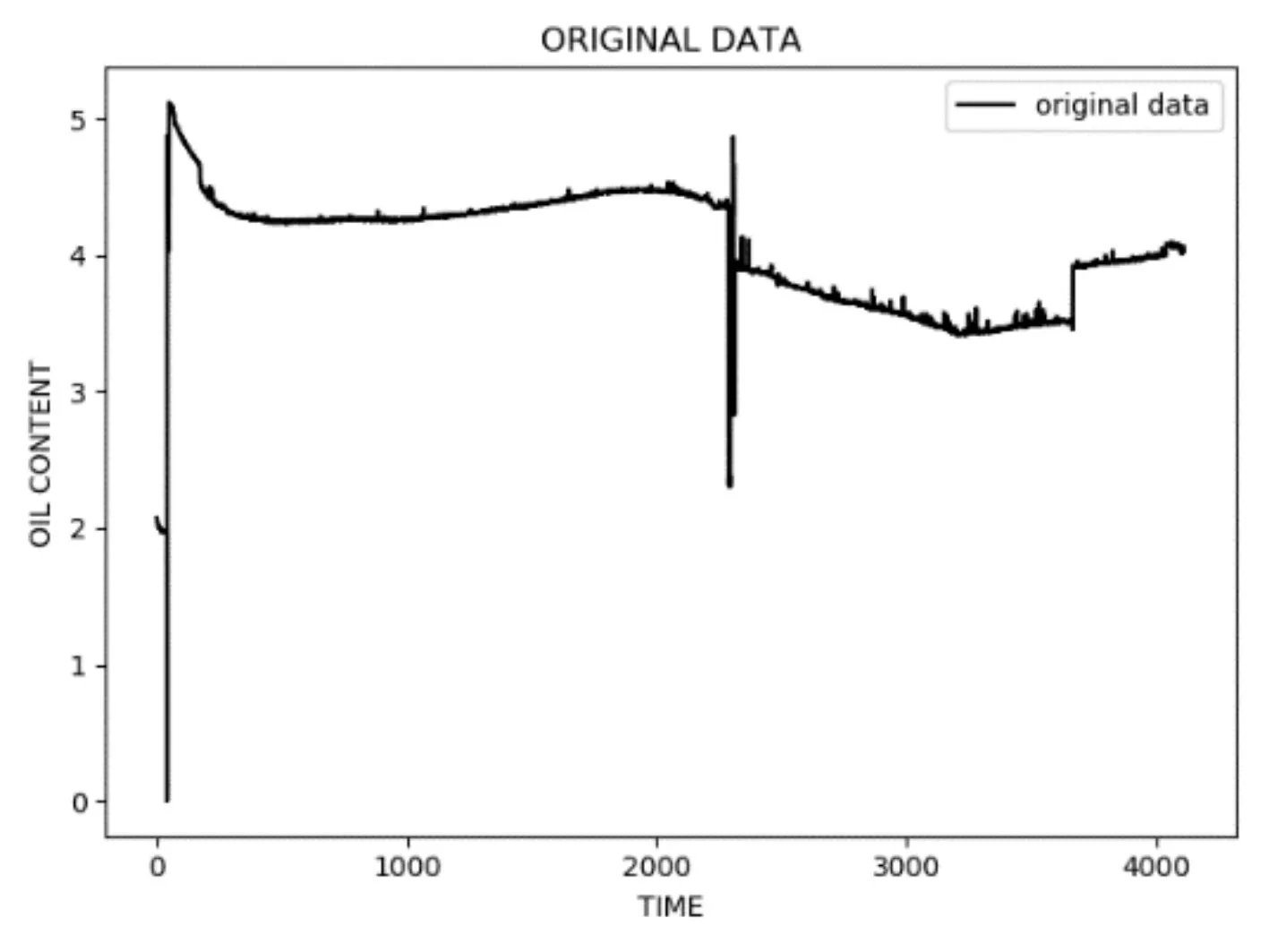
图1 海水含油量原始数据折线图
从图1中可以看出,有些时间点的数据出现过大或者过小等离群点,偏离均值较大,为了不影响最终的训练结果,需要将偏离比较大的数据剔除[5],经预处理后的数据折线图如图2所示。
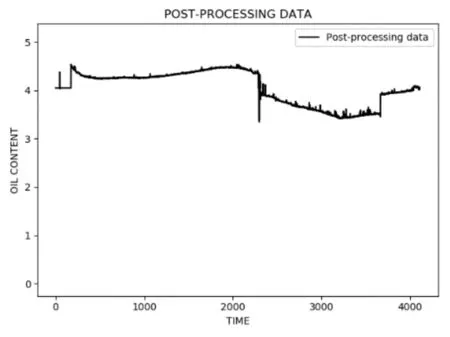
图2 预处理后的数据折线图
选定4月24号采集的数据作为训练集,用来训练模型;用4月25号采集的数据作为测试集,用来测试预测的准确度。为了提高数据利用率,当准确度达到一定高度的时候,再用所有的数据整体去训练一个模型,用该模型作为最终模型,以达到数据的充分利用。
3 预测模型
本文主要采用了两种预测算法:支持向量回归(Support Vector Regression,SVR)和长短时记忆网络(Long Short Term Memory Networks,LSTM),其中SVR作为对照实验,将所采集的数据所对应的时间转换为数据并作为X,如将12:34:56改为12.3456;将所对应的海水油含量作为Y,并用相应地X来预测对应的Y,为回归问题。而LSTM运用数据前后的相关性直接在时序上对海水含油量数据做预测。
3.1 SVR算法
SVR算法主要用来做回归预测,通过建立训练数据中的待预测向量与支持向量间的非线性关系,对测试数据的待预测向量进行预测。核函数对SVR的性能具有重要影响,不同核函数及参数的SVR算法性能存在很大差异[6]。本文使用的是高斯径向基核函数(RBF核函数)[7],其公式为
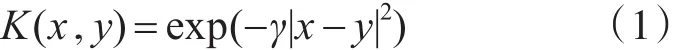
式中,γ为RBF核函数的半径,γ>0。SVR训练效果的好坏主要受到γ的影响,γ越大越能反映局部样本的差异,但是γ过大时则容易泛化误差出现过拟合[8]。
经过k折交叉验证(k-fold cross validation)[9],发现当γ=0.01,惩罚参数C=0.8[10]时模型预测整体效果最好。参数的选取流程图如图3所示。
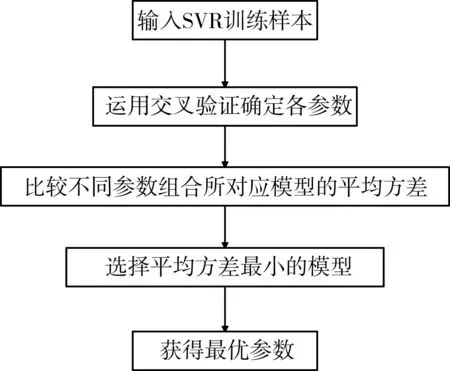
图3 SVR参数选择流程图
3.2 LSTM算法
神经网络一般包含输入层、隐层、输出层,层与层之间通过参数矩阵进行连接[11],训练的过程是通过不断反向传播(Back Propagation)[12]来不断优化参数矩阵。循环神经网络(Recursive Neural Net⁃work,RNN)各个层之间的权值共享,并能“记忆”以前的样本信息[13]。图4为RNN网络结构的模型。
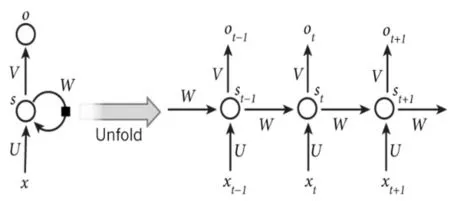
图4 RNN网络结构
由于梯度消失和梯度爆炸问题[14],普通的RNN网络很难解决学习中的长期依赖问题[15]。为解决普通RNN网络存在的问题,本文使用长短期记忆网络(LSTM)对数据进行训练预测。LSTM是对普通RNN网络的一个改进,LSTM网络结构如图5所示。
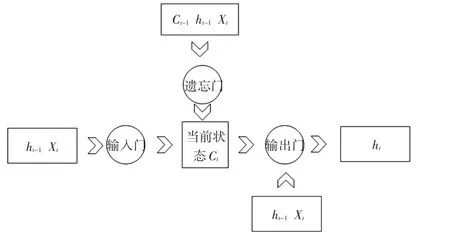
图5 LSTM网络循环单元结构
其中ct-1是上一时刻状态,ht-1是上一时刻输出,Xt是当前输入,ct是当前时刻状态。“遗忘门”会根据当前时刻输入Xt和上一时刻输出ht-1决定哪一部分“记忆”应该被遗忘;“输入门”会根据Xt和ht-1决定哪些信息加入新的状态ct;“输出门”会根据最新状态ct,上一时刻的输出ht-1和当前的输入Xt来决定该时刻的输出ht。三个门的具体内部结构如图6所示。
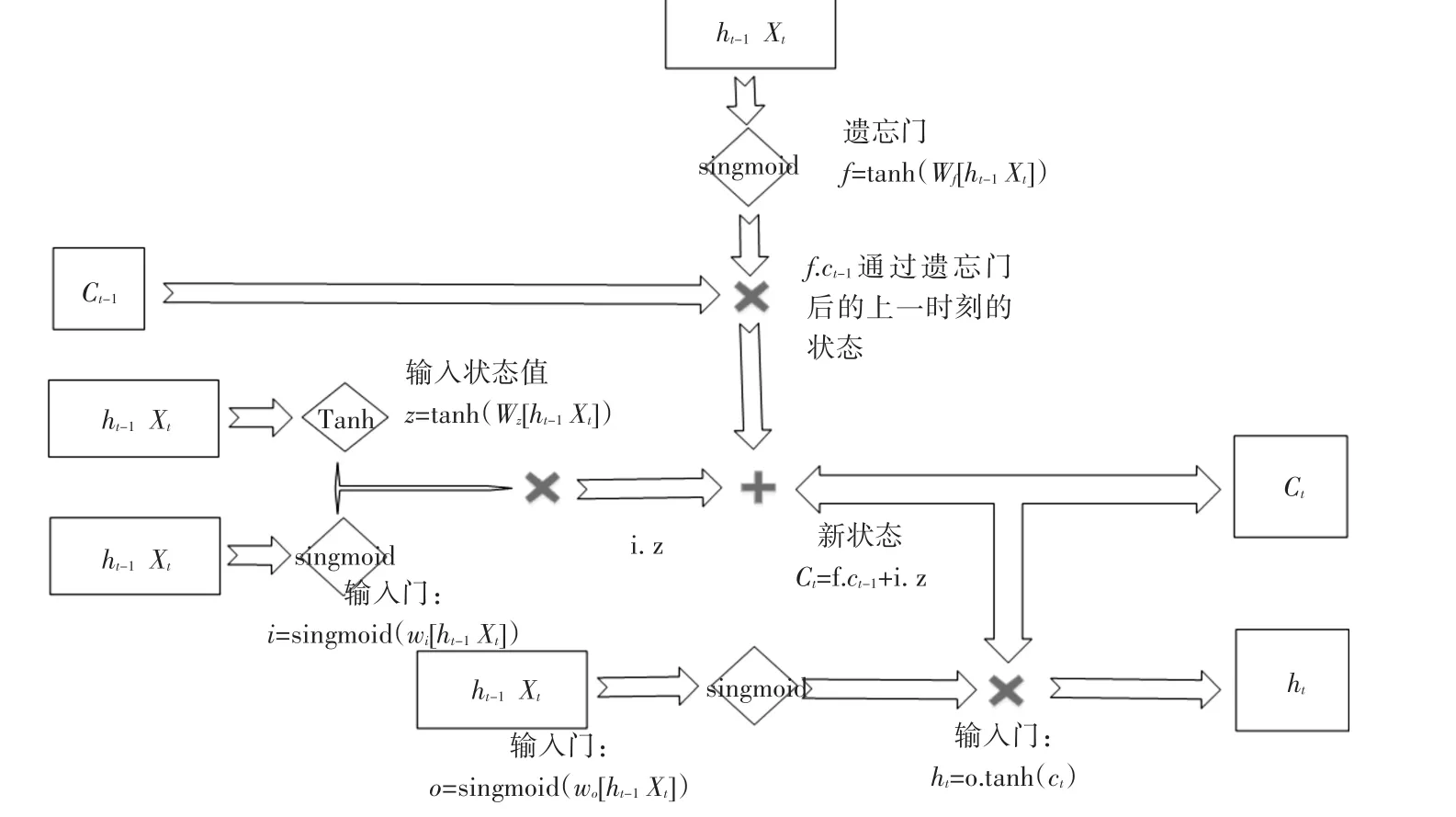
图6 LSTM网络循环单元内部结构
sigmoid为激活函数[16],其表达式为
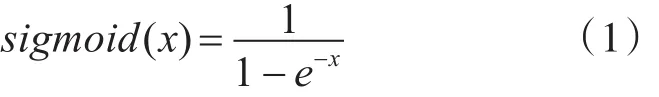
tanh函数表达式为[17]
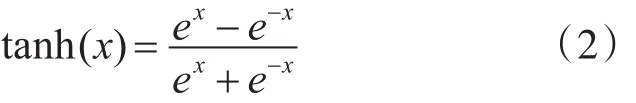
LSTM网络具体每个门的公式定义如下:


其中 Wz,Wf,Wi,Wo是参数矩阵,在 LSTM 训练时,对应的参数矩阵会不断优化。经过实验分析,相比标准的RNN,改进后的LSTM模型可以很好地解决学习训练中的长期依赖问题[18]。
深度学习模型参数收敛过程中学习率的设置是至关重要的,学习率过高时训练过程容易振荡,从而难以收敛;学习率过低则导致训练过慢[19]。本文使用的LSTM网络总共包含4层隐层,每层隐层中节点个数为40个。根据k折交叉验证得出该LSTM网络在学习率为0.01,训练序列长度为16时有最好的预测结果。参数选定后,总共迭代训练400000次,模型每次迭代处理44组数据,每迭代1000次返回一次损失值。
4 结果与讨论
将4月24号的海水含油量数据作为训练集,4月25号的海水含油量数据作为测试集,其中训练集用于模型参数的学习,测试集用来评价模型预测的准确率和泛化能力。
为验证LSTM算法的有效性,本文将SVR和LSTM两种算法做了对比,图7显示了使用SVR训练数据的拟合情况,图8为使用LSTM算法训练数据得到的拟合图。图中虚线表示为预测数据(pre⁃diction data),实线表示真实数据(real data)。通过改进参数优化的方式[20],发现LSTM算法表现出了较好的拟合效果。
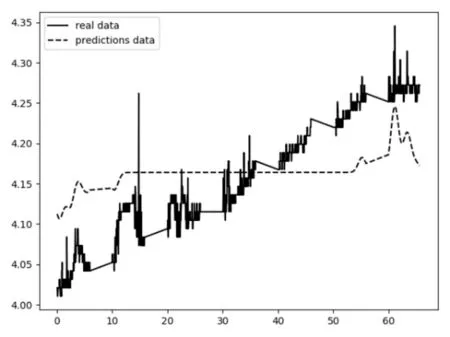
图7 SVR训练数据的拟合图
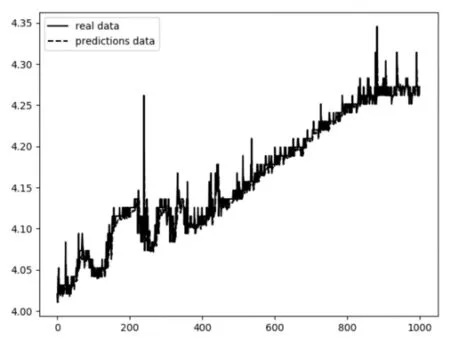
图8 LSTM训练数据的拟合图
为了对两种算法的结果进行定量化分析,本文利用平均绝对误差和拟合优度两种数值指标来衡量两个模型的效果。平均绝对误差(Mean Abso⁃lute Error,MAE)是指预测值与真实值之间平均差值,其值越小越证明的模型效果越好[21],公式如下:
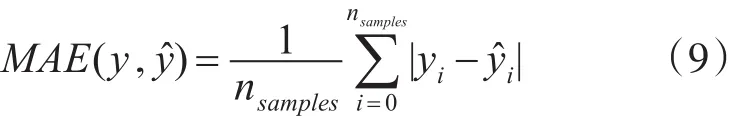
决定系数(Coefficient of Determination),也称为拟合优度,它表示模型对观测值的拟合程度。R2越接近1,表示模型的预测效果越好[22],其公式如下:
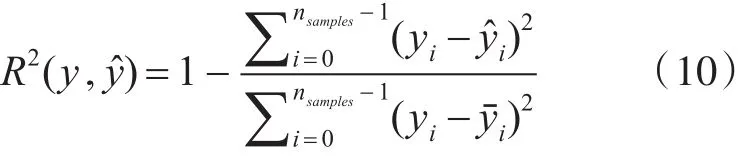
经分析计算,两种算法各自的评估指标如表1所示。
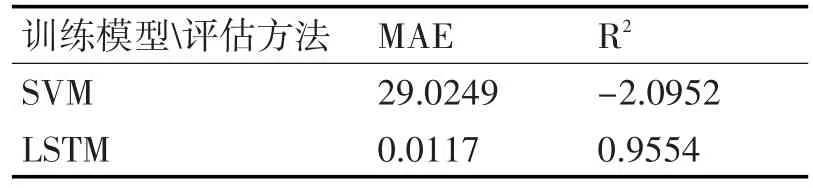
表1 数值评估指标
从拟合图和表格可以看出,SVR的MAESVR=29.0249,LSTM 的 MAELSTM=0.0117,MAESVR>>MAEL⁃STM。SVR的 R2值R2SVR为-2.0952,与 1的距离为 SS⁃VR=|-2.0952-1|=3.0952。LSTM的R2值R2LSTM=0.9554,与1的距离为SLSTM=|0.9554-1|=0.0446,SSVR>>SLSTM。
分析可知LSTM的平均绝对误差远小于SVR的平均绝对误差,且LSTM拟合优度与SVR的相比也更接近1。综上所述,对于本论文的数据来说,运用LSTM算法远优于SVR算法。
5 结语
本文重点阐释了通过两种机器学习算法对海洋水质的含油量数据进行建模预测,与传统算法SVR相比,LSTM能够更加准确训练出预测模型,且预测精度很高,拟合程度非常好,提高了数据的精准度和实时性,解决了目前海水监测系统无法对数据进行实时精确预测的难题,改善了海水预警体系,对海水养殖、海水污染监测与治理具有重要的指导意义。
