基于Graph Embedding的话单分析∗
2020-05-15韩文轻彭艳兵
韩文轻 彭艳兵
(1.南京烽火天地通信科技有限公司 南京 210019)(2.武汉邮电科学研究院 武汉 430074)
1 引言
由于话单分析在犯罪侦查中的作用越来越大,关于话单分析的方法也层出不穷。话单数据中包含着很多隐藏的信息,合理利用话单数据进行分析,可以辅助犯罪侦查工作,大大提高侦查效率。
目前关于话单分析的研究,大多基于社交网络进行分析。如根据通联次数和通联时间分析通连方与嫌疑人是何种关系[1~2]。一般同事主要在工作时间联系,工作之外基本不联系;朋友在吃饭时间联系的较多;情人在私密的时间联系的次数较多,时长较长;行贿的一般在节假日前后联系较多[3~4]。通过话单中的基站区码标识和小区标识判断嫌疑人通话时所在位置,分析嫌疑人的活动轨迹[5~6]。还可以判断嫌疑人的作案地与居住地,根据嫌疑人的通话时间与基站位置,判断嫌疑人的居住地与作案地[7~9]。通过分析嫌疑人亲密联系的人找出逃逸嫌疑人更换的手机号码[10~12]。这个可以根据该嫌疑人换手机号之前的话单分析,找出联系密切的几个人,分析这几个人在嫌疑人换号码前后新增的号码,从中找出共同联系人,从而发现嫌疑人使用的新号码[13~15]等。
根据社交网络关系分析的方法,虽然简洁便利,但是不能用机器学习算法进行话单分析。机器学习是现在的热门算法之一,如果能将机器学习算法用于话单分析,通过提取数据的特征,抽象出数据的模型,应用模型进行预测与分析,那么以后再遇到类似的问题,就可以直接将数据用模型分析。
2 特征设计
提取数据特征,是进行机器学习算法的第一步。本文提取话单数据中的用户号码、对方号码、通话时长、主被叫标志,然后进行特征设计。
在进行特征设计之前,先定义一些基本概念。
令Ω表示已知重点对象集合。
ck=s,t为一条由 s主叫 t的通联关系。为总体样本通联关系集合,其中n为通话记录总数。
I(x)为对象x的重要性指标,这个指标是根据已知对象的涉案程度来定义的,不同案件定义不同。s为主叫方,t为被叫方,那么I(s)和I(t)分别为主叫方s和被叫方t的重要性指标。
1A(x)为指示函数。
T(ck)为通话记录ck的通话时长。
定义了这些基本概念,接下来定义六个影响对象重要性的指标。
2.1 拨出重要性
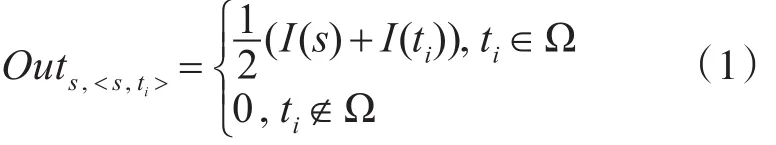
Outs,<s,ti>表示在通话记录 < s,ti> 中 s的拨出重要性。也就是说,若s与ti存在通联关系,且ti在已知重点集合内,那么s的拨出重要性就是通联双方s和ti的重要性指标的均值。在整个通话网络C中,s的拨出重要性累计为
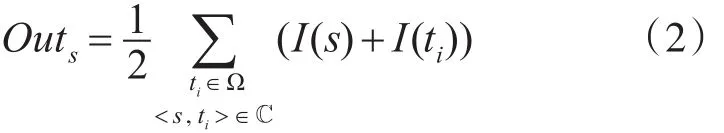
2.2 接听重要性
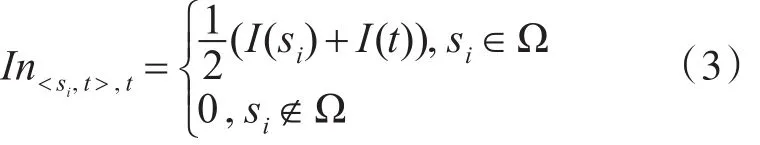
In<si,t>,t表示在通话记录 < si,t> 中 t的接听重要性。也就是说,若si与t存在通联关系,且si在已知重点集合内,那么t的接听重要性就是通联双方si和t的重要性指标的均值。在整个通话网络ℂ中,t的接听重要性累计为
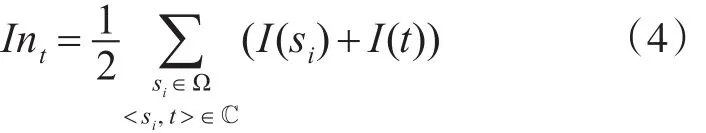
2.3 拨出时长重要性
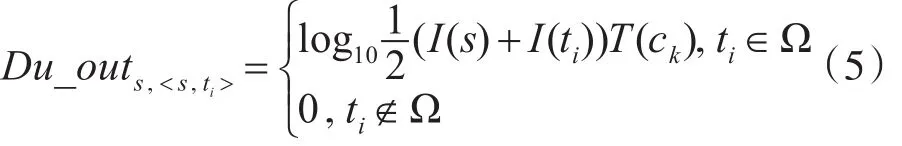
Du_outs,<s,ti>表示在通话记录 <s,ti> 中 s的拨出时长重要性。这里定义s的拨出时长重要性为s的拨出重要性与通话时长T(ck)的乘积以10为基的对数。后续会解释这么做的原因。那么在整个通话网络ℂ中,s的拨出时长重要性累计为
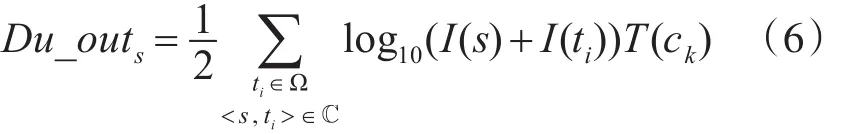
2.4 接听时长重要性
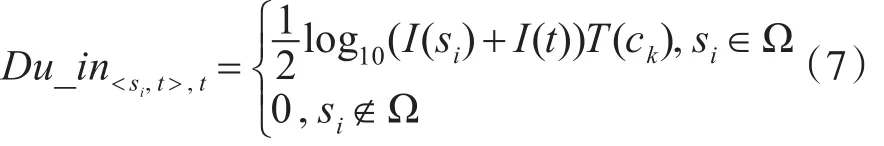
Du_in<si,t>,t表示在通话记录 < si,t> 中 t的接听时长重要性。这里定义t的接听时长重要性为t的接听重要性与通话时长T(ck)的乘积以10为基的对数。那么在整个通话网络ℂ中,t的接听时长重要性累计为i
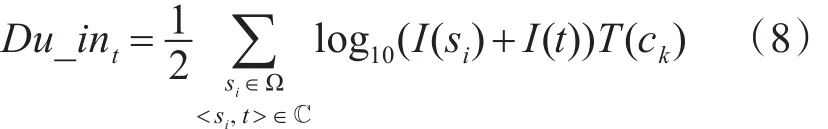
2.5 拨出广度
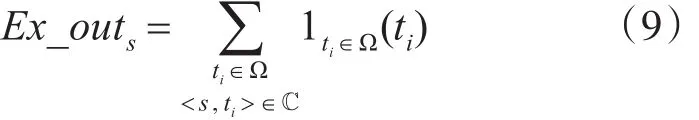
Ex_outs表示在通话记录<s,ti>中 s的拨出广度。这里s的拨出广度为ti在已知重点集合内的个数。
2.6 接听广度
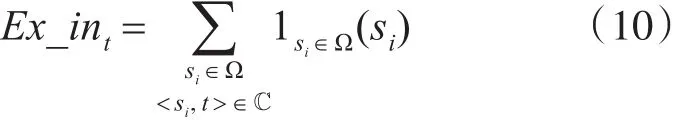
Ex_int表示在通话记录 <si,t> 中 t的接听广度。这里t的接听广度为si在已知重点集合内的个数。
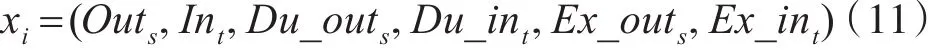
3 推荐模型
提取数据特征之后,要抽象出数据的模型。在建模之前,要先分析上述六个影响对象重要性指标的影响程度。
结合以往的案例分析,发现通联广度(即拨出广度与接听广度)对对象的影响力最大,通话(即拨出电话与接听电话)影响力次之,通话时长(即拨出时长与接听时长)对对象的影响力最小。
但是,从数据来看,对于对象影响力最小的通话时长的数值往往是最大的,我们把这种现象定义为外部极化现象。同时,通话时长的方差也是数据中最大的,我们把这种现象定义为内部极化现象。
在统计分析中,极化问题越严重,代表对于维度对数据集内部结构的解释就越大。这里用到的原理是主成分分析原理。
在数据挖掘中,极化问题往往导致模型偏向解释极化问题最严重的维度,从而弱化其他维度的影响力。
而在话单分析的问题中,我们希望提高通联广度和通话这两个影响因素对数据集的解释作用,降低通话时长的解释力。
为了解决上述问题,我们必须对数据进行无量纲和平滑处理。
而对于外部极化现象,我们采用离差标准化进行无量纲处理。
离差标准化函数为
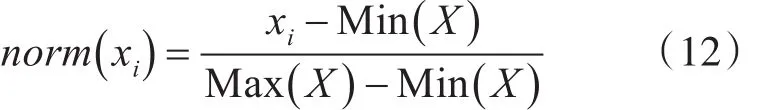
在话单分析问题中,我们选择只对通联广度和通话影响力进行无量纲处理,也就是说不对通话时长的外部极化问题进行处理。
最后我们将对象的影响力(嫌疑度)定义为
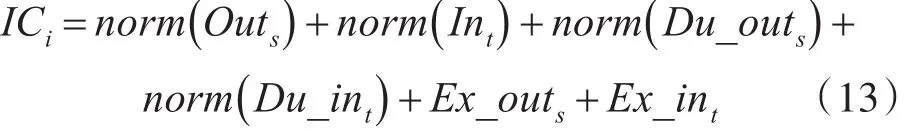
也就是说,IC越大,其影响力(嫌疑度)越大。在实际应用中,对IC进行排序,选出IC较大的作为推荐对象。
4 实验与结果
4.1 实验数据源
数据源来自某案例的话单数据。话单数据中包含的信息非常多,但是根据我们的推荐模型,只需其中的部分数据。对原始数据进行预处理,提取我们所需的数据部分,处理后的结果部分如表1所示(部分数据做了匿名化处理)。
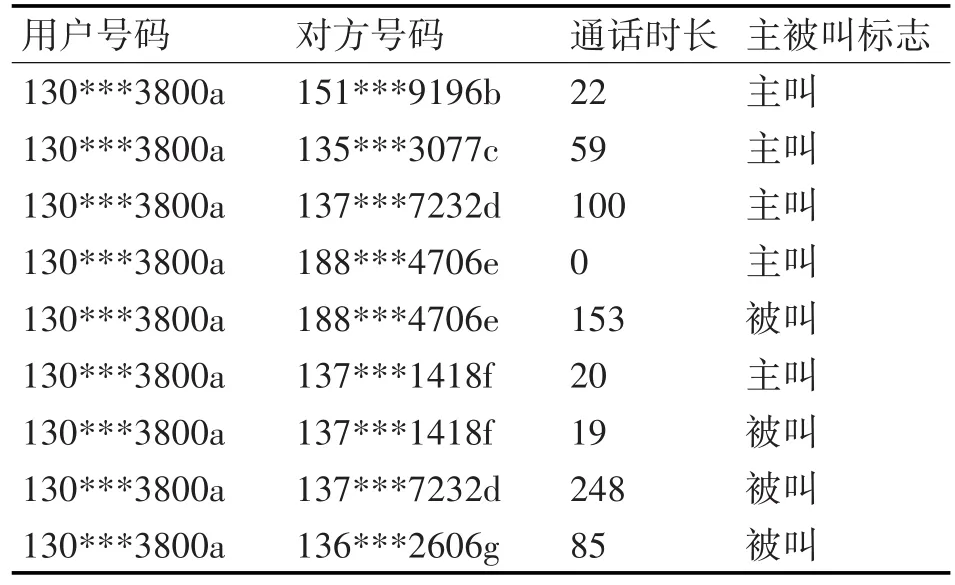
表1 处理后的数据
4.2 实验过程
根据第2节所给出的向量表示,我们先对数据质量、结构和分布进行探索。
由于特征向量包含六个影响力指标,属于多维问题。首先利用t-sne(t student stochastic neibor⁃hood estimation)对数据进行降维,然后在二维空间进行可视化,对数据处理后的结果如图1所示。
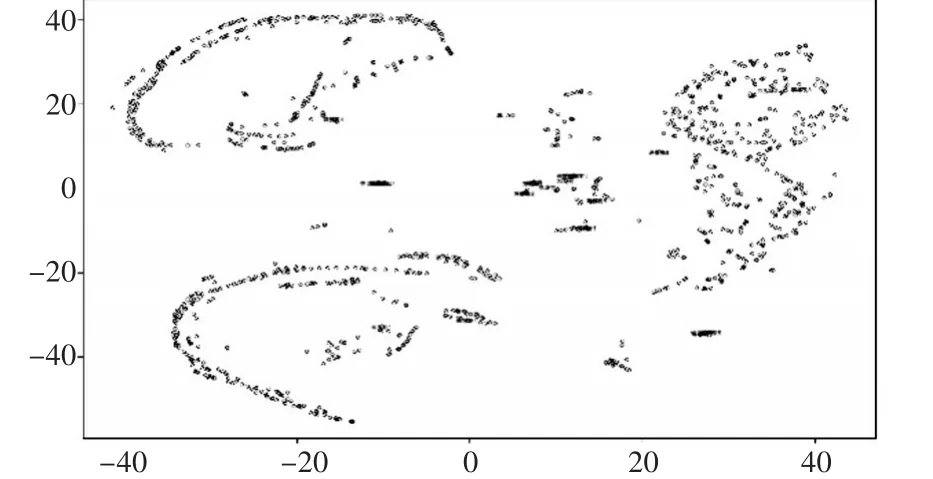
图1 降维后的结果图
可以发现上述数据集是一个可分集合,并且已知重点人具有明显的聚集情况。其中有一些较为离散的点是因为嫌疑人经常换手机,该手机号的话单数量较少,最终导致离群的现象。
接下来,采用k-Means聚类算法(center=5)对上述数据进行聚类,然后进行降维来实现可视化,得到的结果如图2所示。
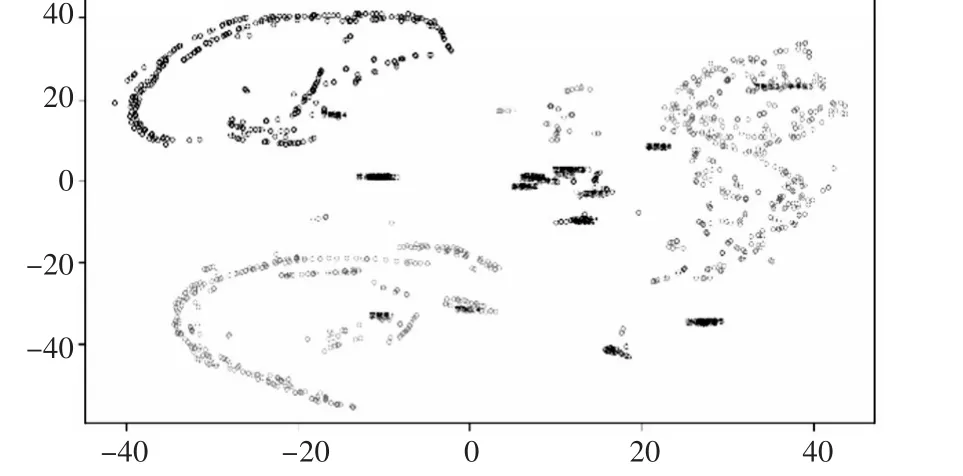
图2 降维可视化效果图
由图可以看出聚类得到的类别划分较为显著,重点人都在同一簇内。这一现象再次说明我们的特征模型是合理的。
4.3 实验结果
对数据进行处理后,使用推荐模型进行计算IC,对IC进行排序,选出IC较大的作为推荐对象,处理得到的结果如图3所示。
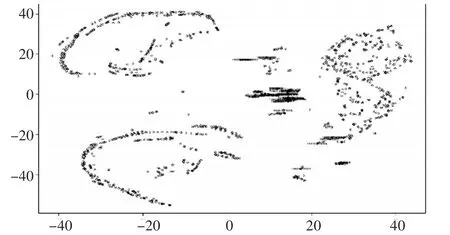
图3 推荐结果图
图中xx标注的点即为模型推荐的排名前50的对象。可以看出它们聚集现象明显。
推荐的结果中,已知重点对象基本都在名单里面。而通过后期调查,发现未知人员大部分都是涉案人员。这个结果说明我们的推荐模型是可靠的。
推荐结果部分如表2所示(部分数据做了匿名化处理)。
表2 推荐结果
5 结语
本文用图嵌入的方法研究话单,图嵌入把图中的节点进行嵌入变成可计算的点,也就是把节点向量化。相较于以往的基于社交网络的方法,图嵌入的方法可以对向量化的数据进行建模分析。相对于以往的点和线的关系,图嵌入的方法更加具体化,更能表达点与线的关系。
通过将通话网络中的点和关系向量化,从而让将机器学习算法用于话单分析成为了可能。
