结合注意力机制的新闻文本分类研究∗
2020-05-15廖闻剑黄珊珊
於 韬 廖闻剑 黄珊珊
(1.武汉邮电科学研究院 武汉 430070)(2.南京烽火天地通信科技有限公司 南京 210017)(3.南京烽火星空通信发展有限公司 南京 210017)
1 引言
随着互联网技术的快速发展,互联网上产生了规模庞大的数据,包括文本、图片、音频、视频等信息,中文新闻数据是数据信息的一种重要载体。面对纷繁复杂的文本数据,快速而准确地找到个人所需的信息变得越来越费事耗力,如何帮助用户快速定位目标信息,从而发现潜在信息,助力科学研究和提升商业价值,成为当前信息处理领域所面临的一大挑战。文本分类技术作为一种高效的信息检索与数据挖据信息技术,有助于数据信息的组织与管理,是解决上述问题的关键技术,具有广泛的研究和应用价值。
文本分类技术和其他的分类技术没有本质的区别,核心方法是提取文本的特征然后选择适当的分类器进行分类。在特征选择方面,常用的特征计算量有TF-IDF,互信息量,信息增益,χ2统计量等方法,也有更深层次的潜在狄利克雷分布(LDA)模型[1],LDA模型带有一定的语义信息,姚全珠[2]等将LDA模型生成的主题分布作为文本的特征构造分类器进行分类。在分类器选择方面,常用的分类器有支持向量机(SVM)[3~4],朴素贝叶斯(Naive Bayes)[5]和最小近邻(KNN)[6]等。
近年来,随着深度学习的兴起,深度学习方法逐渐成为自然语言处理领域的热门。Bengio[7]等提出用神经网络训练词向量表示,Mikolov[8~9]等提出一种结合赫夫曼编码的词袋模型(CBOW)和Skip-gram模型,提升了词向量训练的性能。Zhou[10]等利用长短时记忆网络(LSTM)建模,提取文本的序列信息进行文本分类。在神经网络的选择上,也有学者尝试使用卷积神级网络(CNN)进行建模。Kim[11]等利用不同尺度的卷积核多方位地提取文本特征,从而达到文本分类的目的。Zhang[12]等比较了不同层面的词嵌入对于文本分类结果的影响。注意力机制最早运用了图像处理领域,现在也逐渐应用了自然语言处理领域来挖掘文本更深层次的语义信息。Bahdanau[13]等将注意力机制应用于机器翻译任务中,提升了机器翻译的效果。Lu⁃ong[14]等提出了全局注意力模型和局部注意力模型。Lin[15]等将引入自注意力机制引入句子分类任务中,挖掘句子内部的联系从而提升句子分类性能。
综上所述,本文提出了一种结合注意力机制的文本分类方法。首先利用卷积神经网络提取文本的全局特征,考虑不同的词对于文本分类影响程度的不同,引入注意力机制构建模型,提取更加丰富的文本特征,达到提升分类效果的目的。
2 结合注意力模型的文本分类模型
结合注意力机制的新闻文本分类模型分成两部分,模型总体构架如图1如示,左半部分利用卷积神经网络进行特征提取,右半部分引入注意力机制提取,考虑不同词对于分类的不同影响,为文本分类提供更多的信息。下面将具体描述该模型的每个部分。
2.1 文本表示
文本是不能直接被计算机所理解,在进行文本处理的第一步是将文本数字化。一种最简单而直接的词向量表示方法是独热表示(one-hot Repre⁃sentation),用一个很长的向量来表示一个词,向量的长度是词典的大小,向量只在该词在词典中索引的位置取1,其他所有位置取0。这种词向量表示方法不能表达语义信息,同时由于巨大的单词表导致向量的维数很大,容易发生维数灾难。
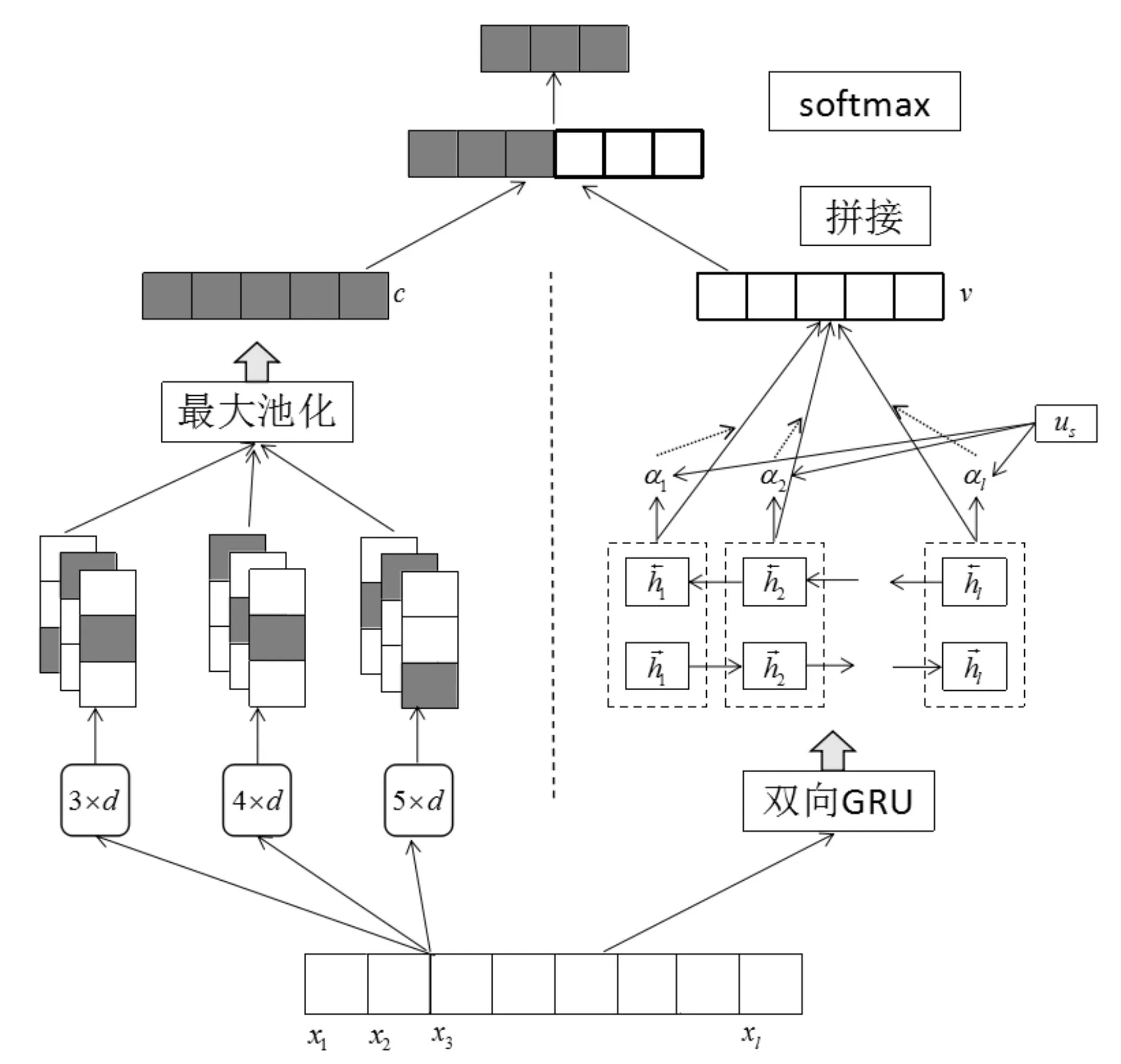
图1 整体结构图
另一种表示方法是分布式表(Distributed Rep⁃resentation),它可以将词映射成一个固定长度的向量,这些向量是带有语义信息的,语义关系越紧密的词在向量空间内的距离会更近。现在最流行的word2vec便是采用这样的词向量表示方法。如式(1)所示,文本d可视为词的序列:
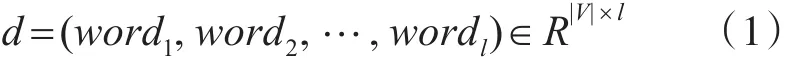
其中l表示文本的长度, ||V表示词汇表 ||V的大小,wordi∈R||V表示文本中第i个词。假设词向量矩阵M∈Rd×|V|,其中d表示词向量的维度,第i个词的词向量如式(2)所示。

2.2 卷积特征提取
经过词嵌入之后,文本被转化成词嵌入序列,如式(3)所示。
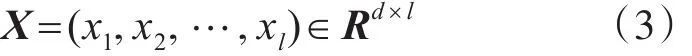
其中xi表示文本第i个词的词嵌入。接下来利用卷积神经网络提取文本的特征,如图2所示。

图2 卷积特征提取
卷积为w×d的卷积核在文本词嵌入矩阵X上向右滑动,提取窗口w上的文本特征。为了提取尽量丰富的文本特征,本文设计了三种尺度的卷积核:3×d,4×d和5×d,每一种尺度的卷积核选取200个。卷积的计算公式如式(4):
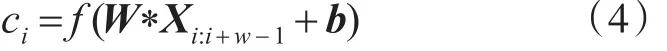
其中W 为卷积核的权值,h为窗口的大小,Xi:i+w-1为i到i+w-1窗口内的词嵌入矩阵,b为偏置,f为激活函数,在本文中选择relu函数。最后对每一个特征向量ci进行池化操作,池化能够降低特征维数,避免过拟合现象的发生。常见的池化有均值池化和最大化池化,本文采用最大化池化,即选择卷积结果的最大值。将池化后的结果,拼接之后便得到总的特征向量:
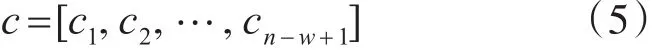
2.3 注意力机制特征提取
考虑到每一个词对于分类的贡献程度不同,本文引入了注意力机制来提取更加全面的文本特征。首先让词向量矩阵X通过一个双向GRU[16]网络,获取文本的表示。

其中xt表示第i个词的词嵌入,t表示t时刻GRU前向隐藏层的状态,表示t时刻GRU后向隐藏层的状态。将前向和后向的隐藏状态进行连接得到 ht,假设隐藏层的长度为 u,那么 ht∈R2u,H∈Rl×2u表示所有隐藏状态的集合:

然后将隐藏层状态集合H经过非线性变换得到隐含表示u,再通过随机初始化的注意力机制矩阵us与u进行点乘运算并使用softmax得到每个隐藏状态ht的权重αi。最后将每个隐藏状态hi乘以对应的权重αi并求和,得到最终的注意力词对分类的注意力矩阵v,该过程可描述为

最后,将两部分网络得到的特征向量c和a拼接在一起,经过全连接层映射成类别,最后通过softmax函数计算属于某一类别的概率。
3 实验
3.1 数据集和实验环境
本文实验在Windows操作系统下进行,使用的CPU为Intel Core i5-4590 3.3GHz,内存大小为8G。使用Python3.5编程,开发工具为Pytorch 0.4。本文实验数据采用清华大学自然语言处理实验室中文文本分类数据(THUCTC)[17],该数据包含74万篇新闻文档,划分出14个候选分类类别:财经、房产、家居、教育、科技、时尚、时政、体育、游戏、娱乐。选取了其中10个类别50000条数据作为训练集、10000条数据作为测试集、5000条数据作为验证集。
3.2 实验设置与方法
3.2.1 预训练词向量
本文使用gensim工具包词向量训练工具预训练词向量,为了保证训练出来的词向量的准确性,应选择尽量大的语料库来进行训练。为此,选取了三种公开的语料库来进行训练:维基百科中文语料库、搜狗新闻CA语料库和微信公众号语料库。在词向量的训练过程中,词向量的维度设置为512维,滑动窗口大小设为5。
3.2.2 实验方法
为了考察注意力机制的引入对于分类结果的影响,将本文模型与经典的CNN分类模型进行比较。同时,还将一些传统的分类模型如朴素贝叶斯(NB)、最大近邻(KNN)和支持向量机(SVM)加入对比实验,对比传统机器学习方法和深度学习方法对文本分类任务的优劣。模型的评价指标采用准确率(Precise),召回率(Recall)和 F1值来衡量。深度学习网络权重初始化为标准差为0.1的正态分布随机数。采用Adam方法对网络进行优化,学习率设置为0.001。为了防止过拟合,在全连接层引入Dropout[18]策略,系数设为 0.5。GRU隐藏层长度为100,输入批次大小为64。
3.3 实验结果分析
表1所示的是不同分类模型的Precision值、Recall值和F1值的比较。从表1可以看出,各个分类器在分类问题上均表现出较好的分类结果。对比传统机器学习模型和深度学习模型可以发现,深度学习模型性能均优于传统机器学习模型。实验展现了深度学习方法的优势,得益于深度学习方法强大的拟合能力,另外深度学习方法不需要添加过多的人工特征就可以达到优秀的分类性能。对比经典的CNN分类模型和文本模型,在引入了注意力机制之后,考虑了不同的词对于分类的贡献度的不同,为分类模型提供了更加丰富的特征,从而提升了分类模型的整体性能。
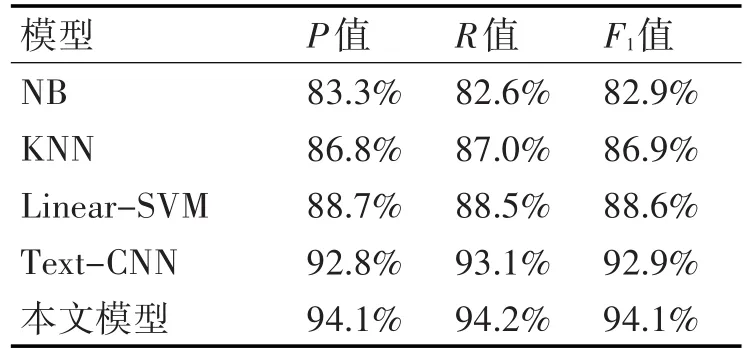
表1 不同分类模型分类结果比较
4 结语
本文提出了一种结合注意力模型的新闻文本分类方法。首先利用word2vec训练大规模中文预料,从大量文本信息中得到词的词向量,作为文本的特征表达。经典的CNN文本分类模型没有考虑到不同词对分类的贡献程度,本文利用注意力机制训练注意力网络并在经典的CNN文本分类模型中加入该特征。实验比较了传统文本方法和深度文本分类方法的优劣以及注意力机制的引入对于分类结果的影响。实验结果表明,本文提出的新闻文本方法能够提供更丰富的特征,提高分类模型的性能。
