基于时间窗口包含用户行为的微博突发话题检测方法∗
2020-05-15於跃成
蔡 莹 於跃成 谷 雨
(江苏科技大学计算机学院 镇江 212000)
1 引言
近年来,随着信息爆炸时代的到来,社交网络开始兴起,微博凭其便捷的优势快速流行起来,成为信息传播的主要途径。突发话题往往在微博初次公布,经过用户迅速传播,产生巨大的社会影响。当新颖话题涌出并与热点话题有关且引起强烈的关注,即为微博突发话题。检测突发话题可以为人类提供有价值的信息,有利于社会进行舆论分析、商业营销等相关应用价值和社会热点线索追踪。
微博突发话题是指在微博中突然初次出现的在较短时间内产生强烈影响的热点话题。与正式的长文本不同,微博是大众媒体的产物,格式随意不规范,同一个话题随着用户关注度和时间推移经历产生、发展、成熟、衰败和消亡的完整生命周期,导致大量信息冗余,产生海量过期信息,使话题呈现出一定的间隔性。这些缺点导致传统的话题检测很难识别突发性话题。
基于传统突发话题检测方法提出的挑战,本文增添动态时间窗口实时检测有意义串以发现微博中不断出现的新词,作为初步候选突发特征,将微博的时间衰减性和用户网络行为加入到传统动量模型中,对候选特征的动态变化进行建模,进而分析其动量及能量变化趋势,修正原有动量模型的不足,提升检测的准确率,从而检测出突发话题。
2 相关工作
突发话题检测是话题跟踪与检测(Topic Detec⁃tion and Tracking,TDT)的一个分支,与传统TDT方法不同,突发话题是随时间的推移动态发展的,提取突发特征来检测突发话题。TDT是以文档为中心的聚类,而微博突发话题检测主要是检测突发特征,将突发特征聚类为突发话题。YU[1]等首次提出以特征为中心的话题聚类方法,通过超几何分布来识别突发话题特征;LIM[2]等对词语权重随时间变化的曲线进行分类,使用高斯混合模型对周期性特征进行建模;Kleinberg[3]等提出二状态自动机突发特征检测方法,利用参数解析度和状态翻转代价来触发状态转移;He[4]等借鉴动力学原理对突发话题进行建模,在动量学模型基础上对参数赋权调整;Gagli[5]等提出实时分析数据流,运用软频率模式深入挖掘信息;于海峰[6]等对样本数据进行降维,将特征值隐含的风险信息在指标论域内进行扩散。上述方法适用于规范长文本,对于微博不太适用。
目前在传统方法的基础上结合了社交网络的新特性,提出一些针对社交网络媒体的突发话题检测的方法。HU[7]等把社交网络话题中TF-IDF和UF-ITUF结合,计算内容特征和用户参与度两方面主题和话题的相似度;Chen[8]等用词的突发性作为噪声过滤的重要指标,计算分隔区间的加和、标准差,按照对应的公式计算结果;TIAN[9]等将用户的影响力、回复数、收藏数来表示关键词的能量,对突发词进行相似度比较;王征[10]等提出基于信息密度的模型MBID,利用话题树的信息密度变化来发现突发话题;LIU[11]等将“#”作为 Twitter突发事件符号,通过“#”出现的位置、频次等定义了稳定性、可能性等属性;Osborne[12]等通过“Hash”的位置检测Twitter中的突发事件;Diao[13]等将微博用户兴趣与时间结合,基于泊松状态机来检测突发话题;郭跇秀[14]等通过凝聚式层次聚类对突发词集合进行合并;毛佳昕[15]等分析用户行为来预测用户信息传播的能力;李栋[16]等分析微博的用户关系,将用户关系强度定义为用户间的相似度。
上述方法大部分都是用传统的词语作为特征,并没有考虑到新词的出现。微博的新词是随着时间窗口的推移大量涌现并常作为突发特征的。本文从微博的时间特征以及用户网络行为这两个方面着手,修正原有的动量模型,对微博的有意义串[17]进行建模,实时检测突发特征,提高突发话题检测效果。
3 基于时间和用户行为特性分析的微博突发话题检测方法
3.1 基于时间窗口的微博消息流数据预处理
突发话题是指在微博中首次出现且在较短时间内产生强烈影响的热点话题。具体定义为在短时间内引起强烈关注并具有较高热度的话题,简称为“热搜”。本文先提取具有重复特征的有意义串[17]作为候选字符串,然后计算重复串的上下文邻接类别来衡量候选字符串是否满足语用多样性,用语言模型来判断字符串的语义完整性,过滤得到有意义串。最后实时检测有意义串来发现微博中涌现的新词,作为初步候选突发特征。
微博瞬时数据规模巨大,涌现出的大量有意义串是呈时间和空间的局部性特点。微博信息流是时间序列上的文本流,设置观察时间窗口T,将T内的信息流作为检测数据,提取表现重复特性的有意义串。突发话题在较短时间内大量爆发,其关键信息在较短时间内也将大量重复出现。因此,在时间窗口T内爆发的突发话题关键信息是包含在T内的有意义串中的。设置T内的信息流作为微博集合D={D1,D2,D3,…},提取D中有意义串作为初步候选突发特征,形成窗口内信息的特征空间S。随着时间窗口(如图1)的推动,特征空间S将动态变化。
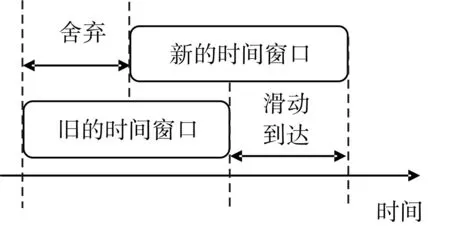
图1 时间窗口滑动过程
3.2 动量模型属性的定义
动量模型的特点是分析词频序列发展趋势及预测能量,核心是计算词频的一阶和二阶序列,检测当前状态是否存在突发性。其中一阶序列是指MACD值指标序列,是衡量突发程度的指标;二阶序列为MACD的变化值,是词频序列的发展趋势。
突发话题检测的核心是识别突发特征,在时间窗口中提取具有突发性的词语作为突发特征。本文提取动态特征空间S中的有意义串作为初步候选突发特征,借助动力学原理对其建模,定义特征的基本属性,反映特征在话题发展中的能量大小及变化走向,最终检测出突发特征。特征的属性定义如下:
1)特征的“质量”m:表示特征在文本流中的重要程度,不随时间变化,在较长时间内基本恒定。特征i的质量公式为
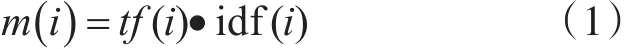
2)特征的“位移”x:指特征在某一时刻的热度,随时间动态变化。特征i在时刻t的位移计算公式为
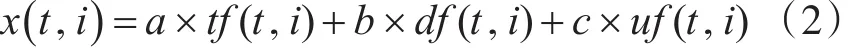
其中x(t,i)表示特征i在时刻t的热度;tf(t,i)表示特征i在时刻t出现的频次;df(t,i)表示在时刻t时包含特征i的微博出现的频次;uf(t,i)表示在时刻t的微博中包含特征i的微博用户数量;a、b、c是调节参数。
由基本属性计算特征i在时刻t的速度v,动量p和加速度a:
(2)动量 p=m×v:将m考虑进动量模型的MACD值指标,表示特征在t时刻的能量大小及变化趋势;
3.3 识别并过滤伪突发特征
特征在一个话题周期内首次大量出现称为突发,而当特征在一个话题周期内再次瞬时爆发时,与初次真正的突发存在间隔期,从发展趋势来看间隔期后的爆发点处于特征的下降趋势。为了识别并过滤间隔性伪突发特征,需要分析特征在一定时段内的新颖性。股票趋势分析方法就是针对一定时间的价格变化进行平滑,分析价格在一定时间范围的上涨或者下跌趋势。因此,本文借鉴股票趋势分析方法,对话题周期内的特征动量进行平滑,分析其趋势的走向,判断突发特征的新颖性,识别并过滤间隔性伪突发特征。具体过程如下:
1)首先需要对词频进行数据平滑,用来减少噪声影响:平滑数据用EMA来衡量。指数移动平均(Exponential Moving Average,EMA)是一种趋势类指标,用指数的形式进行递减加权的移动平均。将特征的动量时间序列进行n天指数平均,平均后的动量值与前n天的动量值相关:
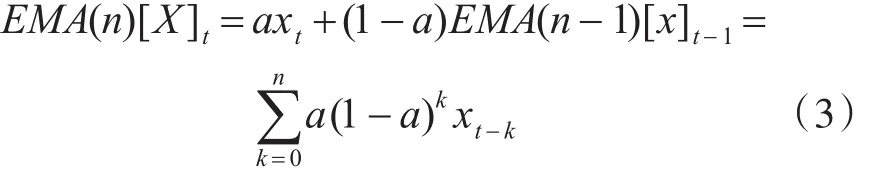
2)对平滑后的时间序列进行动量计算:移动平均收敛发散 MACD(moving average convergence-di⁃vergence)指标又称指数平滑异同移动平均线,是一种利用短期和长期移动平均线之间的聚合与分离情况来判断股票的买卖时机,跟踪股价运行趋势。在股票机制里,MACD线的组成:由一条快速线(DIF)、一条慢线(DEA)和柱状图(BAR)三部分组成。MACD指标是根据均线的构造原理,对股票价格的收盘价进行平滑处理,求出算术平均值以后再进行计算的趋向类指标。
(1)DIF=EMA1-EMA2,其中DIF指离差值,EMA1指快速移动平均线,EMA2指慢速移动平均线;
(2)DEA:DIF的平均值,DEA是MACD线经过指数平均之后的另一条线,即DEA=EMA3(DIF);
(3)BAR=2*(DIF-DEA):快速的DIF线穿过慢速的DEA线,获取动量的变化值;
借鉴股票趋势理论建模,用两个不同周期的指数移动平均序列的差来取得动量大小,差值是较快EMA线和较慢EMA线的差,用MACD线来衡量,即相当于股票趋势分析理论里的DIF线:
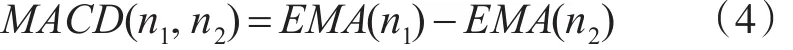
其中MACD(n1,n2)值即为文前所定义的速率v,用来检测是否存在突发信号;n1、n2为时间周期,n1<n2;
本文用H来表示股票趋势分析理论BAR,当快速MACD线穿越慢速Slow线,动量趋势发生变化:
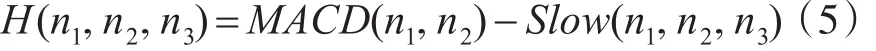
其中H表示特征平均动量和局部波动之间的差异即为加速度a,获取词频MACD值的变化,反映特征动量变化趋势,作为衡量特征新颖性的指标。判断动量模型特征是否突发后,再次根据特征的H值是否大于0判断特征是否是间隔性伪突发特征:
1)伪突发特征首次出现:H>0表示动量处于上升趋势,该特征属于突发;
2)伪特征在周期内再次出现:H<0表示特征在前期大规模爆发过,动量处于下降趋势,该特征不是新颖的突发特征。
综上所述,将非新颖间隔性伪突发特征过滤进而检测突发特征。传统动量模型并没有将时间衰减性和用户网络行为考虑在内,导致该模型在微博上检测效果不能进一步提升,因此对传统动量模型进行修正与改进。
3.4 改进传统的动量模型
传统动量模型仅仅分析特征词,并没有考虑微博时间衰减特性和用户网络行为,检测效果不能更加精确,因此本文从这两个方面进行分析,提出时间衰减性因子和微博热搜因子,从而提高检测效果。
3.4.1 时间衰减性因子
微博消息之间具有相关性,因此必须考虑时间特性。前段时间的微博对当前数据的影响会随着时间流逝而有所衰减,因此微博中时间影响力体现时间的衰减性。微博的发布数量呈指数型增长,因此时间的衰减性应该体现指数特征。
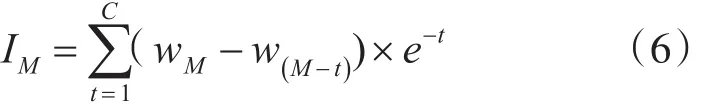
其中IM表示前M个周期的微博发布情况对当前特征的影响力,即为前M个周期蕴含时间窗口维度的位移;wt表示每个时间段t内关于特征词的微博发布总量;C表示设定的衰减性周期。
时间衰减特性体现前一段周期的数据对当前微博的影响。若前一段周期内的话题讨论量较多,则该话题获得用户的关注度更高,因此当前微博影响力较大;反之则认为当下微博的词频会随着时间衰减导致影响力不断减小。
3.4.2 微博热搜因子
传统动量模型并没有考虑用户网络行为因素,因此需要基于用户网络行为的热搜因子来改进动量模型。用户社交行为包括对微博的点赞、评论、转发等。随着时间窗口的推移,话题讨论量呈下降趋势,旧话题被新话题代替。若突发话题词频变化呈上升趋势,则说明该时段中用户网络行为较为频繁,话题关注度有所增加。若话题需要提高原有序列值,则需要一定的热度,只有更多用户参与到话题讨论中,才能使得序列得到提升,即微博的话题“热搜”。热度即为热搜因子,表示话题被用户讨论的趋势,结合热搜因子探讨一阶序列的增长变化,用以下定义来衡量重要性的大小。
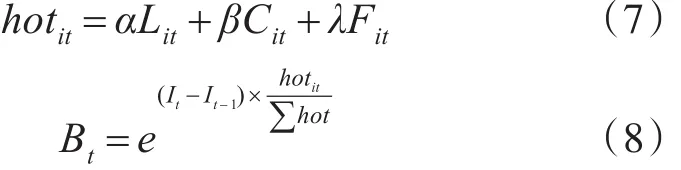
其中α、β、λ分别表示用户对微博的点赞、评论、转发的参数因子,α+β+λ=1;Lit表示用户在某时段t内对包含特征词i的微博的点赞数;Cit表示用户在某时段t内对所含特征词i的微博的评论数;Fit表示用户在某时段t内对含有特征词i的微博的转发数;∑hot表示整个时间窗口内用户对所含特征词的微博的点赞数、评论数、转发数的总数;Bt表示时段t内数据重要性的大小;It表示前t个时段内的词频序列。
改正MACD动量序列,衡量用户网络行为随着时间窗口的推移对话题的发展趋势产生的影响:
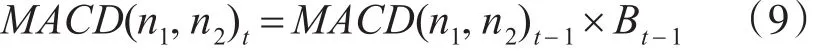
3.5 获取突发话题
采用K-means聚类算法对突发特征集合进行归类进而形成突发话题。K-means聚类是一种无监督算法,能自动依靠词频序列间的相似性合并计算,动态调整类簇中心。K-means聚类简单且时间复杂度较低,因此本文用该聚类算法合并特征词。
首先经过上述步骤过滤伪突发特征得到突发特征词,随后初始化k个随机数据作为簇类中心点,初始化方式由原始序列数据位于最大值、最小值之间的随机值确定;最后迭代得到最终k类的中心点以及标记后的突发特征序列数据:
1)把所有的点分配到k个类的系数r,属于第k个类的记为1,否则为0:rik∈{0,1}(1≤i≤N,1≤k≤K)。
2)由1)可知第k个类中的样本数量:

3)目标是最小化损失函数:
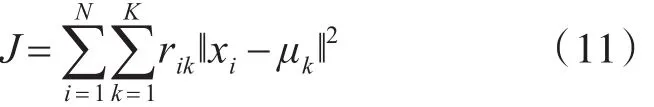
4)估算每个点到中心点的距离,给出r的系数:
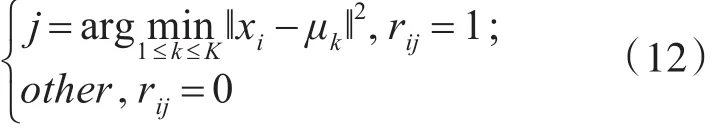
5)重新计算每个类的中心点:
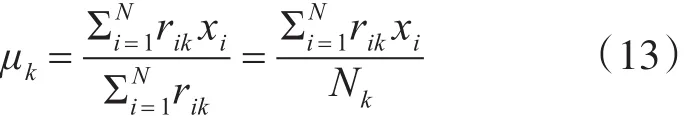
重复4)和5)两个步骤使得各类的中心点的偏离值趋于收敛,从而聚类所得的各簇类即为突发话题。
4 实验及结果分析
4.1 实验数据
本文为评估基于时间窗口的微博突发话题检测的有效性,结合新浪API编写的分布式爬虫程序,从新浪微博上爬取1000个活跃用户发表的628682余条微博作为实验数据。将2018年2月到2018年5月这三个月的数据作为训练语料,将每日的数据作为微博信息流检测突发话题。每天对数据进行手动标记,产生突发话题作为衡量实验结果的标准。实验结果通过聚类得到,最后获取算法检测后的突发话题。分离出的突发话题与直接手动标记的突发话题进行对比,获取算法检测的准确度。
4.2 实验结果及评价标准
在实验中,准确率(Precision)、召回率(Re⁃call)、F值(F-measure)是检验实验结果的三项重要指标。微博文本高度稀疏,传统聚类突发话题检测在微博上效果较差,无法确定时间区间内突发话题内容,因此通过手工提取突发话题的方法来近似作为实际检测的突发话题。本实验采用将改进后的动量模型和经典模型TF-IDF与传统动量模型来作比较。实验结果如表1所示。
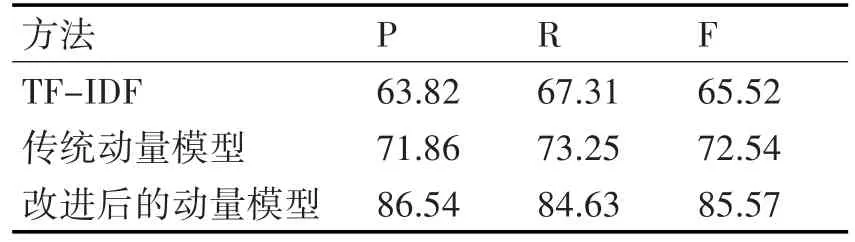
表1 模型实验结果对比(%)
从表1的对比结果可以看出,相较于TF-IDF和传统的动量模型,改进后的动量模型在精确率上占较大优势。实验表明,改进的动量模型突发话题检测方法适用于微博消息数据,可以除去大量噪音,在最短时间内能快速检测突发特征。改进的动量模型考虑时间的衰减性,对特征进行跟踪,分析随时间窗口滑动特征的能量变化,过滤伪突发特征,提高检测的准确率。数据结果表明,在传统的动量模型中加入时间衰减性因子和微博热搜因子,在实时微博数据流检测中准确地把突发特征挖掘出来,对话题中的突发信号较为敏感,放大微博数据流中的突发信号,有利于检测出突发特征。
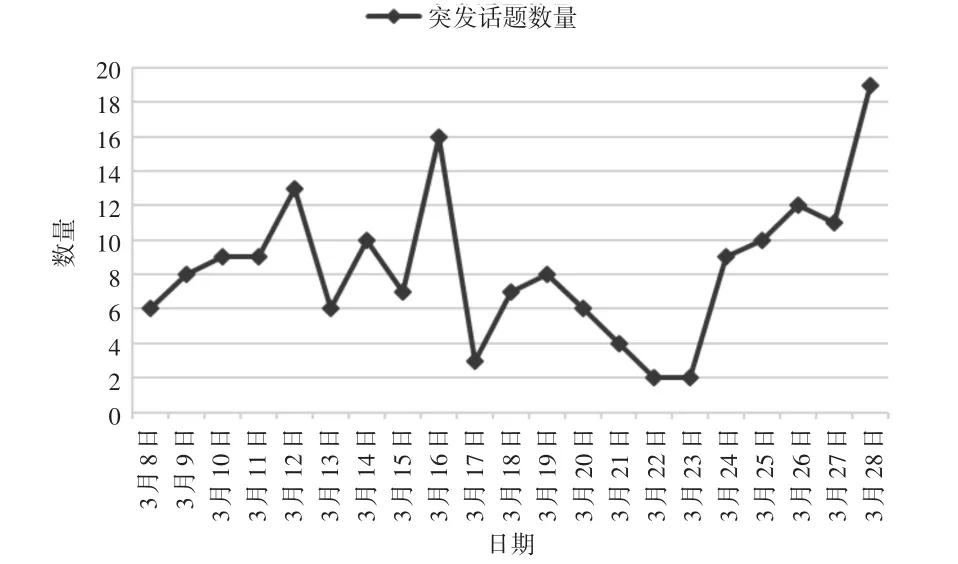
图2 突发话题数量时间分布图
图2 是从2018年3月8日到2018年3月28日的微博突发话题的数量,纵坐标表示突发话题数量,单位是个,横坐标表示日期,单位是天。可以直观看出在3月12日、16日、28日这3天明显微博的突发话题较多,话题分布相对来看比较分散,相反在3月17日、22日、23日这3天突发话题数量较少,话题相对来说比较集中。
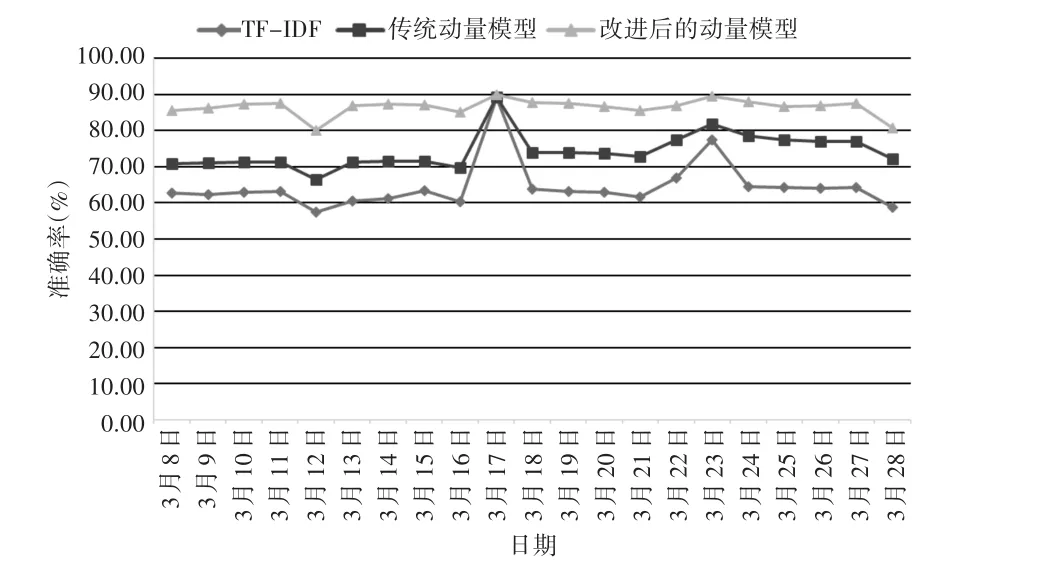
图3 实验结果准确率对比图
图3 是这二十天的TF-IDF以及传统的动量模型和改进后的动量模型方法的准确率的分布情况,其中纵坐标表示准确率,单位是%,横坐标表示日期,单位是天。从图3可以看出,在3月12日、16日、28日这3天突发话题数量较多时,这三种模型的检测结果的准确率都是较之前时间内是降低的。因为当突发话题数量较多时,话题的分布是分散的,一些突发和非突发话题相互交叉从而使得噪音较大,进而识别不出突发话题和非突发话题,导致检测的准确率大大降低。相反,在3月17日、22日、23日这3天突发话题数量较少的情况下,这三种模型的检测结果的准确率都是比较高而且相对于其他时间段来说是较为接近的。因为在微博中突发话题数量较少时,突发话题的分布是较为集中的,因此噪音相对来说会比较小,准确率会相对地提升。
5 结语
该论文以传统的动量模型为基础,鉴于微博的特点,加入了时间衰减性因子和微博热搜因子,对传统的动量模型进行改进,提出了基于时间窗口包含用户行为的微博突发话题检测方法。
实验结果可以看出,改进的模型不仅突发话题检测效果有所提升,而且相对而言降低了噪音,减少信息冗余,在检测结果的准确性方面有所提高。基于时间窗口包含用户行为特征的微博话题检测方法虽然有效地提高了检测的准确率,但是在以后的工作中还需要继续研究。微博用户都是基于好友关联的,需要考虑用户与用户之间的关系、用户之间的亲密程度以及用户对话题的感兴趣程度等这些因素对话题产生影响,因此需要进一步学习研究这些要素在突发话题检测上的影响。
