基于BPTT算法的webshell检测研究∗
2020-05-15先正锴
先正锴 甘 刚
(成都信息工程大学网络空间安全学院 成都 610225)
1 引言
随着因特网技术飞速发展和日益普及,服务器安全问题日益严峻,甚至严重威胁到网络服务的正常运行。webshell是远程攻击者上传的网页脚本(asp,jsp,php,CGI)文件,在这其中使用php的情况占多数。攻击者上传webshell到目标服务器后,系统命令被执行。webshell是一个网页源代码查看代码,可以插入恶意脚本(iframe等),上传文件各种攻击,将导致如服务器和数据库泄漏。并且可以以此为跳板,向网页传输更多的文件甚至上传一个更大功能更全的webshell。
机器学习拥有减少传统恶意代码检测方法所需的大量人工工作量的能力,以及提高webshell检测和分类准确性的能力。在分析webshell的时候,机器学习模型在标记为webshell的数据集上进行训练,在任何一种情况下,模型都可以学习类之间的差异化特征,从而能够形成一个模型,然后据此去推断模型所属是白样本还是黑样本,并且具有很高的准确性,对于新型的webshell检测是一个很好的构想。
相比于动态分析方法,静态分析消耗的时间和资源代价更小,机器学习方法模型在静态分析的基础上,仅需要opcode作为输入,拥有极大的优势。
本文主要设计包括两种基于深度神经网络结构的新方法并进行比较。一种方法是通过卷积神经网络(CNN)从灰度图像中学习。从文件中提取灰度图像,其中CNN可以从其本地图像模式获得webshell的结构特征。另一种方法是通过长短期记忆(LSTM)从操作码序列中学习。其中LSTM可以学习有关恶意代码序列和模式的特征。但是在实际实验中,一些webshell可能隐藏在很大的文件中,混入正常代码或者其他隐藏方式,导致操作码序列很长,从而在LSTM训练时可能会有梯度消失的情况出现,因此我们采用基于子序列的截断反向传播算法来解决这个问题。实验结果验证了此方法具有更好的效果。
2 webshell混淆
安全防护软件对能够执行命令或者代码的函数比如eval、assert、system等特别敏感,一句话木马不做加密变形处理容易被查杀,因此衍生出了多种多样变形逃逸方式。
2.1 字符串和运算符变形改变特征码
普通的绕过方法,利用字符串函数或者操作符等,对关键字符串进行多次加密、编码、分割等操作后,再进行拼接组合然后运行。大部分的脚本语言中都包含有操作符。不同的操作符对应的对象不同,操作功能也不尽相同。这使得代码变形有了更大的发挥空间。
<%
Function MorfiCoder(Code)
MorfiCoder=Replace (Replace (StrReverse(Code),“/*/”,“”“”),“*”,vbCrlf)
End Function
Execute MorfiCoder(“)/*/z/*/(tseuqer lave”)
%>
这段代码在被访问运行的时候,“)/*/z/*/(tseuqer lave”会被转换为“eval request(/*/z/*/)”,变成后门文件,这样来逃避通过特征码来查杀,目前市面上绝大多数webshell都是以这种动态解码方法或者类似方法进行变形来绕过检测。
2.2 编码和加解密方式加密特征码
普通的加密方法可以使用自带的加密函数例如base64、urlencode、str_rot13等进行编码和加密。这些加密关键字对防护软件十分敏感,对于函数众多的php来说,有多重编码和转换方法,也有多种加密方法。
除了系统提供的函数,还可以自己定义加密函数进行加密,常见的有可逆和不可逆加密两种方法。可逆加密即是旨在绕过查杀,当链接的时候,通过制定加密函数即可获取原文。不可逆加密即是通过RSA等密码学非对称加密算法进行加密,当攻击者连接时,需要自己提供私钥以此来解密出明文执行。不可逆加密的好处是即便shell被发现,也无法解密出明文。
2.3 利用php函数的特性
部分特有的特性或者函数,可以用来进行代码变形,常见的有preg_replace、create_function和动态函数执行以及序列化和反序列化等。这些也属于基于字符串的变形而衍生出来的方式,最终还是调用eval之类的关键函数。除了这些普通特性,一些高级特性也能够被利用于webshell上,比如反射机制,和动态函数执行的方式十分的相似,将后门代码放到/**/注释中,然后利用类的反射机制获取到,最后执行动态函数。这种方法的代码可以以任意一种格式存在,灵活度非常高。
随着技术的更新,webshell的特性和使用方式也会越来越多,其利用方式和造成的危害也会更加严重。相信不久的将来动态学习的方法会在web⁃shell检测领域发挥关键性的作用。
3 相关工作
3.1 webshell检测方法
目前通过特征对webshell进行检测的方式主要有两种,一种是静态检测,利用特征和文件相关特性异常的比较。第二种是动态检测,通过访问状态、行为模式等进行对比。多数Webshell会通过伪装成一些普通的网页文件来躲避检测。
传统及现有的检测方法如下。
3.1.1 静态检测[9]
静态检测是通过提取代码的典型特征值,对于webshell来说,典型的就是一句话木马,攻击者会对其进行各种各样的变形以逃避检测。此外,对于一些高危函数,可以去观察它的修改时间同其他作比较。这种检测方法主要是尽量预先设置规则去匹配恶意代码的主要特征,常见的一些方法有正则表达式、文件时间聚类以及关联度和语义分析等等。
因为是基于规则,所以对已知类型的木马具有很好的查杀效果和速度。不过在漏报误报方面有很大的局限性,十分依赖规则库的性能。并且对于新型的webshell木马查杀效果很不理想,很多攻击者稍微有针对性的进行改动即可绕过。
3.1.2 动态检测
动态监测实现原理类似沙箱机制,当webshell上传到服务器后,攻击者在执行后门的时候会表现出动态特征。我们在webshell的分析层修改底层函数去hook可疑的危险函数,检测代码运行过程中是否去调用了这些危险函数,或是在脚本调用这些函数的时候进行分析,判断该脚本是否为非法用户的shell。
不过动态检测在部署时可能会需要重新编译或者修改配置文件等,对于小型服务器效果显著,对于大型批量式部署则会比较麻烦。
3.1.3 日志分析
当攻击者链接webshell的时候不会留下系统日志记录,但是会有相关的访问链接记录。日志分析就是根据webshell的访问规律和正常文件访问规律不同,其主要特征例如访问次数比较少,访问总数也比较少,并且该页面文件与网站其他页面无相关联,也就是无其他页面指向webshell页面。这种方法类似数据分析,在访问量到一定的级别时利用相关设计能够有很大的参考价值。
日志分析也有一些缺点,在误报方面依旧存在问题,并且当访问量足够大的时候,相关方法的检测能力和效率较低。
3.1.4 统计学
除了之前几个方法以外,webshell在加密或者混淆的同时,会表现出一些统计学方面的特征,这方面典型的代表就是NeoPi。其主要检测方法为信息熵、最长单词、重合指数、特征和压缩。统计学主要针对加密和混淆,所以它对经过处理后的模糊代码具有不错的检测效果,相反对于原生未经过加密混淆的webshell,检测效果的表现没有那么良好。
3.2 Opcode在webshell中的应用
当Zend虚拟机解析php,执行一段代码时,一般会经历以下4个步骤:
1)Scanning(Lexing),将PHP代码转换为语言片段(Tokens);
2)Parsing,将tokens转换成简单有意义的表达式;
3)Compilation,将表达式编译成Opcodes;
4)Execution,Zend引擎接下来顺次执行 Op⁃codes。
PHP是运行在Zend虚拟机之上的,PHP中的Opcode则属于字节码。这里PHP的opcode就指的是Zend虚拟机能识别的指令。Opcode是可以由Zend虚拟机执行的单个操作的数字标识符,php扫描了人可读代码后并将其嵌入到tokens中之后,这些tokens在解析阶段被组合在一起,这些小表达式又被编译或转换为操作码。操作码是Zend VM作为一个单元执行的指令,最终会在一个数组中逐个执行并运行。
VLD(Vulcan Logic Dumper)是一个PHP 扩展,在Zend引擎中通过hook的方式输出PHP脚本生成的中间代码(执行单元)。因此我们使用VLD提取样本中的Opcodes,最常见的一句话木马实际运行情况下的操作码:
<?php@eval($_POST['password']);?>
它的opcode输出如下
op return operands
BEGIN_SILENCE ~0
FETCH_R $1 '_POST'
FETCH_DIM_R $2 $1,'password'
INCLUDE_OR_EVAL $2,EVAL
END_SILENCE ~0
RETURN 1
php webshell实际上也只是一段php代码,通过加密混淆手法,最终执行了一些特定的操作,比如执行命令、列出目录、上传和查看文件等。如果使用传统静态检测方法,直接对人们编写的源代码进行检测,那么会有很多因素影响检测结果。但是当我们在Opcode层面对webshell进行检测则可以绕过这些混淆方法。
4 神经网络研究设计与实践
4.1 CNN分析设计
CNN作为典型的深度神经网络,广泛应用于计算机视觉领域和图像相关任务。典型应用用于通过多个卷积层和池化层来处理输入数据的手写数字识别。每个卷积层输出一组特征映射,而每个特征映射表示通过一个特定卷积滤波器提取的高级特征。并且汇集层主要使用局部相关原理来完成下采样,因此后续卷积层可以从更全局的角度提取特征。这大大减少了重量参数的数量和训练深度网络的计算。
为了满足CNN对输入数据的要求,我们首先对灰度图像进行预处理。当CNN执行像图像分类这样的任务时,它会获取具有相同大小的输入图像数据。由于web文件具有不同的文件大小,各种灰度图像大小也存在很大差异,因此有必要对所有灰度图像进行标准化。
保证模型训练过程的实用性还需要对文件大小规定一个上限。为了尽可能地保留原始结构我们使用了通用图像缩放算法,其中文件字节代码被解释为一维“图像”并且被缩放到规定的大小,这是一种有损数据压缩。使用图像缩放算法主要是为了尽可能地降低数据中存在的空间模式的失真。与在进行分类之前将Opcode文件转换为2D图像的方法相比,这种方法更加简便,不需要规定图像的高度和宽度。将Opcode文件转换为字节流也保留了原始文件中字节码的顺序,原始Opcode文件的这种顺序表示它很容易应用在循环神经网络体系结构上。
我们使用OpenCV计算机视觉库将每个原始webshell文件缩放到10,000字节的大小-即在缩放之后,一个webshell样本对应于一个1字节值的序列。图1是多个webshell文件的二维灰度图像。

图1 opcode文件的灰度图像表示示例
4.2 LSTM分析设计
Ocode序列实际上反映了文件的代码逻辑和执行逻辑。因此,我们可以使用LSTM挖掘与它们的高级恶意行为相对应的序列特征。
在操作码序列提取过程中,操作码集的大小将影响操作码序列的平均长度。为了使操作码所表示的信息更加有效,需要对其大小进行控制并制定一个最佳的范围。因此,我们用词汇表来表示web⁃shell文件的文本和指令,统计它们的出现评率,对低于一定频率的进行删除。把词汇表里面的每个词汇的频率作为特征,使用随机森林模型分类,得到所有特征重要性的排名,选择具有最佳特征重要性的词汇表。最后,从操作码集中提取操作码序列。到目前为止,这些操作码序列在被用作神经网络的输入之前应该被数字化;我们使用one-hot编码方式,它只需要进行映射变换就可以获得稀疏向量,如[0,0,0,1,0,……,0]其状态位表示仅包含一个非零元素的状态。每个操作码都有一个独特的表示。
4.2.1 截断反向传播TBPTT
不仅是操作码集,输入序列过长也会影响LTSM的训练效果。本文使用截断反向传播时间(TBPTT),它增加了时间窗口约束来限制错误反向传播操作的最大距离。因此,错误传播和梯度计算仅在窗口中执行,并且窗口之外的节点的权重不会更新。与标准BPTT(或完全BPTT)相比,它通过牺牲一小部分精度来提高计算效率,当反向传播距离太长时,标准BPTT计算效果较差。此外,截断的BPTT还可以快速适应长度大的序列中的一些新生成部分。总体而言,截断BPTT方法更加合理且有效。
我们提出了一种基于截断BPTT算法的LSTM实现。由于梯度仅在窗口中传播,首先将操作码序列划分为多个子序列,其中每个子序列的长度等于截断的BPTT的窗口长度。对于每个子序列,我们只做一个完整的BPTT,它等于对整个序列进行截断的BPTT而没有交叉窗口划分。这样还可以让一系列子序列同时进行训练。利用此方法我们的训练速度可以达到之前的3倍以上。图2显示了序列长度为6,误差反向传播为3的步骤图。
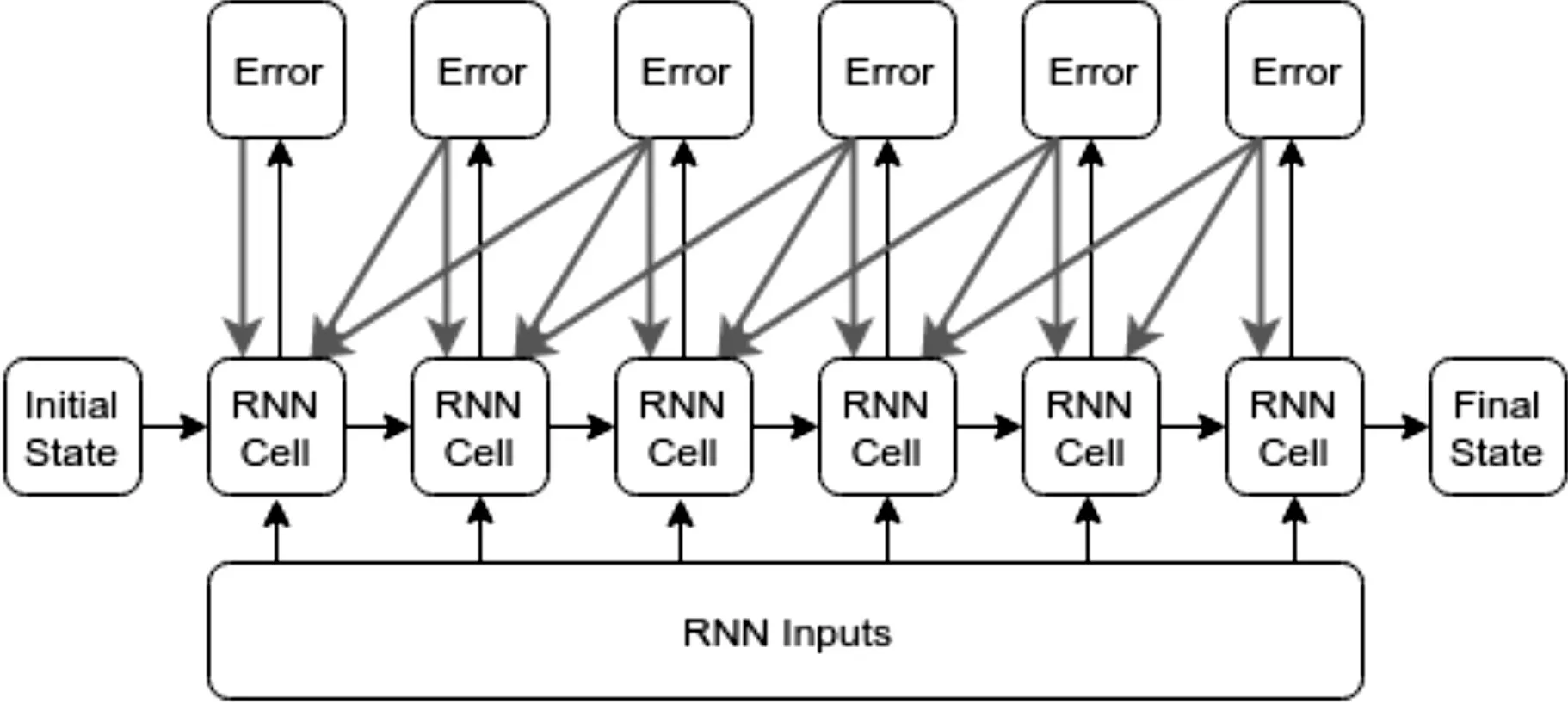
图2 TBPTT步骤图
其中本文所使用BPTT算法过程如下:
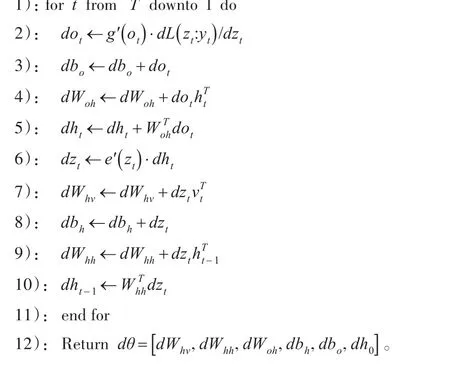
4.2.2 滑动窗口数据增强策略
此外神经网络应用到分类时,常常会出现类不平衡问题。对于webshell更是如此,往往大型网站里面web文件成千上万,和其中一些webshell差别巨大。并且对于webshell也有很多种类型,其中被广泛运用的一句话木马和一些少见的留后门方式数据集差距很大,于是我们采用数据增强策略来避免数据集的不同对后期的训练学习造成影响。
因为长度很长的两个子序列之间没有重合的部分,所以提出了滑动窗口来对长度比较大的序列进行分割。窗口长度等于BPTT的窗口长度,我们使用控制滑动窗口的大小来控制生成子序列的多少。如果窗口越大,那么子序列的数量越少,反之越多。我们用表示类总样本,βi代表总样本数,αij表示单个样本长度,其中j∈(0,…βi),χ表示滑动窗口长度。如果我们要把类总样本扩展到s,那么我们首先计算出当前滑动窗口步长di:
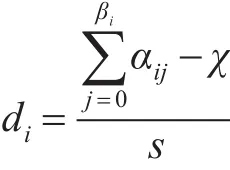
而且因为步长的最小值设置为1,所以对于总样本数还有上限设置:
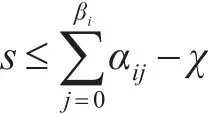
4.3 数据提取处理
我们的实验数据来自github的一些开源的php项目和一些收集的webshell项目。在预处理(重复度处理)之后,它包含2,738个不同的php源代码,1,132个标记为黑名单代码,1,606标记为白名单代码。接下来,我们对代码样本进行一些处理以便后面进行训练。使用VLD扩展从代码里面提取出opcode,然后根据php文档里面的opcode列表进行相应的序列化转换。最后,进行对样本数据的二类化标签,用0代表白样本代码,1代表恶意代码。
4.4 实验配置与结果
第一个模型将卷积层的输出连接到密集层,然后通过softmax激活连接到输出层,将每个输入分类为九类webshell中的一个,如图3所示。此CNN-基于方法使用每个webshell类的局部模式对op⁃code文件的一维表示进行分类,并且是图像分类中非常成功的神经网络架构。
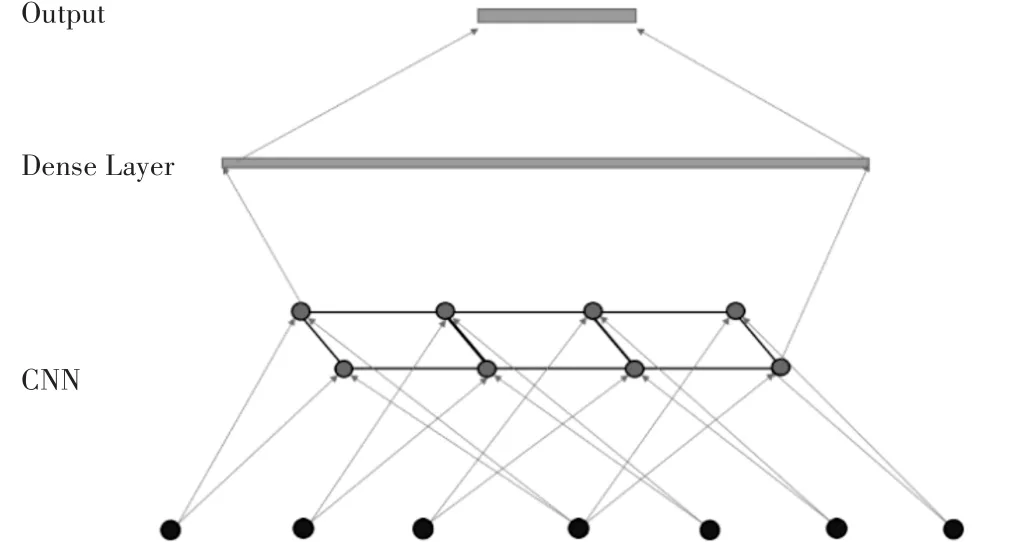
图3 卷积神经网络(CNN)模型
第二种模型,在循环层的顶部之前应用递归神经网络层也就是长短期记忆模块(LSTM),然后将循环层的输出馈送到输出层将输入分类为九个webshell类之一。我们在卷积层的顶部应用一个前向LSTM层,其中LSTM中单元从头到尾链接。
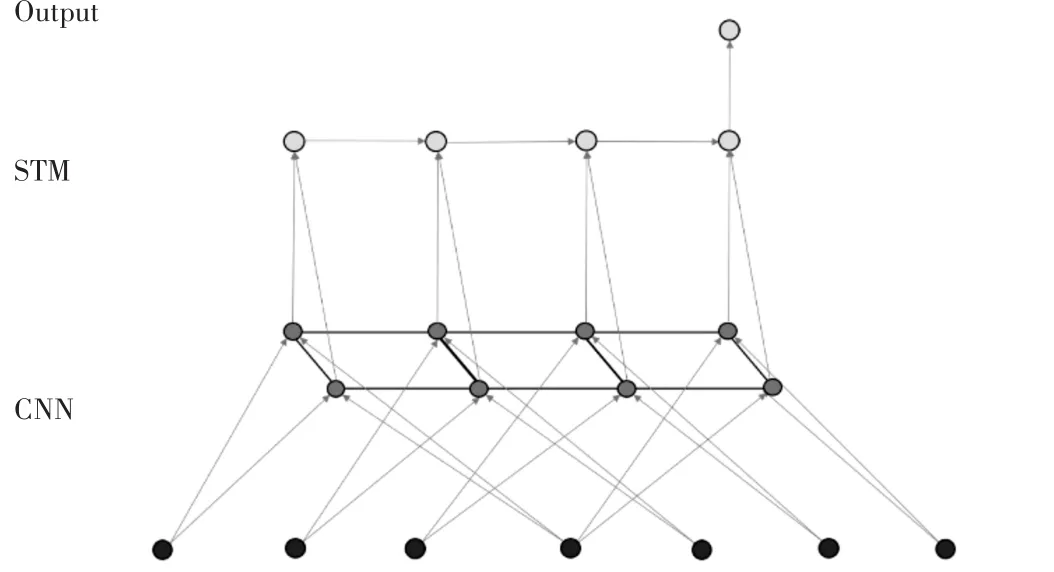
图4 (CNN+LSTM)模型
本实验总共使用了三种深度学习配置作为对比,第三种用于与第二种作对比检验基于子序列的截断反向传播方法效果:所有模型都具有三个卷积层,每层中的节点数通过其在交叉验证过程中的性能来选择。为了实现更稳健的准确度测量,我们使用五折交叉验证。数据集被混洗并分成五个相等的部分,每个部分具有与主数据集大致相同的类分布。对于具体选择的深度学习配置,我们将五个部分中的每一个设置为左侧部分,在另外4个部分上训练一个模型并记录其中样本的预测。然后汇总所有五个部分的预测,并使用它们来计算所选深度学习配置的性能。
除了使用平均分类准确度来显示模型的性能之外,还通过其针对每个类别的平均F1分数来评估模型的性能。F1值报告任何一个类别上的模型的性能作为该类别的precision和recall的调和平均值,并且平均F1值将对每个同等重要的类别的性能进行处理。
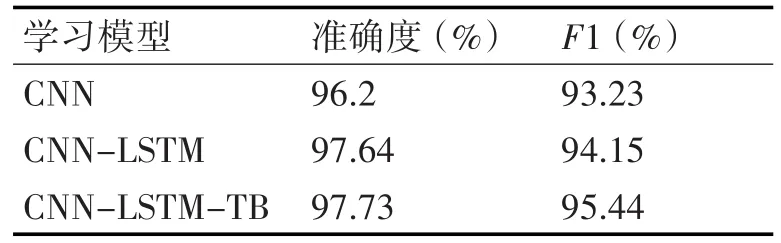
表1 使用5倍交叉验证程序的不同深度学习配置的平均准确度和F1值
最终的深度学习模型的参数如下:所有型号都有三层卷积层,带有整流线性单元(ReLU)激活功能;三层滤波器的数量分别为30,50和90。对于CNN模型,卷积层的输出连接到256个单元的密集层,然后反馈到输出层。对于具有LSTM的CNN,我们将卷积层的输出连接到一个LSTM层,每个LSTM层具有128个隐藏单元;然后,LSTM层的输出连接到输出层。这些模型都是使用带有Tensor⁃flow后端的Keras库实现。
采用5倍交叉验证过程,通过Adam优化方法修改模型的权重,用0.001的学习速率最小化交叉熵。因为对于传统的随机梯度下降在训练中学习率并不会发生变化,Adam算法可以计算梯度的一阶矩估计和二阶矩估计,从而对不同的参数可以拥有独立的学习率。
表1显示了3种不同深度学习配置的平均准确度和F1值。
根据结果可知,几乎所有的检测都达到了95%以上的准确度,其中使用反向截断滑动窗口算法的CNN-LSTM-TB具有最佳的F1分数和验证数据的最佳准确度。
5 结语
本文分析了webshell的一些流行变形方式,然后介绍了现今常见的一些webshell的检测方法。最后提出了使用了反向截断滑动窗口算法的神经网络方法来对webshell进行检测,通过不同深度学习框架对经过处理后的恶意后门进行检测,实验结果表明相关算法及神经网络模型对webshell有着极高的检测准确度,并且F1值也十分出色,验证了我们的构想。传统的检测方法对已知类型的web⁃shell有着不错的检测效果,但是人力成本和商业成本花费开销巨大。并且对于未知类型的检测是重中之重,往往造成巨大危害后果的就是少数躲过检测的新型变种,除了神经网络,我们还可以尝试使用其他算法或者训练模型来进行检测。
