基于三支决策粗糙集思想的RFM客户细分模型∗
2020-05-15陈昭君阎瑞霞彭连贵
陈昭君 阎瑞霞 彭连贵
(上海工程技术大学管理学院 上海 201620)
1 引言
在当今的大数据时代,人们的生活以数据的形式被多方记录、收集、存储着,企业比以往任何时候都更多地拥有商业数据。如何从海量的商业数据中挖掘出有价值的信息,发现数据中可能存在的某种潜在的关系或规则,并被有效利用以实现企业战略目标,成为许多企业越来越迫切的需求,在这种情况下,数据挖掘技术应运而生。客户细分是数据挖掘技术的一个重要应用领域,也成为许多管理者和学者在客户关系管理中的研究热点[1~3]。
客户细分是20世纪50年代中期由美国学者温德尔史密斯提出的,它是企业客户关系管理的核心环节,也是认知客户价值并进行个性化精准营销的关键,通过客户细分,企业可以更好地识别不同客户群体的需求以及其对企业的价值,并据此赢得、扩大和保持高价值的客户群,吸引和培养潜力较大的客户群。由于不同企业的研究目的不同,用于客户细分的指标和模式也不尽相同。目前主要有以下四类客户细分模式:基于客户统计学特征的客户细分、基于客户价值相关指标的客户细分、基于客户生命周期理论的客户细分和基于客户行为的客户细分[4]。
该论文采用基于客户消费行为的RFM模型(Recency为最近购买时间;Frequency为购买频率;Monetary为总购买金额)进行客户细分的应用研究。目前基于RFM模型的客户分类方法主要有两种:以各指标的平均值为界线,将客户分为8类;将各指标的总体划分成五个等级,共产生125类。第一种分类方法对各指标的划分太过粗放,使得单个或多个指标变量处于平均值界线附近的客户的分类误差较大,分类结果不够细致。第二种分类方法对各指标的划分比较细致,但将客户细分成125类,会给企业后续的精准营销带来很大的挑战,同时对于客户个体平均消费水平不高但客户数据量比较大的企业来说,会大大增加营销成本。因此,该论文借鉴三支决策思想,将三个属性指标按等级高低分成三类,总共能产生27类由不同属性等级组合成的客户类型簇,这种属性划分方式既能够对各属性指标进行较为细致的划分,又使得最后的客户类型数量适中,这种方法也对处于各属性指标平均值邻域内的客户进行了有效的划分。
该论文的主要创新点如下:
1)基于粗糙集和三支决策理论的属性权重确定方法,同时考虑了正域、负域中的元素贡献程度,且该方法完全依据数据集本身,不需要任何先验知识,结果比较客观,明显优于传统的层次分析权重确定方法[5]。
2)借鉴三支决策粗糙集思想,用经典的RFM细分模型代替基于客户价值评价的指标体系,对消费型企业来说,RFM模型的三个指标能够很好地反映客户的购买能力和客户价值,并且数据指标易于获取,将各指标划分成3个等级,共产生27类属性组合,相比把各指标变量分为两类或五类,这种方法能够兼顾细分粒度和分类精度,减小了大量的客户类群给个性化精准营销带来的挑战。
3)运用决策树技术挖掘客户细分规则。由于客户细分的最终目的是能对企业的客户进行快速准确地划分类别,以便及时地提供个性化精准营销服务,并且RFM客户价值评价模型属性指标数量较少,因此适合用决策树技术创建客户细分决策规则,为企业提供了一种新的客户细分方法。
2 基础知识
粗糙集(Rough Set)理论是Pawlak教授于1982年提出的一种能够定量分析处理不精确、不一致、不完整信息与知识的数学工具,它的基本思想是通过关系数据库分类归纳形成概念和规则,通过等价关系的分类以及分类对目标的近似实现知识发现[6]。
定义1[7]:设U 是对象集,R是U 上的等价关系,对于任意的 X⊆U,X关于R的下近似-R(X)和上近似 Rˉ(X)分别为
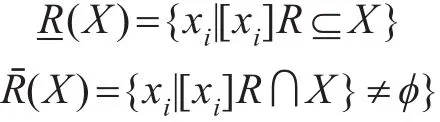
定义2[8]:决策粗糙集通过引入一对阈值α和β来定义正域,负域和边界域中的事件对象,设0≤β<α≤1,则(α,β)正域、边界域和负域可定义为

当α=1,β=0时,上面3个式子就转化为Paw⁃lak粗糙集模型;当α=β=0.5时,其转化为0.5-概率粗糙集模型;当 β=1-α时,其转化为对称变精度概率粗糙集模型;当 β≠1-α时,其转化为非对称变精度概率粗糙集模型。
由于运用决策树技术做分类决策时,决策过程简单直接,决策结果直观且易于理解,考虑到RFM客户细分模型的条件属性较少,因此该论文采用决策树技术,运用ID3算法创建一个基于消费者行为数据的客户细分决策规则。ID3算法建立决策树的具体实施步骤如下[9]:
第一步:计算决策属性信息熵。
设数据集S的样本数量为n,而数据集S又被决策属性划分成m类,每一类含有的样本数用ni表示,那么数据集S的信息熵,即建立决策树需要的总的信息量为
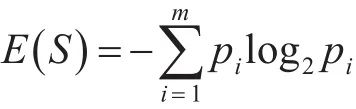
其中,pi=ni/n,表示不同决策类的样本数量在数据集总量中的占比,由于信息是以二进制编码的,所以公式中的对数的底数为2。
第二步:计算条件属性信息熵。
条件属性集A={a1,a2,…,am}中,任意一个条件属性ai的值分别为ai1,ai2,…,aiv,任一条件属性ai同时也把数据集划分成v类,用Sv来表示,即,那么,每个属性的期望信息熵为
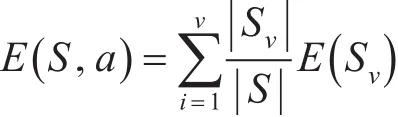
其中 ||Sv||S为每个属性取值在该属性所有取值中的权重。
第三步:求不同属性信息增益。
任意一个属性的信息增益是指选取它作为决策树根节点时需要获取的信息量,也表示它对分类提供的信息量,其计算公式为Gain(a)=E(S)-E(S,a)。
第四步:决策树的剪枝。
在建立决策树的过程中,会不可避免地混入一些噪声数据,这就需要通过一定的手段限制决策树的生长或者在决策树建立完毕之后,对决策树进行修剪。剪枝的方法主要有两种:前向剪枝和后向剪枝。前向剪枝主要是在决策树还没有完全生成的时候进行剪枝,容易丢失信息;而后向剪枝主要是系统的开销比较大,必然会生成很多被剪掉的子树,含有较多的无用功[10]。
第五步:建立决策树。
比较第三步中不同属性信息增益的大小,选择Gain(a)值最大的属性作为根节点,由该属性的不同取值建立分枝,对各分支的实例子集递归,用该方法建立树的节点和分枝,直到某一子集中的数据都属于同一类别,或者没有属性特征可以再用于对数据进行分割,并根据第四步中的剪枝策略,适当地忽略掉噪声数据。
3 基于三支决策粗糙集思想的RFM客户细分模型
3.1 数据标准化与离散化
对于RFM模型中的三个指标数据,首先要进行标准化无量纲处理,以避免不同计量单位对聚类分析结果的影响[11]。具体来说,R为损益变量,损益变量是指变量的数值越小,对结果的正向影响越大,即客户最近一次购买时间距现在的时间间隔越短,表明客户的价值越大;F和M为增益变量,增益变量是指变量的数值越大,对结果的正向影响越大,即客户的购买频率和购买金额越大,表明客户的价值越大。针对这两类变量,该论文采用以下方法对数据进行标准化处理。
标准化后的R变量为
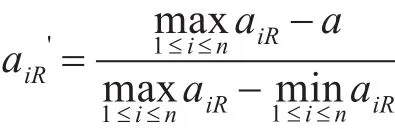
标准化后的F和M变量分别为

将各个指标变量标准化处理后的数据离散化,按值的大小划分成三段区域,用1,2,3表示程度等级,其中R=1,最近一次购买行为发生时间与现在时间节点的间隔较长,客户价值较低;R=3,最近一次购买时间间隔较短,客户价值相对较高;R=2,处于这两者之间的中等水平。同样地,可对购买频率和购买金额做出相应的解释。等级划分不但能为下一步用三支决策方法确定属性权重带来计算上的便利,也使后续的聚类分析更直观,易理解。具体程度与等级定义如表1所示。
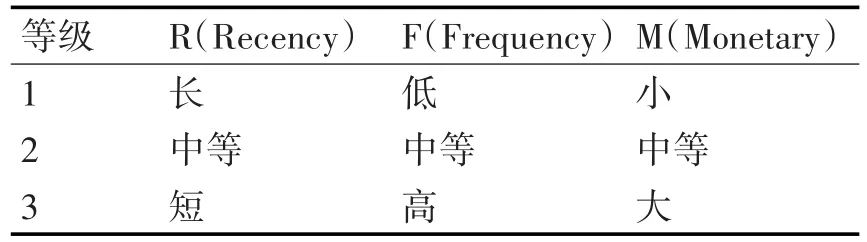
表1 属性等级划分
3.2 RFM属性重要度
目前,大多数客户关系管理研究普遍采用层次分析法来确定指标权重[12],但由于层次分析法需要获取判断矩阵的最大特征根以及相对应的特征向量,计算比较复杂。另外,运用层次分析法时,定量数据较少,定性成分多,结果不易令人信服。因此,该论文采用文献[13]提出的一种基于粗糙集与三支决策理论的权重确定方法来确定属性权重,该方法同时考虑了正域、负域中的元素贡献程度,定义了一种新的属性确定度,与传统Pawlak属性重要度相比,该属性确定度既考虑了正域中元素的贡献程度,又考虑了负域中元素的贡献程度,使得其决策更加客观合理。
定义 3(属性重要度)[13]:给定一个信息系统S=(U ,A,V,f ),其中 U={x1,x2,…,xn} 表示非空有限论域集,表 示 属 性 集 ,∀B⊆A且a∈A-B,那么,属性a的属性重要度为
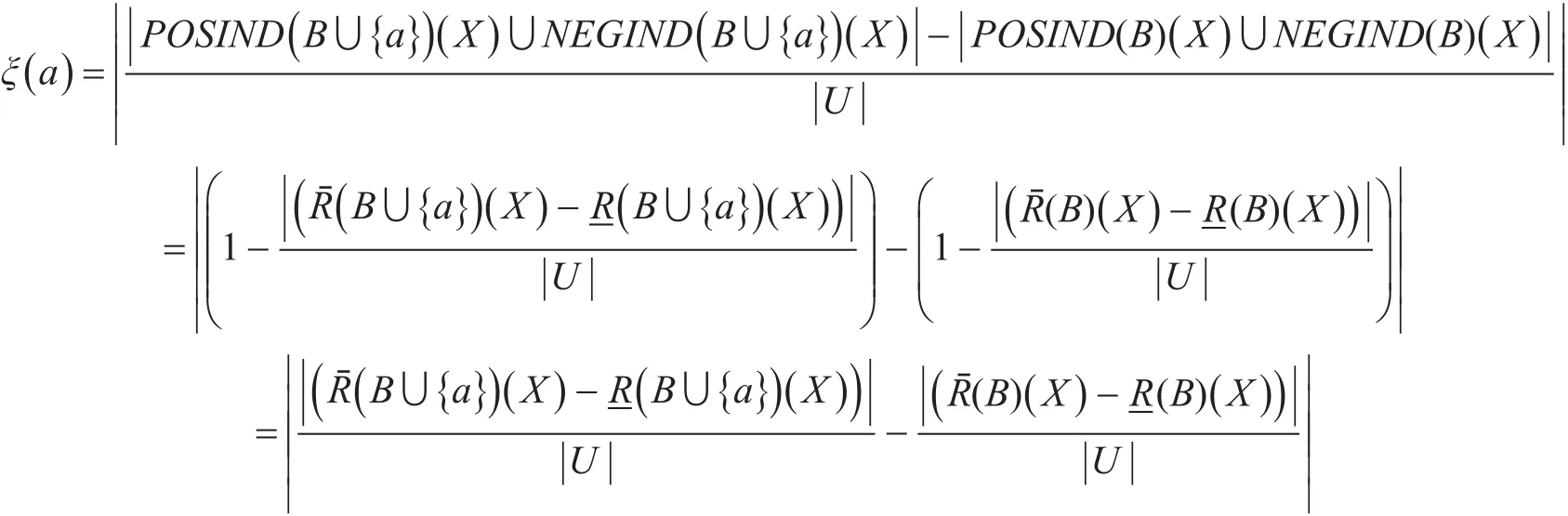
该论文中,论域为待分类的客户群,属性集为A={R ,F,M } 。基于三支决策思维,所有客户的状态集可假设为
Ω={高 价值客户,重要发展客户,一般价值客户} ,并且R,F,M都为必要属性,故无需考虑属性约简,即ω(a)=ξ(a)。
3.3 客户价值聚类
由于K-均值聚类算法能使同一簇内的对象具有较高的相似度,而不同簇之间的相似度较低,因此成为目前最常用的聚类分析算法。该论文借鉴三支决策思想,将三个属性指标按等级高低分成三类,总共能产生3×3×3=27类不同的客户类型簇。
对聚类分析得到的27类客户群,计算出每簇客户的价值并进行排序,从而能明显地看出不同客户类型的价值高低,并对价值排序靠前的9类客户定义为高价值客户,对价值排序后9位的客户簇定义为一般价值客户,而处于价值排序中间位置的9类客户簇定义为重要发展型客户。对客户价值的计算,该论文用分别表示第 j类客户的R,F,M各个指标标准化后的平均值是第j类客户的RFM各项指标加权后的总价值,计算公式为
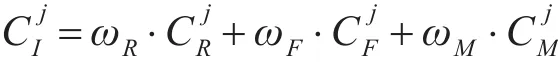
其中 j=1,2,…,27.表示聚类后的类别[14]。
对属于一般价值客户的属性组合进行剪枝处理,使决策树停止生长。
3.4 客户细分的决策规则
本研究的最终目的是要根据R,F,M三指标的大小,准确地对客户进行分类,为后续开展相应的营销活动提供支持[15]。在上述前向剪枝的基础上,依据计算所得的各属性信息增益大小,建立决策树,并从中提取决策规则:对于高价值客户,需要重点经营与维护;对于一般价值或低价值客户,需要刺激他们的消费或减少对他们的营销投入;对于重要发展型客户,需要根据客户的后续购买行为,选择适当的营销策略,并持续关注这类客户,努力把他们转化为企业的高价值客户。
4 算例分析
4.1 数据采集与处理
由于电子商务企业有着数据量大,交易数据易于保存、易于查找和分析处理等特点,所以,该论文实例数据来源于一家女装网店近1年的销售数据,数据总量为30674条,共892名客户,从中随机选取了25名客户的数据作为样本。数据经过标准化和离散化处理后,按值的大小划分成三段区域,分别用1,2,3表示程度等级,数据处理结果如表2所示。
4.2 客户价值聚类分析
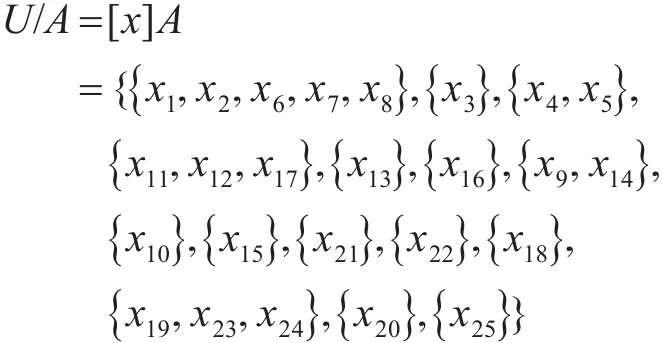
A的上、下近似集为
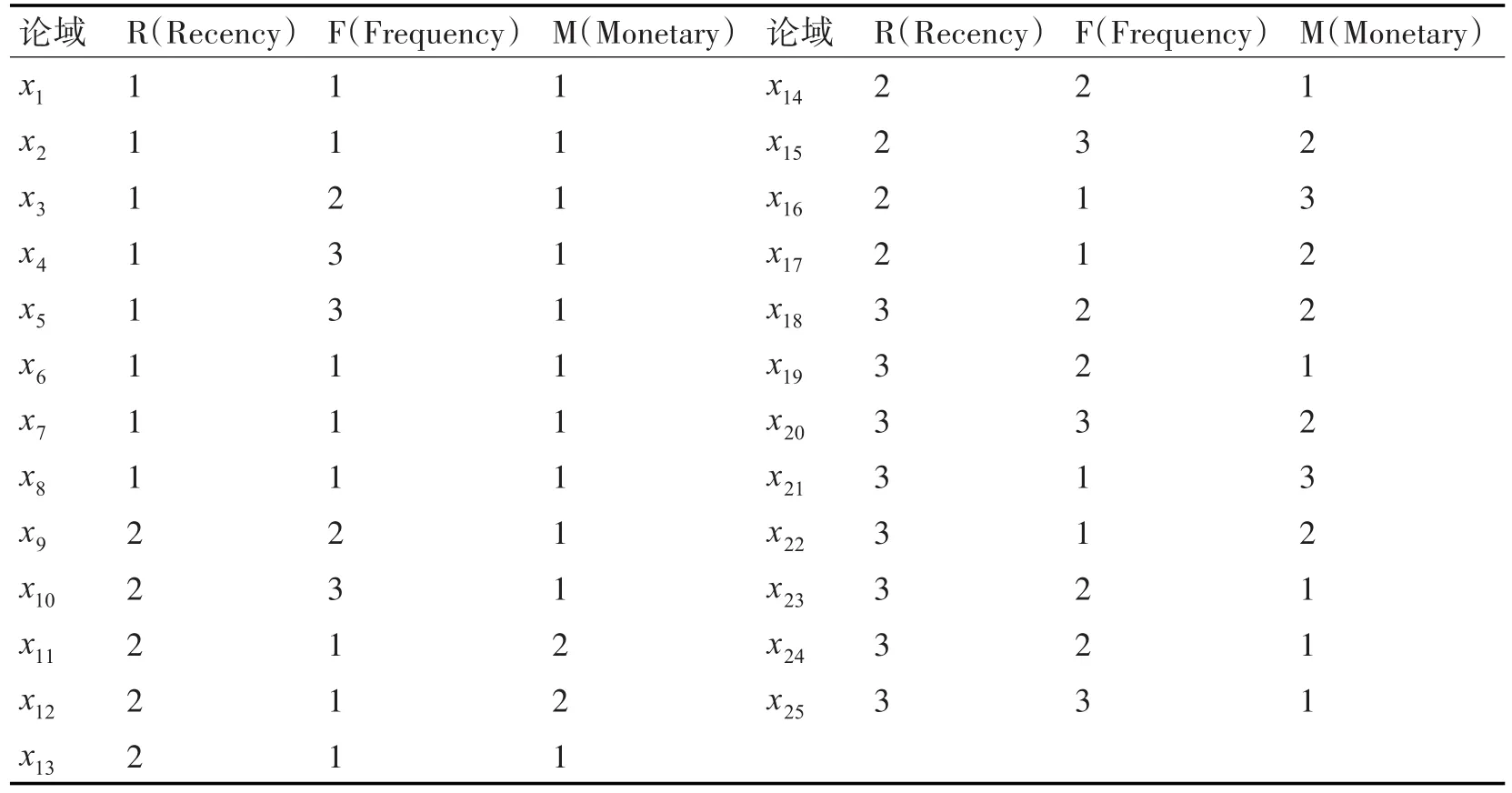
表2 基于RFM模型的客户价值评价表
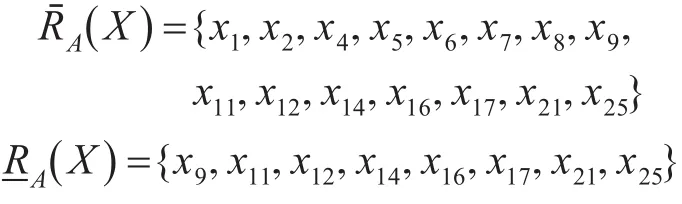
B1的等价类为
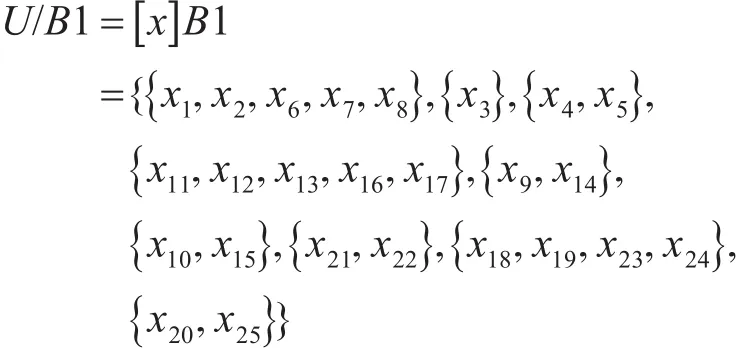
B1的上、下近似集为
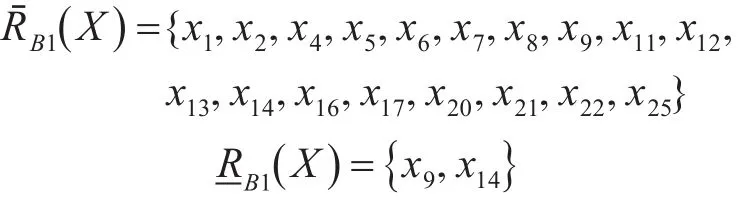
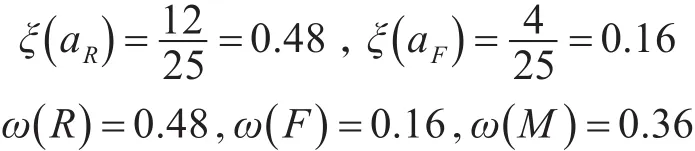
所以,计算各个客户的价值且按大小进行决策分类,并结合上述不同属性权重的大小比较:全部数据集聚类分析得到的27类客户的价值评价结果如表3所示,对于表3中决策类为低的客户属性组合,建立叶子结点,在决策树中不再进行向下分枝。
4.3 客户细分决策树
表3中,基于RFM模型的客户信息系统,客户按价值被分为三类,分别为高价值客户、重要发展客户和一般价值客户,基于上述的客户价值评价表,很容易看出,样本个数n=25。客户按价值被分为三类,故所以,决策属性信息熵为
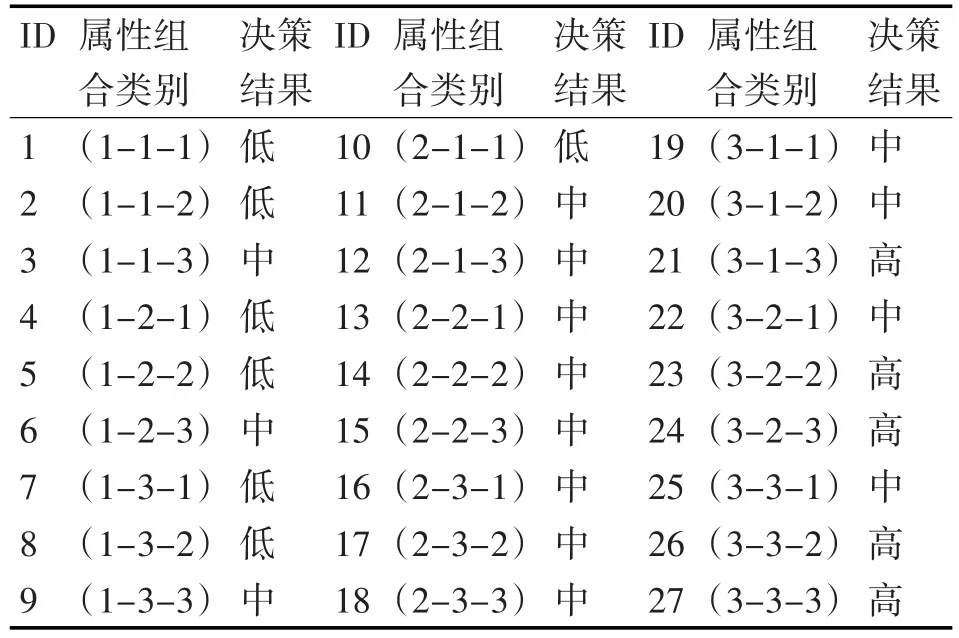
表3 客户价值分类结果
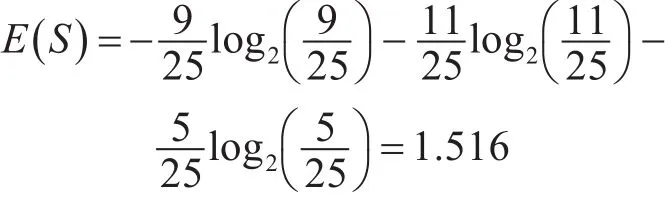
各条件属性信息熵分别为
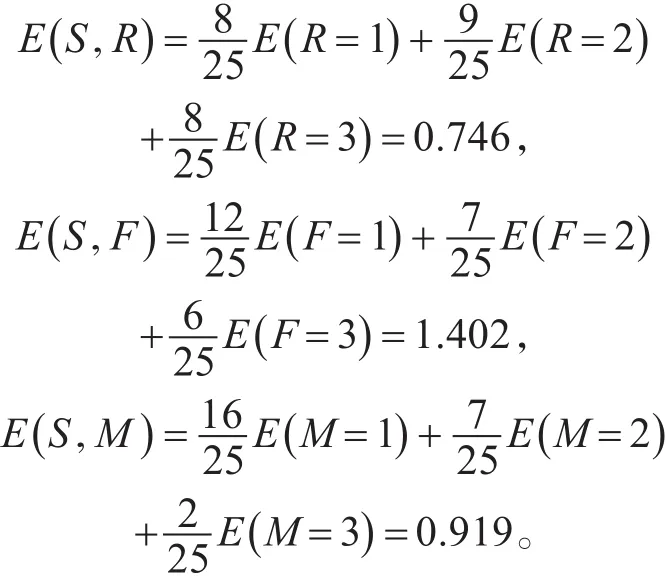
各属性的信息增益为


图1 决策树结构
由决策树能够得到以下决策规则:
1)IF(购买间隔=‘短’)AND(购买金额=‘小’)THEN(属于重要发展客户);
2)IF(购买间隔=‘短’)AND(购买金额=‘中’)AND(购买频率=‘低’)THEN(属于重要发展客户);
3)IF(购买间隔=‘短’)AND(购买金额=‘中’)AND(购买频率=‘中’)OR(购买频率=‘高’)THEN(属于高价值客户);
4)IF(购买间隔=‘短’)AND(购买金额=‘大’)THEN(属于高价值客户);
5)IF(购买间隔=‘中’)AND(购买金额=‘小’)AND(购买频率=‘低’)THEN(属于一般价值客户);
6)IF(购买间隔=‘中’)AND(购买金额=‘小’)AND(购买频率=‘中’)OR(购买频率=‘高’)THEN(属于重要发展客户);
7)IF(购买间隔=‘中’)AND(购买金额=‘中’)OR(购买金额=‘大’)THEN(属于重要发展客户);
8)IF(购买间隔=‘长’)AND(购买金额=‘小’)OR(购买金额=‘中’)THEN(属于一般价值客户);
9)IF(购买间隔=‘长’)AND(购买金额=‘大’)THEN(属于重要发展客户)。
5 结语
本文主要是运用粗糙集理论和决策树技术,求得属性权重并挖掘客户细分规则,为企业提供了一种新的客户细分方法。一方面,用经典的RFM细分模型代替基于客户价值评价的指标体系,对消费型企业来说,RFM模型的三个指标能够很好地反映客户的购买能力和客户价值,并且指标数据易于获取;另一方面,用基于粗糙集理论的权重确定方法代替常用的层次分析法,该方法基于数据本身,不需要先验信息,从客观的角度对属性进行判断,计算相对简单。有效的客户细分能够减少对低价值客户的营销投入,以节约资源用于对高层次客户的精准营销,他们是企业主要的利益来源,同时持续关注中档客户的后续消费行为,创新营销模式与方法,争取将他们转化为企业的高价值客户,提升企业的利润率。
