基于用户偏好挖掘生成对抗网络的推荐系统*
2020-05-13李广丽邬任重姬东鸿张红斌
李广丽,滑 瑾,袁 天,朱 涛,邬任重,姬东鸿,张红斌+
1.华东交通大学 信息工程学院,南昌 330013
2.华东交通大学 软件学院,南昌 330013
3.武汉大学 国家网络安全学院,武汉 430072
1 引言
互联网的快速发展使Web 上的信息呈指数增长,为缓解“信息过载”问题,人们着力构建各种推荐系统。推荐系统是一种有效的信息过滤机制,它可从大量候选信息中发现符合用户兴趣的产品和服务,更好地拟合用户实际需求。尤其对于电影、音乐、书籍、家电等评分类产品,推荐系统的实际效果非常显著。因此,Amazon、京东、Google、Facebook 等互联网企业均研发了相关的推荐系统。基于推荐系统,它们自动、高效地向用户推荐其产品和服务,获取了巨大的经济效益。
本文主要贡献:基于生成对抗网络[1](generative adversarial networks,GAN)框架,提出用户偏好挖掘生成对抗网络(users’ preference mining GAN,UPMGAN),围绕用户偏好挖掘展开推荐系统研究:基于三元组损失算法[2](triplet loss)对MovieLens 数据集的评分矩阵进行处理,挖掘难分负样本以更好地确立正样本,为准确刻画用户偏好奠定基础;采用SVD++算法[3]设计UPM-GAN 的生成模型,即利用SVD++算法中的偏置信息及隐式参数描述用户隐含偏好,以提高评分预测精度;基于GAN 框架完成推荐过程对抗学习。实验表明:UPM-GAN 可准确刻画用户偏好,从而改善推荐质量。同时,UPM-GAN 收敛速度更快,模型训练过程也更平稳。
2 相关工作
推荐系统是一种有效的信息过滤机制,它主要包括两大类[4]:一类是基于内容的推荐系统,它为用户和项目创建配置文件,以表征其特性,然后基于用户、项目之间的相似性生成推荐结果。它常采用最近邻[5]、贝叶斯分类器[6]等模型完成推荐。如在电影推荐中,项目特征包括电影类型、演员等,用户特征指用户曾评价的电影,它们也包含电影类型、演员等信息,故基于KNN(K-nearest neighbor)模型可计算用户与项目间的相似性。然而,某些领域配置文件需专业人员设置,故推荐系统专业性较强,不适合跨领域应用。目前,较成功的基于内容的推荐系统是音乐基因组计划[7],它被应用于互联网服务Pandora.com。另一类是基于协同过滤的推荐系统,它依赖用户过去的行为完成推荐。如浏览记录或评分等,它无需创建配置文件,而仅需分析用户之间的关系及项目之间的依赖性。它常采用矩阵分解[8]、因子分解机[9]等模型完成推荐。一般基于协同过滤的推荐系统比基于内容的推荐系统更准确,但它存在冷启动问题,因此有研究者将上述两类推荐系统进行混合,构建混合型推荐系统[10],以发挥不同类型推荐系统的优势,获取更优推荐效果。
近年来,深度学习(deep learning)在机器视觉、自然语言处理等领域快速发展[11],这为推荐系统的研究带来了新机遇。深度学习模型是一种深层次非线性网络结构,它可获取深层的用户和项目特征表示,即深层语义信息,为建立优秀的用户模型和对象模型奠定基础。目前,推荐系统中常用的深度学习模型包括:卷积神经网络[12](convolutional neural network,CNN)、多层感知机[13](multi-layer perception,MLP)、深度结构化语义模型[14](deep structured semantic model,DSSM)、自编码器[15](autoencoder,AE)等。此外,研究者还尝试混合若干种深度学习模型,完成高质量推荐。例如,Chen 等[16]提出基于位置感知的新闻推荐系统,他们为DSSM 模型增加位置通道,利用MLP模型从用户信息、项目信息和位置信息分布中学习用户、对象和位置的隐含表示,结合这三方面信息计算特定位置下用户偏好与新闻内容的关联度,从而产生推荐结果。Lei 等[17]提出一个基于CNN 和MLP模型的图像推荐系统:CNN 模型完成图像特征提取,而MLP 模型则完成用户偏好建模。因此,深度学习模型有力地推动了推荐系统的研究。
2014 年,Goodfellow 等提出生成对抗网络(GAN)[1]。GAN 正逐渐成为学术界研究热点,它在图像生成[18]、图像理解[19]、序列生成[20]等诸多任务中表现优越。最近,研究者们开始将GAN 应用到推荐系统研究中:Wang 等[21]提出IRGAN(information retrieval generative adversarial networks)模型,即把信息检索领域的生成模型和判别模型统一在GAN 框架内,采用策略梯度下降算法优化模型,完成高质量推荐。Cai 等[22]提出基于异构目录网络表示(heterogeneous bibliographic network representation,HBNR)的GAN,有效解决引文推荐。Wang 等[23]运用GAN 完成基于记忆网络的流媒体推荐。
综上,深度学习模型在推荐系统的研究中发挥了重要作用[12-23]。上述基于GAN 的研究工作[21-23]主要聚焦推荐结果对抗学习,而忽略用户偏好挖掘,用户偏好是制约推荐质量的关键因素。因此,本文在IRGAN[21]的基础上,提出高效、鲁棒、性能优秀的UPM-GAN,基于UPM-GAN 构建全新推荐系统。它从两个角度进行用户偏好挖掘,生成能准确拟合用户需求的推荐结果,最终改善用户体验。
3 基于UPM-GAN 的推荐系统
3.1 推荐系统框架
基于UPM-GAN 的推荐系统框架如图1 所示:UPM-GAN 主要包括生成模型和判别模型两部分。基于SVD++算法构造生成模型G,图1 中pu、qi分别表示用户向量和项目向量,bu、bi分别表示用户偏置、项目偏置,它们刻画用户隐含偏好;采用三元组损失算法对数据集执行难分样本挖掘,预先在样本候选池中确立样本类别(图1 中白色圆点为正样本,黑色圆点为负样本);生成模型G从样本候选池中选取负样本并根据样本间的相关概率分布生成伪造正样本给判别模型D;继而,基于矩阵分解(matrix factorization,MF)算法构造判别模型D,它通过向量内积计算候选池中正样本和生成模型G提供的伪正样本的相似性,并基于策略梯度下降算法向生成模型G提供反馈,以优化生成模型G,使其更好地生成伪正样本。高质量的伪造正样本能提高判别模型D的判别能力。G和D两个模型通过对抗学习,不断提高各自性能并达到纳什均衡。最后,基于训练好的生成模型G输出推荐列表。
3.2 UPM-GAN
3.2.1 三元组损失算法
在推荐系统的数据集中,数据分布极不平衡:高分数据占多数,而低分数据相对较少。因为大部分用户倾向于表达积极观点而不愿给出消极评价,故传统推荐系统很难准确捕获用户偏好,设计优良的难分负样本挖掘(hard negative mining)策略是抑制数据分布不平衡,进而准确刻画用户偏好并提高推荐性能的重要手段。提出采用三元组损失算法[2]完成难分负样本挖掘,为构建高质量推荐系统奠定基础。三元组损失算法能实现精确到个体的图像识别,它被广泛用于人脸识别、车辆识别、行人识别等热门领域。算法基本原理:把样本分为Anchor (A)、Negative (N)和Positive (P)三类,任意样本都可作为基点A,通过训练不断“拉近”它与同类样本的距离,而“疏远”与之异类的样本。最终,近距离样本作为正样本P,而远距离样本则作为负样本N。在用户-评分矩阵中,评分范围固定,如从1 分到5 分,但评分模式或标准不同,某些用户给4 分表示非常喜欢,他们几乎不给5 分,而某些用户给4 分则表示一般。故应深入分析评分数据,更好地挖掘用户偏好。三元组损失算法聚焦于确定正样本评分和负样本评分(而非评分绝对大小),正样本评分的确定有助于描述用户偏好,故将三元组损失算法应用到UPM-GAN中:把用户的一个高评分项目作为基点A,经过多轮训练,将与之距离较近的项目作为正样本P,而将与之距离较远的项目作为负样本N。难分负样本被不断送回模型,以提升模型对正样本的识别性能,即以负样本反向激励的方式确立正样本,从而更好地刻画用户偏好。
在用户评分矩阵中,项目特征向量表示为f(x)∈Rd,每个项目i都可映射到d维欧式空间,三元组损失算法使用户基点特征向量f(xa)与正样本特征向量f(xp)更近,而与负样本特征向量f(xn)更远。故它的优化目标如式(1)所示:
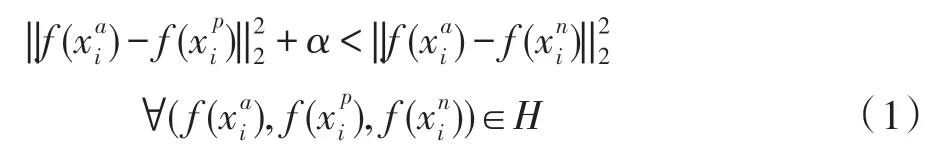
式中,α是一个常量,表示正负样本对训练的边界值。H是与用户有关的所有样本集合,从中选择样本构建三元组,训练模型。最小化式(2)所示的代价函数,完成难分负样本挖掘:
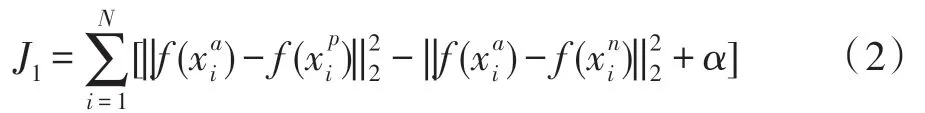
由于采用欧式距离度量向量间距离,故当式(2)中“[]”内的值大于0 时,该值即代价函数损失值。小于0 时,规定损失值为0。
3.2.2 SVD++算法
SVD++[3]基于奇异值分解(singular value decomposition,SVD),相比传统矩阵分解算法,SVD++加入用户偏置信息及隐式参数,以客观描述用户偏好。而用户评分中确实隐含偏好信息:某些评分偏低(或偏高)。故用SVD++算法设计UPM-GAN 的生成模型能更好地挖掘用户偏好,并准确计算预测评分。SVD++算法中预测评分计算如式(3)所示:

式中,bi是项目偏置,它指项目i相对均值μ的偏移量。bu是用户偏置,它指用户u相对均值μ的偏移量。pu、qi分别表示矩阵分解后的用户向量和项目向量。Nu是用户u的评分数据集合,|Nu|表示集合大小;yi是隐式参数,它表示用户u评价过项目i。综上,SVD++算法根据偏置信息、隐式参数等来刻画用户偏好。
SVD++算法的损失函数如式(4)所示:
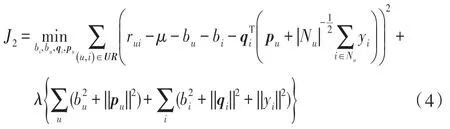
式(4)前半部计算损失值,UR为所有用户向量和项目向量构成的用户评分矩阵,后半部分+为正则化项,以防止算法过拟合,λ是规则化系数。
3.2.3 生成对抗网络
生成对抗网络由生成模型G和判别模型D组成,它们在对抗模式下竞争:D尝试区分真实正样本与G伪造的正样本,而G尝试欺骗D。当对抗相对平衡后,GAN 训练完成。GAN 的代价函数如式(5)所示。其中m为训练集中样本,U表示用户集合,un表示第n个用户,ϕ、θ分别表示判别模型D和生成模型G的参数。
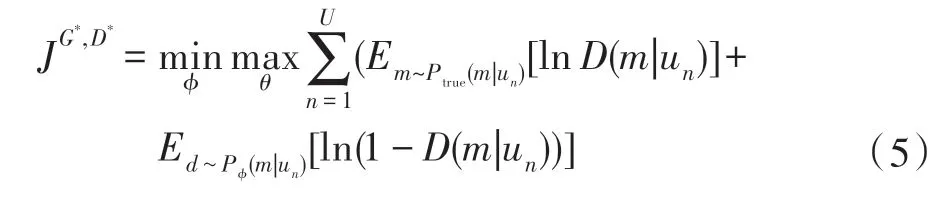
首先,训练判别模型,即最大化正确判别真实正样本与G伪造的正样本的概率,如式(6)所示:
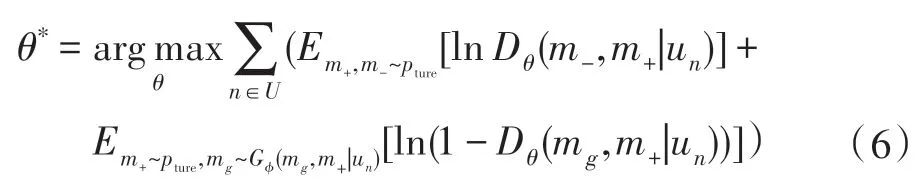
式中,m+、m-分别表示正样本和负样本,mg表示生成模型G伪造的正样本。与判别模型D相反,生成模型G旨在最小化判别模型D的正确判别概率,即欺骗判别模型。如图1 所示:G从样本池中根据相关概率分布(参见式(7),gϕ(u,m)计算样本相似度,t是温度参数)抽取负样本,故生成模型的参数优化如式(8)所示,M表示样本集合。

由于在采样时样本是离散的,故不能直接通过梯度下降法求式(8)的最优解,需采用基于强化学习的策略梯度法进行近似求解,如式(9)所示,其中K是需要判别的样本对列表大小。
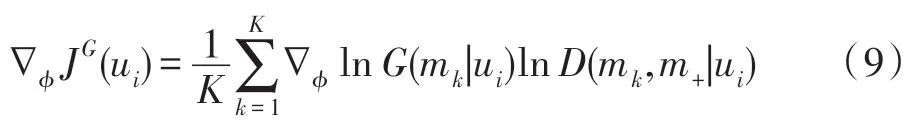
3.3 推荐系统的算法描述
算法1基于UPM-GAN 的推荐系统


4 实验结果与讨论
4.1 数据集
本文采用两个主流数据集MovieLens-100K 和MovieLens-1M 评估UPM-GAN 的有效性。MovieLens(https://movielens.org/)由GroupLens 团队在处理电影评分后得到,它包含用户对电影的评分,每个用户至少评价过20 部电影。数据集的统计信息如表1 所示。实验时将数据集随机分割成两部分,选取80%作为训练集,剩余20%作为测试集。

Table 1 Statistics of MovieLens datasets表1 MovieLens数据集的统计信息
4.2 基线模型
本文的对比基线有四类,具体介绍如下:
(1)最大似然估计(maximum likelihood estimation,MLE)模型[24],即采用最大似然估计方法完成评分预测,它来源于传统机器学习领域。
(2)贝叶斯个性化排序(Bayesian personalized ranking,BPR)[25]模型,它基于矩阵分解(MF)方法分析用户及项目的潜在语义信息,并以逐对排序方式训练推荐系统,完成推荐。
(3)LambdaFM(lambda factorization machine,LambdaFM)模型[26]是基于FM(factorization machine)的排序模型,它将LambdaRank 和FM 混合以提高基于Top-n排序的推荐性能。
(4)信息检索生成对抗网络(IRGAN)[21],它是首个基于生成对抗学习模型的推荐系统。
4.3 实验结果及分析
4.3.1 推荐性能对比
采用基于排名的评价指标衡量模型的Top-n推荐表现[27],包括Precision@K(简写为P@K)、标准化折现累积增益(normalized discounted cumulative gain,NDCG@K)、均值平均精度(mean average precision,MAP)、平均倒数排名(mean reciprocal ranking,MRR)。以上指标越大说明推荐性能越好。实验结果如表2(MovieLens-100K)、表3(MovieLens-1M)所示。表2中倒数第二行、最后一行分别表示在MovieLens-100K 数据集上,UPM-GAN 相对LambdaFM、IRGAN模型的性能提升幅度Improve1和Improve2。表3 与之类似,它采用Improve3、Improve4表示。
由表2 可见:在MovieLens-100K 数据集上,UPMGAN 的推荐性能提升显著,尤其是P@5、P@10、MAP、NDCG@5 等指标,各模型/算法的推荐性能降序排列UPM-GAN>IRGAN>LambdaFM>BPR>MLE。首先,相对于LambdaFM、BPR、MLE 等推荐系统,UPM-GAN 的MAP 指标提升最显著,MAP 是综合类指标,这表明UPM-GAN 的整体推荐性能更优。主要原因:不同于传统推荐系统,UPM-GAN 基于生成对抗学习框架,它的生成模型能产生若干接近真实正样本的伪造正样本,而其判别模型能准确区分真实正样本与伪造正样本,并给生成模型反馈(奖励)。故生成模型与判别模型相互对抗,在提升各自能力的同时不断改善推荐性能。其次,相比IRGAN 这一主流模型,UPM-GAN 的推荐性能也有提升。其中基于准确率的P@K指标整体提升幅度高于基于排序权重的NDCG@K指标。这表明UPM-GAN 在准确率提升上优势明显,而对推荐结果中的位置关注度稍弱。
UPM-GAN 表现优秀的主要原因:(1)基于三元组损失算法处理用户评分数据时,难分负样本以间接方式更好地确立正样本,从而准确描述用户偏好;(2)GAN 的训练过程更有效,它通过生成模型和判别模型之间的对抗学习,不断提升推荐性能;(3)UPMGAN 中的生成模型采用了SVD++算法,SVD++算法中加入了偏置信息、隐式参数等来更好地挖掘用户隐含偏好,进而准确预测评分并改善推荐性能。综上,GAN 框架、三元组损失算法、SVD++算法在推荐中都发挥了重要作用。4.4 节将对UPM-GAN 做模型简化测试,更精准地确定UPM-GAN 中各组成部分的相对重要性。

Table 2 Performance comparisons among different models/algorithms(MovieLens-100K)表2 不同模型/算法的推荐性能比较(MovieLens-100K)
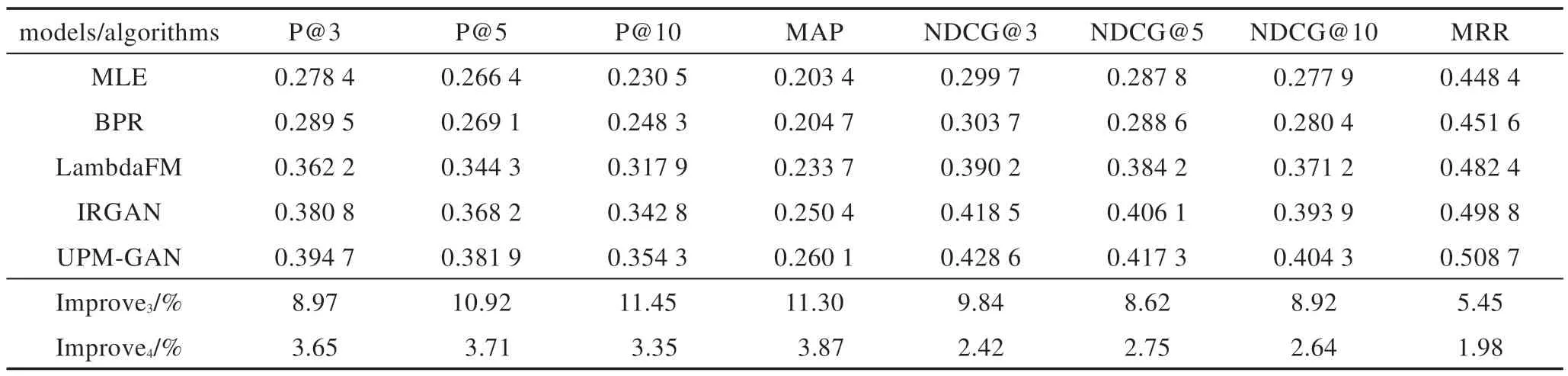
Table 3 Performance comparisons among different models/algorithms(MovieLens-1M)表3 不同模型/算法的推荐性能比较(MovieLens-1M)
表3 实验结果与表2 实验结果相似,即在Movie-Lens-1M 数据集上,UPM-GAN 的推荐性能提升也很显著,尤其是P@5、P@10、MAP、NDCG@5 等指标。各模型推荐性能降序排列UPM-GAN>IRGAN>LambdaFM>BPR>MLE,主要原因同上,不再赘述。表3 结果进一步说明UPM-GAN 具有较强的鲁棒性。此外,在表2 中,UPM-GAN 相对LambdaFM、IRGAN两模型的平均提升幅度分别是10.22%、3.27%。而在表3 中,UPM-GAN 相对LambdaFM、IRGAN 两模型的平均提升幅度分别是9.43%、3.05%。显然,在MovieLens-100K 数据集上,UPM-GAN 的平均提升幅度更大,这主要是由于MovieLens-100K相对Movie-Lens-1M 更稠密(参见表1),而推荐系统在稀疏数据中较难准确捕获用户隐性偏好,故推荐性能的提升幅度不大(对比MLE、BPR 等模型,它们的部分性能指标因为数据稀疏而出现了衰减,即传统推荐系统对数据稀疏更加敏感。相比,UPM-GAN 对数据稀疏的敏感度稍低)。
深入分析不同模型在MovieLens-100K 和Movie-Lens-1M 两个数据集上的推荐性能差异,实验结果如图2 所示。例如,对于MLE 模型,它在MovieLens-100K 和MovieLens-1M 两个数据集上的P@3 指标性能差异是0.336 9-0.278 4=0.058 5。其他差异值同理,故图2 中颜色越深,表示性能差异越大。
由图2 可发现:MLE 和BPR 两模型各类指标的颜色较深,它们在稀疏数据集上出现性能衰减。相反,LambdaFM、IRGAN、UPM-GAN 这三个模型的性能衰减有限。若计算性能衰减均值,LambdaFM 是0.008 7,IRGAN 是0.010 3,UPM-GAN 是0.011 6,UPMGAN 衰减较多,但这并不影响它在表3 中表现最优。需要说明:MRR 指标仅计算结果中第一个正确推荐的样本的位置,它受数据稀疏影响非常大,故各模型的MRR 指标性能衰减都较严重。
综上,数据稀疏一直以来都是推荐系统研究中的难点问题,尤其针对大型数据集(如MovieLens-1M),未来拟引入额外信息(文本、图像等)来进行推荐对象建模,全方位、多角度地刻画待推荐对象,期望可在一定程度上缓解数据稀疏问题。
4.3.2 模型训练过程分析
本小节主要对模型训练过程进行深入分析,以获取一些重要结论。因篇幅问题,仅选取在Movie-Lens-100K 数据集上,IRGAN 模型和UPM-GAN 模型的P@5、NDCG@5 指标(其他指标与它们相似)的训练过程曲线(生成模型)做比较,如图3 所示。Movie-Lens-1M 数据集的结果与之类似。

Fig.2 Performance difference of each model between MovieLens-100K and MovieLens-1M datasets图2 各模型在MovieLens-100K 和MovieLens-1M 上的性能差异
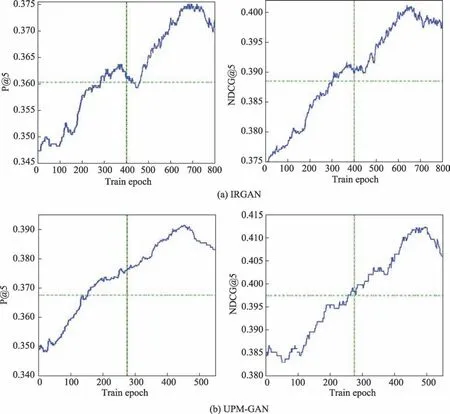
Fig.3 Learning curves of different recommendation systems图3 不同推荐系统的学习曲线
如图3 所示:(1)对于IRGAN,当迭代次数达到650 次左右,IRGAN 的推荐性能达最优,即此时模型趋于收敛。继续增加迭代次数,推荐性能出现小幅衰减。对于UPM-GAN,当迭代次数达到500 次左右,UPM-GAN 的推荐性能达最优,即此时模型趋于收敛。显然,UPM-GAN 比IRGAN 获取了更快的收敛速度,这一优势在训练大型数据集时将更显著。主要原因:在UPM-GAN 中,三元组损失算法为判别模型挖掘了高质量的负样本,进而更好地确立正样本并加速模型训练速度。相反,IRGAN 采用随机方式选取负样本进行训练,样本质量整体较差。
(2)在图3 中,IRGAN 的最优性能分别是P@5=0.375 0,NDCG@5=0.400 9,而UPM-GAN 的最优性能分别是P@5=0.390 7,NDCG@5=0.412 3。UPMGAN 推荐性能更优,这与表2、表3 结论吻合。主要原因:三元组损失算法识别的高质量负样本并确立了正样本,促使判别模型能更好地辨别真实正样本和伪造正样本,UPM-GAN 判别模型的能力不断提升,而由于基于GAN 框架,判别模型能力的改善会促使UPM-GAN 的生成模型的性能不断提升。最终,它们在对抗学习之下不断提高系统推荐性能。显然,GAN 框架是UPM-GAN 的核心组成部分,参见4.4 节分析。
(3)UPM-GAN 的训练过程曲线较IRGAN 更平滑,即迂回曲折、突变、毛刺等现象更少,故模型训练过程更平稳,未出现大幅度“颠簸”现象。这也是由于三元组损失算法在UPM-GAN 中发挥重要作用,故结合(1)的实验结果可推测:三元组损失算法对于高质量推荐也非常重要。参见4.4 节分析。
由于UPM-GAN 收敛速度快,训练代价大大降低。因此,UPM-GAN模型不但推荐性能优越,且模型实时运行效率也非常不错,推荐系统的实用价值更高。
参数的调制,主要包括GAN 框架的t及三元组损失算法的α。图4 是在MovieLens-100K 数据集上,UPM-GAN 中t参数的动态调整过程,选取P@5 和NDCG@5 这两项指标进行展示。与之对应,图5 是在MovieLens-100K 数据集上,UPM-GAN 中α参数的调整过程,同样选取P@5 和NDCG@5 这两项指标进行展示。
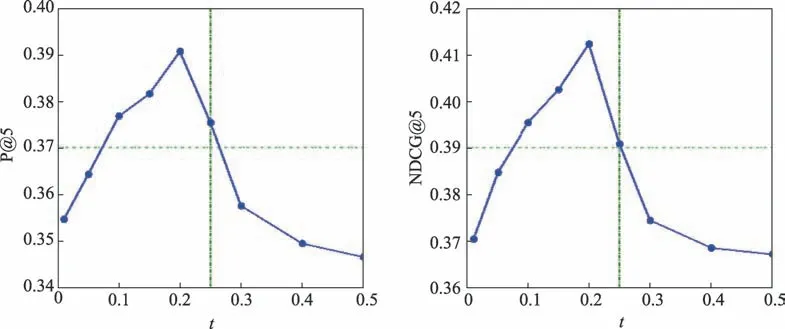
Fig.4 Performance variations of P@5 and NDCG@5 with respect to t图4 P@5 和NDCG@5 性能指标伴随t值的变化
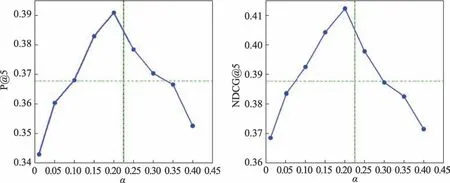
Fig.5 Performance variations of P@5 and NDCG@5 with respect to α图5 P@5 和NDCG@5 性能指标伴随α值的变化
在图4 中,由生成模型t参数的动态调整过程可知:P@5 和NDCG@5 这两类指标的变化趋势非常相似。当t>0 时,UPM-GAN 的推荐性能逐渐上升,直到t=0.2 时,推荐性能最优。之后,伴随t值增加,推荐性能出现衰减。这表明:在UPM-GAN 中,生成模型需根据用户和项目的相关概率分布,选取合适的敏感度参数t,完成最佳推荐。
在图5 中,由三元组损失算法α参数的动态调整过程可知:P@5 和NDCG@5 这两类指标的变化趋势也非常相似。当α>0 时,UPM-GAN 的推荐性能逐渐提升,直到α=0.20,三元组损失算法可获取最合理的样本分布,进而促使推荐系统性能最优。
4.4 模型简化测试
如图1 所示,基于UPM-GAN 的推荐系统包含三大核心部分:GAN 框架、基于三元组损失算法的难分负样本挖掘和SVD++算法。为明确各部分在推荐中的作用,本节对UPM-GAN进行模型简化测试(ablation analysis),这也为未来优化模型指明方向。选取表2、表3 中的UPM-GAN 作为Baseline 进行模型简化测试,得到如表4、表5 所示实验结果。“No_GAN”表示推荐系统未使用GAN 框架,它被简化为次优模型LambdaFM,该简化测试的目的是评价GAN 框架的重要性。“No_SVD++”表示基于GAN 的推荐系统未使用SVD++算法作为生成模型G,该简化测试的目的是评价SVD++算法的重要性。“No_TripletLoss”表示基于GAN 和SVD++算法的推荐系统未使用三元组损失算法完成难分负样本挖掘,该简化测试的目的是评价Triplet Loss算法的作用。
如表4、表5 所示:在UPM-GAN 中,GAN 框架最重要,即强有力的对抗学习使得生成模型、判别模型的能力都不断增强,从而大幅改善推荐性能;其次是三元组损失算法,难分负样本被不断筛选出,进而提升模型对正样本的识别精度;SVD++算法相对重要性最低。当然,UPM-GAN 中的难分负样本挖掘还有改进空间,如引入文本、图像等额外信息进行基于内容的难分负样本挖掘。另外,可引入DeepFM[28]来改进UPM-GAN 的生成模型,更好地挖掘用户隐性偏好。

Table 4 Ablation analysis on MovieLens-100K dataset表4 在MovieLens-100K 数据集上的模型简化测试结果

Table 5 Ablation analysis on MovieLens-1M dataset表5 在MovieLens-1M 数据集上的模型简化测试结果
5 结论与展望
用户偏好挖掘是制约推荐性能的关键因素。提出全新的基于UPM-GAN 的推荐系统,从两个角度深入分析用户偏好:基于三元组损失算法完成难分负样本挖掘,即以负样本反向激励的方式确立正样本,从而更好地刻画用户偏好;设计基于SVD++算法的生成模型,加入隐式参数、偏置信息等更准确地描述用户潜在偏好。在GAN 框架上训练出高效、鲁棒的推荐系统。实验表明:UPM-GAN 不但推荐性能优秀,且其收敛速度更快,模型训练过程更平稳,故基于UPM-GAN 的推荐系统的实用价值较高。
未来研究方向:(1)引入文本、图像等额外信息进行基于内容的难分负样本挖掘,更好地确立正样本;(2)设计基于DeepFM[28]的生成模型,更好地挖掘用户隐性偏好;(3)加入文本、图像、知识图谱[29-30]等辅助信息进行高质量的对象建模,进一步缓解推荐时的数据稀疏问题。
