关于主动学习下的知识图谱补全研究*
2020-05-13陈钦况寿黎但
陈钦况,陈 珂,2+,伍 赛,2,寿黎但,2,陈 刚,2
1.浙江大学 计算机科学与技术学院,杭州 310027
2.浙江省大数据智能计算重点实验室(浙江大学),杭州 310027
1 引言
随着信息科技的突破,新一代人工智能迎来了史无前例的发展热潮。知识图谱作为人工智能的基础支撑,例如支撑轨道交通运维优化、系统设计等,目前也得到了许多学者和研究人员的关注。
知识图谱是一种信息网络,它包含真实世界中存在的物品、人物、地点等信息。知识图谱一般用三元组集合来表示,用RDF(resource description framework)或者图数据库来存储三元组。知识图谱目前已经被广泛应用在搜索、推荐、问答领域,知识图谱逐渐成为人工智能领域不可或缺的一部分。学术界对知识图谱的研究从未间断过,随着人工智能的热潮来临,研究知识图谱变得越来越重要。
常见的公开的知识图谱有Freebase、DBPedia、ConceptNet 等。然而这些知识图谱都有不同程度的缺失。这些知识图谱的缺失主要体现在实体与实体之间缺失本应该有关系的边。知识图谱补全任务(knowledge graph completion)是致力于通过预测知识图谱中潜在的关系,从而提高知识图谱的完整性和可靠性。许多学者对知识图谱补全任务进行了许多探索和研究,其中包括:(1)路径排序算法(path ranking algorithm,PRA)[1-5];(2)词嵌入技术[6-12];(3)神经网络方法[13-18]。这些方法一般将知识图谱补全任务看作是分类问题,比如路径排序算法(PRA)的改进——子图特征提取算法(sub-graph feature extraction,SFE)[2]通过判断不在知识图谱中的三元组是否成立,来实现知识图谱缺失补全。
然而这些方法存在以下两个问题:(1)这些方法都关注于算法准确率,使用的测试集一般由人工规则进行构建,如果将这些方法应用到真实的知识图谱上,需要对所有的候选目标进行分类任务,导致庞大的时间开销。(2)这些方法都只着眼于知识图谱内部数据的缺失补全,没有考虑到采用知识图谱外部数据进行缺失补全,导致利用的信息不充分。这些方法在缺失补全上有这么两点局限,因此本文提出一种基于主动学习的知识图谱补全框架,这个框架由三部分构成:不断更新的知识图谱、链接预测器、关系验证器。其中链接预测器预测知识图谱中最有可能产生链接的k对实体对,关系验证器推理验证实体对之间的关系,形成新的三元组完善知识图谱。
本文的主要贡献可以概括如下:
(1)提出了一种采用主动学习,使用知识图谱内部和外部关系验证,从而不断完善知识图谱的框架。这个框架结合了主动学习,能够不断完善知识图谱。
(2)在链接预测阶段,提出了增强链接预测算法(enhance link prediction,ELP)来预测知识图谱中最有可能形成链接的实体对。ELP 算法结合了Rooted PageRank 算法和实体聚类算法,能够有效挖掘知识图谱中的图结构信息和语义信息。利用ELP 算法能够实现主动学习,从而不断完善知识图谱。
(3)在关系验证阶段,提出一种采用基础验证加增强验证的方法验证关系。实验表明,这种方法能够有效利用知识图谱内部数据和互联网数据进行关系验证。
2 相关工作
本文的相关工作主要涉及链接预测任务、知识图谱补全任务、知识库问答系统、实体抽取、关系抽取等领域。
在知识图谱补全领域已经有许多学者做出了丰富的研究,Lao 等人[1]提出路径排序算法(PRA),PRA通过计算知识图谱中节点间的特征矩阵来实现知识图谱中的链接预测。PRA 算法主要分成两步:(1)使用统计模型来寻找两个节点间的潜在路径。(2)计算任意两个节点间的随机游走概率。Gardner 等人[2]在PRA 的基础上提出了子图特征提取算法(SFE)。SFE 将知识图谱补全任务看作是二分类问题,通过判断三元组是否成立来实现知识图谱缺失补全。SFE 算法主要分成两步:(1)提取两个节点的一系列特征。(2)采用二分类分类器对第一步提取的特征做二分类判别。
Bordes 等人[6]提出了词嵌入模型TransE。TransE模型将实体和关系映射到低维空间中的向量,通过计算向量间距离h′+r′-t′来实现知识图谱缺失补全。Wang 等人[7]在TransE 模型的基础上提出了TransH 模型,TransH 模型将实体映射到关系向量的超平面中,增强向量解释能力。
Neelakantan 等人[14]提出了Path-RNN 模型来推理两个节点间的关系。Path-RNN 将两个节点路径之间的实体输入到循环神经网络(recurrent neural network,RNN)中,来实现实体间的关系推理。Das 等人[15]在Path-RNN 的基础上提出Single Model,Single Model不仅考虑了节点间路径上的实体,还考虑了路径上的关系,增强了神经网络的表达能力。
在社交网络领域,许多学者和研究人员对链接预测问题进行了许多研究[19-21]。链接预测问题主要是从图中筛选出最有可能形成链接的k对节点对。解决链接预测问题的方法主要有三类:(1)局部方法;(2)基于路径的方法;(3)随机游走方法。其中局部方法有公共邻居方法、Jaccard 系数等,主要的流程是计算节点对之间的相邻的节点来实现相似度的计算。基于路径的方法有最短路径、Katz 距离等,主要的流程是计算节点对之间的路径信息来实现相似度的计算。随机游走的方法有Rooted PageRank 等,主要的流程是通过图中节点的随机游走来实现相似度计算。
主动学习[22]是一种机器学习技术,从数据中选择出具有代表性或者能够有利于学习模型快速学习的样本。主动学习解决的问题包含已标注的数据和未标注的数据,主动学习采用算法策略从未标注的数据中选择一部分最有利于学习模型学习的数据,交由专家系统进行标注,标注后的数据用于学习更好的模型。
知识库问答系统(knowledge base question answering,KBQA)[23-24]是给定自然语言问题,通过对自然语言问题的语义分析,利用知识库进行语义查询、关系推理得到答案。KBQA 主要分以下几个模块:问题分析、短语映射、消歧、查询构建等。KBQA 主要的应用体现在智能问答上,同时也广泛应用于搜索、推荐等领域。
还有许多学者对开放世界假设下的知识图谱补全问题进行了深入的研究[25]。开放世界假设指知识图谱中的关系代表现实世界中正确的关系,知识图谱中未知的关系可能代表现实世界中错误的关系,也可能代表现实世界中存在的关系。开放世界假设对应的是封闭世界假设,封闭世界假设是指知识图谱中未知的关系代表现实世界错误的关系。一般知识图谱比较完善的时候,或者是知识图谱不完全,但是由于需要通过知识图谱对现实世界的问题做出回答时采用封闭世界假设。
3 知识图谱补全方法框架
本文对知识图谱作如下定义:知识图谱由三元组集合O={(h,r,t)}构成。每个三元组都有两个实体h,t∈E 和关系r∈R,其中E 是实体集合,R 是关系集合。定义,ei∈E,ej∈E 是知识图谱中的实体对。知识图谱补全框架的主要流程如图1 所示,知识图谱补全框架主要分为链接预测和关系验证两个模块。链接预测模块主要是从知识图谱中筛选出最有可能形成链接的k对实体对。关系验证模块验证链接预测输出的实体对之间的关系,形成正确的三元组。形成正确的三元组会返回知识图谱进行不断更新迭代。整个知识图谱补全框架包含了主动学习的思想,链接预测模块从未标注数据中选择代表性的数据,交由关系验证模块进行专家验证。
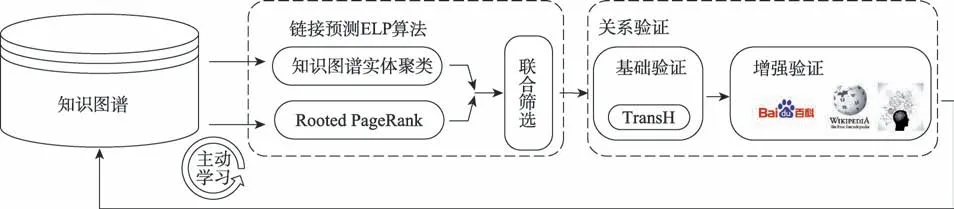
Fig.1 Flowsheet of knowledge graph completion图1 知识图谱补全流程图
链接预测模块主要实现筛选知识图谱中最有可能形成链接的k对节点对。链接预测模块以知识图谱的三元组作为输入,采用ELP 算法,寻找并筛选整个知识图谱中最有可能形成链接的k对实体对。ELP 算法采用实体聚类算法来挖掘知识图谱中的语义信息,采用Rooted PageRank 算法来挖掘知识图谱中的图结构信息,经过联合筛选来挖掘知识图谱中最有可能形成链接的k对实体对。链接预测模块输出实体对,由关系验证模块进行进一步的关系确认。关系验证形成的正确的三元组能够返回链接预测模块进行进一步的学习,使得链接预测模块能够更好地预测知识图谱中能够形成链接的实体对。
关系验证模块主要实现对实体对之间的关系的验证。关系验证模块由基础验证和增强验证两部分构成。基础验证采用TransH[7]算法,以知识图谱内部的数据作为训练集,对链接预测模块产生的实体对进行分类任务确定实体对间的关系。增强验证模块通过爬取、清洗互联网结构化数据,采用多源数据关系验证和领域专家的人机交互方式来实现对基础验证输出的三元组集合的进一步验证。关系验证模块输出正确的三元组,输出的三元组返回知识图谱补全完善知识图谱。正确的三元组还会返回链接预测模块,增强链接预测模块的链接预测效果。
4 链接预测
链接预测模块主要的任务是从知识图谱中筛选出前k对最有可能形成链接的实体对。本章提出了增强链接预测算法(ELP),ELP 算法结合了Rooted PageRank 算法和实体聚类算法进行联合筛选,使得筛选出的候选实体对更有可能形成链接。Rooted PageRank 算法能够挖掘知识图谱中的图结构信息,筛选可能形成链接的实体对。而实体聚类算法能够挖掘知识图谱中的语义信息,排除不可能形成链接的实体对。ELP 中算法中的Rooted PageRank算法和实体聚类算法是相对独立的两个子模块,通过该两个模块的联合筛选,能够筛选出知识图谱中最有可能形成链接的实体对。由于ELP 算法结合了知识图谱中的语义信息和图结构信息,因此ELP 算法信息挖掘能力更强,能够通过主动学习增强链接预测的性能。将在实验中证明本章提出的ELP 算法效果优于Rooted PageRank 算法,并且具有主动学习能力。本文分知识图谱实体聚类和Rooted PageRank算法两部分来介绍ELP 算法。
4.1 实体聚类算法
本节提出一种知识图谱实体聚类算法来挖掘知识图谱中的语义信息。在知识图谱中,节点和边分别代表实体和关系,节点和边都是有各自的语义的。本节提出的实体聚类方法能够快速筛选出知识图谱中的实体类。筛选出的实体类可以用于ELP 算法的联合筛选。它主要分成两个阶段:(1)实体类的初始化;(2)实体类的合并。
定义知识图谱可以看作是有向图G,其中实体类E 是有向图G 的节点,三元组o=∈O 可以看成是有向图G 中从节点h出发到节点t的一条有向边。定义H={H1,H2,…,H2m}代表头节点类集合,T={T1,T2,…,T2m}代表尾节点类集合。
对于关系ri∈R,有三元组集合Oi={(hij,ri,tij)}⊆O,其中hij∈Hi,tij∈Ti。如图2 所示,头节点类Hi中的实体hij都有一定的相似性,比如关系-Nationality-对应的头实体类一般都是人。尾实体类Ti中的实体tij也有一定的相似性,比如关系-Gender-对应的尾实体类一般都是性别。图2 中的{e1,e2}、{e2,e3}、{e4,e5}、{e6,e7}分别构成4 个实体类{H1,H2,T1,T2}。
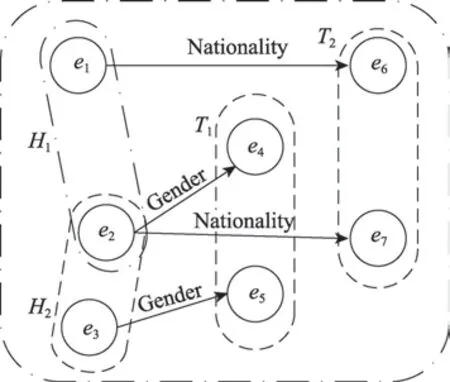
Fig.2 Entity class initialization diagram图2 实体类初始化示意图
实体类的初始化过程需要遍历关系集合R,对于每个关系ri∈R,记录对应的头实体类Hi和尾实体类Ti。最后得到了2m个初始实体类,该实体类集合记为S={H1,H2,…,H2m,T1,T2,…,T2m} 。值得注意的是,由于知识图谱包含一些错误数据,以及一些关系的头实体类和尾实体类有一定的重复,因此对于任意的实体e∈E,可能属于一个或者多个实体类。初始化实体类的流程如下:
算法1初始化实体类

实体聚类算法的第二个阶段是合并初始实体类。经过上一步提取的实体类存在很多错误,这些错误主要体现在以下几个方面:(1)知识图谱中可能有些边是错误的,比如大规模的多语言百科知识图谱DBpedia 有大约10%的错误率。知识图谱中错误的三元组可能会导致一些实体类包含少量本不属于该集合的实体。(2)一些集合之间可能存在大量重复的实体。比如关系-Gender-和关系-Nationality-对应的头实体类高度相似,这两个实体类之间存在大量相似的实体。由于实体类初始化提取的实体类存在以上的问题,因此需要对上一步提取的实体类做进一步的处理。实体类的合并过程如图3 所示,当发现{e1,e2}、{e2,e3}两个实体类较为相似,这两个实体类需要被合并,合并完后剩余的实体类有{e1,e2,e3}、{e4,e5}、{e6,e7}三个实体类,记为{H1,T1,T2}。
对于实体类si,sj∈S,count(si)、count(sj)分别代表实体类si和sj中的实体数量。定义两个集合的相似度:

任意两个相似度超过阈值τ的实体类需要进行合并,不断迭代直到没有两个实体类相似度超过阈值τ。
由于实体类过程中的每次迭代需要计算两两实体类间的相似度,当实体类较多时候,每次迭代需要较大的时间开销,因此采用贪心策略来加速实体类的合并。实体类的合并算法如下:
(1)随机选取一个集合,计算其他集合与当前集合的相似度。
(2)选取一个与当前集合相似度最大的集合,如果相似度超过阈值τ,则将这两个集合进行合并,并将新的集合作为当前集合;如果没有超过阈值τ,则将当前集合标记为终态,以后不参与集合合并。
(3)重复前两步直到所有集合都为终态。
算法2实体类的合并

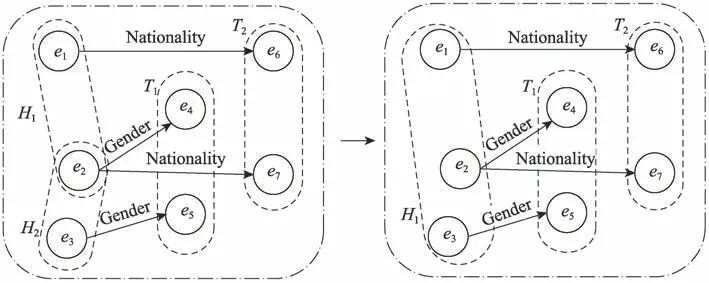
Fig.3 Diagram of entity class consolidation process图3 实体类合并过程示意图

4.2 Rooted PageRank 算法
Rooted PageRank 算法[19-20]将知识图谱看作是无向图G,其中实体E 是无向图G的节点,三元组o=∈O 可以看成是无向图G中从节点h出发到节点t的一条无向边。介绍Rooted PageRank 算法之前,本节先介绍随机游走算法(Random Walks)。对于任意节点x∈E,随机游走算法以等概率游走到和节点x相邻的节点。定义命中时间Hx,y:从节点x,随机游走到节点y的期望步长,其中x,y∈E 。那么往返时间Cx,y定义如下:

Rooted PageRank 算法在随机游走算法的基础上引入了重启机制,对于图G中的任意节点x,每次随机游走的时候,以α的概率重新回到节点x,以1-α的概率游走到与节点x相邻的节点。本文定义score(x,y)代表从节点x随机游走到y的稳定概率。选择score较高的k个实体对作为知识图谱中最有可能形成链接的实体对。相应的图计算核方法是(1-α)(I-αD-1A)-1,其中D代表度矩阵,A代表邻接矩阵。
4.3 ELP 算法
前文所介绍的Rooted PageRank 算法能够通过知识图谱的图结构,从知识图谱中发现最有可能形成链接的k对实体对。而实体聚类算法则是挖掘知识图谱中的语义信息对知识图谱中的实体进行聚类。本节将提出ELP 算法,联合Rooted PageRank算法和实体聚类算法对实体对进行筛选。
在实体聚类算法对知识图谱中的实体进行聚类后,对于任意两个实体类Si,Sj∈S,定义三元组集合Oz={(hik,rz,tjk)}⊆O 并且满足hik∈Si,tjk∈Sj。定义实体类之间的置信度如下:
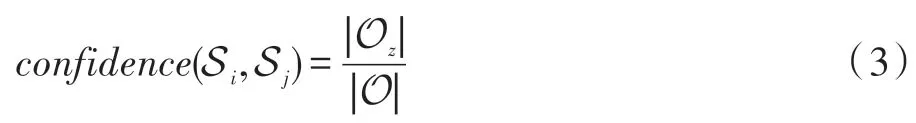
如果两个实体类之间的置信度大于阈值β,则任意两个实体ei和ej都属于筛选出的实体候选对。因此,对于实体对,ei∈Si,ej∈Sj,有如下关系:
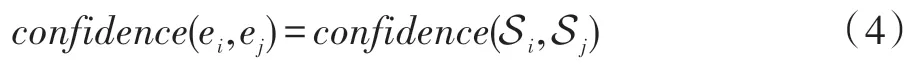
ELP 算法采用Rooted PageRank 算法和实体聚类算法联合筛选进行链接预测。既考虑了知识图谱中的图结构信息,又考虑了知识图谱的语义信息。通过ELP 算法筛选出的最有可能形成链接的k对实体对更具有代表性,可获得优于Rooted PageRank 算法的效果。
另外,ELP 算法具有主动学习能力。对于链接预测问题,将整个知识图谱看作是数据集Ud,所有在知识图谱中有链接的数据看作是训练集Us,所有不在知识图谱中的链接看作是测试集Ut。ELP 算法每次从测试集Ut选出一定数量的样本,通过关系验证模块组合成正确的三元组加入训练集Us,组成新的训练集Us′和新的测试集Ut′。在实验环节,验证了对于新的训练集Us′,ELP 算法的链接预测效果比原训练集Us要好。这说明ELP 算法具有主动学习能力,对于更完善的数据集,ELP 算法有更强的潜在信息挖掘能力。
5 关系验证
关系验证模块验证链接预测输出的实体对的关系。对于链接预测输出的任一实体对,关系验证模块需要找到对应正确的三元组,如果不存在关系,则有r=NULL。本章采用基础验证和增强验证两个模块解决关系验证问题。在基础验证模块中,将关系验证问题看作是关系分类问题,采用TransH 算法对链接预测模块输出的实体对进行分类任务。在增强验证模块,通过爬虫技术爬取互联网上结构化数据信息,采用多源数据关系验证和领域专家人机交互方式来实现增强验证。
5.1 基础验证
在基础验证模块,本节只利用知识图谱内部的数据,将关系验证看作是分类问题。对于任一实体对,需要对所有r∈R 做二分类判别。即是对于所有的r∈R,判断三元组是否成立。关系验证也可以看成是多分类任务,即对于实体对,分类选择出正确的关系r,形成正确的三元组。
Bordes 等人[6]提出词嵌入模型TransE,TransE 模型将知识图谱中的实体和关系都用数学空间的向量来表示。因此,对于三元组,可以通过计算头实体h和尾实体t的向量距离来实现关系验证。图4展现了三元组在数学空间中的关系。
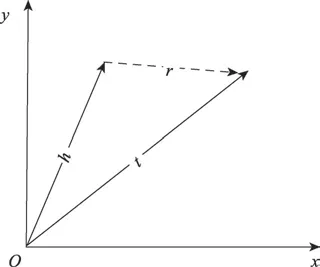
Fig.4 Math space of TransE图4 TransE 模型数学空间
对于知识图谱中的三元组O={(h,r,t)},其中h,t∈E,r∈R,TransE 模型将实体和关系映射到数学空间Rk中,其中k是模型的超参数。定义知识图谱中的正确的三元组集合为S(h,r,t),错误的三元组集合为S′(h′,r,t′),其中S′(h′,r,t′)可以随机替换知识图谱中正确的三元组的头实体和尾实体来得到。有如下等式:
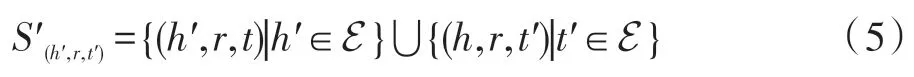
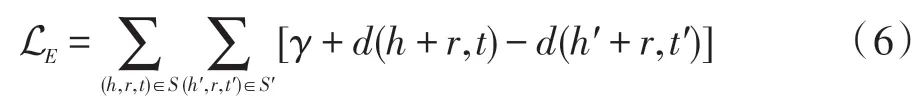
其中,γ是超参数。实体向量和关系向量可以通过训练目标函数L来得到。
Wang等人[7]在TransE模型的基础上提出了TransH模型,TransH 模型在TransE 模型的基础上把实体向量和关系向量映射到超平面空间wr。图5 展现了TransH 模型中的三元组在数学空间中的关系。TransH 模型的距离函数和目标函数如下定义:
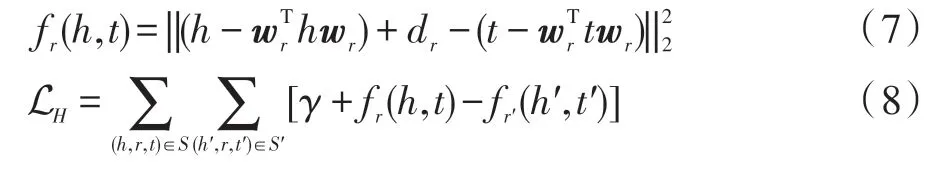

Fig.5 Math space of TransH图5 TransH 模型数学空间
模型训练开始时,一般用随机值来初始化实体向量和关系向量。在训练过程中,为了节省计算资源以及加快训练速度,研究人员往往采用随机梯度下降方法SGD(stochastic gradient descent)来实现模型的训练,采用L2正则化方法来避免模型对训练数据的过拟合。
5.2 增强验证
通过基础验证后的三元组仍存在许多错误,造成这些错误的原因主要是基础验证只利用了知识图谱内部的数据信息,然而现实世界中大多数知识图谱包含的知识信息较为有限。随着互联网的进一步发展,诸如百度百科、互动百科、维基百科等包含了大量的知识信息。因此,本文提出利用外部数据进行增强验证,增强验证模块包括三部分:(1)多源数据的采集与清洗;(2)多源数据的关系验证;(3)领域专家的人机交互验证。
定义多源数据S={S1,S2,…,Sn}表示不同数据源的数据,数据仓库KB={KB1,KB2,…,KBn}表示多源数据S经过爬虫技术采集、数据清洗、数据格式规范化后的数据。对于任意数据仓库KBi都符合以下形式:

其中,Ei={ei1,ei2,…,eim}代表数据仓库KBi中的实体集合,Ri={ri1,ri2,…,rim}代表数据仓库KBi中的关系集合,Oi代表数据仓库KBi中的三元组集合。增强验证模块如图6。
数据采集部分采用网络爬虫技术对互联网上的网站进行数据爬取。许多网站针对开发者开放了API接口与Dump 文件等。互联网上的数据如图7 所示,一般由文本数据和结构化Infobox 数据构成。增强验证模块主要采用互联网的结构化数据进行关系验证。

Fig.6 Flowsheet of enhanced verification图6 增强验证流程图
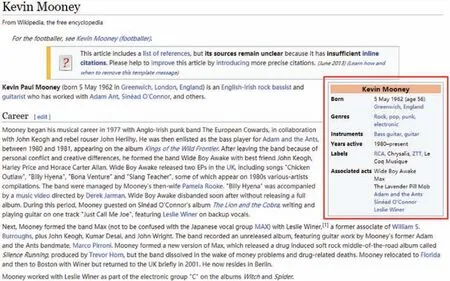
Fig.7 Diagram of Wiki Web page图7 Wiki网页数据示意图
爬取后的数据需要进行数据清洗和格式规范化,包含以下几点:(1)剔除无关字符。(2)关系统一化。在不同数据源中,关系描述可能不一致,因此需要将同一关系的不同描述统一化。(3)实体消歧与统一化。在不同数据源中,实体的描述可能并不一致,可能出现缩写名等,因此需要对实体进行统一化。经过清洗与规范化后的数据会存入数据仓库中,进行多源数据关系验证。
多源数据关系验证以基础验证输出的三元组集合Op、知识图谱G和数据仓库KB为输入,输出置信度集合Cp。对于任意三元组o=∈Op,与数据仓库KBi进行数据对齐需要考虑如下两点:(1)实体h在知识图谱G中描述的实体和在数据仓库KBi中描述的实体是不是同一个实体。(2)数据仓库KBi是否存在三元组o=。

式(10)描述了三元组关系o与数据仓库KBi之间的对应关系。
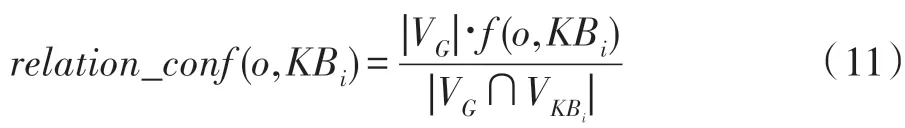
式(11)描述了三元组o与数据仓库KBi之间置信度。其中VG表示知识图谱G中包含实体h的三元组集合,VKBi表示在数据仓库KBi中包含实体h的三元组集合。因此对于三元组o,总的置信度有如下公式:

多源数据关系验证输出三元组集合和置信度,经过领域专家人机交互验证后可以输出正确的三元组集合。对于置信度较低的三元组,领域专家依靠自身的专业知识来决定三元组是否正确。领域专家人机交互验证的形式化定义如下:
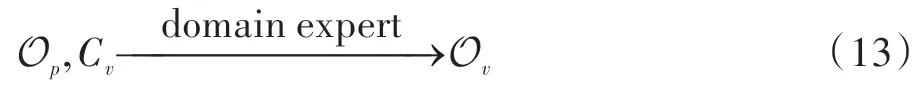
本节提出的增强验证包含多源数据采集与清洗、多源关系验证、领域专家人机交互验证三部分。增强验证模块能够有效地验证基础验证输出的三元组集合,形成更加正确的三元组集合。
6 实验结果
本文的实验环境是在一台小型服务器上运行,处理器为Intel®Xeon®Silver 4114 CPU@2.2 GHz,内存为100 GB,操作系统为Ubuntu 18.04.1 LTS Server。使用的语言为Java 和Python,Python 主要用于链接预测模块筛选实体对,Java 主要用于关系验证模块验证实体对的关系。
实验数据方面,本文采用公开数据集Freebase 和DBpedia。Freebase 数据集和DBpedia 是在知识图谱领域常用的数据集,被许多科研学者采用。由于Freebase 数据集和DBpea 数据集非常庞大,为了方便起见,本文对Freebase 数据pedia 数据集进行了采样,选取了一定数量的实体、关系作为实验的真值数据集。真值数据集如表1 所示。

Table 1 Truth dataset表1 真值数据集
从真值数据集随机采样55%、60%、65%、70%、75%、80%、85%、85%、90%、95%的三元组,构成本文的缺失知识图谱。剩余的三元组作为需要补全完善的缺失值。
6.1 链接预测实验结果
在链接预测模块中,测试了Rooted PageRank(RPR)算法和ELP 算法筛选缺失的知识图谱中最有可能形成链接的前1 000 和前2 000 对实体对,并将筛选出的实体对和真值数据集进行比较,计算出正确预测的实体对百分比。筛选前1 000 对实体对和前2 000 对实体对的结果如表2 所示。图8 和图9 表现了在DBpedia 数据集上和Freebase 数据集上的实验对比。
从图8 和图9 中分析发现在DBpedia 和Freebase两个数据集上,ELP 算法效果均好于RPR 算法。对于前2 000 对实体对,应用了CommonNeighbours、Katz、SimRank 算法[19]进行对比测试。实验结果如表3 所示。可以看到在DBpedia 和Freebase 数据集上,ELP 算法效果均优于其他算法。这两个实验证明了本文提出的ELP 算法的有效性,说明本文算法相较于其他算法而言,能较为准确地筛选知识图谱中最有可能形成链接的前k对实体对。
ELP 算法不仅能够很好地进行链接预测,还具有主动学习能力,随着知识图谱的不断完善,ELP 算法能够更好地预测知识图谱中需要进行链接的实体对。然而由于知识图谱越来越完善的同时,需要补全的正确三元组越来越少,用前k对实体对中正确的实体对百分比来评价链接预测的主动学习能力并不公平。定义了如下函数来评价在知识图谱更新过程中算法的链接预测能力。
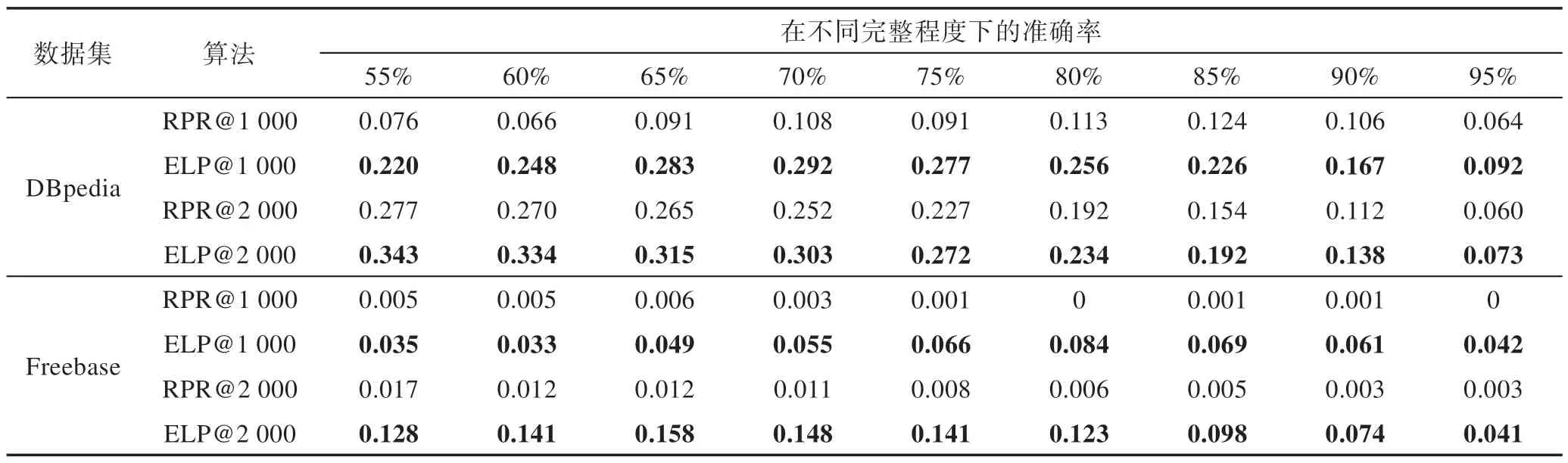
Table 2 Accuracy comparison of RPR and ELP表2 RPR 与ELP 准确率对比
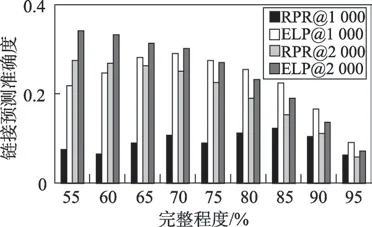
Fig.8 Experiment comparison between RPR and ELP in DBpedia图8 DBpedia 数据集RPR 与ELP 实验对比
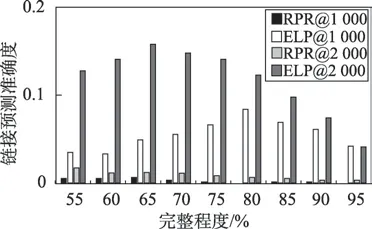
Fig.9 Experiment comparison between RPR and ELP in Freebase图9 Freebase数据集RPR 与ELP 实验对比

Table 3 Accuracy comparison of ELP algorithm and others@2 000表3 ELP 算法与其他算法准确率对比结果@2 000

其中,Dt表示当前知识图谱剩余还未补全的正确实体对总数,hit代表链接预测器筛选出的前k对实体对中正确的实体对个数。相比较于前k对实体对中正确实体对的百分比,Yscore考虑了知识图谱中剩余还未补全的实体对总数,能较好地评价算法的主动学习的能力。本文在DBpedia 数据集和Freebase 数据集上测试了各个算法的实验结果,如表4 所示。通过图10 和图11 可以看出,随着知识图谱的不断完善,Yscore结果变得越来越高。这说明了随着知识图谱的不断完善,ELP 算法的链接预测能力越来越强。因此,ELP 算法具有主动学习能力。
以上的实验以及分析验证了如下两点:(1)本文提出的ELP 算法能够挖掘知识图谱中的图结构信息和语义信息,效果好于Rooted PageRank 算法。(2)本文提出的ELP 算法具有主动学习能力,随着知识图谱的完善程度越高,ELP 算法的信息挖掘能力越强。
6.2 关系验证实验结果
关系验证模块采用TransH 模型对链接预测模块输出的候选实体对进行关系验证。首先对ELP 算法链接预测得到的前k对实体对进行关系扩展,对于链接预测输出中的正确的实体对,需要扩展正确的关系;对于链接预测输出中的错误的实体对,则随机扩展知识图谱中的任一关系。
对于链接预测模块输出的前1 000 对实体对和前2 000 对实体对,基础验证模块采用TransH 模型进行二分类。基础验证模块将预测的结果和真值数据集进行比较,并计算F1值。F1值的计算方式如下:

其中,P代表精确率,R代表召回率。F1指标能较好地衡量二分类分类器的性能。关系验证的结果如表5 所示。

Table 4 Yscore results of active learning in link prediction module表4 链接预测模块主动学习Yscore 结果

Fig.10 Yscore results of ELP algorithm in DBpedia图10 DBpedia 数据集ELP 算法Yscore 结果
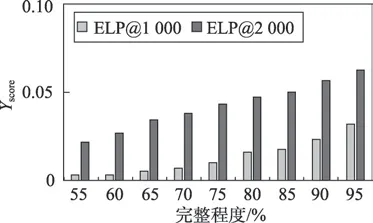
Fig.11 Yscore results of ELP algorithm in Freebase图11 Freebase数据集ELP 算法Yscore 结果图

Table 5 F1 results of relationship verification表5 关系验证F1 指标实验结果
表5 证明了基础验证模块能够较好地验证链接预测输出的实体对之间的关系,基础验证模块的F1指标都集中在0.5~0.8 之间。
爬取Freebase 有关的实体75 043 个,以及它们有关联的三元组集合。然后以0.25 的概率采样其中的三元组集合,构建了5 个与Freebase 有关的多源数据仓库。同样地,爬取了与DBpedia 有关的实体14 656个,以及与它们有关联的三元组集合。然后以0.3 的概率采样其中的三元组集合,构建了5 个与DBpedia有关的多源数据仓库。基础验证标记为正确的三元组将作为多源数据关系验证的输入,计算对应的F1指标,结果如表6 所示。从实验结果可以看出采用较为正确的数据源进行多源关系验证,能得到较好的效果。
对于多源关系验证中置信度较低的三元组,增强验证模块采用领域专家人机验证进一步确定三元组关系,可以得到正确的三元组。经过增强验证后的三元组较为正确,最后采用正确的三元组更新知识图谱。
6.3 各环节时间实验结果
本文测试了本文提出的基于主动学习的知识图谱补全框架的各个环节的时间消耗。框架包含四个环节:(1)实体聚类算法;(2)RPR 算法;(3)ELP 算法;(4)TransH 模型训练。结果如表7 所示,从表7 中可以看出主要时间开销在关系验证模块中,链接预测模块的时间开销相对不高。而本文提出的对于知识图谱实体聚类方法的时间开销相对于RPR 算法要小很多。总的ELP 算法的时间开销相对占比不大。
7 结论
本文提出了一种基于主动学习的知识图谱补全框架来实现对缺失知识图谱的不断更新完善。知识图谱补全框架由不断更新的知识图谱、链接预测模块、关系验证模块构成。在链接预测模块中,提出的ELP 算法充分考虑了知识图谱中的语义信息和图结构信息,能准确实现对知识图谱的链接预测,同时ELP 算法具有主动学习能力,能随着知识图谱的不断完善,可以更好地进行链接预测。在实验中,通过与前人的RPR、SimRank、CommonNeighbours、Katz 等方法进行对比,证明了ELP 算法的有效性。同时,也通过实验证明了ELP 算法的主动学习能力。关系验证模块采用基础验证和增强验证相结合的方法进行关系验证,这种关系验证方式能够结合知识图谱内部数据和互联网结构化数据,以及领域专家人机交互标注,能够验证三元组的正确性。通过实验验证了关系验证模块的有效性。关系验证模块能验证链接预测模块输出的实体对之间的关系,形成正确的三元组,从而更新知识图谱。

Table 6 F1 results of multi-source data relationship verification表6 多源数据关系验证F1 实验结果

Table 7 Time comparison of each step表7 各环节时间对比
