融合CamShift的TLD算法实现人脸跟踪
2020-05-09李丽宏
牛 颖,李丽宏
(太原理工大学 电气与动力工程学院,太原 030024)
1 引 言
人脸检测与跟踪是计算机视觉和图像处理领域的一个重要分支,在安防监控系统[1]、门禁系统[2]和机器人[3]等系统中应用非常广泛,已引起越来越多研究人员的关注.Turk等提出了特征脸,通过比较面部特征与已知个体的特征来识别目标人物,其性能容易受到光照和姿态变化的影响[4].简毅等提出基于遗传优化 GRNN神经网络的人脸识别算法将人脸识别的准确率提高到88%,但平滑因子选取不当则达不到预期效果[5].张涛等提出一种融合了卡尔曼滤波器的Mean Shift算法,实现了实时多人脸跟踪,但背景光线变化对跟踪的准确性影响较大[6].王健基于传统的Gentle AdaBoost算法在弱分类器训练中引入代价因子,通过更新其权值,提高了人脸检测率,但检测速度慢,无法满足实时性要求[7].DU等使用帧差法提取运动区域,通过融合卡尔曼滤波器的CamShift算法识别人脸,提高了系统的鲁棒性,但因计算量大导致运行速度慢[8].Nhat等提出基于特征自适应模型,实现了准确且快速的人脸追踪,但此法仅能检测一张人脸[9].Zhang等人将KCF算法和CamShift算法相结合,能有效地抵抗干扰,实现对目标人脸的稳定跟踪,但实时性较差[10].席志红等提出背景差分法改进TLD算法的检测模块,提高了跟踪速度,但此法不能很好处理目标被遮挡的情况[11].
本文使用融合CamShift的TLD算法,改进了跟踪模块,利用直方图反向投影得到目标图像像素的概率分布,自适应调整目标窗口大小并自动跟踪目标,提高了人脸追踪效率和准确率.
2 TLD算法
TLD算法分为跟踪模块、检测模块和学习模块三个部分[12].跟踪模块在连续的视频序列中对目标进行追踪,检测模块通过对视频序列的每一帧图像进行独立的检测,获取目标物体的最新外观特征来定位每一帧图像中目标物体的位置,追踪模块追踪目标失败后帮助系统重新定位并追踪目标物体,使得系统重新稳定运行.跟踪模块与检测模块是独立工作的.学习模块根据跟踪模块结果和检测模块结果的对比评估错误和误差,通过迭代训练样本,更新检测模块的目标模型,实现自我学习,避免以后出现类似错误,从而使跟踪更加稳定和可靠[13].TLD算法整体结构如图1所示.
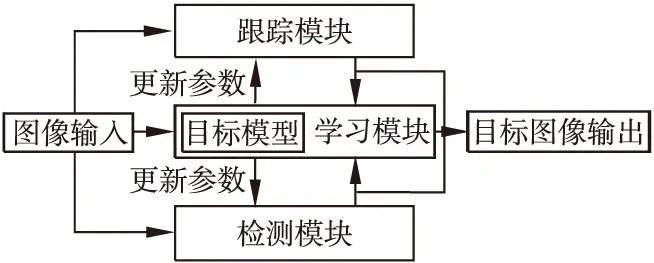
图1 TLD算法整体结构Fig.1 TLD algorithm overall structure
2.1 改进的跟踪模块
TLD算法中跟踪器采用的是L-K光流法,该方法在视频处理过程中需要从图像金字塔最高层开始计算光流,向塔底迭代计算,复杂度较高,导致跟踪实时性很差.
本文将CamShift算法作为TLD算法框架中的跟踪模块,通过计算目标图像在HSV颜色空间下的颜色分量直方图,利用直方图反向投影得到目标图像像素的概率分布,自动定位并跟踪目标并自适应调整目标窗口大小.该算法计算量小且易于实现.在前一帧图像中进行Haar人脸特征提取,并使用分类器检测出人脸,然后使用CamShift算法对目标人脸进行跟踪,步骤如下:
1)将包含目标人脸的待检图像的色度分为m个等级,记第i个像素坐标为(xi,yi),其色度特征值为b(xi,yi),待检图像的特征色调值为u,则可构建色度特征直方图模型为q={qu},u=1,2,…,m.
(1)
2)根据步骤1)构建的色度特征直方图模型进行反向投影,预测其灰度值,形成概率投影图.设像素(x,y)对应的特征色调值为u,则该像素点的概率投影图的灰度值I(x,y)为:
(2)
其中,⎣·」为向下取整符号.
3)计算待检图像中定位窗口的零阶矩和一阶矩:
(3)
4)计算定位窗口的质心(xw,yw):
(4)
5)对定位窗口的大小进行自适应调整:
(5)
设定定位窗口的中心与质心的距离阈值,若该距离大于设定阈值,重复步骤3)到步骤5),直到该距离达到预定要求,小于设定阈值.
6)计算定位窗口的二阶矩:
(6)

(7)
(8)
则椭圆形定位窗口的大小和方向为:
(9)
7)获取下一帧图像,返回步骤1),重新构建色度特征直方图模型,计算新的目标图像的像素点,直至完成目标跟踪.
跟踪模块使用CamShift算法,可以跟踪目标图像并自适应地调整定位窗口大小,获取目标人脸的大概位置,从而提高跟踪模块的运行速度.
2.2 检测模块
TLD算法的检测模块对图像进行滑动窗法扫描搜索,即对用一个个小窗口对输入图像进行扫描,扫描窗口尺度缩放系数为1.2,窗口水平方向步长是图像宽度的10%,窗口竖直方向步长是图像高度的10%,如图2所示.以大小为320×240的图片为例,滑动窗法扫描次数高达5万次,计算量非常庞大.因此需要有效的分类器,检测模块中分类器是由三个子分类器级联而成,对从目标边界框获得的样本进行分类.子分类器包括图像方差分类器、集成分类器和最近邻分类器.
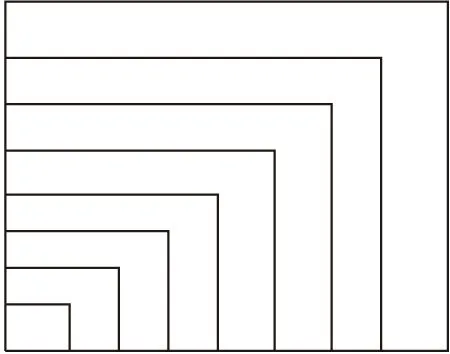
图2 扫描框示意图Fig.2 Schematic diagram of the scan box
一般情况下,跟踪器可以追踪出人脸大致位置,而检测器需要对人脸位置进行更精准的检测.以本文所采集的1920×1080分辨率图片为例,人脸距离图像采集设备距离在0.5m~2m的情况下,图像中人脸所占大小约在250×200像素到400×500像素之间.设图像视野宽度为W,高度为h,目标人脸所占窗口最大尺寸的宽度为wmax,高度为hmax,人脸所占窗口最小尺寸的宽度wmin,高度为hmin,若扫描框的变换阶数设为k,那么单次扫描框宽度及高度变化增量表示为:
ΔW=(Wmax-Wmin)/k
Δh=(hmax-hmin)/k
(10)
若当前帧的目标矩形框最初尺寸宽度为ws,高度为hs,则第i种扫描矩形框的宽度计算公式为:
Wi=Ws-ΔW·i,i∈Z[0,il]
Wi=Ws+ΔW·i,i∈Z[0,ir]
(11)
其中:il=(ws-wmin)/Δw,ir=(wmax-ws)/Δw
同理第i种扫描矩形框的高度计算公式为:
hi=hs-Δh·i,i∈Z[0,il]
hi=hs+Δh·i,i∈Z[0,ir]
(12)
其中,il=(hs-hmin)/Δh,ir=(hmax-hs)/Δh
求出当前帧中矩形框的中心点即脸部中心(xc,yc),在左上角坐标(xc-ws,yc-ws),右下角坐标(xc+ws,yc+ws)的矩形范围内进行矩形框滑动检测,滑动时的行步长计算公式为:
sr=λΔw,sc=λΔh
(13)
λ取值为[0,1]的实数.
将所有种扫描框中的图像区域提取出来,作为一个集合对其进行分类器检测.
1)方差分类器
积分图像在图像计算处理过程中具有重要作用,积分图像定义为:图像上任意位置(x,y)处值ii(x,y)为该点左上角所有像素的和,如公式(14)所示:
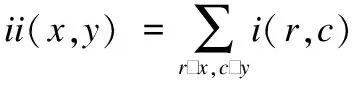
(14)
其中i(r,c)表示初始图像(r,c)位置的像素值.通过积分图像计算图像某一区域像素方差时可大大缩短计算时间.如图3所示,P1,P2,P3,P4围成的区域A.
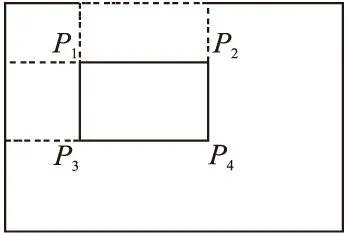
图3 通过积分图计算像素方差Fig.3 Calculate pixel variance by integral graph
由积分图像的定义可知,该区域图像的像素和为sum(A)=P4-P2-P3+P1.该区域图像的期望为:E(A)=sum(A)/(hi·wi),对于第i个矩形框区域集合,其灰度值方差σ12计算如下:
(15)
将该矩形区域中图像的像素灰度值方差σ22与目标图像的方差σ22相比较,若σ12≤0.5σ22,则从集合中排除该矩形区域图像,否则认为当前扫描窗口包含目标图像.
2)集成分类器
集成分类器实际是随机蕨分类器,每层节点判断准则相同,是线性结构的分类器.集成分类器根据样本特征值进行判断,例如,在图像中任意选取两点A和B,对两点亮度值进行比较,若A的亮度大于B,则特征值为1,否则为0.蕨的每个节点就是通过比较每一对像素点.每选取一对新像素点,就是一个新的特征值.同一类的多个样本经过同一个蕨,得到该类结果的分布直方图,计算见公式(16).用很多个蕨对同一样本分类,投票数最大的类作为新样本的分类,这样可以很大程度提高分类器的准确度.
(16)
其中,p(F|Ck)代表类的先验概率,F代表蕨的结果.
3)最近邻分类器
通过最近邻分类器对扫描框图像集合进一步筛选,最近邻分类器通过计算图片间对应点像素值间的距离作为评定准则,如两个图像像素向量间的曼哈顿距离.假定第i个矩形框区域的像素分布如图4所示,将其作为输入图像,目标矩形框作为参考像素框,相减后各像素和作为图像距离的评定标准,数值越小则表示距离越近.筛选出距离最近的k个扫描框图像作为最终结果.
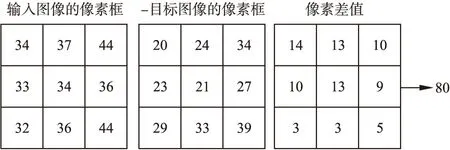
图4 图像像素点求距离示意图Fig.4 Image pixel point distance map
2.3 学习模块
在TLD算法框架中,跟踪模块与检测模块是并行独立工作的.学习模块根据跟踪模块结果和检测模块结果的对比评估错误和误差,通过迭代训练样本,更新检测模块的目标模型,实现自我学习,被称为P-N学习器.P-N学习器流程框图如图5所示.

图5 学习模块流程图Fig.5 Learning module flow chart
首先根据标记样本数据,经过训练得到初始分类器.P-N专家负责找出错误分类样本,并对训练样本集做出修正.由于目标与背景在图像中是共存的,并不相互独立.在检测模块中,P专家负责找出被标为背景的目标图像,也就是错误的负图像;而N专家负责找出标记为目标的背景图像,也就是错误的正图像.
3 对比试验及结果分析
本文将改进的TLD算法与TLD算法和CamShift算法进行对比试验.本文试验设置改进的TLD算法中CamShift算法迭代次数为10,检测模块中检测到的目标人脸和真实人脸的定位窗口重叠50%及以上,则认为跟踪正确,以此作为标准对算法的效果进行对比.
3.1 与TLD算法对比试验及结果分析
本试验分别在人与相机距离0.5m,1m,2m时,使用改进的TLD算法和TLD算法实现人脸跟踪,实时跟踪效果良好,其效果图见图6.分图左图均为原始TLD算法效果图,分图右图均为改进的TLD算法效果图.

图6 改进的TLD算法和TLD算法实现人脸跟踪Fig.6 Improved TLD algorithm and TLD algorithm for face tracking
通过图6可知,在人与相机距离不同时,TLD算法和改进的TLD算法均成功实现人脸跟踪,这两种算法跟踪准确率和实时性见表1.
表1 改进的TLD算法和TLD算法跟踪实时性比较
Table 1 Comparison of improved TLD algorithm and
TLD algorithm tracking real-time

算 法人与相机距离/m总帧数跟踪准确率所用时间/s帧率TLD算法0.550390%4311.7149889%4211.8250189%4311.7改进的TLD算法0.550392%3116.2149891%3016.1250191%3116.1
根据表1的测试数据可知,对500帧图像进行跟踪,原始TLD算法所用时间约为42s,跟踪准确率约为89%.改进的TLD算法所用时间约为31s,跟踪准确率约为91%.改进的TLD算法跟踪准确率提高了2%,所用时间减少11s.
3.2 与CamShift算法对比试验及结果分析
有无遮挡物时,改进的TLD算法和CamShift算法实现人脸跟踪如图7所示.分图左图均为原始CamShift算法效果图,分图右图均为改进的TLD算法效果图.
通过图7可知,脸部存在遮挡物时,CamShift算法将无法准确实现人脸跟踪,甚至出现跟踪失败.但使用改进的TLD算法,可以成功跟踪人脸,这两种算法的跟踪准确率和实时性见表2.

图7 改进的TLD算法和CamShift算法实现人脸跟踪Fig.7 CamShift algorithm and improved TLD algorithm for face tracking
根据表2的测试数据可知,没有遮挡物时对500帧图像进行跟踪,原始CamShift算法所用时间约为35s,跟踪准确率约为92%;改进的TLD算法所用时间约为27s,跟踪准确率约为92%,改进的TLD算法跟踪所用时间减少8s.有遮挡物时对500帧图像进行跟踪,原始CamShift算法所用时间约为36s,跟踪准确率约为87%,改进的TLD算法所用时间约为28s,跟踪准确率约为91%.改进的TLD算法跟踪准确率提高了4%,所用时间减少8s.
表2 改进的TLD算法和CamShift算法跟踪实时性比较
Table 2 Improved TLD algorithm and CamShift algorithm for
tracking real-time comparison
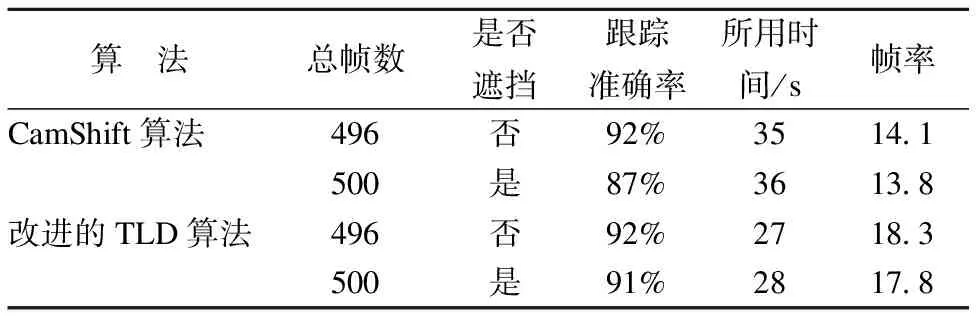
算 法总帧数是否遮挡跟踪准确率所用时间/s帧率CamShift算法496否92%3514.1500是87%3613.8改进的TLD算法496否92%2718.3500是91%2817.8
综合上述数据分析可知,使用改进的TLD算法,跟踪准确率和帧率均高于原始两种算法,且在有遮挡物的情况下也能成功跟踪人脸.
4 结 论
针对TLD算法跟踪人脸实时性差的问题,本文提出了改进的TLD算法,该方法使用CamShift算法作为跟踪模块,对跟踪性能进行优化.通过对比试验可知,改进的TLD算法相比于TLD算法和CamShift算法,人脸跟踪效率和准确率均得到提高,满足试验要求.
在Visual Studio 2015平台上创建应用程序进行测试,结果表明,本方法思路合理,有效地实现了实时人脸跟踪.
