基于转录组数据的三峡库区消落带适生狗牙根SNPs和SSRs分析
2020-05-05李彦杰贾洪沅李庆天白艺旋刘芸杉
李彦杰,贾洪沅,李庆天,白艺旋,刘芸杉
(1.重庆三峡学院 生物与食品工程学院,重庆 万州 404100;2.重庆三峡学院 教师教育学院,重庆 万州 404100)
【研究意义】三峡大坝水位调度使其上游库区两岸出现了周期性的反季节淹没——出露消落带区域[1-2]。消落带植被受水陆环境交替影响而逐渐退化,加剧了库区生态环境的不稳定性,进而引发水土流失等次生灾害[3]。稳定消落带生态环境的关键是消落带植被的重建和恢复[4]。研究表明,作为三峡库区消落带原生植物,狗牙根通过调整来自多个基因信号通路的众多基因表达,从通气组织生成、伸长性生长和不定根形成等形态学变化以及细胞加固和抗氧化组分增高等代谢调整,在多方面、多层次适应水淹信号,从而使其表现出一定程度的水淹生境适生性[5-8]。开发、建立大规模的分子标记有利于分离和鉴定与消落带原生狗牙根水淹适生性相关的等位基因,并且在遗传性状解析、分子育种、多样性分析以及抗水淹植物筛选等方面具有重要作用。简单重复序列标记(simple sequence repeats,SSRs)和单核苷酸多态性(single nucleotide polymorphisms,SNPs)是使用较多的两种共显性分子标记,前者是片段标记,多用于目标基因定位和遗传图谱构建等,后者是序列信息标记,多用于目标基因精细定位和识别等[9-10]。【前人研究进展】目前,基于SSR标记的狗牙根相关研究相对较少,且主要集中在种质遗传多样性分析和抗寒性状鉴定等方面,而有关狗牙根SNP标记研究鲜有报道[11-14]。【本研究切入点】三峡库区消落带原生狗牙根水淹适生性与其序列片段及序列信息有关,解析其SSRs和SNPs数量及分布以评估其遗传多样性分析和种质资源,进而分析其与水淹相关的现状及定位功能基因,有助于加深对狗牙根耐水淹机制的理解。【拟解决的关键问题】为三峡库区消落带的植被重建及生态环境恢复提供基础和参考。
1 材料与方法
1.1 供试材料
实验材料取自位于重庆市万州区新田镇谭绍村的三峡库区天然消落带,材料处理、取样方法和测序样品制备等见课题组前期研究[5]。Illumina HiSeq 4000 平台测序及SSR引物合成由深圳华大基因科技有限公司完成。测序样品分为水淹处理组(A2)和未水淹对照组(A1)。
1.2 试验方法
转录组测序原始读序(Raw reads)经去除测序接头读序(reads)、未知碱基含量大于5 %的reads和低质量的reads后得到纯净读序(clean reads)。使用Trinity V2.0.6软件首先将clean reads打断为较短片段(K-mer)构建数据库,选高频率作为种子向两端延伸得到线性重叠群(contigs),再将Contigs聚类得到片段集合(Component),并对每个Component构建de Bruijin图,最后根据pair-end reads解读de Bruijin图信息得到转录本序列(Full-length transcriptome assembly from RNA-Seq data without a reference genome)。将上述转录本序列基于Tgicl v2.0.6r软件进行聚类去冗余得到Unigene。使用HISAT v0.1.6-beta把clean reads比对到Unigene,利用GATK v3.4-0检测SNPs。使用MISA v1.0搜索Unigene的SSRs,筛选标准为:单核苷酸、二核苷酸、三核苷酸、四核苷酸、五核苷酸和六核苷酸的重复次数分别设置为12、6、5、5、4和4次。
2 结果与分析
2.1 测序数据整理及组装
整理转录组测序原始读序(Raw reads)和纯净读序(clean reads)得Total Raw Reads、Total Clean Reads、Total Clean Bases、Clean Reads Q20、Clean Reads Q30和Clean Reads Ratio分别为89.875 Mb、73.72 Mb、11.055 Gb、99.14 %、97.19 %和82.035 %。其中,Clean Reads Q20是指质量值大于20的碱基数目占总碱基数目的比例,若其值大于80 %则认为测序数据质量较高[15]。本次所得clean reads为99.14 %,说明狗牙根转录组测序的Raw reads经过滤后所得clean reads质量高。两组样本基于Trinity软件共组装得到162323条转录本,其平均长度为721个核苷酸(nucleotide,nt),将上述转录本基于Tgicl软件去冗余得含147256条序列的非冗余基因数据库(universal gene,unigene)(表1)。将所有的Unigene按照从长到短排序,将排序后的Unigene从长到短依次相加,当相加长度等于Unigene总长度的一半时所对应的Unigene长度即为N50值。N50可用来评估转录本和Unigene组装质量,其值越大表示组装或所得的序列质量越高[16]。本实验转录组测序数据经组装所得转录本的N50为1287 nt,所得Unigene的N50为1509 nt,且长度大于500 nt的Unigene超过50 %(图1),故认为所得Unigene质量较高,其可满足后续数据库注释和差异基因富集等分析。
2.2 狗牙根转录组中SNP数量与分布
利用GATK软件从两组样本共检测出297 542个SNPs,其中转换型位点数量为183 565个,颠换型位点数量为113 977个。从图2可知,每组样品内的A-G或C-T转换型位点数量相近,且均远多于颠换型位点数;4种颠换型位点数量按照从多到少依次为C-G>G-T>A-C>A-T。水淹样品(A2)的各类型SNPs数量均小于未水淹样品(A1)。

表1 转录本和Unigene组装结果Table 1 Assembly results of transcripts and Unigene

图1 Unigene长度分布Fig.1 Length distribution of Unigene
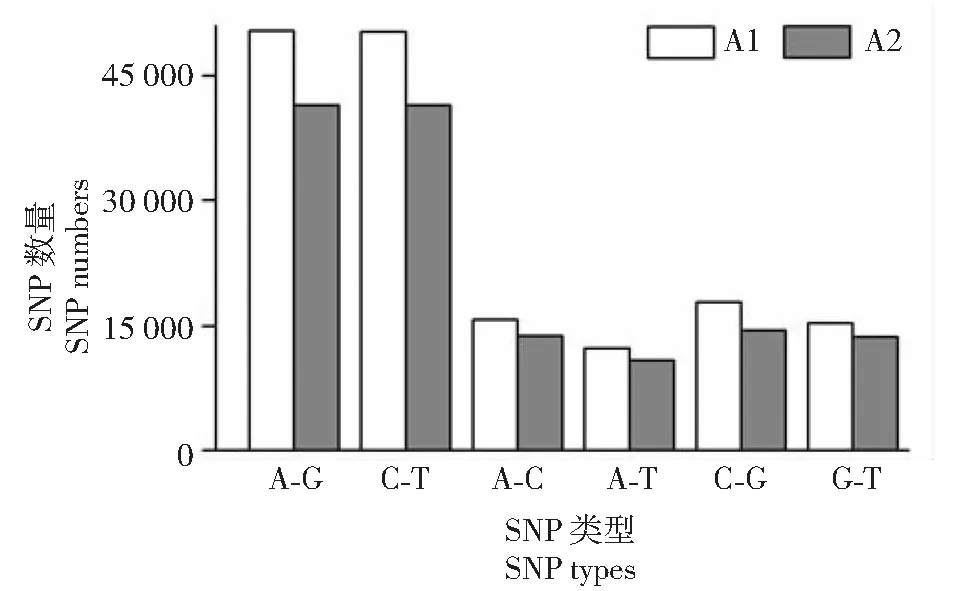
图2 SNPs类型分布Fig.2 Type distribution of SNPs
2.3 狗牙根转录组中SSR数量与分布
利用MISA软件对狗牙根的147 256条Unigene作序列搜索共检测到22 154个SSRs分布于18 982条Unigene中,发生频率为(含SSRs的Unigene数目与总Unigene数目的比值)12.89 %,出现频率(SSR总数与总Unigene数目的比值)为15.04 %,含有超过一个SSR位点的Unigene有2680条,含复合型SSR位点的Unigene有1023条。SSRs以单核苷酸、二核苷酸和三核苷酸重复为主,三者总和约占SSRs总数量的94.99 %(表2)。单核苷酸SSRs中腺苷酸(A)和胸腺嘧啶(T)分别为3776和3650条,胞嘧啶(C)和鸟苷酸(G)分别为103和225条。
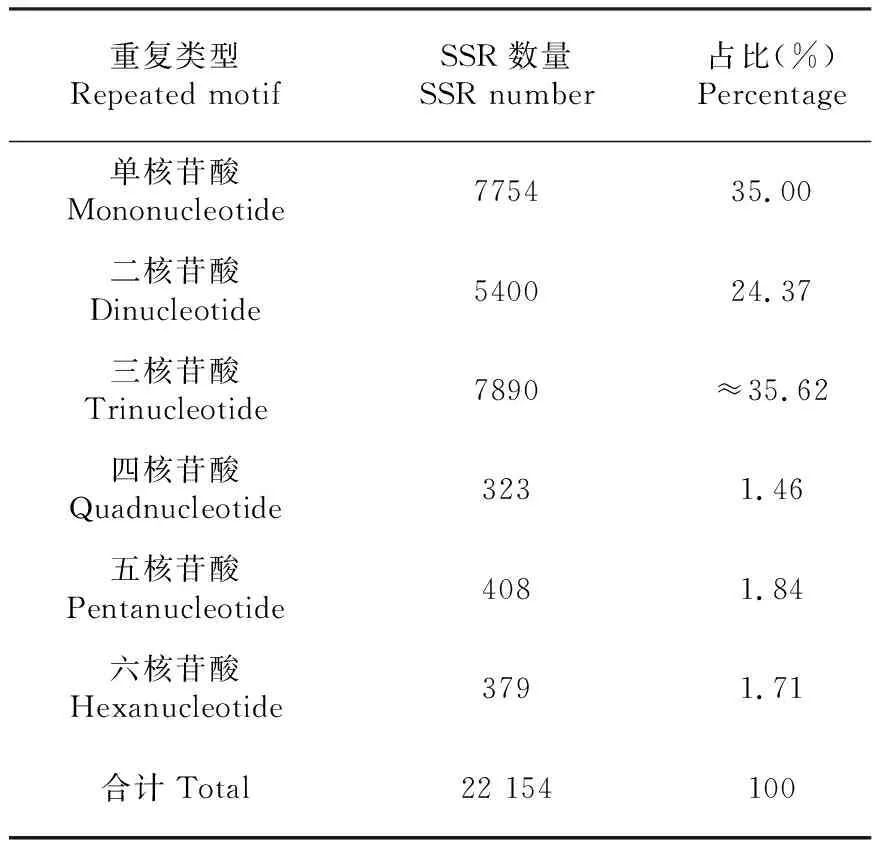
表2 Unigene中的SSRs数量Table 2 Number of SSRs in Unigene
进一步统计SSRs分布可知,二核苷酸重复类型中4种SSRs数量大小为:AG/CT>AC/GT>CG/CG>AT/AT,其中AG/CT型SSRs数量明显高于其他3种,且与AT/AT型SSRs数量相差近10倍;三核苷酸重复类型中10种SSRs数量大小为:CCG/CGG>ATC/ATG>AGG/CCT>AGC/CTG>ACT/AGT>ACG/CGT>ACC/GGT>AAT/ATT>AAG/CTT>AAC/GTT,其中CCG/CGG型SSRs数量比AAC/GTT型高出10倍(图3)。随着重复次数的增加,单核苷酸和其他5种SSRs数量均呈下降趋势,其中重复6次的位点数在二核苷酸SSRs中占比最高,其约占二核苷酸SSRs总数的29.41 %,重复6~10次和6~20次的二核苷酸SSRs分别占二核苷酸SSRs总数的68.80 %和94.74 %(图4)。三核苷酸SSRs和四核苷酸SSRs的重复次数主要以5和6次为主,其中重复5次的SSRs分别占两类SSRs总数的62.79 %和97.41 %。五核苷酸SSRs和六核苷酸SSRs以4次重复为主,该重复次数的SSRs分别占两类SSRs总数的83.82 %和87.60 %。
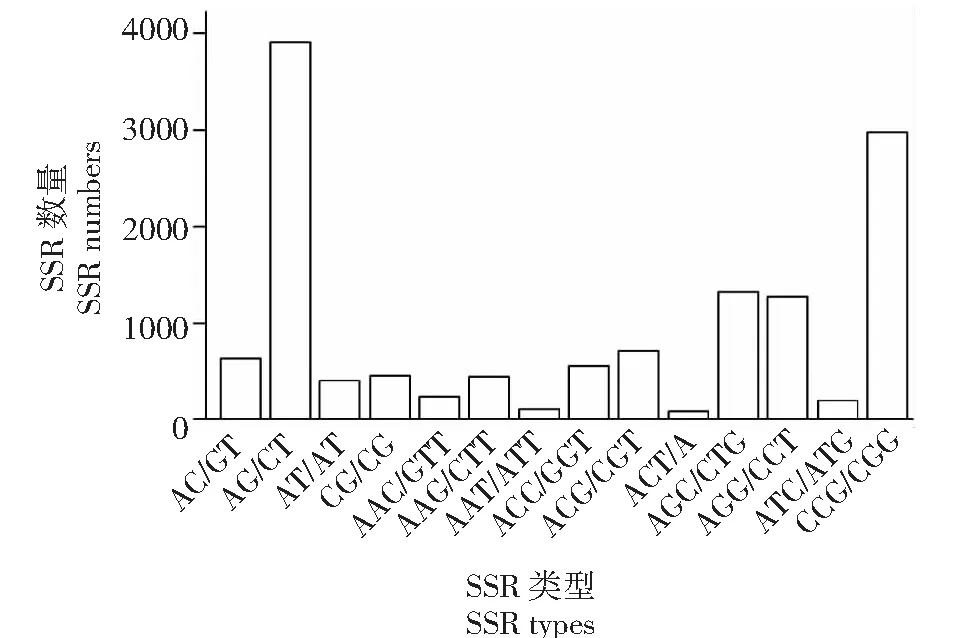
图3 SSRs类型分布Fig.3 Type distribution of SSRs

图4 不同重复次数的SSRs位点数量分布Fig.4 Number distribution of SSRs with different repetition times
SSRs基序长度可用来评估多态性高低,通常12~20 bp的长度范围具有中等多态性,低于12 bp和高于20 bp分别具有低多态性和高多态性[17]。本次实验获得的SSRs基序长度在12~246 bp之间,平均长度为19.60 bp。SSRs基序长度分布如图5,可知,基序长度在12~20 bp的SSRs数量最多,占比为78.52 %,其次为占比13.37 %的基序长度在12~20 bp的SSRs,基序长度大于30 bp的SSRs占比为8.11 %,说明狗牙根转录组SSRs具有中等多态性,可用于后续的遗传多样性和品质鉴定等分析。

图5 SSRs基序长度分布Fig.5 Distribution of SSRs motif length
3 讨 论
不同植物或同一种植物的SSRs碱基组成和拷贝数随物种或个体的不同而表现出一定差异,而SSRs的两侧序列却相对保守,因此可通过设计引物扩增SSR或基于测序数据分析其序列多态性。SSRs序列多态性与DNA复制、修复过程中DNA滑动和错配,或有丝分裂、减数分裂期姐妹染色单体不均等交换有关[18-19]。SSRs中的重复核苷酸数常为一至六,其中以单核苷酸、二核苷酸和三核苷酸型SSRs占比最高。本实验中,狗牙根SSRs主要以单核苷酸、二核苷酸和三核苷酸型为主。此外,SSRs的长度和数量可能与染色体结构、转录调控和功能基因鉴定等有关[20]。本实验中狗牙根转录组SSRs具有中等多样性,故借助SSRs数量、类型分布、位点分布和长度分布等信息有助于解析与三峡库区消落带原生狗牙根耐水淹的相关性状,或可进一步用于相关功能基因的识别和定位等。SNPs是由于单个核苷酸的变异所引起的DNA序列多态性,且多为二等位多态性。SNPs主要分为转换和颠换两种形式,转换的频率远高于颠换,这可能与CpG二核苷酸上的胞嘧啶残基易于脱去氨基而形成胸腺嘧啶有关。本实验中搜索到的SNPs标记也是以转换型为主,且总数约占总SNPs数目的2/3。SNPs在基因组可分布于多个位置,其中位于基因编码区的SNP(coding-region SNP,cSNPs)虽然相对数量较少,但其对生物性状解析和辅助育种等具有重要作用,故通过进一步深挖狗牙根转录组数据的cSNPs信息,绘制cSNPs图谱可用于狗牙根与抗逆相关的多样性分析、品质鉴定和分子育种等研究。
SSRs和SNPs技术较为成熟,在植物分子育种以及相关性状解析等多个方面发挥了重要作用。SSRs有标准化的分析流程,但其分辨率相对较低,而SNPs具有数量更多、密度更高、分布更广,因此有相对较高的分辨率。植物以多倍体为多,使得SNPs的可用性降低,因此在实际工作中可将SSRs和SNPs标记结合使用。
4 结 论
基于狗牙根转录组测序数据共得到297 542个SNPs和22 154个SSRs,其中这些SSRs的发生频率为12.89 %,且主要以单核苷酸、二核苷酸和三核苷酸重复为主,三者合计占比为94.99 %;基序长度在12~20 bp的SSRs数量最多,占比达78.52 %,显示出较好多态性。由于狗牙根为多倍体,故结合丰富的SSRs和SNPs信息,或可为其遗传多样性分析和分子育种等提供参考。
