基于深度学习的牙齿识别方法
2020-04-25柯文驰李莎李睿
柯文驰,李莎,李睿
(四川大学计算机学院,成都610065)
0 引言
灾难遇害者识别(DVI)是法医学中的一项重要研究课题。在大型灾难事故中,通常伴随有火灾、爆炸等极端条件。此时遇难者的软性组织不可用时,传统的同一认定方法如DNA 检测、指纹和人脸识别等方法有较大困难且不准确。自然牙齿是脊椎动物中最耐用的器官,具有很好的防腐性和抗降解性,在极端条件下也能够保存下来。在一些极端灾难事件中,牙齿是鉴定遇难者的唯一方法[1]。采用牙齿解剖形态标志以及颌面部骨性标志的口腔影像学资料进行法医学同一认定越来越受到国际法科学界的认可。
21 世纪的多次重大群体性死亡事件中,依靠牙齿进行个体识别均发挥了重要作用[2]。但是现行的DVI系统主要依靠人工进行识别,速度慢效率低。在2004年的印尼海啸事件中,对遇难者的身份识别绝大多数都是由牙齿匹配确认,但是身份认定工作耗费了数年才基本完成。正是由于基于牙齿的DVI 系统的匹配准确率高、速度慢的这一特点。迫切的需要一种快速的比对方法,因此采用计算机图形图像技术进行辅助识别具有极其重要的作用。
相关研究人员设计出了很多DVI 系统,例如:基于根尖片的方法[3]、基于咬翼片的方法[4]、基于全景片的方法[5]。这些DVI 系统主要是利用传统的计算机视觉方法人工设计提取特征,并设计一套特征比对方法来对个体进行识别。传统图形图像算法的存在着一定的局限性。人为设计的特征提取方法不具有泛用性。大多数DVI 系统针对于牙齿修复体设计[6],在没有在牙齿治疗的个体,DVI 系统会失效。并且这些系统都运行在小样本的环境下,取得了不错的实验结果,但在更大数据集上则无法工作。
随着人工智能技术的发展,深度学习已经成为了一种跨多学科的前沿技术潮流。如何将深度学习技术应用到各个学科上,已经成为一个非常重要主题。深度学习应用在计算机视觉中,产生了许多重要的应用,如人脸识别技术。人脸识别技术广泛应用于常见的可获取人脸的身份验证场景,在铁路、安防等领域已经投入实际使用。
鉴于深度学习在人脸识别领域取得的成果,本文运用深度学习算法,提出了一种通过牙齿全景曲断片来进行人类身份认定的方法。这种方法能够避免传统方法中的特征设计,使用卷积神经网络来提取牙齿特征,提高泛用性。对牙齿图像全局进行特征抽取,不针对单一类型牙齿修复体进行设计,增强了系统的稳定性和准确率。
1 材料与方法
1.1 研究材料
本实验采用牙齿全景曲断片(PDR)作为主要的研究材料,如图1 所示。牙齿全景曲断片是一种常见的X 光片。全景曲断片清晰完整的显示了上颌骨、下颌骨,人类医师可以通过全景片观察到全口牙齿的状况。拍摄全景片是口腔治疗前一个非常重要的环节,大部分口腔治疗都会产生全景片。全景曲断片的可供收集使用的数量非常大。口腔治疗持续时间长,病人会定期复查,而口腔治疗的全过程都会产生全景曲断片。对于同一认定来说,每个病人至少应该存在2 个不同时期的认定样本。
数据越多,深度学习能从中学习到的高维信息越多。大量的数据会极大的提高网络的准确率和泛化能力。因此,本实验一共收集了2096 人,共计5211 张口腔全景曲断片。因未成年人的牙齿全景片为混合牙列,全景片会在短时间内变化巨大。为了简化实验,本次采用的数据均为16 岁以上牙齿萌发完成的成年人。实验数据收集自四川大学口腔医院。所有全景片按人进行加标签分类。取出其中96 人(294 张全景片)作为测试集。整个数据集平均每人不同时间拍摄的全景片2-3 张。
1.2 方法
(1)数据预处理
对于每一张全景片,都会有一定的差别,在拍摄时不同的辐射剂量,会造成图像明暗上存在差异。拍摄者在拍摄时的角度,会使得最终生成的图像呈现出在一定范围内的变形。若不对这些图片进行针对性调整,则会对实验结果造成影响。还有部分图片会存在一些无关标记,这些标记是为了方便人类医师阅片,对于深度学习来说,这些标记是无关的,故裁剪掉。本实验针对性设计了一套图像预处理方法。
处理方法如下:
经过上述处理方式后,最终将图片全部调整到256×256 尺寸的灰度图,如图1 所示。
(2)算法
①总体框架
如图2 所示,算法利用牙齿的全景片作为输入,经过图像预处理后,将数据集分割为训练集和测试集合。在卷积神经网络的训练阶段,进行分类训练。训练完成后,抽取出特征向量与库中所有注册数据进行相似度计算,选取具有最高相似度的。
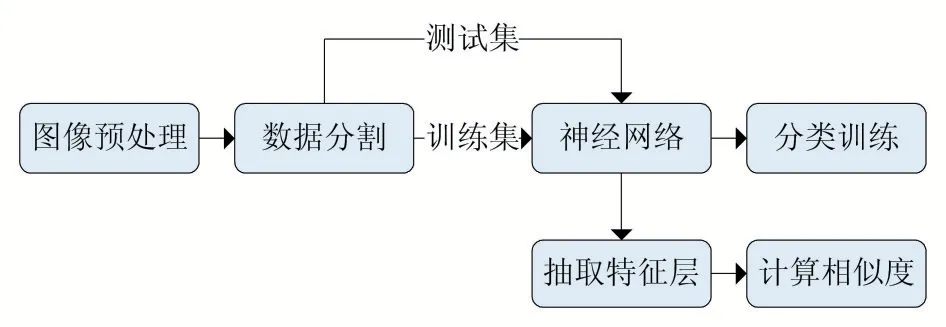
图2 算法流程图
同传统的神经网络方法相比深度学习最大的特点在于深度。受限制于设备运算能力的限制,早期常常是浅层神经网络,但浅层神经网络效果并不理想。随着运算能力的发展,深度神经网络逐渐加深。深度神经网络在采用大量数据进行训练后模型的效果远超传统方法。基于这个原因,本实验网络架构直接基于AlexNet[7]网络设计。
网络架构如图3,网络一共有11 层,前7 层为卷积层,后4 层为全连接层。激活函数使用ReLU。网络输入沿用AlexNet 网络中使用的256×256。第2、4、7 层卷积层后跟池化层,池化操作,全部采用最大池化。使用池化操作能够利用局部相关性减少数据冗余,控制过拟合。当数据输入卷积层,不同的卷积核会捕捉到不同的局部信息。经过图像在全连接层将这些信息进行综合,从而得到全局的信息。全局信息经过恰当的压缩过后行成表征整幅图像的特征向量。在后续的深度学习发展中,Local Response Norm Layer(LRN 层)并无必要[8]。本实验中去除掉了最后一层的LRN 层。在AlexNet 中使用的11×11、5×5 步长卷积核运算量大,使用3×3 步长的小卷积核来替换能够取得相同的效果,并能够显著降低运算量。所以本研究用3×3 替换了AlexNet 的大卷积核。更详细的参数见表1。
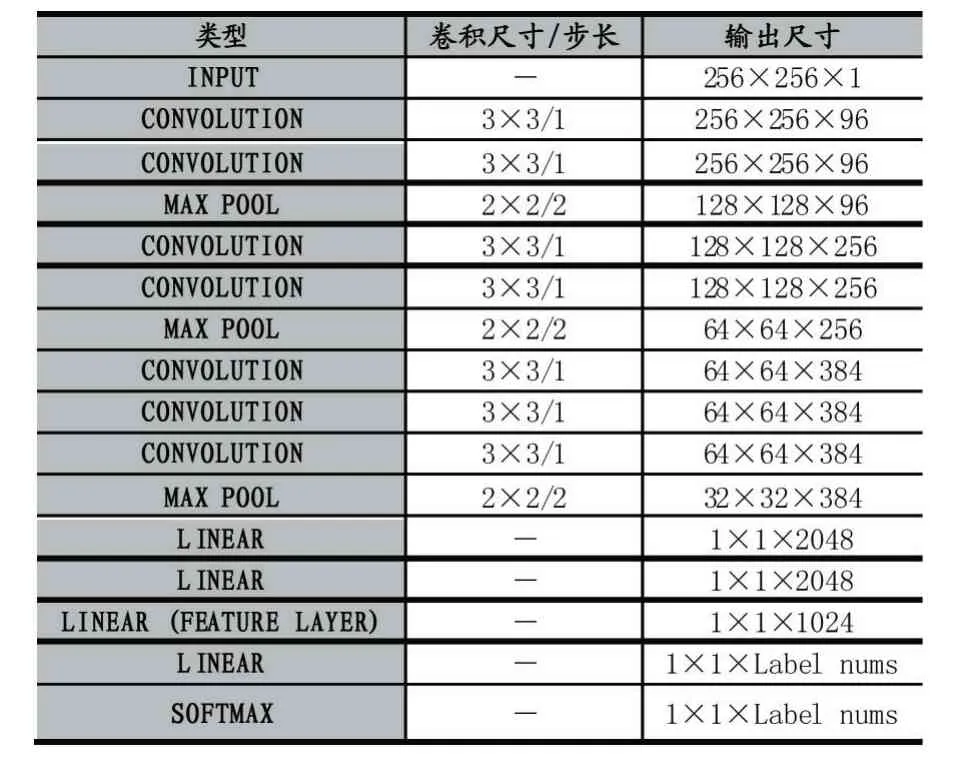
表1 网络架构参数

图3 网络架构图
本实验使用了PyTorch 1.4.0 的深度学习框架,利用OpenCV 进行图像处理。训练使用设备为NVIDIA RTX2070 Super,使用的随机梯度下降算法(SGD)进行训练。初始学习率为0.001,每20000 次迭代学习率折半,到80000 次迭代时停止。Batch 值为16。
④特征提取与相似度计算
因为AlexNet 设计之初只是为了解决分类问题。对于身份认证这类问题需要针对做一定的修改。在人脸识别中,为每一个人分配一个类别是不可能的,一方面由于分类类别数过于庞大会导致网络训练困难,另一方面搜集所有人的数据的代价也是难以承受的。所以常规做法是用一个特征向量来代表一张图像所包含的信息。通过计算两人图像的相似度,来区两者是否为同一人。
在本实验中第二层全连接设为特征层,将该层单独从网络中抽取出来。匹配时,任意计算任意两人的余弦相似度:
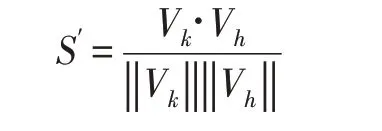
当获取到了足够的数据,训练出的网络模型能够将图像的特征表征得足够好。可以通过设定一个容忍的识别率来获取认定阈值。这样只需将任意两张全景片输入网络得到特征向量,计算两者余弦相似度,当其相似度超过阈值时即为同一人。相比于人工的同一认定,速度会大大提高。
(3)测试方法
测试集中包含96 人,共294 张全景片。采用Top1/Top5 测试,对测试集中的数据进行划分。在每个样本中抽取一张全景片组成原型图像集合(gallary set){X},剩下的全景片作为测试图像集合(Prob set){X'}。对任意的一张全景片Xl'abel,同原型图像集合中所有的全景片进行相似度计算,并排序。在Top5 测试中,选取相似度最高的前五个全景片Xtop5= {X1th_label,X2th_label,X3th_label,X4th_label,X5th_label},若该集合与全景片Xl'abel中标签满足(i)th_label= =label(i=1,2,3, 4,5),则视为认定成功。Top1 同理。
2 实验结果
通过使用Grid-Cam 方法生成了神经网络的关注区域(图X)。可以看到,网络的重点关注区域是牙齿部分,这与人类医师的关注的重点区域是一致的。

图4 网络关注区域
在测试集上,全景片通过神经网络抽取特征后,取得特征向量,进行Top1/Top5 测试,Top1 准确率为80.30%,Top5 识别率85.86%。
3 结语
本次研究中,由于数据量的限制,并没有达到深度学习在人脸识别上的准确率。但是在2000 人左右的数据集上训练已经有了80.30%的识别率。但是深度学习具有良好的可扩展性,后续收集到更多的数据之后,可以通过迁移学习继续训练,能够不断的提高准确度。使用本方法,避免了人为设置特征的困难,也不会因为针对修复体设计产生修复体消失后无法匹配的情况。相比于传统的方法更不易失效,具有更强的鲁棒性。
可以预见,通过深度学习进行牙齿同一认定,有着极大的可能会替代传统方法,成为齿科身份识别的主流。并且随着数据的增多有着接近人工识别的潜力。对于本文中使用的深度学习模型,通过不断的迭代修改,还有着准确率进一步提升的可能性。
