基于x-vector 嵌入与BLSOM 模型的声纹聚类系统
2020-04-25项扬殷锋袁平
项扬,殷锋,袁平
(1.四川大学计算机学院,成都610065;2.西南民族大学计算机科学与技术学院,成都610041;3.重庆第二师范学院数学与信息工程学院,重庆400067)
0 引言
语音中包含有非常丰富的信息,除了语义信息外,还有一些“副语言”信息,例如说话人的性别、情感、语种以及说话人的身份。声纹识别又称为说话人识别,其任务为语音信号提取,表征语音信号中传达的身份信息并进行分类辨识。声纹识别是生物识别领域重要的验证手段,与其他生物特征相比,声纹具有语音获取方便,采集装置成本低廉使用简单,配合语音识别技术可防止录音假冒等特点[1]。在公安司法鉴定[2]、智能硬件、金融安全等领域有广阔的应用前景。
基于人工标注数据上的声纹识别模型进行监督训练面临一些挑战:人工添加标注代价非常高,对于标注者来说需要熟悉大量说话者的声音才能够进行准确标注,需要大量数据训练有监督模型。本文为无监督的声纹聚类系统。这种无监督的声纹聚类系统节省人力算力成本,可以用在说话人分割(Speaker Divarication)任务中区分录音中的说话者,实现“谁在什么时间段发言”的任务。
1 x-vector特征提取
1.1 语音信号预处理
使用时延神经网络(TDNN)模型将变长的说话者语音映射到固定维度的嵌入矢量(embeddings),称为x-vector。输入到x-vector 提取器关键神经网络TDNN结构的预处理矢量是帧长为25ms 的24 维Filter Banks,在3 秒的滑动窗口上进行均值归一化。不选用MFCC[3]是因为Filter Banks 语音特征相对于MFCC 经过较少的预处理加工,包含的语音信息更丰富。Filter Banks 处理流程如图1 所示。
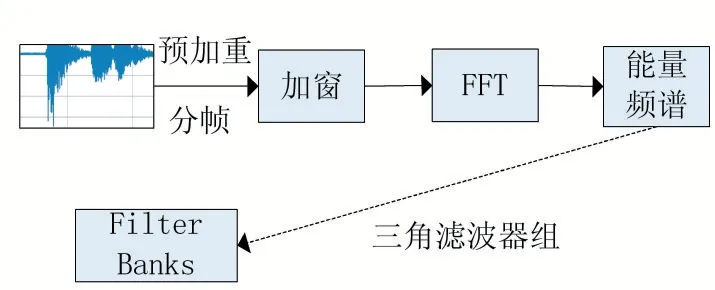
图1 Filter Banks处理流程图
预加重处理放大语音信号中的高频信号。语音信号频率会随时间变化,非常不平稳,对整个信号进行傅立叶变化会失真,为避免这种情况,可以假设语音在很短的时间内是一个较平稳的信号,因此我们需要对语音进行分帧,并且帧与帧之间应该有重叠的部分,这样做时为了让帧之间有一定的相关性,不会在应用窗口函数后丢失帧边缘的信息,通过串联相邻的帧来获得信号频率轮廓良好的近似值。窗口函数采用汉明窗口:

0 ≤n ≤N-1,N为窗口的长度
计算Filter Banks 最后一步是将三角滤波器(通常为40 个)应用于能量频谱,每个滤波器中心频率处响应为1。三角滤波器是建立在梅尔比例刻度(Mel-Scale)上的,梅尔刻度与频率刻度之间的转换可用如下公式:
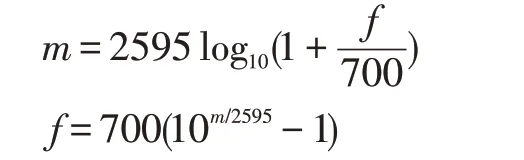
梅尔比例刻度的作用是模仿人耳对声音的感知,梅尔滤波器组的原理是人耳对较低频率比对较高频率更具判别力。
1.2 TDNN时延神经网络提取特征
为了充分挖掘时序数据时间上下文关系捕捉上下文的依赖关系,循环神经网络RNN[4]及其变体门控制神经网络GRU[5]和长短期记忆神经网络LSTM[6]被广泛使用,然而,由于RNN 算法的序列性结构训练速度较慢,Vijayaditya Peddinti 等人提出了带有子采样的时延神经网络TDNN,用于较长时间语音上下文的建模[7]。
在传统标准的DNN 中,DNN 仅对输入层的语音特征做了前后若干帧的扩展,在输入层拥有上下文信息,而TDNN 与DNN 不同之处在于TDNN 对隐藏层也进行了上下文的扩展,TDNN 会将隐藏层的当前时刻的输出与其前后若干时刻(可以指定)输出拼在一起,作为下一个隐藏层的输入。TDNN 的每一层被赋予了上下文时间的信息,这对时序数据处理是非常有效的。图2、图3 为传统DNN 与TDNN 的对比示意图。息重叠带来的效率问题。前五层在语音帧上操作,以当前帧t 为中心扩展上下文信息,例如第三层t-3,t,t+3 帧处的输入来源于第二层输出的叠接,而第二层的上下文信息来源于第一层,所以第三层总共包含了15 帧的上下文信息。经过TDNN 网络提取器,在segment6第六层非线性变换前被提取出x-vector 语音特征。图4 为x-vector 特征提取器的TDNN 网络结构图。

图2 传统DNN结构示意图
图3 时延神经网络TDNN结构示意图

表1 x-vector 中TDNN 神经网络结构配置
2 BLSOM算法分析
2.1 自组织特征映射神经网络(SOM)
自组织特征映射神经网络(SOM)是一种基于竞争机制的无监督神经网络算法,也被称为Kohonen 特征映射网络[8],该网络上所有节点都直接连接至输入向量,但网络上的节点彼此之间没有连接,节点之间不知道其“邻居”的值,根据给定输入更新其连接权重,自组织神经网络根据输入每次迭代进行更新组织网络地图。自组织特征映射神经网络能够对高维复杂数据聚类并且将其可视化在二维空间且保留输入之间的特征关系[9]。

图4 x-vector特征提取frame层
自组织特征映射神经网络有两层,第一层是输入层,第二层是输出层(特征映射层),与其他神经网络不同的是,SOM 在神经元中没有激活函数,直接将权值传递给输出层,SOM 中每个神经元都被赋予了一个与输入空间维数相同的权向量值。与其他神经网络不同,SOM 不是通过SGD 反向传播学习,而是通过竞争学习来调整神经元的权值。竞争学习有三个步骤:
(1)竞争阶段
计算网络每个神经元与输入数据之间的距离,距离最小的神经元将成为胜者BMU(Best Marching Unit),通常用欧几里德距离度量。
(2)合作阶段
在第三步(适应过程)中更新优胜神经元向量,同时它的“邻居”也会被更新。选取更新“邻居”的过程即为合作。使用邻域核函数hck=exp(-来选取“邻居”,该函数取决于两个因素:时间和空间,时间因素为每个新输入数据的时间增量值,空间因素为神经元到优胜神经元的距离。
其中dck是wc与wk之间的晶格距离(lattice distance),c表示优胜神经元,σ(t)为随时间递减的邻居半径,递减函数为σ(t)=σ0exp(-
(3)适应调整阶段
被步骤2 选择的神经元将会被更新,距离输入数据越近的神经元更新程度会更大,反之,距离输入数据越远的神经元更新程度会比较小。如图5 所示。
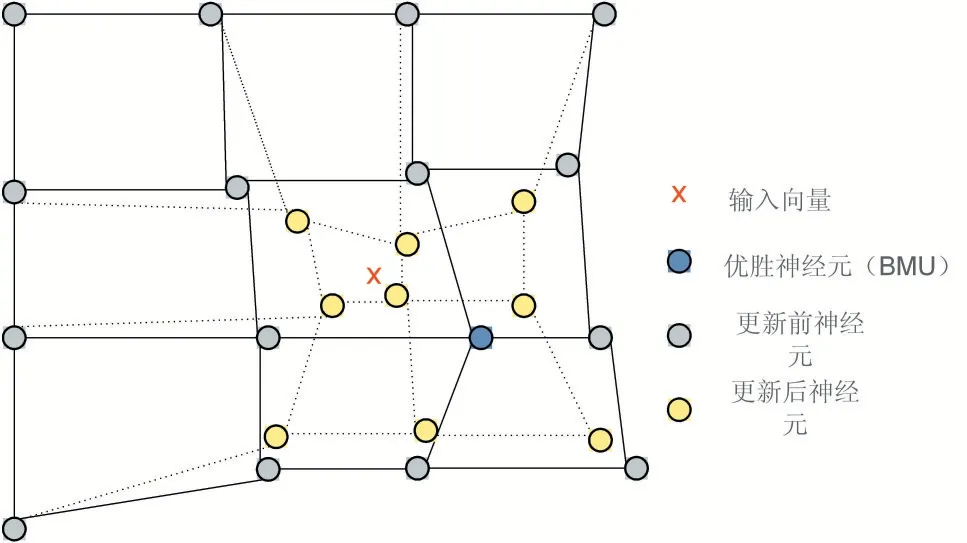
图5 适应调整阶段神经元示意图
优胜神经元和被选中的邻居神经元用如下公式进行更新:
wk(t+1)=wk(t)+α(t)∙hck(t)∙(x(t)-w (t))
其中α(t)为学习率(0<α(t)<1),学习率随着迭代的次数递减:α(t)=α0exp(-
完整的自组织特征神经网络算法如下:
输入向量x=[x1,x2,...,xn]
初始化网络全值向量,wk∈Rn,k=1,2,...,K t=0
for epoch=1 to Nepochsdo
for input=1 to Ninputsdo
t=t+1
for k=1 to K do
计算dk(t)=‖x(t)-wk(t)‖
end for
根据公式dc(t)=minkdk(t)计算出优胜神经元BMU 并挑选出邻居神经元
for k=1 to K do
更新wk
end for
end for
end for
2.2 BLSOM算法分析
在传统顺序SOM 算法中,根据一个输入向量找到优胜神经元就立即更新权重向量,然而会存在一些问题,如计算消耗大并且训练效果依赖于数据输入的顺序[10]。而在批处理自组织特征映射神经网络(Batch Learning Self Organized Map)更新网络神经元的时机延后至整个数据集输入后,因为网络权值不是在每一次输入时“即时”更新,所以BLSOM 权值的更新不依赖输入顺序,可以将其应用于基于相似度的学习分析算法中,BLSOM 初始网络映射权重可以基于主成分分析(PCA)得到,输入特征张量在权重增加前后不会有非常大的变化。
批处理自组织神经网络BLSOM 算法如下:
输入向量x=[x1,x2,...,xn]
初始化网络权值向量,wk∈Rn, k=1,2,...,K
t=0
for epoch=1 to Nepochsdo
赋予σ(t)新值,σ(t)=σ0exp(-
重置wk(tf)=分子与分母
for input=1 to Ninputsdo
t=t+1
for k=1 to K do
计算dk(t)=‖ x(t)-wk(t)‖
end for
使用公式dc(t)=mki n dk(t)计算优胜神经元(BMU)
并根据“邻居”挑选公式hck(t)=exp挑选出邻居神经元
for k=1 to K do
end for
end for
for k=1 to K do
使用公式wk(tf)=更新权重向量wk
end for
2.3系统设计及实验
本文中的实验在Ubuntu 16.04 的64 位操作系统上完成,硬件环境是中科曙光深度学习高性能服务器W780-G20(CPU:2 颗Intel E5-2620v4.2.1G 8.0OPI 20M 8C 85W,GPU 为8 块NVIDIA Tesla P40 24GE3x16 250W,内存:256G DDR4,硬盘:240G 2.5 6Gb R SSD)。
本实验采用自建语料库,使用Android 手机录制音频(16KHz,16-bit),录制环境为安静的室内环境,没有明显其他人说话声及噪音,共有30 人参与录制,15 位男性,15 位女性,录音人按照常规语速朗读录音内容,录音内容有中文也有英文,测试算法模型跨语言识别的性能。语料库被划分为训练集(80%)与测试集(20%),训练集用来训练分类模型,测试机用来检测模型效果。识别准确率accuracy=作为评价标准。经过训练模型,得到本声纹聚类算法在训练集的平均识别率及测试集平均识别率如表2 所示。
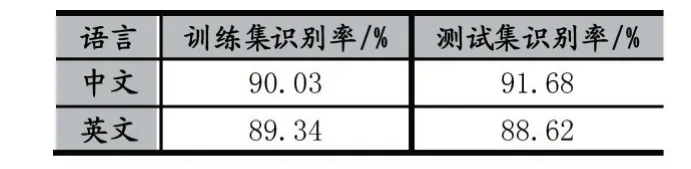
表2 不同语言语料库识别率
由表2 可以看出本文提出的基于x-vector 特征提取器与BLSOM 声纹聚类系统在中英文语料数据集上均有比较好的识别效果,模型具有较好的跨语言识别效果。
3 结语
无监督声纹识别系统,即基于不同说话人独特的声道构造所发出独一无二声音的识别分类,常被用于增强ASR 系统中的说话人自适应训练。传统方法是使用高斯混合模型(GMM)和隐马尔可夫模型(HMM)从语音记录中提取特征[11],本文中我们研究了时延神经网络模型TDNN,设计并采用基于TDNN 模型的x-vector 特征提取器有效提取出说话人语音中稳定有效发音的特征向量,选取批处理自组织特征映射神经网络BLSOM 训练x-vector 特征进行聚类识别,系统取得了较好的声纹聚类效果,具有一定的应用价值。本文在有噪声的环境条件下和语音特征增强等方面还有待改进提高准确率。
