基于支持向量机与XGboost 的成年人群肿瘤患病风险预测研究
2020-04-11马倩倩孙东旭石金铭何贤英翟运开
马倩倩,孙东旭,石金铭,何贤英,翟运开,3*
本文价值及局限性:
(1)肿瘤风险预测对于提高人群健康水平、降低患者经济负担意义重大。随着海量医疗健康大数据的产生,传统的统计学方法已无法满足数据分析需求,部分学者开始尝试将支持向量机等机器学习算法进行数据挖掘。但尚未见支持向量机、XGboost 等算法应用于预测个体肿瘤发生风险。
(2)本文创新性地将支持向量机、XGboost 等算法应用在肿瘤风险预测领域,搭建的肿瘤患病风险预测模型表现出较高的预测正确率及稳健性,可以提前给予肿瘤风险预警,从而可根据风险指标开展精准健康干预,为肿瘤预防提供一定的临床指导和帮助。
(3)本研究有一定局限性,例如进入模型的特征依然不够全面,未包含生化指标、环境指标、饮食摄入情况等因素;支持向量机模型中核函数的选择中,仅采用了常用的径向基核函数,未考虑多项式核函数等其他不同核函数向量分类器并进行对比,可进一步深入研究。
肿瘤是危害人类健康的重要问题之一,2015 年中国恶性肿瘤发病率约285.83/10 万,死亡率约为 170.05/10 万,恶性肿瘤发病率、死亡率近十几年来分别保持3.9%、2.5%的增幅[1],疾病负担呈持续上升趋势。肿瘤的防控对于节约医疗资源、降低医疗开支、提高人群健康水平意义重大。肿瘤受生活方式、环境、基因等多种因素的影响,对于其患病风险的精准预测涉及庞大的数据量和数据特征,尤其随着海量医疗健康大数据的产生,传统的统计学方法已无法满足数据分析需求,部分学者开始尝试采用支持向量机等机器学习算法进行数据挖掘[2-4]。目前尚未见支持向量机、XGboost 等算法应用在肿瘤风险预测领域中的研究。因此,本文旨在探索支持向量机和XGboost 于肿瘤风险预测的应用价值。
1 资料与方法
1.1 一般资料 本研究时间为2011—2015 年,数据来源于中国健康与营养调查(CHNS)[5],其是北卡罗来纳大学教堂山分校(University of North Carolina at Chapel Hill)的卡罗来纳州人口中心(Carolina Population Center)与中国疾病防控中心的国家营养与食品安全研究所共同开展的国际合作项目。该调查是一个持续开放的队列,采用多阶段分层整群随机抽样法,共得到约4 400 个家庭住户、26 000 个个人样本,覆盖了在地理位置、经济发展、公共资源和卫生指标均存在巨大差异的黑龙江、辽宁、湖南、山东、贵州、江苏、广西、湖北、河南、北京、上海和重庆12 个地区,是一个少见的、信息含量丰富的、具有全国代表性的数据。本文选用其中成年人调查表所得数据,筛选出患肿瘤可能的影响因素(见表1)[5]。以我国12 个地区城乡成年(≥18 岁)常住居民为对象,经过数据清理,合并2011 年与2015 年数据[5],剔除重复记录数据,最终纳入分析的对象有19 410 例,其中男9 371 例(48.28%),女10 039 例(51.72%)。
1.2 数据处理 剔除是否患肿瘤(U24W:医生给你下过肿瘤的诊断吗?)等关键变量存在缺失记录及重复的记录,并采用随机森林算法填补缺失数据。以是否患肿瘤为因变量,分别随机抽取2/3 样本作为训练集,剩余1/3 样本作为测试集评估各模型表现。
1.3 方法 基于逐步Logistic回归分析的变量筛选策略,在训练集上分别建立逐步Logistic 回归、支持向量机、XGboost 肿瘤患病风险预测模型,并在测试集上进行 验证。
1.3.1 逐步Logistic 回归分析 在训练数据集中,以成年人群是否患肿瘤为因变量,以表1 中除因变量外所有变量为自变量进行初始逐步Logistic 回归分析,利用R软件中step 函数,基于赤池信息量准则(AIC)越小模型更优原则逐步进行变量筛选。
1.3.2 支持向量机 支持向量机是由VAPNIK[6]于1997 年提出的,是一种线性和非线性分类方法,其基本思想是利用适当的核函数将待分类数据映射到具有一定容错条件的更高维特征空间,通过在此空间构建最优的分类超平面将数据分类。支持变量为确定最佳分类超平面时附近距离最近的样本点。支持向量机适用于小样本、非线性、高维数据分类问题,具有预测可靠性高、稳定性强、泛化能力强等特点。支持向量机主要的参数有用于控制错误分类惩罚程度的正则化参数C 与控制样本间距离尺度的径向基核函数半径的倒数γ,此处采用常用的径向基核函数。
1.3.3 XGboost 算法 XGboost 由陈天奇教授于2016 年提出,是一种基于迭代决策树模型的集成学习算法[7]。作为Boosting 算法中的一种,其基本思想是集成众多弱分类器形成强分类器。该算法最大的特点在于多线程计算,并利用正则化提升技术减少过度拟合,从而保证模型的鲁棒性。同时可自定义损失函数、稀疏特征的处理、允许缺失值等,具有灵活、计算速度快、不易受异常值干扰、稳健性好的优势。
1.4 统计分析与软件 采用RStudio1.1.456 建模与评价,分别采用e1071 程序包、XGboost 程序包建立支持向量机和XGboost。训练集进行逐步Logistic 回归分析时,采用stepwise 方法对模型特征进行筛选;XGboost 与支持向量机利用网格搜索方法进行调参,将训练集作为原始数据,利用K 折交叉验证法(K-CV),本文K=10,找到交叉验证精度与正确率最高误差最小的最优参数组合。以逐步Logistic 回归为对照,由受试者工作特征(ROC)曲线下面积(AUC)判断各模型优劣,使用pROC 程序包中roc.test 函数,利用DeLong 检验比较各模型AUC 的差异,以比较各模型的性能。双侧检验水准α=0.05。
2 结果
2.1 一般资料 19 410 例研究对象中,被诊断为肿瘤患者262 例(1.35%)。训练集(n=12 919)中含有174例肿瘤患者,测试集(n=6 491)含有88 例肿瘤患者。
2.2 逐步Logistic 回归分析 基于AIC 逐步进行变量筛选,最终得到逐步Logistic 回归分析结果(见表2)。逐步Logistic 回归分析在训练集上的拟合值与真实值相比,其预测成年人群患肿瘤的正确率为73.28%〔95%CI(72.51%,74.04%)〕,灵敏度为68.97%,特异度为73.34%。

表 1 变量赋值说明Table 1 The description of variables

表2 成年人群是否患肿瘤的多因素逐步Logistic 回归分析结果Table 2 Stepwise multivariate Logistic regression analysis of variables possibly associated with cancer in adult population
2.3 支持向量机 以成年人群是否患肿瘤为因变量(赋值:0=否,1=是),以逐步Logistic 回归分析筛选出的变量作为自变量(赋值同表1),在训练集上建立支持向量机,利用tune.svm()函数,通过网格搜索方法,循环遍历,尝试各种参数组合以寻找最优的参数,C与γ 初始取值范围皆为[0.01,0.1,1,10,100]。10 折交叉验证错误率最低时的最优参数为C=100、γ=0.01,此时训练径向支持向量机预测成年人群患肿瘤的正确率、灵敏度、特异度均为100.00%。
2.4 XGboost 算 法 使 用Caret 包 中train() 函 数的网格搜索法进行参数调优,选取模型预测正确率更高的参数组合,最终确定学习率η=0.3,树深度max_depth=1,nrounds=150,gamma=0,colsample_bytree=0.6,min_child_weight=2,subsample=1,scale_pos_weight=1,此时在训练集上预测成年人群患肿瘤的正确率为69.78%〔95%CI(68.98%,70.57%)〕,灵敏度为78.16%,特异度为69.67%,变量重要性评分见图1。
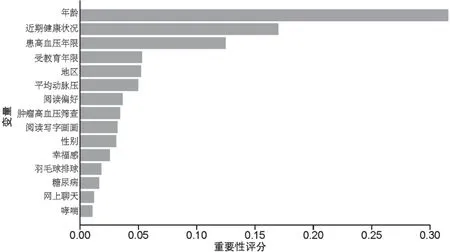
图1 基于XGboost 算法得出的变量重要性评价(前15 个)Figure 1 Variable importance evaluation based on XGboost algorithm(top 15)
2.5 模型对比 以上3 个模型其实是二值分类器,在测试集上验证其预测性能。由ROC 曲线可知,支持向量机预测成年人群患肿瘤的AUC 最大,为86.32%〔95%CI(81.64%,91.00%)〕,且正确率最高,为99.54%〔95%CI(99.34%,99.69%)〕。 经DeLong 检验,支持向量机、XGboost 预测成年人群患肿瘤的AUC与Logistic 回归模型比较,差异有统计学意义(Z 值分别为-2.519、-2.138,P 值分别为0.012、0.032);XGboost 预测成年人群患肿瘤的AUC 低于支持向量机,差异有统计学意义(Z=2.081,P=0.037,见表3、图2)。
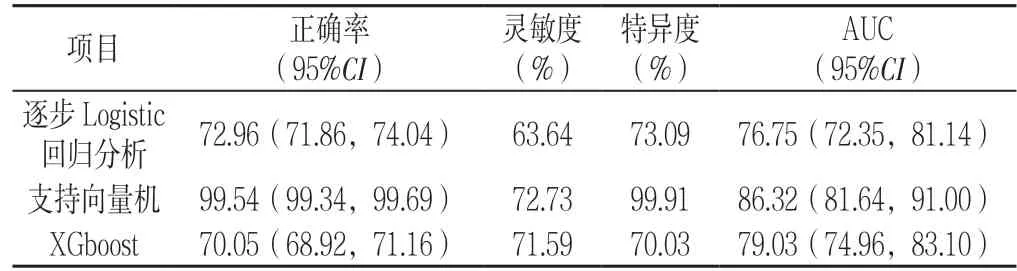
表3 支持向量机、XGboost、逐步Logistic 回归分析预测成年人群患肿瘤的正确率、灵敏度、特异度、AUCTable 3 Accuracies,sensitivities,specificities,AUCs of SVM,XGboost and SLR for cancer of prediction in adult population
3 讨论
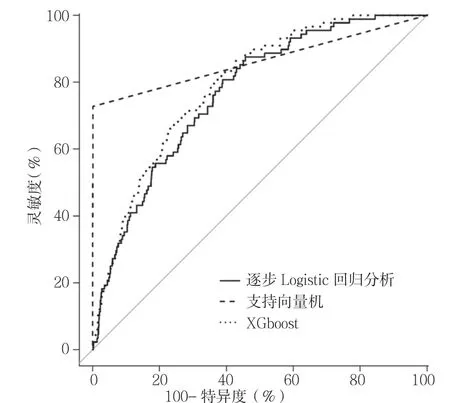
图2 支持向量机、XGboost、逐步Logistic 回归分析预测成年人群患肿瘤的ROC 曲线Figure 2 ROC curves of SVM,XGboost and SLR for cancer of prediction in adult population
随着生活节奏的加速、生活方式的改变,我国罹患各类肿瘤的患者数量不断增加[8]。通过特定的模型预测个体肿瘤发生风险,可及早发现肿瘤患病高危人群,对高危人群实施干预措施,从而提高人群健康水平。本文分别采用逐步Logistic 回归分析、XGboost 与支持向量机建立肿瘤风险预测模型,结果显示,在测试集上,支持向量机模型在预测成年人群患肿瘤的正确率、灵敏度、AUC 等性能指标上优于其他两者,虽然XGboost 预测成年人群患肿瘤的AUC 大于逐步Logistic 回归分析,但未见其预测成年人群患肿瘤的正确率明显提升。
传统Logistic 回归分析适用范围广,应用灵活。对于特定的问题,其性能等效甚至优于某些相对复杂的机器学习算法,如在肝硬化患者上消化道出血预后评估的研究中,Logistic 回归模型的正确率为81.5%,高于决策树模型(75.1%)[9]。赵子龙等[4]在判别乳腺病变性质领域发现,传统Logistic 回归模型与随机森林、支持向量机等机器学习算法建立的诊断模型相比较,预测效果不存在明显差异。但有研究表明,Logistic 回归分析在交互作用方面的处理效果不如决策树和随机森林模型[10]。
机器学习在医疗行业领域的应用发展迅速,支持向量机是机器学习中常用算法,由于其强大的学习功能,已在医学领域得到广泛应用[2-3,11-12]。VIJAYARAJESWARI 等[3]利用Hough 变换提取乳腺钼靶图像特征,并利用支持向量机对其进行分类,用于发现异常检查结果,实现乳腺癌早期筛查。KAUR 等[12]分别利用支持向量机、K 近邻法(KNN)、线性判别分析(LDA)和决策树模型建立图像识别乳腺癌的多分类诊断模型(正常、良性、恶性)。BATTINENI 等[11]通过建立支持向量机模型分析373 个MRI 数据预测痴呆,发现低γ 高正则项系数(γ=0.000 1,C=100)模型表现出更好的性能,正确率和精确度分别达68.75%、64.18%。
近年部分学者将XGboost 算法应用于健康预测领域。在预测ICU 脓毒症患者住院死亡风险的研究中,XGboost 的AUC 为0.836〔95%CI(0.819,0.853)〕,优于支持向量机模型和SAPS-Ⅱ模型,可以有效地辅助临床医生开展ICU 脓毒症患者死亡风险预测,进而提前采取合理的临床干预措施[13]。张洪侠等[14]基于XGboost 算法建立2 型糖尿病精准预测模型,预测正确率达96.6%,并发现血糖、三酰甘油、SLC30A8 基因等是模型中重要性排序靠前的影响因素。XGboost 独特的优势之一在于可以得到每个因素的重要性得分,对于肿瘤患病危险因素的分析具有指导意义。XGboost 具有高度灵活性,但这也增加了模型调参的复杂度。
另外,不少学者开始尝试将其他机器学习算法应用于健康风险预测、疾病诊断[9,15-16]。有学者发现,随机森林算法对体检人群的糖尿病风险预测具有较高效能,但多因素Logistic 回归分析具有更直观的解释性[16]。张英男等[17]通过随机森林算法预测阿尔茨海默患病风险,具有较高的精确度及稳定性,并能输出对患病影响程度较大的因素。王喜丹等[18]在糖尿病患病风险预测中发现,采用深度信念网络(DBN)的模型预测正确率比基于反向传播神经网络的预测正确率更高、更准确(93.10%与89.66%)。
综上所述,用于分类预测的机器学习方法很多,不同方法间的优劣取决于具体问题与数据情况。模型的最终选择需结合模型的预测能力、可解释性、计算能力、运行效率等多个方面综合考虑[4]。支持向量机可以使用核函数对高度非线性数据进行分类,但其可解释性较差,无法有效地进行自变量筛选,常与其他方法结合使用。本文XGboost 与逐步Logistic 回归预测成年人群患肿瘤的效果近似,但考虑到Logistic 回归分析具有操作便捷、适用性广和可解释性强的特点,建议在肿瘤风险预测方面,采用支持向量机与Logistic 回归分析相结合的模式,综合得到预测能力更强的模型。
本研究搭建的肿瘤患病风险预测模型表现出较高的预测正确率及稳健性,可以提前给予肿瘤风险预警,从而可根据风险指标开展精准健康干预,为肿瘤预防提供一定的临床指导和帮助。但本研究也有一定局限性,例如进入模型的特征未包含生化指标、环境指标、饮食摄入情况等因素;侯玉梅等[19]在2 型糖尿病非线性样本预测时发现,基于多项式核函数比基于径向基核函数的支持向量机分类正确率更高,而本文采用了常用的径向基核函数,未进一步深入考虑不同核函数向量分类器。在大数据的背景下,利用数据挖掘处理海量多源健康数据,建立预测效能高、训练速度快的模型是医疗领域的重要方向。
志谢:本研究采用中国健康与营养调查(CHNS)数据,感谢国家营养与健康研究所、中国疾病预防控制中心、美国卡罗来纳州人口中心和北卡罗来纳大学教堂山分校等对CHNS 数据的收集和财务的支持。
作者贡献:马倩倩、翟运开进行文章的构思与设计,文章的可行性分析;马倩倩、孙东旭进行数据收集、整理、统计学分析与论文撰写;石金铭、何贤英、翟运开负责论文的修订,以及文章的质量控制及审校。
本文无利益冲突。
