基于FWGKNN算法的个人违约率的应用
2020-04-08葛传明
葛传明
(安徽工业大学管理科学与工程学院,安徽 243002)
0 引言
随着中国制造2025的出台,信息技术中大数据与云计算越来越受到各方重视,其中创新性的机器学习算法依然是未来信息技术突破的关键。面对复杂繁多的海量数据,如何快速、准确地处理数据将成为未来数据管理方向的主流。现如今,信用风险是商业贷款风险的主要来源,也是银行和和其他金融机构严格监管和政策辩论的主题,它通常被定义为债务人未能按时履行还款所造成的风险损失[1]。精确地评估信用风险是所有金融机构贷款人关心的问题。解决这个具有挑战性的问题,构建信用风险模型是一个常见的适用方式[2,3]。银行或者其他贷款机构通常构建模型来评估信用风险。在信用风险模型的构建中违约率(PD)是一种主要的评测指标,用于估算债务人在即将到来的一年违约的可能性以及因此而造成的损失。评估PD的主要目的是为了对特定债务人的信用质量做一个全面的了解[4]。个人违约概率可以根据一系列的因素来计算如债务比率、月收入、借款人年龄等。然而,个人信用数据是一个庞大而复杂的数据量,如何根据这些复杂多样的数据来计算出个人违约率是估算个人信用的关键一步。
PD的传统评价方法都集中在使用技术方面,如判别分析和线性回归来区分贷款申请人属于两类之一,即好的和坏的信贷风险。之前国内外的研究中使用了很多方法来计算违约率。Wiginton率先提出了使用逻辑回归来对PD进行计算,目前已经被成功的应用[5,6]。尽管这些技术能够获得不错的效果,但是他们忽略数据缺失可能造成的影响,数据缺失可能由很多因素造成,包括调查无应答、受访者拒绝回答某些项目的问卷以及数据本身的损失[7]。一般来说,相关特征值的缺失可以严重影响分类的性能,在这方面为了准确地计算违约率,填补缺失数据是一个实际可行的方法。现有文献提出了很多用机器学习方法来估算缺失的属性值,如最大期望算法(EM)、决策树归纳法、贝叶斯方法以及多只填补等。
目前在各种机器学习算法中用来解决数据缺失填补最流行的就是K近邻(KNN)算法,因为它实现起来比较简单且能获得较高的精度。该算法最初由Cover和Hard提出,是一个标准的非参数化方法主要用于概率密度函数估计和分类[8]。在此基础上,Kim等人提出了一种新的基于集群的填补方法称为壳近邻(SKNN)算法。该方法按顺序来填补实例中的缺失值,并使用填补后数值来估算下一个缺失值[9]。为了提高填补的性能,各种使用欧氏距离或其变体KNN改进算法被提出来。在最近的研究中,已被实验证明了比欧氏距离或其他距离方法更适合捕获“近似”值(两个实例间的距离或关系)的灰色关联分析法(GRA)已经被用来描述所有实例之间的关系结构[10]。例如,李汉明提出了一个基于灰色关联分析的最近邻(GBNN)方法[11]。张师超提出了基于灰色关联分析的最近邻(GKNN)迭代填补方法已广泛应用于缺失数据的填补[10]。然而,在衡量特征属性之间的关系时,现有的基于灰色关联分析的最近邻填补方法基本都是将所有特征属性同等对待。这些研究忽略了一个至关重要的问题:随机特性之间的相关性对特征属性之间相似性度量有着显著影响,这可能导致偏见进而对最近邻的选择产生误差影响。
本文为了更精确的计算个人违约率引用一种特征权重灰色K近邻(FWGKNN)的新算法来填补信用数据的缺失[12]。计算过程中,使用多元非线性回归来拟合各变量和违约率之间的非线性参数方程。首先,通过FWGKNN算法将不完整训练集中的缺失数据填补完整;其次,使用多元非线性回归方法分别求得基于原始不完整训练集和填补后的完整训练集的参数方程;然后,通过上述求得的两个参数方程分别使用相应的数据集求出两个违约率;最后使用均方根误差(RMSE)和误差降低率(ERR)来评估预测的各方法的准确性。实验中,使用了某竞赛组织提供的10000个借款人的信用信息,并且为了验证该方法的性能,分别使用均值/模式填补法(Mean/mode imputation)、模糊 K-means聚类填补法(FKMI)以及基于灰色关联分析的最近邻迭代填补法(GKNN)来对实验进行比较分析[10,11]。
本文主要框架如下:第二部分介绍了违约率PD的计算方法;第三部分描述了详细的实验设计;第四部分主要是实验结果分析与讨论;第五部分是结论。
1 违约率PD的计算
在本节中,主要介绍使用FWGKNN算法对缺失数据进行填补以及使用多元非线性回归拟合各变量与违约率PD之间参数方程。
1.1 FW W G G K K N N N N 算法
FWGKNN算法主要是在互信息和灰色关联分析理论的基础上设计的,该方法通过考虑缺失特征属性和其他特征属性之间的关系来选择K个最近邻。设实例数据集为T,T={X1,X2,…,Xn},每一条实例有m个特征属性,设为为特征类集合并且Xci代表特征类C中第i条实例。假设第X条实例的第j个属性是未知的,在计算X实例和其他实例的灰色关联度(GRG)之后,实例X的K近邻就为,V是根据灰色关联度的大小降序排列的。k进而可以通过平均值规则求出未知值MVj:

该方法一个非常重要的改进是根据实例间的灰色关联度来计算每一个邻居的相应权重。如果缺失数据是数值型数据,设每一个邻居的权重为wk,最近邻MVj:

这里
其中使用互信息来确定随机变量之间的关系,互信息(MI)的数学表达式如下:
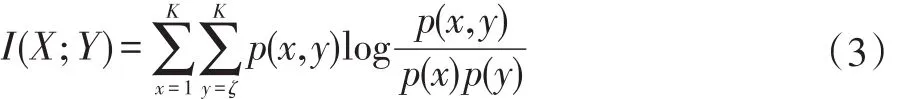
对于连续随机变量,其熵值和互信息(MI)表达式如下:
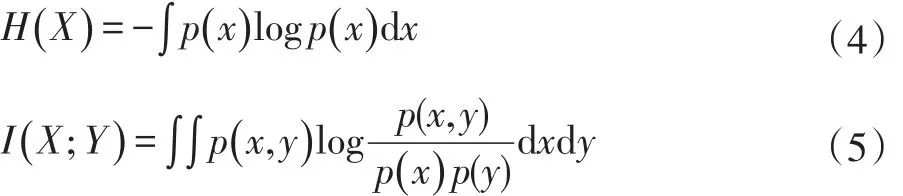
这里熵值和互信息需要满足如下条件:

FWGKNN算法利用了灰色关联分析理论,其表达式如下:
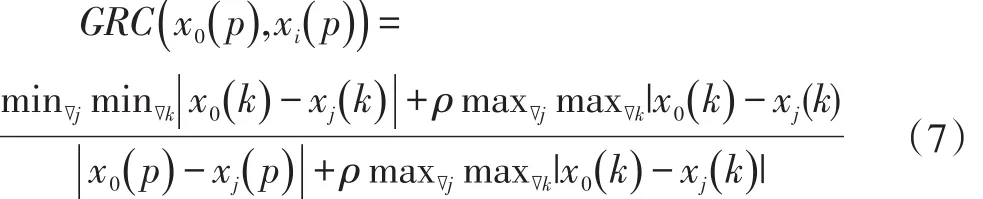
基于互信息理论,我们提出了灰色关联度(GRG):
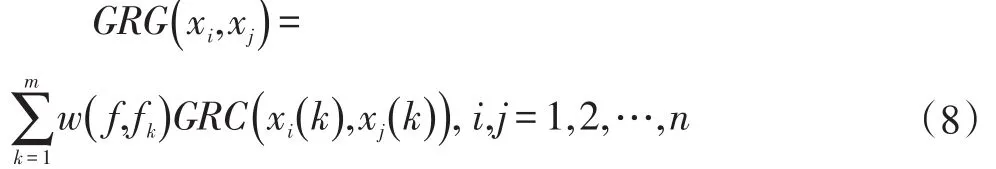
1.2 多元非线性回归计算P P D D的基本理论
非线性回归是一种统计方法,用来帮助描述非线性关系,并根据实验数据做出预测。非线性回归模型通常设定一些参数,模型被描述为一个非线性方程。参数化非线性回归模型是结合非线性参数来描述一个或多个自变量和因变量之间的函数关系,模型可以是单变量的也可以是多变量的。模型所使用函数可以是指数型、三角变量型、幂函数型或其他类型的非线性函数,通常使用迭代算法来确定非线性参数的估计,简化公式表示如下:

这里,x是自变量(Xi,i=1,2,…,10),y是因变量(PD),β是非线性参数估计,ε是误差因子。
11..33违约率计算的算法设计
本小节主要包含两部分:算法1步骤和算法2步骤。
算法1步骤:FWGKNN算法填补缺失数据。
输入:
T:n×m维不完整数据集
输出:
T^:n×m维完整数据集
1):使用最小最大化规则对数据集T进行预处理
2):根据特征类集合D对每个实例Xi进行分类
4):对数据集T中的每一个特征属性,如果是数值型属性则使用均值法(mean)来预测缺失值;如果是分类属性则使用模式识别法(mode)来预测缺失值
6):对每一个特征类C,假设数据集中某一实例的第一个缺失值已被填补好,余下的填补数据将会作为已知值。根据公式(8)带有缺失值实例与其他完整实例间的灰色关联度GRG,并按降序排列
8):根据公式(2)每一个邻居的权重,然后使用权重最高的邻居代替缺失值
9):将填补后的数据当作已知值去预测下一个缺失值。重复步骤6)-8)直到所有的缺失值都被填补完成
10):重复步骤6)-9)直到迭代时间到达N
算法2步骤:多元非线性回归计算违约率。
输入:
T^:n×m维完整数据集
T:n×m维不完整数据集
输出:
违约率(PDs)
1):使用最小最大化规则对数据集T进行预处理
2):随机将数据集T分拆为训练集T1和测试集T2
3):根据多元非线性回归方法分别使用原始不完整训练集T1和填补后的完整训练集T1*得到两个参数方程y0和y1
4):根据参数方程y0使用原始不完整测试集T2计算出违约率PD1
5):根据参数方程y1使用填补后的完整测试集T2*计算出违约率PD2
2 实验设计
2.1 数据集
本文所采用的原始数据集T由竞赛组织所提供,包括10000个借款人的信用信息。为了方便对实验进行分析,我们随机地将数据集进行分拆,其中2/3为训练集T1,1/3为测试集T2。
表1列出了数据集中所包括的变量:因变量(Y)和自变量(X1,X2,… ,X10)。
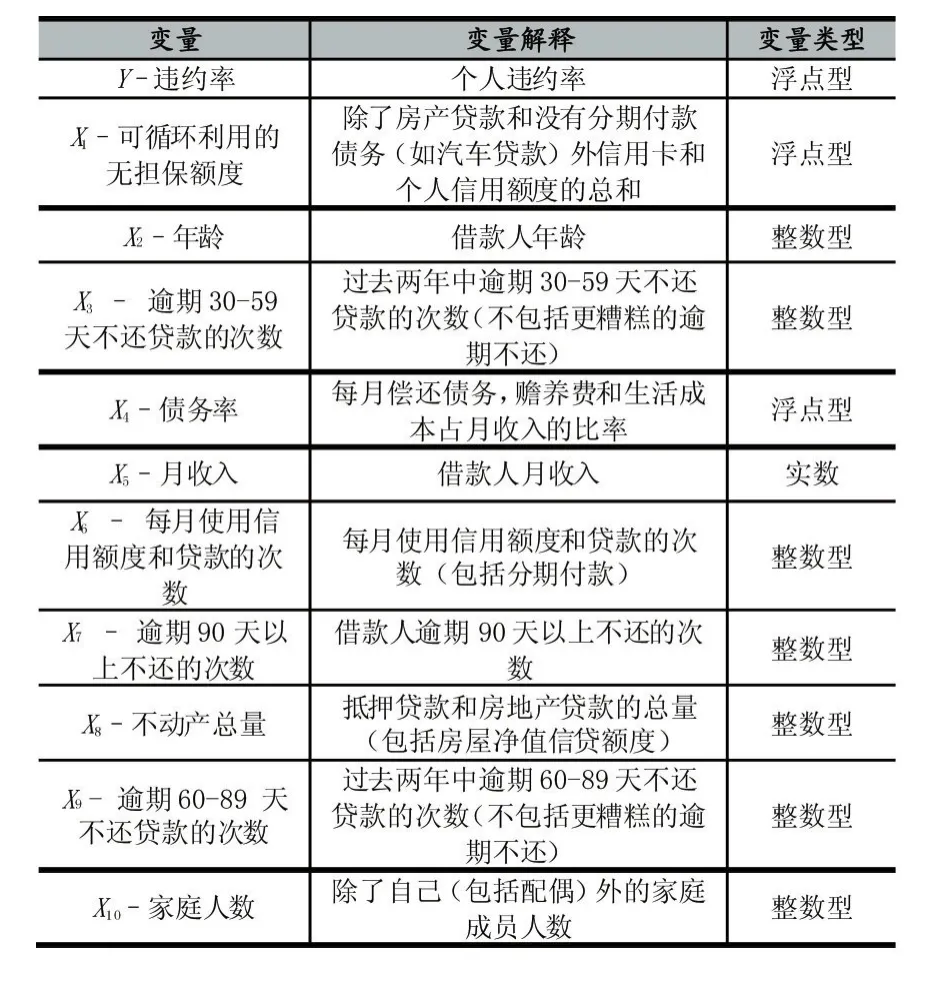
表1数据集描述
2.2 比较方法和评测指标
本节主要介绍实验对比所使用的比较方法以及各方法的评测指标。
为了方便对实验结果进行分析比较,这里我们使用4种方法作为对比:均值/模式填补法(Mean/mode imputation)、模糊 K-means聚类填补法(FKMI)、基于灰色关联分析的最近邻迭代填补法(GKNN)以及不使用任何填补法(Not imputed)。
为了准确评测各方法的填补预测效果,本文主要使用两种评测指标来对实验结果进行评测:均方根误差(RMSE)和误差降低率(ERR)

这里ei表示真实值,表示填补后的缺失值,m表示缺失值的个数。

这里error0表示根据违约率PD1和真实违约率PD计算出的RMSE,error1表示根据违约率PD2和真实违约率PD计算出的RMSE。
3 实验结果及分析
本次实验在Windows平台上运行,使用MATLAB编程语言,相关机器配置是AMD6380(2.50GHz)处理器,8GBRAM。整个实验所用时间为160.05秒。
3.1 实验结果比较分析
为了测试FWGKNN算法对违约率预测的精度,我们对各方法的实验结果进行分析比较。表2和表3分别提供了带有缺失值(X5和X10)的个人信用信息实例被填补后的结果。
实验中,我们分别根据原始不完整数据集和填补后的完整数据集求出各自相应的参数方程y0(x,β)和y1(x,β)。其他对比方法求得参数方程为y2(x,β),y3(x,β)和y4(x,β)。参数方程的特征表达式如下:

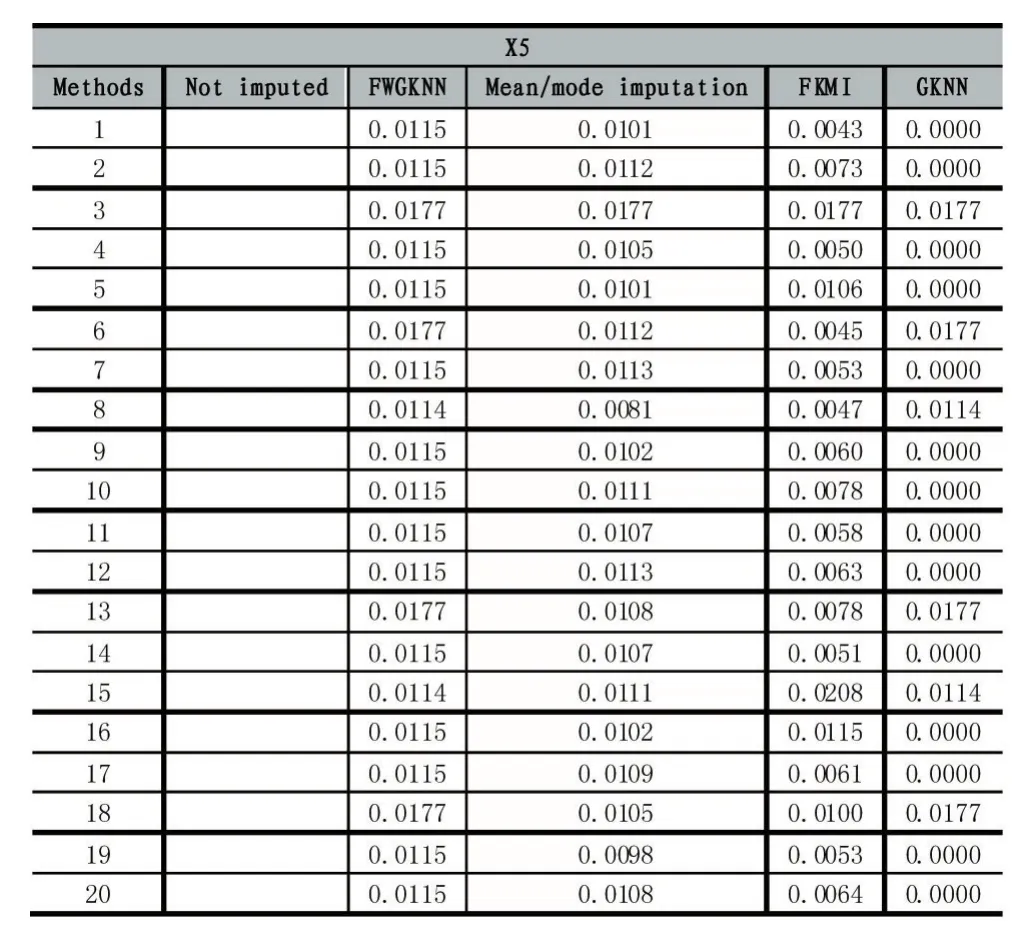
表2缺失属性X5的个人信用信息实例及各方法的填补结果
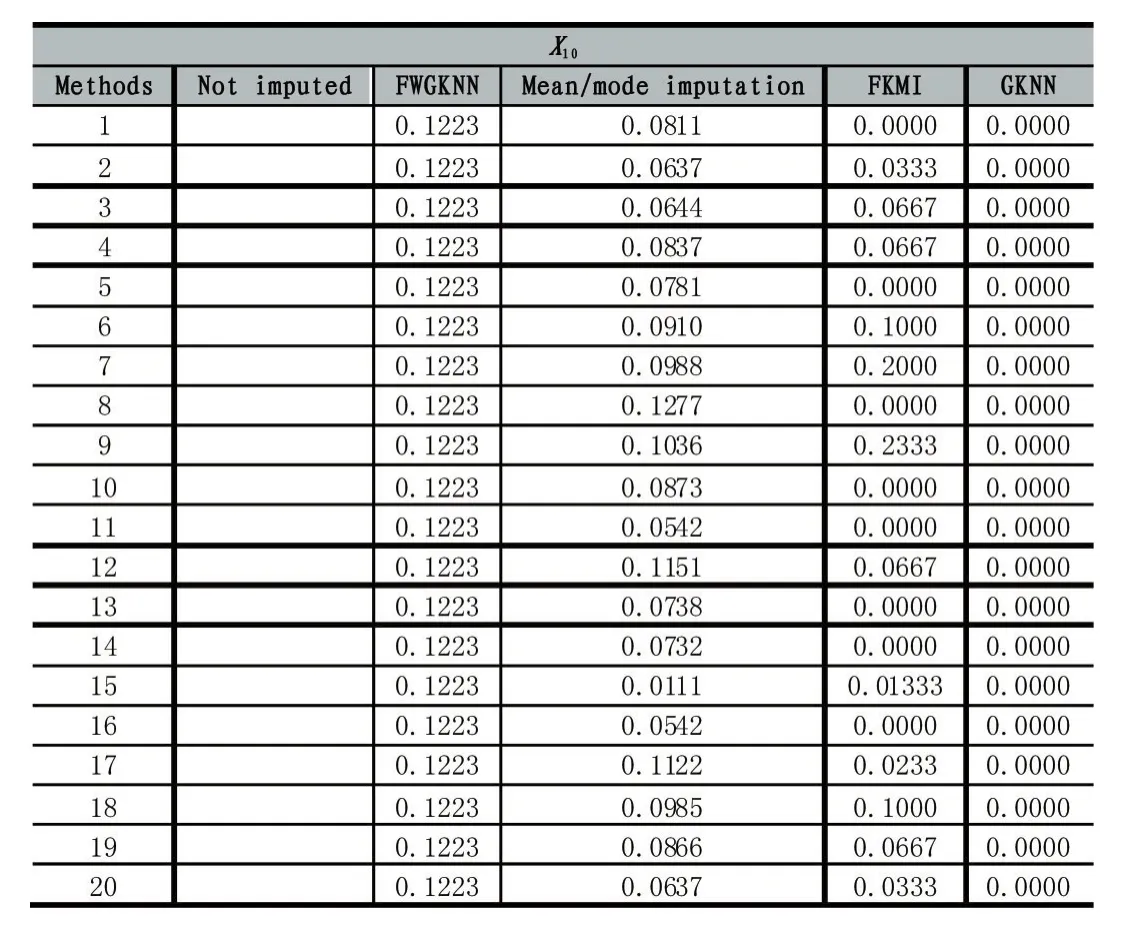
表3缺失属性X10的个人信用信息实例及各方法的填补结果
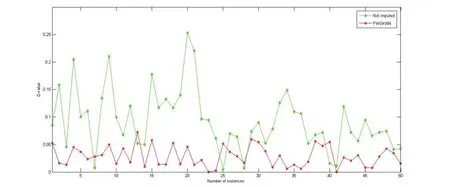
图1 FWGKNN算法和未填补方法求得预测值的差值(D-value)对比
β4=(0.8377,-0.1024,4.1070,0.0261,-0.0606,-0.0262,3.2253,0.0151,-6.9358,0.0499)
ε4=0.0944
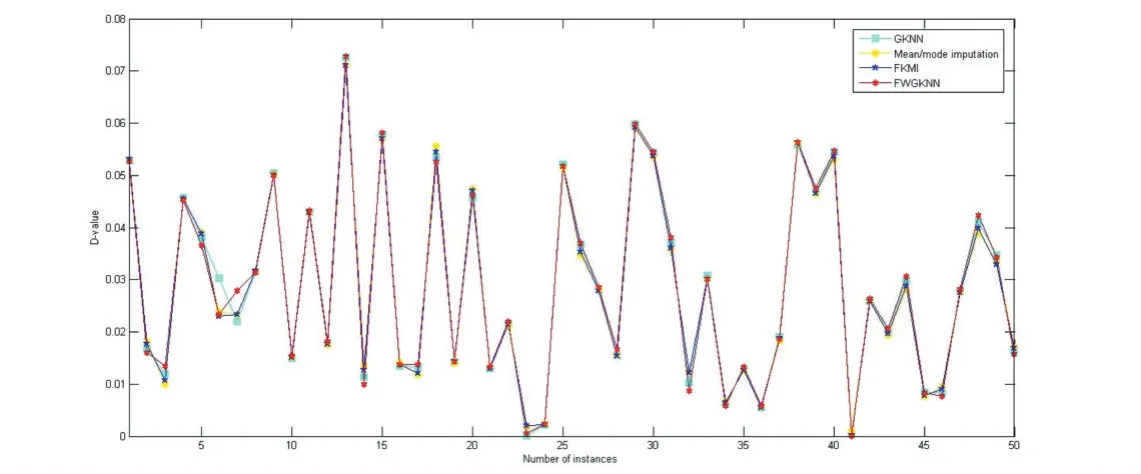
图2各方法间求得预测值的差值(D-value)对比
实验中使用的观测指标是目标值和真实值之间的差值(D-value),差值越小说明填补效果越好。图1展示了实际值和FGWKNN算法所得结果的比较,其中X轴表示测试集中实例的个数,Y轴表示目标值与真实值之间的差值(D-value)。从图1中我们可以看出,使用FWGKNN算法求得的差值比未填补方法得到的差值要小很多,这是因为在计算违约率PD时,考虑特征属性间的相关性来选择最近邻要更好。从图2中也可以看出相似的结果,FWGKNN算法所求得的差值也要比其他填补方法求得结果要小。
图3展示4种方法使用测试集数据的多项式曲线拟合效果,从图中可以看出使用不同方法求得的预测值和实际值之间的变化趋势。
3.2 各方法的精度比较
为了更形象的描述实验结果,我们使用均方根误差(RMSE)和误差降低率(ERR)来违约率计算的预测精度。分析结果表4以及图4和图5所示。
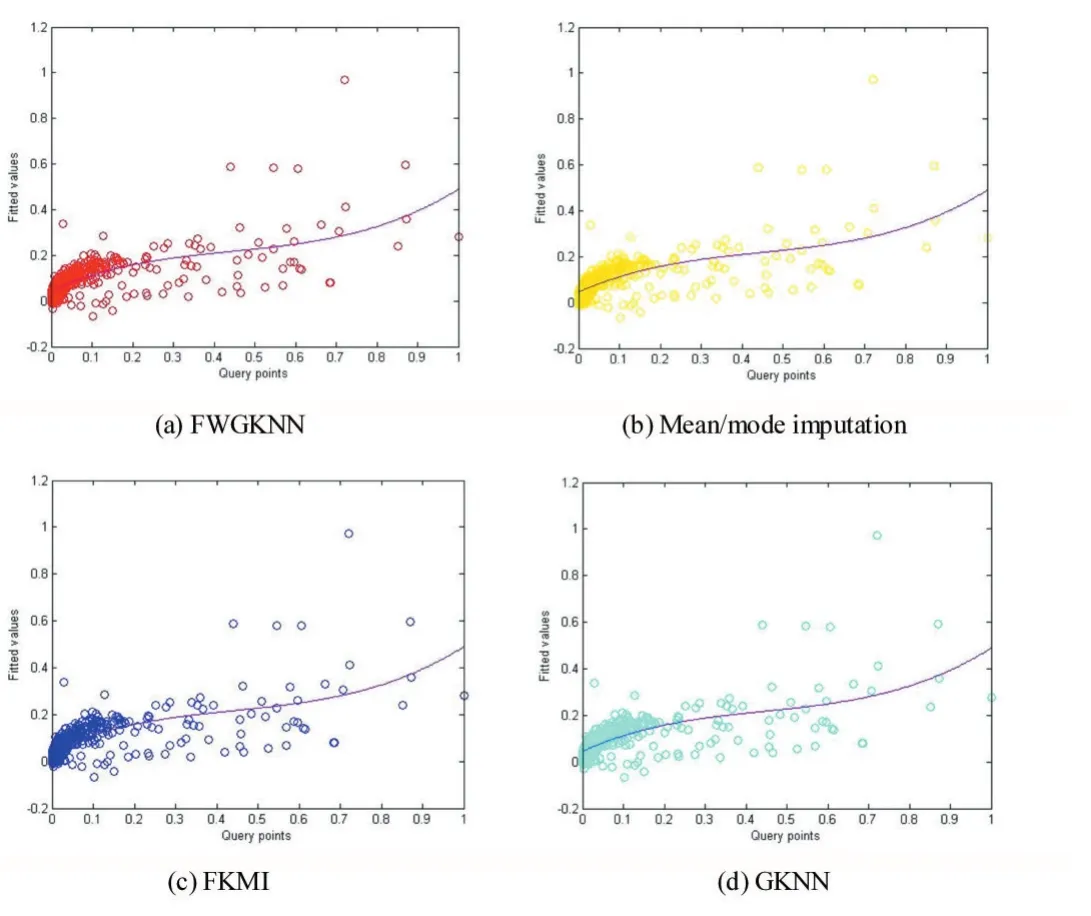
图3多项式曲线拟合
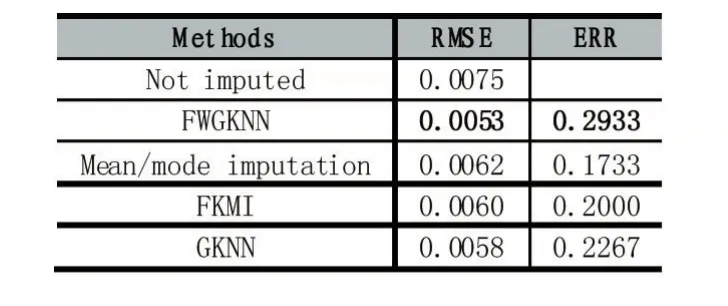
表4
各实验方法的RMSE和ERR。
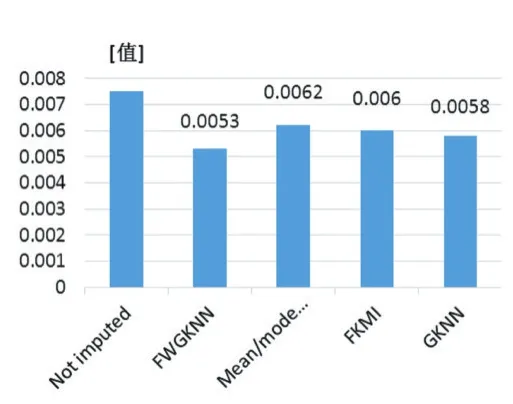
图4各实验方法的RMSE
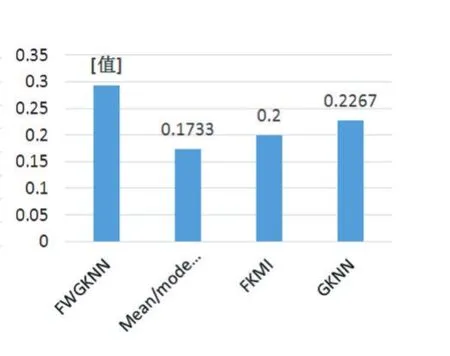
图5各实验方法的ERR
从表4和图4中可以清晰地看出,使用FWGKNN能够得到更好的实验结果:RMSE=0.0053,它远远小于不适用任何方法得到的结果。同时,与其他填补方法相比,其结果也要优越很多,且有着更高的ERR。
4 结语
本文引用一种新算法FWGKNN来计算个人信贷的违约率,该方法主要是基于互信息和灰色关联分析法来实现的。通过一系列的对比实验及分析可知,该方法能够对缺失值进行更好地填补,进而能够对违约率进行更加准确的预测。因此,使用这种方法,当面临客户信息丢失或不确定的情况下,一些银行和金融机构仍可以相对准确地计算出个人信贷违约率PD,这对银行和金融贷款机构有着重大的现实意义。更为重要的是,这对未来信息技术的发展和应用提供了另一个方向。虽然使用我们的方法可以取得一些不错的效果,但是这种方法仍然存在一些现实的问题。例如,如何自动选择最近邻K值,以及如何更有效地评估个人违约率PD等。未来工作的研究重点将是进一步提高对个人信贷违约率的预测精度。
