基于残差神经网络的陆空通话声纹识别
2020-04-08郭东岳周群彪
郭东岳,周群彪
(1.四川大学视觉合成图形图像技术国防重点学科实验室,成都 610065;2.四川大学计算机学院,成都 610065)
0 引言
21世纪以来,随着国民经济的飞速发展,飞机出行已经成为远距离出行的首选交通工具。据统计,2018年我国民航全行业完成运输总周转量1206.53亿吨,比上年增长11.4%。根据此趋势预测,2020年我国民航各类飞行起降将超过1500万架次。给人们带来巨大的便利的同时,也意味着飞行流量急剧增加,空域容量不足,地面空中交通管制压力随之成倍增长。近年来,民航不安全事件时有发生。管制员工作负荷与压力越来越大使空中交通管理行业面临巨大的安全保障压力,空管保障能力与飞行流量增长、管制员工作负荷压力之间的矛盾日益突出。随着人工智能的发展,基于深度学习的目标检测、人脸识别、语音识别、飞行轨迹预测等技术逐渐应用到空中交通管理中来,为空中交通的安全运行提供了有力的保障。其中,基于语音识别的空管安全监控系统[1-4]成为研究的热点。本文所研究的声纹识别是安全监控系统的子模块,主要功能是识别信道中的每句语音的角色(管制员/飞行员)。同时,对说话人的准确识别丰富了语料的信息,为后期数据查询、分析提供可靠的数据依据。
声纹识别(Voiceprint Recognition,VPR)又叫说话人识别(Speaker Recognition,SR),根据应用功能不同可以分为说话人辨认(Speaker Identification)和说话人确认(Speaker Verification)。说话人辨认的任务是从N个说话人中辨认该语句属于哪一个说话人,主要应用于多人对话场景的声纹识别;说话人确认任务是确认某一语音与目标语音是否属于同一说话人,主要应用于声纹锁、声纹认证等应用场景中。根据应用形式不同,又可以分为文本相关(Text-dependent)和文本无关(Text-independent)的声纹识别。文本相关的声纹识别需要说话人录制给定文本的语音供算法识别,因有文本的限定这类方法一般性能较好,但也缺乏一定的灵活性。而文本无关的说话人识别仅需要任意一段语音即可,以其灵活、方便易用等特点在工业界广受欢迎。由于陆空通话语音内容的多样性和随机性以及一个信道中存在多个说话人,本文的研究内容属于文本无关的说话人辨认。
声纹识别的发展历程大致如下:20世纪30年代,人们就展开了声纹识别相关的研究工作。直至60年代bell实验室提出了模板匹配的说话人识别方法,在当时取得了突破性的进展。
60年代至21世纪初,学界分别从音频特征提取和识别方法两个方面展开研究,先后将MFCC、LPC、PLP、LSP等音频特征应用到声纹识别中来,并取得了良好的效果。而识别方法也从模板匹配发展到了高斯混合模型-通用背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM)[5-6]、隐马尔可夫模型(Hidden Markov Model,HMM),人工神经网络(Artificial Neural Network,ANN)等准确率更高、鲁棒性更好的概率模型。随后,在GMM-UBM的基础上,P.Kenny提出联合因子分析(Joint Factor Analysis,JFA)[7]的方法、N.Dehak提出了i-vector[8]方法,将不定长的语音映射到一个子向量空间中,成为主流的声纹识别技术。以上传统方法虽然能达到一定的识别精度,但这些方法对信道环境、语音时长都有较大的依赖,只能应用于一般的声纹识别场景中,对专用场景的适应性较差。近年来,随着深度学习在生物特征识别(人脸识别、指纹识别)等方向取得巨大的成功,研究者们也将深度学习技术应用到了声纹识别中来,相继提出了基于深度神经网络(Deep Neural Network,DNN)、卷积神经网络(Convolutional Neural Network)、循环神经网络(Recurrent Neural Network)及其变种的声纹识别方法[9-14]。例如 d-vector[15]、x-vector[12]、j-vector等方法,这类方法的本质特征都是训练一个深度神经网络作为说话人特征(Speaker Embeding)提取器,再使用 PLDA[16]、余弦相似度(Cosin Similarity)等作为后端判决模型。2017年,百度和VGG实验室几乎同时提出了基于残差神经网络(Residual neural network,ResNet)[17,18]的说话人特征的提取方法用于说话人识别,在大规模语音数据集上取得了较好的效果。一般而言,采用深度学习的方法即可应用于一般场景,也可以针对特殊场景加强训练以得到良好的效果,是目前主流的声纹识别方法。
本文根据陆空通话的特点,提出了一种基于深度残差神经网络的陆空通话识别方法。该方法能够有效地在不稳定噪声、多语种、开集说话人的空管信道中完成空管语音角色识别任务,是一种鲁棒性较好的声纹识别方法。
1 相关工作
d-vector方法是使用深度学习完成声纹识别任务的经典方法之一,在训练阶段,提取每一语音帧的Filterbank Energy作为语音特征馈入DNN模型中,通过softmax层训练说话人分类模型。在使用阶段,当模型收敛后将移除softmax层的网络模型作为说话人特征提取器,将最后一个隐藏层的输出经L2正则化、多帧向量叠加作为说话人特征。并且d-vector也可以与PLDA等信道补偿算法相结合以消除不同信道对语音的影响。实验证明。通过对大量的音频数据训练后,d-vector不仅可以对训练过的说话者集合上有良好的表现,并且在未训练的说话者身上也取得了较好的成绩。d-vector算法的模型结构图如图1所示。
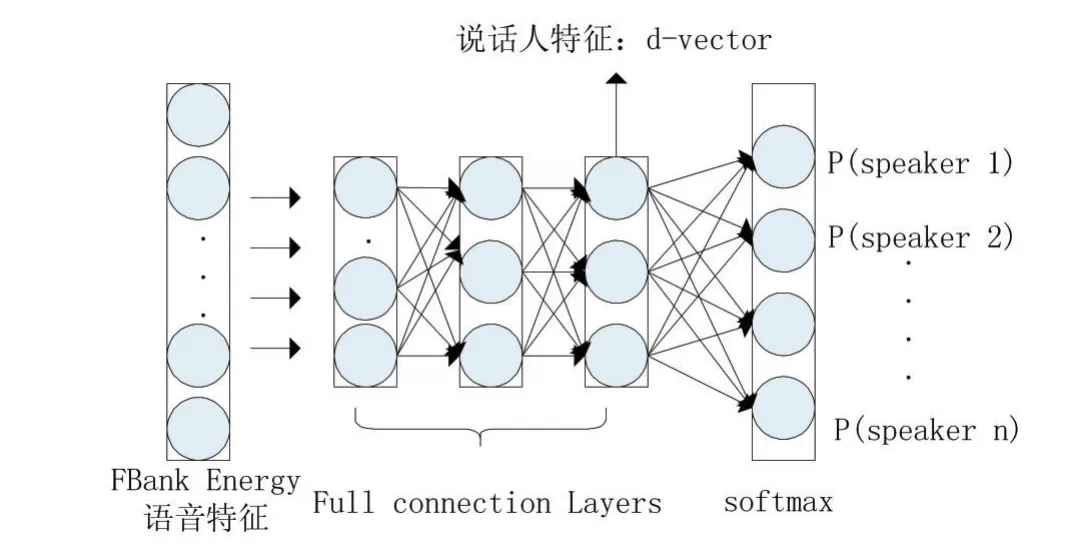
图1 d-vector模型结构图
2 基于ResNet的陆空通话声纹识别
2.1 相关语料分析
本文对真实陆空通话数据集ATCSpeaker和一般开源数据集LibriSpeech进行了统计与分析。其中,ATCSpeaker数据集分为英文和中文子集,LibriSpeech为全英文数据集,按总时长分为100、360和500小时的数据子集。统计结果如表一所示,根据数据对比可得,陆空通话语音与一般语音相比具有以下特性:
(1)短语句
陆空通话为半双工无线电通信,一个信道内一般存在一个管制员与多个飞行员通话。因此,陆空通话内容要求发音清晰、言简意赅。表中统计了平均单句语音的时长(Avg-duration),明显可以看出陆空通话语句约为LibriSpeech数据集单句时长三分之一。并且,平均语速(avg-word/s)也要明显快于LibriSpeech数据集。一般来说,在声纹识别中,语句越长则其中包含的说话人特征越明显,对音频特征的提取越有利。
(2)不稳定噪声
无线电通话易受天气、环境、通讯设备等因素的制约,信道极易受外界因素的干扰。相同指标下与LibriSpeech相比,ATCSpeaker数据集的平均信噪比(Avg-SNR)之差为5左右。高信噪比意味着提取难度说话人特征的难度增加,需要更大的信道补偿。
(3)多语种
在我国空中交通管制中,管制员与外航或外籍飞行员使用英语沟通,与国内航班使用中文沟通。多语种声纹识别也给声纹识别的准确性带来了巨大的挑战。
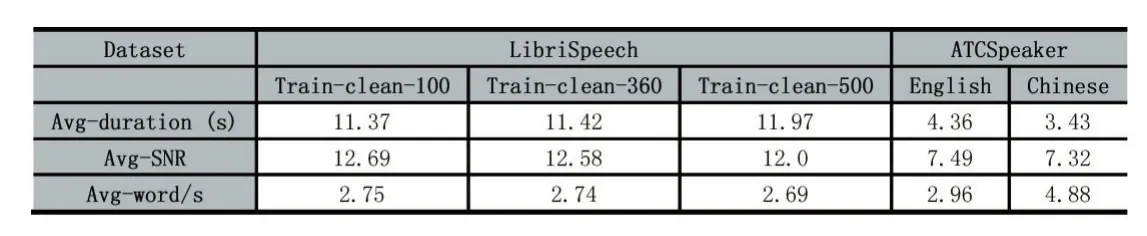
表1数据特点对比表
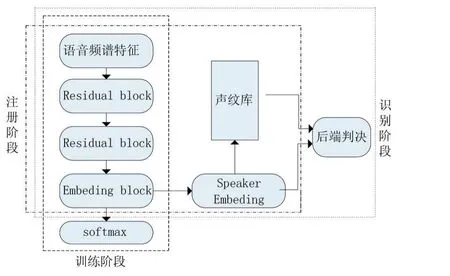
图2陆空通话声纹识别架构图
综上所述,陆空通话场景下的声纹识别不同于一般声纹识别,现有的算法并不足以满足陆空通话声纹识别的精度要求,需根据其特点研发适合陆空通话声纹识别的方法。
2.2 陆空通话声纹识别架构
本文提出的陆空通话声纹识别架构如图2所示。其中,Residual block为2.3节所介绍的残差模块,主要是用于提取说话人特征。Embeding block包含两个部分:全连接层和L2正则化层,其主要作用是将残差模块提取出的特征归一化到一个固定维度的子向量空间中作为说话人特征。陆空通话声纹识别主要分为三个阶段:
(1)训练阶段:训练阶段首先按照分类模型搭建深度神经网络,softamx层的节点数对应说话人的个数。将音频文件提取音频频谱特征馈入神经网络中直至收敛。
(2)注册阶段:在注册阶段将softmax层移除,将管制员语音馈入训练好的网络中,取Embeding block层所提取出的说话人特征放入声纹库,即注册完成。
(3)识别阶段:在识别阶段将待识别语音馈入训练好的神经网络中,取声纹库中的语音,经后端判决模型判断是否属于某一管制员,否则待识别角色为飞行员。在本文中采用余弦相似度作为后端判决模型,判决阈值随应用环境调节。
该架构将说话人特征提取和后端判决分离开来,有利于适应不同的陆空通话信道。当信道环境发生巨大改变时可以使用PLDA等信道补偿算法作为后端判决模型以适应不同的信道,而不用再次重新训练说话人特征提取模型。实验证明,该架构在陆空通话环境下切实可行,是一种稳健的陆空通话识别方法。
2.3 Res Net网络结构
随着数据量和用户的增大,d-vector算法已经不能满足于大规模的声纹应用需求,而一味的增加网络深度、网络堆叠会导致梯度消失、网络训练难度成倍增大等现象。而残差神经网络的出现则解决了网络深度导致的梯度消失问题。残差模块的原理如下:假定某段神经网络输入为x,期望输出为H(x),那么直接把x传到输出作为初始结果,那么此时学习的目标F(x)如式(1)所示:

这就将学习的目标从完成的输出改变为学习输入输出的残差。在声纹识别中,由于残差神经网络的特性,随着数据量的增加ResNet可以很好地拟合数据,而不会额外增加网络的参数和数据计算量。因此,模型训练的难度也得以降低。文献[17,18]都选择了ResNet作为说话人特征的提取器,并在各自的大型数据集上取得了良好的效果。
本文提出了一种多核残差神经网络,其中Residual block模块如图3所示。不同于文献[17,18]的残差块,本文根据陆空通话语料的特点采用两路多尺度卷积残差块:第一路采用卷积核大小为3×3的卷积层;第二路两层卷积层的卷积核大小分别为5×5和1×1。针对陆空通话语料语速快、多语种、语音特征分散等问题,本文采用语音频谱图作为网络输入。语音频谱可以最大限度的保留原始语音信息,而多尺度卷积操作可以分别从不同的尺度充分挖掘语音频谱中所隐藏的说话人信息,尽量避免信道所带来的影响。
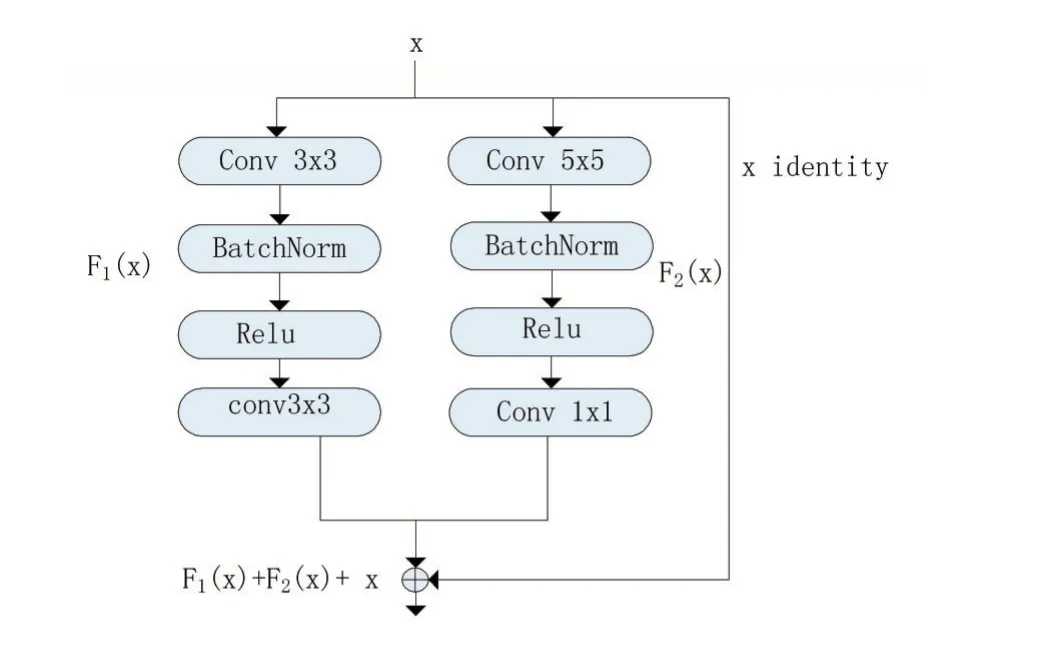
图3多核残差块结构图
3 实验
3.1 实验环境与数据集
本文实验环境在Ubuntu16.04操作系统下搭建,使用RTX2080Ti显卡训练深度训学习模型。深度神经网络基于TensorFlow、Keras等深度学习框架搭建。陆空通话数据集ATCSpeaker取自国内真实陆空通话录音,经人工切分、标注,共有50位说话人,音频时长约20小时。对比实验数据集使用开源语音语料库LibriSpeech中的train-clean-100子集,约有250位说话人,音频总时长约100小时。
3.2 评价标准
等错误率(Equal Error Rate,EER)是声纹识别系统中常用的评价标准。本文所提出的陆空通话声纹识别由于说话人个数的不确定性,属于开集说话人识别。因此,使用EER作为本文实验的评价指标。EER的计算主要依靠两个指标:错误接受率(False Acceptation Rate,FAR)和错误拒绝率(False Rejection Rate,FRR)。其计算如公式(2)、(3)所示,其中 NIRA 代表的是类间测试次数,NGRA是类内测试次数,NFA是错误接受次数,NFR是错误拒绝次数。在0-1内画出FFR和FAR的坐标图,交点即为EER值。

3.3 实验结果与分析
实验结果如表2所示,本文所提出的ResNet无论是在LibriSpeech数据集还是ATCSpeaker数据集上都取得了良好的效果。其中与d-vector方法相比,在ATCSpeaker数据集上提升了约6%,提升幅度也明显优于LibriSpeech数据集上的提升幅度。实验表明本文提出的ResNet网络架构中的残差模块对陆空通话语音中的说话人特征更加准确,能很好地抑制信道差异。因此,本文提出的ResNet网络架构是一种鲁棒性较好的陆空通话声纹识别架构。
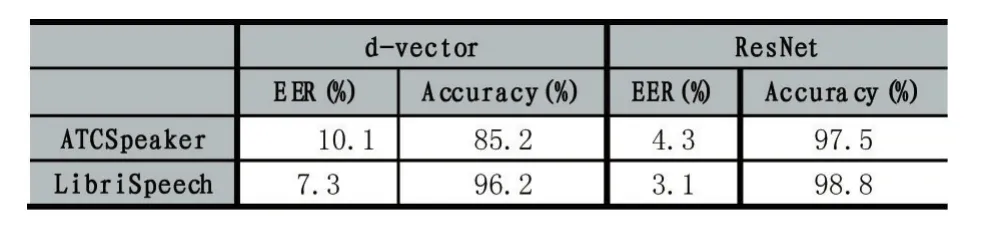
表2实验结果
4 结语
本文实验了d-vecotr与ResNet声纹识别方法在陆空通话声纹识别中的应用,在此基础上提出了一种基于深度残差神经网络的陆空通话声纹识别架构。该方法能够针对陆空通话场景的特点,通过声纹识别的方式很好地完成空管语音角色识别任务,同时可以灵活的调整后端判决模型来适应信道的剧烈变化。综上所述,本文提出的算法灵活易用、鲁棒性较好,实验表明具有较强的实用价值。
