大数据时代下电商自动处理评论文本的研究
2020-04-06罗胤达
罗胤达

[摘 要]在电子商务营销模式中,面对如今网络上海量增长的数据量,仅靠人工阅读来收集消费者的反馈变得越来越难以实现。文章将采用一种自动化的文本处理方法,自动处理海量的文本数据。以小米手机为例,文章将没有进行人工标注好评与差评的原始评论文本经过中文分词、关键词提取和情感分析处理自动得出手机各个功能的消费者评分及汇总。让电商企业可以快速了解所有消费者对产品每一个功能的总体评价,灵活、方便、快捷地了解到客户的真实需求,从而及时调整后续产品和服务,制定合适的市场营销策略,不断提高企业的竞争力。
[关键词]电子商务;产品评价;文本挖掘
[DOI]10.13939/j.cnki.zgsc.2020.36.166
1 引言
对于大数据时代下的电商企业来说,在线评论功能的产生,提供了及时的、透明的市場反馈渠道。并且该功能使用起来非常方便,不少消费者自发地对商品进行评论,发表自己在这次购物后喜悦或是愤怒的心情,有的企业甚至通过“评论返现金”的方式促使更多的消费者对其产品做出评价而获得更多的反馈。有了在线评论功能的支持,商家解决了传统销售企业想要迅速获得消费者反馈却无从下手的困难,克服了使用问卷调查方法下时间跨度过大的缺陷。文章的研究成果可以帮助电商企业快速批量处理大量的评论数据,提升对顾客需求的反馈速度,为营销决策提供参考依据。
2 文本挖掘步骤
文章研究所使用的数据由python爬虫抓取天猫商城小米旗舰店新款mate 9手机的最新评论2135条。
2.1 中文分词
中文分词是进行文本挖掘的必要环节,如果不对得到的原始评论语句进行分词,后续的特征词提取将无法进行。中文分词属于自然语言处理技术范畴,主要目的是将一个连续的中文句子按照汉语语言的规则组合成分开的词组的过程。分词是中文文本挖掘中专属的概念。除了中文分词需要增加分词的步骤外,汉语语言本身也是更为复杂的,在不同的语境下,相邻的同样几个字可能组合成不同的词语。本文在python语言环境下进行分词操作,通过import命令调出jieba模块。jieba模块有一个自带的词典,里面基本包含了所有常用的或是生僻的词语,但仅仅拥有自带的词典是不够的。汉语不但语法复杂,语义多样,还极具创造性,在各种领域里经常会有新的词语出现,甚至某些评论会刻意去使用一些代称,而该分词工具则允许使用者调用自己建立的词典来完善其词库。
2.2 关键词提取
TF-IDF算法,是一种对纯词频统计TF(term frequency)增加了一个抑制因子逆文档频率IDF(inverse document frequency)的加权算法。逆文档频率的引入,抑制了某一文本内无意义高频词的负面影响;如果一个词语在大部分句子中都出现过,此时抑制因子就会给这个词语乘上一个较低的权重。如果一个词语仅在少部分句子中频繁出现,此时抑制因子就会得到较高的权重。该算法不但对于那些对分类结果没有帮助的、无意义高频词有着良好的区分度,还更倾向于保留文档中较为特殊的词语。TF-IDF本质上是一种试图抑制噪声的加权,且对于大部分文本是可行的。
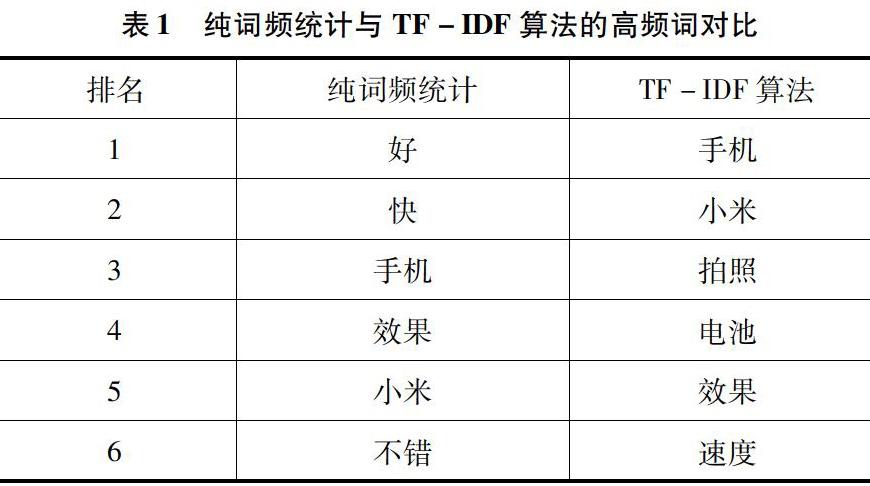
文章使用爬虫抓取到的同一组数据进行纯词频统计与TF-IDF算法统计进行对比,如表1所示。
除了文章所研究的产品名字“小米”“手机”有很高的权重外,TF-IDF算法得出的其他关键词相较于纯词频统计得出的关键词更符合于手机的某一特征。至此提取出了拍照、电池、效果、速度、运行、音质、客服作为关键词,而这些手机特征也就作为最后一部情感分析的对象。
2.3 情感分析
文章所使用的情感分析方法是基于情感词典进行的,是对人的思维的简单模拟。由公式“情感单元得分=(-1)^(否定词个数之和)×程度副词权重×情感词得分”实现。将句子看作“关键特征词+情感词+程度副词”或者“关键特征词+否定词+情感词+程度副词”的组合。基于情感词典法无须训练模型,主要依靠人工标注,没有机器学习算法中略过语义、语法考虑的问题,更适合中文这样复杂的语言体系。
文章所用的情感词典集合了2019年1月24日上传的清华大学李军中文褒贬义词典、知网Hownet情感词典和台湾大学NTUSD简体中文情感词典三种词典的整合。将三种词典中的积极情感词、消极情感词、否定词和程度副词分别复制到一个文档中并进行去重操作,整合成为了文章所需要的情感词词典。将分词后的文本带入模型进行计算机情感打分,最后得出结果,比如表2所示。
将情感分析的结果按提取出的各个关键词分别统计得分并汇总,最后得出手机各功能情感得分均值为:“客服=0.79”,“拍照=0.75”,“效果=0.74”,“速度=0.60”,“运行=0.53”,“音质=0.35”,“电池=0.28”。
通过计算机情感分析后发现:小米mate 9手机的售后服务与手机功能方面如“客服”“拍照”普遍受到用户好评,而手机性能“电池”“音质”方面评价略低。电商企业可以根据本文的结果有针对性地改善后续的产品和服务。
3 结论与展望
文章使用的文本挖掘方法从海量的评论数据通过计算机自动计算汇总了消费者对小米手机各功能的总体评价,每一步均由计算机自动计算,相比于人工调查客户反馈提升了效率,为企业节省了大量的人力、物力,让企业对消费者的反应更加灵敏、精准,提升了电商企业的竞争力。
如果原始数据的获取没有限制,该方法完全可以应用于海量网购评论数据的挖掘。尽管计算机算法结果难以企及人类阅读判断的准确性,但如今的互联网每时每刻都会产生大量数据,很显然不可能由人来完成这样的数据分析。文章所使用的模型的准确性很大程度上取决分词精度与情感词典的完整度,而这些都需要后人不断地对词典进行完善,中文自然语言的处理结果就可以越来越接近人类的判断。
参考文献:
[1] ALAN S, JIAO J, FAN W, et al.Whats buzzing in the billzard or buzz? automotive component is olation in social media postings[J].decision support systems,2013,12(23):873-876.
[2]PANG B,LEE L,VAITHYANATHAN S. Thumbs up? sentiment classification using machine learning techniques[J].proceedings of the conference on empirical methods in natural language processing.usa:stroudsburg, 2002:79-86.
