谓词逻辑视角下HanLP中文分词中对歧义的处理
2020-03-23邱德钧
邱德钧,冯 霞
(兰州大学哲学社会学院 兰州大学大气科学学院,兰州 730000)
一、中文分词的类型
自然语言中很多时候存在歧义,在数理逻辑创始之初,莱布尼茨就对此作了深入研究。莱布尼茨极力推动的“通用文字”计划,目的是对语言实现技术性理解,以规范语言的日常使用,实现无歧义地交流(1)斯特普夫和菲泽著,丁三东译校,《西方哲学史》,中华书局,北京,2005-226.。虽然在有的领域受到批评,但这一开创性的工作为人类留下了数理逻辑的宝贵财富,今天更成长为人机交互的重要工具。斯通普夫说:“莱布尼茨在描述宇宙时并没有使用机械论的模式,因为如果他这样做,他就不得不说这个宇宙的各个不同的部分是按照每个其他部分而行动的,就像一个钟的各部分影响每个其他部分的运动一样。在某种意义上,莱布尼茨的解释甚至比机械论模式的主张更加具有严格的决定论色彩。因为他的单子全都是互相独立的,并且互不发生影响,但却按照它们从一开始就通过上帝的创造而接受到的原始目的而行动。这种决定论之所以更严格,是因为它不依赖外部因果联系的变化莫测,而是依赖每个单子被给定的并且是永远固定的内部本性。”①抛开作者的本意,文字中透出了莱布尼茨力图从单子这个简单毫无歧义的出发点,避免日常语言歧义的深层的哲学思想。今天在NLP的处理中,遇见了大量的自然语言难题,尤其是歧义问题,哲学家从更高的范畴寻求其根由;自然语言处理的人们多从算法和实用出发研究,都遇到了不同的问题。本文从一阶谓词逻辑的角度讨论分析NLP中的长处与不足,试图从方法论上提供一种新的思路,以利于实际的NLP工作。这是因为一阶逻辑本身有着丰富的表达能力,且稍加处理就能为机器识别,当统计的方法遇到阻碍时,我们一起看看,一阶逻辑是否可以提供给人们新的思路。
汉语不同于英文,汉语句子内部词与词之间没有明显的分隔符(如空格),而信息化处理时是以此为单位的;再者,相较于其他语言,汉语表达意境的特征突出,不追求逻辑和约束结构,很难有固定的词句构造规律;第三,汉语历史悠久,分布广泛,更是增加了其千变万化的特征。因此自动化处理时必须进行分词,中文自动分词时涉及到的歧义主要有以下几种类型:第一类歧义是由自然语言的多义性所引起的歧义,句子“兵乓球拍卖完了”,有两种分词办法,一是“乒乓球/拍卖/完了”,二是“乒乓球拍/卖/完了”。这两种都是正确的,无论人工分词还是自动分词都会产生歧义,只有结合上下文才能给出正确的结果。由机器自动分词产生的特有歧义是第二类歧义。如:“在这个问题上班里意见不统一”用机器切分,可以切分为“在/这个/问题/上班/里/意见/不/统一”,也可以切分为“在/这个/问题/上/班里/意见/不/统一”。只有第二种分词是正确的,人工分词不可能产生上述歧义,歧义是由于机器机械切分产生的。由于分词词典的大小引起的歧义,称为第三类歧义,如:“王小二是一个农民”用机器切分被分为“王/小/二/是/一个/农民”,这里“王小二”是一个人名,在汉语中应是一个词,所以这个切分是错误的。由于机器自动分词是根据分词词典进行的。故词典中没有的词,就不可能被正确切分,分词词典不可能也没有必要包括所有的词(如人名、地名),同时,词典中所包括的词越多,就会产生新的歧义。例如:“发展社会主义的新乡村”新乡是一个地名,若词典中有该词,则“新乡村”是一个歧义字段。因此,不论词典的大与小都可能产生歧义。虽然近年发展出的消歧方法不进行这种分类研究,而视为相同的情形处理(2)参见《神经网络和贝叶斯网络在汉语词义消歧上的对比研究》,卢志茂 刘挺 郎君 李生,《高技术通讯》, 2004年第8期 15-19,共5页,但从逻辑角度思考这种分类是必要的,能使我们思路更清晰和详尽。
二、各种歧义句子的分词和谓词逻辑分析比较
汉语中出现了许多歧义句子,以下分别给出它的机器自动分词(3)采用哈尔滨工大的HanLP自动分词技术Apache License Version 2.0,官网为:http://hanlp.com/。和谓词公式(4)谓词逻辑公式统一采用希尔伯特系统。,力图从逻辑角度找到新的、一般的方法论的分析结论。
1.过直线外的一点能做并且只能做一条直线与它平行。


(∀x)(F(x)∧G(x,a)→P(x,a)∧W(x))
这一分词是正确的,相对于谓词公式却较难表达“且只能做”的涵义。不必对原文句子做改动,这正是近年算法中不用谓词公式而是用NLP分词的重要原因。谓词公式虽然能准确揭示内在的逻辑关系,却不合乎自然。
2.张三的每个朋友都是李四的朋友,所以,每个认识李四所有朋友的人也认识张三的所有朋友。


(∀x)(P(x,a)→P(x,b))→
这是逻辑关系复杂但表述清楚无歧义的句子,HanLP处理起来没有难度,其能力优于谓词公式。
由此可见,如果句子本身没有歧义,现有的分词法,无论是贝叶斯的还是神经网络的,远比谓词公式更有优势,这源于它不需改变句子本身就能被机器识别,而谓词公式必须分清个体词、个体常项、谓词、谓词的约束范围,关键的在一阶逻辑中不允许谓词做为其他谓词的运算对象,更是与自然语言的习惯不符合。下面来分析有歧义的句子。
3. 严守一把手机关了。

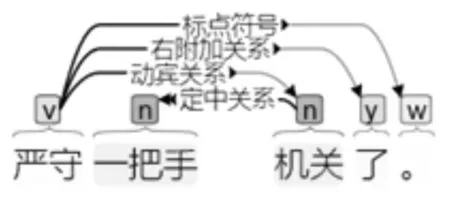
(∃x)(S(x)∧P(x,a)→G(a,x))
逻辑关系理解为:存在着个体x,若x是手机S,并且x属于(P)a,那么,a关掉(G)了x。分词法显然没识别“严守一”是一个体名词,错误地将“一把手”识别,造成了更多错误。传统汉语将这种情况是为结构性歧义,在本文上述分类中它既属于第二类又属于第三类歧义。但逻辑关系的表达正确,依赖于进行符号化的人的背景知识,若是没看过电影《手机》的人,也回避不了出错。同理,增加语料库将“严守一”作为专有名词,分词也会正确。
4.鸡不吃了。


(∃x)C(a,x)
这是前些年不能正确分词的句子,宾语前置,当现在已经可以准确识别“鸡”是前置宾语。但它还有一种分词法,“鸡”作为主语。相应的逻辑公式得改为 (∃x)((∃y)s(y)∧J(x)→C(x,y))
表示为:存在个体下x,如果存在个体y是食物并且x是鸡,那么x不吃y。但需要注意,即便是正确的第一种表达,也没有让读者领会到实际上这句话存在的暗示:吃的主体也许吃饱了。
5.新华为和新苹果该选哪一个?

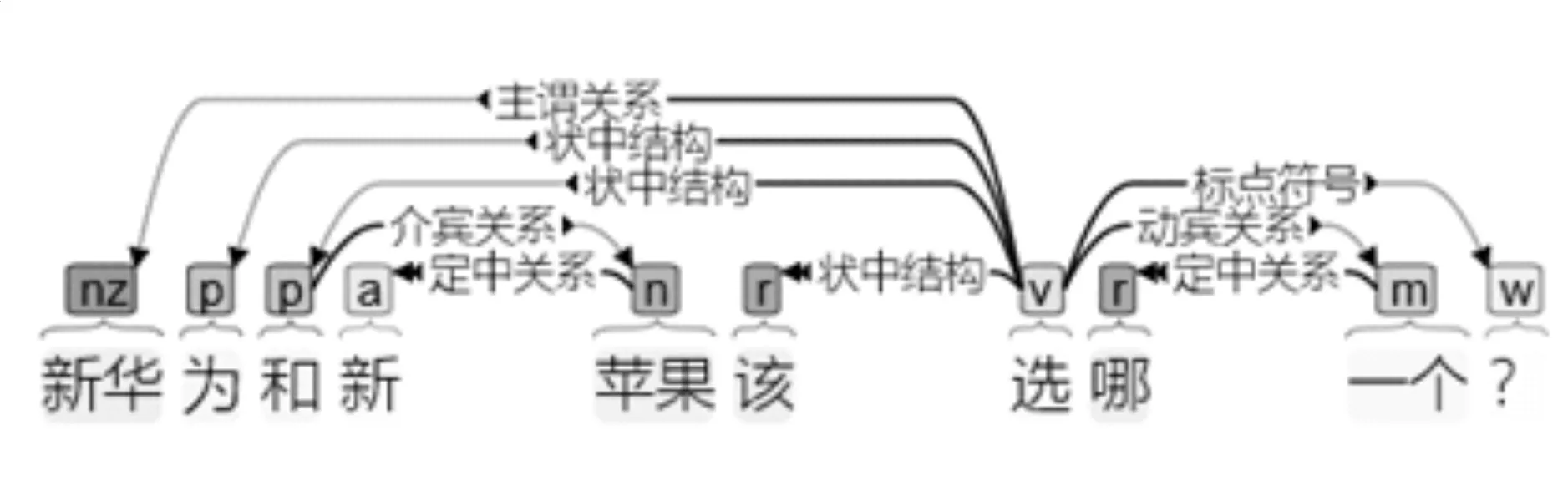
(∃x)(∃y)(H(x)∧P(y)→C(a,x)∨C(a,y))
语料库中预先存在的“新华”和“华为”词汇,调用的先后顺序肯定不能用字典排序解决,采用从左到右最大匹配法可以解决这个句子的问题。注意谓词公式将这个句子处理为了条件句,而不是原来的疑问句,因为逻辑处理方法对语句的基本要求就是首先必须是陈述句。如果考虑是语音环境,这个改变是巨大的。
6.为人民办公益。


(∃x)(∃y)(Z(x)∧G(y)→B(x,y)∧W(x,a))
这个例子十分特别,以前人们研究它是因为易出现“为/人/民办/公益”的错误分词,但现在已将解决。但“人民”是个特殊的集合体概念,如上将它以“a”这个个体常项表达。可现实中存在有人处理“人民”为普遍概念,解释为“为每一个人办公益”,这是错误的。同时,现在的分词方法如何教会机器区分集合体与非集合体,也应该是一个重要的研究方向,否则像“人是由古猿变来的”这种句子的真实含义机器依旧不会明白,弄不清它的准确含义是指“人类做为一个整体是由古猿变来的”,而不是“每个人都是由古猿变来的”。
7.欢迎新老师生前来就餐

(∃x)(∀y)(S(y)∨P(y)→W(χ,y)∧C(y))
这个句子简单,逻辑结构复杂,存在着x,对于所有y,如果y是学生或者老师,那么,x欢迎(W)y,并且y就餐。容易错的是条件句的前提是或者不是“合取”。以前容易将句子分为“欢迎/新/老师/生前/来/就餐”,但现在nlp的处理能力显著提高了,但精确的分词该是“欢迎/新/老/师生/前来/就餐”,这里是把“老师生”视为名词,“新”成了“老师生”的定语,还是有所欠缺。
8. 这事的确定不下来。

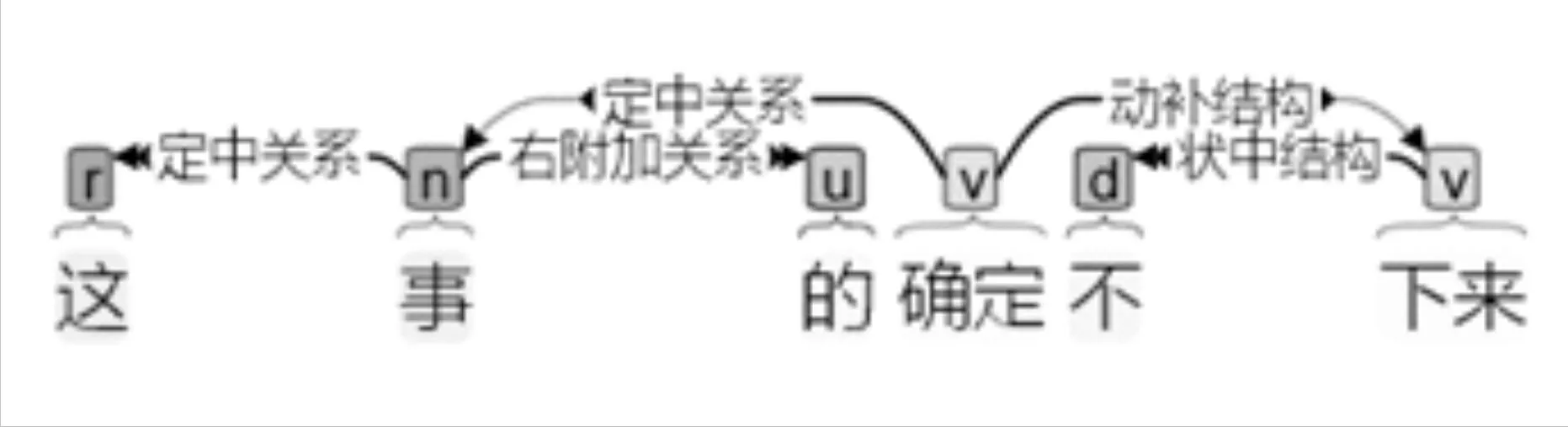
(∃x)(S(x)∧D(x))
这是贝叶斯概率分词算法缺陷的体现,“的”字的出现概率太高了,它几乎总会从“的确”中挣脱出来,而不把“的确”组合在一起。但同时,谓词逻辑对它的表达也是无力的,存在着x,x是事,并且x不能定下来,“的确”这个涵义被完全忽略了。
9. 已取得文凭的和尚未取得文凭的干部。


(∃x)(∃y)(R(x)∧W(y)→H(x,y)∨H(x,y))
同8,“的”又两次因频率高独立出来没有与“取得文凭的”组合,“和”与“尚”因为频率高意外组合在一起。谓词公式可以准确但复杂地表达出来,对两个名词组合的词组改变为了一个条件句。
10. 人的正确思想是从天上掉下来的吗?


(∀x)((S(x)∧Z(x)→R(x))→D(x)∧T(x))
Nlp在处理这个句子时完全正确,谓词逻辑再次遇到麻烦,由于不能处理非陈述句,必须先加工为“人的正确思想不是从天上掉下来的”,才能符号化。若机器分词采用逻辑办法,显然是不可能如此的。
11. 咬死猎人的狗。


(∃x)(∃y)(G(x)∧R(y)→Y(x,y)∧S(y))
以前爱出现的错误分词“咬/死猎人/的/狗”,在这个系统里得到改进。谓词逻辑对这种短的名词组处理起来却不方便,也很复杂:存在x,存在y,x是狗并且y是猎人,那么,x咬y并且x死了。
12. 从中学到大学的知识。

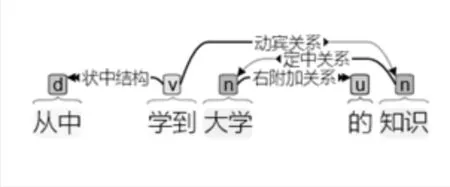
(∃x)(Z(x)∧G(x)∧U(x))
这是人工和机器分词都应该有两个结果的例子,HanLP输出了其中一种,却不知道其内部的选择机制,曾尝试多次,也未能输出“从/中学/到/大学/的/知识”,若是后者,该句逻辑结构简单。
谓词逻辑在表达中文时,具有以下优势:使用符号较少就可充分表达人类众多的自然语言;使用的符号系统可以方便为计算机识别,尤其是还有专用的Prolog计算语言,给人机交互带来便利;在处理具有多义的句子中准确,不会造成奇怪的新意义,如同7、8中的例子;对于较长的文章,可以生成一系列公式,由这些公式或者形成推理或者检验其一致性,进行元逻辑的进一步研究;尽管自然语言表达内容数量无尽,但其基本的逻辑结构却是数量较少,其表现力足以满足日常及专业的使用需求。
按照莱布尼茨的构想,这种天然带有可计算性能的工具今天在中文分词和其他主要语言的分词处理中却退居为弱势地位,也正反映出谓词逻辑的天生的不足:谓词逻辑以个体词xi(i=1,2,3,…)为运算对象,自然语言的个体往往是隐性的,有时还很难找出个体,需要另外做技术处理,如同6中的“人民”;汉语的简洁性造成句子的逻辑关系也是隐藏的,很少完整说“如果天下雨,那么不踢球”,而是替之以“天下雨不踢球”,更有甚者这还与“适当温度使鸡蛋孵出小鸡”是完全不同的逻辑关系,人类有时都难以区分;最后,谓词公式必须改变人类使用多年的句子本身外在结构,这个改动巨大,如同2中,不具备专业知识都很难读懂。基于此,无论HanLP的分词方法有多少不足,其不改变句子外在结构直接令机器识别这一个优势,就使得该方法无可替代。
三、逻辑结构分析与分词方法的结合构想
试图改变谓词逻辑劣势的尝试来源于给谓词逻辑增加新的算子“情态谓词”,如同8中的态度“的确”以前是为谓词逻辑忽略的,但句子的中的这些情态词却是说话人态度的重要反应,决定着句子的真实含义。语义学中对情态谓词做了大量的研究,认为语言中说话人对所报道信息“可信性”的评价属于主观情态性范畴内容,甚至研究了不同类型的命题态度谓词在语言的使用中呈现出自己的不同特色,构造出多了一个算子的演算系统。但这些工作只是增加了谓词公式的复杂度,补充了公式的态度、可信度等表达能力,没有解决它不直观、不自然和改变句子本身结构的缺陷,不会为文本分词也更不可能为语音识别分词所用。
深层的原因根植于计算机算法的本质主要是查询与匹配。给定的需要处理的句子文本,计算机会在已知的库中寻找匹配项,正序的或者是反序的多次高速匹配。匹配的首要条件就是存在一个在先建立的文本库,自然语言的词汇和句子库建立已经持续几十年,在将来建立一个谓词公式库能否对分词歧义有作用?不考虑建库的难度与成本,从操作上这不可取,因为必须要将自然语言转化为公式才能与库中已有的公式匹配比较,转换过程会影响速度;即便以后高速计算使转换速度忽略不计,自然语言的丰富性和新的词汇增加量的问题还得再处理一次,被匹配对象的问题没能得到解决。
能不能在现有的匹配中,考虑加入逻辑结构的对比,并使之在实际操作中可行?比如,一旦出现“天下雨不踢球”,就给出以下五种结构,结合概率和监督学习进行选择:
1. 天下雨∧不踢球。
2. 天下雨∨不踢球。
3. 天下雨→不踢球。
4. 天下雨⟺不踢球。
同理,出现句子“城会玩”,也给出选择:
1.(∀x)(城里(x)→会玩(x))
2.(∃x)(城里(x)∧会玩(x))
这种办法有可能有助于提高句子分词成功率并且切实可行,笔者将在以后的文章中具体探讨,此处给出基本流程图:
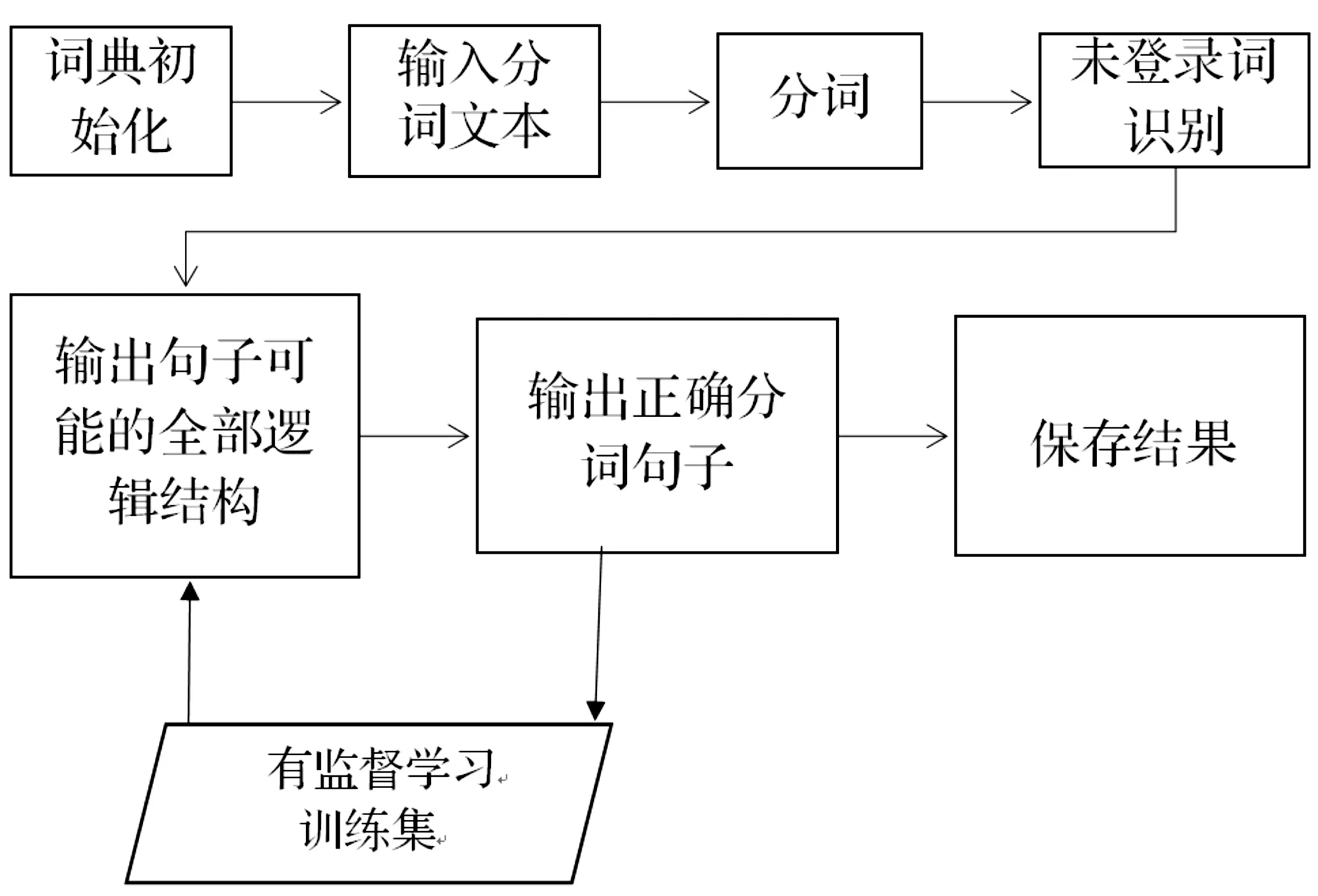
图1 基本流程图
