电力变压器故障类型与关键状态量关联规则分析
2020-03-20戴瑞成董小兵
董 翔,赵 璧,戴瑞成,董小兵
(1.国网北京电力检修分公司,北京 100069;2.国网陕西省电力有限公司经济技术研究院,西安 710065)
0 引言
随着计算机技术的飞速发展,电力变压器的故障检测手段发生了巨大变化[1-2],已逐渐转入计算机领域,通过建立相应的数学模型来预测变压器内部故障,使得故障的检测朝向智能化、信息化的方向发展[3-4]。
常用的故障检测方法有基于人工神经网络模型的诊断、基于模糊理论的故障诊断和基于专家系统的故障诊断。此外,其他的诊断方法如Petri网、灰色聚类及支持向量机等也运用于故障诊断中,并得到了一定程度的发展。每种方法均有优点和缺点,需要人们根据实际问题寻找最合适的办法。按照当今的发展趋势,人工智能的方法在故障诊断领域占据越来越重要的地位。
传统的设备运维基本采用状态检修技术,根据设备的定期试验结果并结合评价模型开展检修策略的制订[1-2]。现阶段随着带电检测、在线监测和运行数据逐步纳入电力企业云平台,为开展电力设备大数据分析、进一步提高供电可靠性奠定了基础。而现阶段积累的状态监测和检测数据没有得到充分挖掘利用,造成信息资源的浪费[3-4]。
因此,非常有必要完成变压器异常事件及其影响因子的调研、收集和相关规则库建设,对规则库中的海量数据开展基于大数据技术的潜在关联探索和未来短期预测,逐步提升设备故障诊断水平,为后续生产运行和状态评估提供决策依据。本文介绍了关联规则挖掘的基本原理、故障状态量的划分及数据离散化处理方法,以此为基础,利用SPSS Modeler 软件平台建立电力变压器故障关联规则挖掘模型,旨在采取关联规则挖掘的方法发现状态特征量和故障类别之间的内在联系,对故障进行判定。
1 关联规则挖掘基本原理
1.1 关联规则挖掘概念
关联规则挖掘的概念可以描述如下:设I={i1,i2,…,im}是一个项目的集合,D={d1,d2,…,dn}是事务数据库且其中的事务都具有唯一的标识。每个事物di(i=1,2,…,n)都对应I 上的一个子集Ij(j=1,2,…,m),Ij即为由j 项I 中的元素组成的集合。关联规则就是定义在I 和D 上,满足一定的置信度及支持度的形如Ij→di的关系式。关联规则挖掘的主要任务在于挖掘出支持度和置信度分别大于或等于设定的最小支持度及其最小置信度的关联规则。
1.2 关联规则挖掘
1.2.1 关联规则挖掘流程
关联规则挖掘流程如下:
(1)找出全部的频繁项目集。所谓的频繁项目集指的是支持度不小于给定的最小支持度的项目集,例如k 阶频繁项集Lk中每个元素都是由k个项组成的集合,且其中每个元素的支持度均不小于最小支持度阈值,以2 阶频繁项集为例,其形式为L2={{i1,i2},{i1,i3},{i2,i4},…}。
(2)根据频繁项目集来生成关联规则。这一步以置信度大于等于用户所设定的最小置信度作为基本原则,生成所期望的强关联规则。
在以上2 步中第(1)步的任务集中了几乎所有的计算量,所以耗时相对较大;第(2)步在第(1)步的基础上较容易实现,所以关联规则挖掘算法性能主要取决于第(1)步。
1.2.2 关联规则挖掘算法
Apriori 算法作为关联规则挖掘的经典算法,自被提出以来就一直在关联规则挖掘中占据重要的地位。该算法主要包含两大步骤:挖掘得到频繁项目集;由频繁项目集生成关联规则。Apriori算法是一种挖掘关联规则频繁项集的算法,其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。该算法的基本原理如图1 所示。

图1 Apriori 算法原理
关联规则挖掘过程的核心部分是频繁项集的生成过程,因为频繁项集的生成过程是影响算法的关键,也是计算量最大、耗时最长的过程。生成频繁项集的过程又有2 个子步骤:
(1)连接步。为了产生频繁k 项集的集合Lk,首先要找到候选k 项集的集合Ck,该集合可以通过频繁(k-1)项集的集合Lk-1与自身进行连接得到。假设l1和l2均为Lk-1中的项集,lj中的第i 项用lj[i]来表示。如果它们的前(k-2)个项均相同的话,即满足(l1[1]=l2[1]∧l1[2]=l2[2]∧…∧l1[k-2]=l2[k-2]∧l1[k-1]≠l2[k-1])。连接l1,l2产生的结果项集即为候选k 项集:Ck={l1[1],l1[2],…,l1[k-1]l2[k-1]}。
(2)剪枝步。由于候选项集并不是所有的项集都是频繁的,因此为了减小搜索空间,可从Ck中去掉候选k 项集的(k-1)项子集[5-7]。
1.2.3 算法程序实现
根据以上算法原理可以设想程序的实现应分为以下3 个模块:
(1)找出满足最低规则支持度的频繁n 项集Ln,为此要先构建初始候选1 项集C1及频繁1 项集L1,由连接步依次生成Cn,再在Cn中筛选出Ln。
(2)从频繁n 项集Ln中筛选出满足最低支持度的Qn。
(3)在Ln中找出满足最低规则支持度和最低支持度的强规则集。
关联规则挖掘阶段主要由四大部分构成,即变压器故障数据归集整合、数据预处理、单变量交叉表分析和利用Apriori 算法得到关联规则[8-10]。
2 故障状态量的划分及数据离散化处理
2.1 故障特征量和故障类型划分
变压器在故障状态下会生成多种气体,本文采用基于PCA(主成分分析)的输入参数分析方法对相关量进行优选。利用PCA 法选取诊断模型对应的最优参数,并同步剔除影响诊断正确率的冗余参量,最终取8 种气体(CH4,C2H2,C2H4,C2H6,H,CO,CO2和总烃)作为故障特征量,即故障诊断中的条件变量,而故障类型选取过热兼放电、低温过热、中温过热、高温过热、低能放电和高能放电,并标记相应的变量,如表1、表2 所示。
将故障特征与变压器典型故障相结合,可形成关于关联分析规则分析中的数据项集I,记为:
I={x1,x2,…,x11,y1,y2,…,y6} . (1)
以下电力变压器故障与特征量的关联分析,是对特征量集X={x1,x2,…,x11}与故障集Y={y1,y2,…,y6}的相关性进行分析,计算获得X→Y 的模糊关系规则。
2.2 数据离散化
原始数据中存在着许多空缺值,并且关联规则挖掘需要针对的是离散化数据,因此原始数据必须进行预处理后方可使用。对于空缺值的处理一般有平均值填充和去除2 种方法。由于本文中所处理数据量较大,并且分散性较高,所以当一个案例所有信息均空缺时对空缺值采用去除的方法,若案例的空缺信息不多,则利用Spss Modeler将其设为缺失值。数据的离散化方法有很多,如等距离划分法、等频率划分法、K-means 算法、最小信息熵法、NavieScaler 离散化和模糊离散方法,方法的具体选取由数据本身决定。
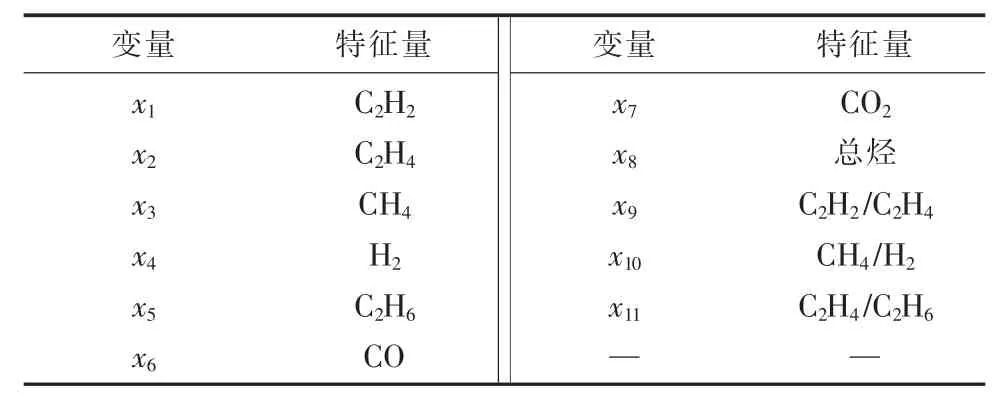
表1 变压器故障特征量
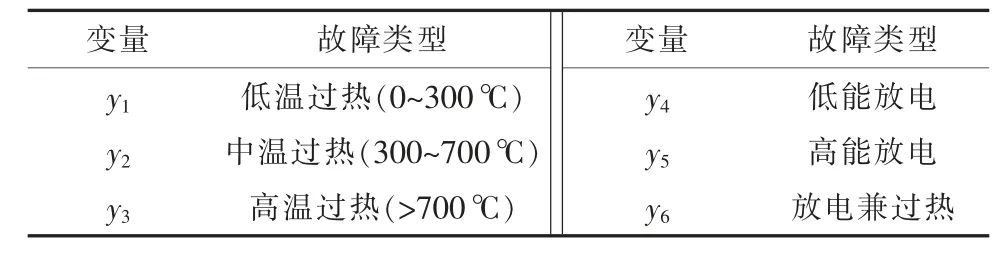
表2 变压器典型故障类型
有关故障状态量的离散化本文选取了布尔逻辑算法和模糊离散方法2 种方法,优先运用布尔逻辑算法。由于正常变压器油中氢和烃类气体的含量限值各不相同,具体注意值如表3 所示,若对所有属性值采用相同的区间,则缺乏一定的针对性。且由对电力变压器数据统计特征分析可知,有4 种气体其绝大部分数据均集中在含量极小处,综合考虑后决定离散方法如下:若离散值为0,则表示气体含量在正常范围内;若离散值为1,则表示气体含量超出注意值。

表3 正常变压器油中氢和烃类气体的含量限值
由于国标没有规定CO 和CO2的阈值,因此可利用现有数据的分布来确定二者具体阈值,即根据IEEE 所规定的气体浓度极限值,通常是基于去除了破坏后的样品的大型数据库的90%和95%的气体浓度来确定的。
3 建模分析
基于关联规则挖掘基本原理,利用SPSS Modeler 软件平台建立电力变压器故障关联规则挖掘模型。先以改进的等距离划分算法所得离散化数据的建模过程作为重点介绍。当采用模糊的离散化方法离散时,建模过程与此相同。
其中,将能直观表示故障特征量以及故障类型总共9 个类别量之间相关联程度的网络关系展示如图2 所示。图中,如果案例支持两点之间存在关联,那就在两点之间连成一条线;如果案例不支持,两点之间就不连线。把所有案例遍历后,哪两点之间的连线最多,说明这两点之间的相关性最强。

图2 不同链接数下的属性值相关关系网络图
利用模糊关联规则模型对特高压变压器进行异常状态诊断及分析,流程如图3 所示。以故障特征量为前项,以故障类型为后项,设置最小支持度和最小置信度,运用Apriori 数据挖掘经典算法挖掘出变压器故障和故障状态量之间的关联规则。
4 实例分析
以2016 年某220 kV 变压器跳闸为例进行验证[15]。该变压器跳闸后的试验结果见表4,油色谱数据见表5。
将该结构化数据与故障类型、故障部位进行关联规则匹配,结果见表6。由表6 可知,基于模糊关联规则的变压器诊断结果与实际解体检查结果(B 相低压绕组严重变形,多处匝间短路,存在电弧放电)相符。
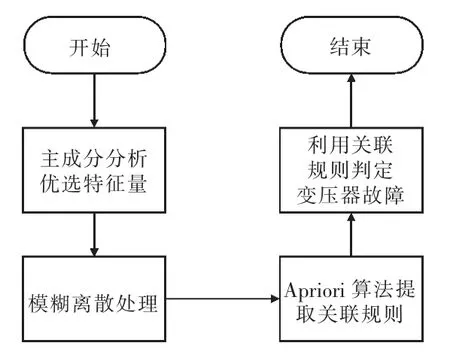
图3 模糊关联规则模型诊断分析流程

表4 变压器电气试验结果
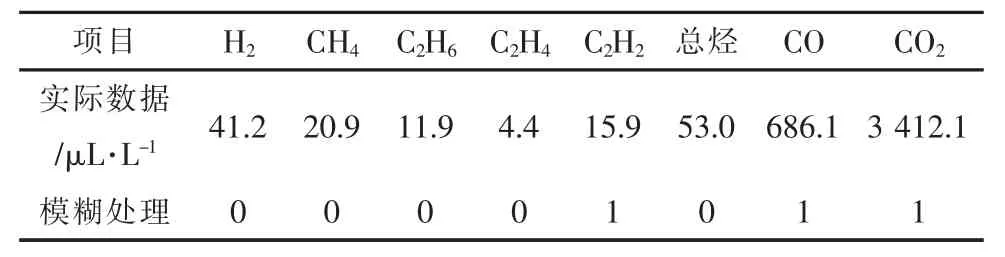
表5 变压器故障油色谱数据

表6 诊断结果
5 结语
本文以电力变压器故障特征量为前项,以故障类型为后项,设置最小支持度和最小置信度,运用Apriori 数据挖掘经典算法挖掘出变压器故障和故障状态量之间的关联规则。基于关联规则挖掘基本原理,利用SPSS Modeler 软件平台建立电力变压器故障关联规则挖掘模型进行建模分析,得到以下故障诊断流程:
(1)利用PCA 法对输入特征参量进行优选,得到优选后的特征参量。
(2)基于模糊集合理论对优选后的特征量(油色谱及电气试验数据)进行模糊离散处理,得到相应离散后的特征数据库。
(3)基于离散后的特征数据库,使用Apriori算法进行关联规则的提取。
(4)利用所提取的关联规则对待诊断设备进行故障判定。
该流程能够从历史数据中获取潜在的诊断知识,有效解决故障诊断中知识获取困难的问题。实际应用时,在得到相应特征参量(油色谱数据及电气试验)的数据后,及时转化为结构化数据并对结构化数据进行模糊离散化处理,再将离散数据输入到模糊关联规则模型后即可得到变压器异常状态的诊断及分析情况。
