价值样本选取的不均衡分类*
2020-03-19王馨月才子昕沈启航景丽萍
徐 剑,王馨月,才子昕,沈启航,景丽萍
北京交通大学 计算机与信息技术学院,北京100044
1 引言
在许多场景和应用领域中,不均衡学习是一个常见并且长期存在的问题[1-2]。当不均衡数据分布存在于二分类问题时,其中一类(多数类)样本数量远远超过另外一类(少数类)样本数量。在许多重要的现实分类问题中,不均衡率,即多数类样本和少数类样本数量的比例是非常高的。例如诊断数据中的罕见疾病[3]、信用卡欺诈检测[4]、技术设备故障检测、不合格产品分类[5]等。由于样本的不均衡性,传统分类器更多地偏向于多数类样本。如图1 所示,星形表示多数类,圆圈表示少数类。首先,当少数类数目很少时,由于决策面更多地偏向于多数类,因此导致少数类被分类错误。同时,一些有噪声的样本(如图1 中的A、B样本点)和多数类中冗余样本点(虚线圈中样本)也会对分类造成困扰。因此,有必要对少数类自适应地分配更高的权重来改变决策面的偏移,其次要选择那些更有价值的样本,以避免冗余样本和噪声样本对分类的影响。

Fig.1 Illustration of impact of imbalance distribution for decision boundary图1 不均衡分布对决策面影响展示图
近年来,关于不均衡分类研究的问题越来越受到重视,并提出了一系列处理不均衡的方法[1,6]。为了解决不均衡问题,像欠采样和过采样等方法广泛用于处理不均衡数据集。其中欠采样需要删除一些多数类样本以平衡数据集,但是这类方法会存在删除有价值和有代表性样本的风险;过采样是另一种在少数类中添加新样本的采样方法,但是过采样方法仍可能会产生不准确的样本,导致过拟合和重叠问题。
与此同时,代价敏感度学习是另外一种处理平衡问题的方法,该方法考虑了在算法层面上错误分类样本和代价成本的关系。代价敏感的学习方法的设计理念是当少数类样本错误分类时,会对其增加昂贵的成本,从而强调对少数样本的任何正确分类或错误分类的代价差异性。最近几年关于不均衡类分布的代价敏感学习的研究主要包括由Shao等人[7]提出的一种有效的加权拉格朗日双SVM(support vector machine),Cao 等人[8]提出的一种优化的代价敏感SVM,Katsumata 等人[9]提出应用SVM 作为稳健的代价敏感分类技术。
本文主要处理不均衡数据为图像数据集,以此需要考虑特征提取对以后分类的影响,从而本文选取了新的特征提取器压缩激励网络,以此来提取更有价值的特征信息。同时为了避免冗余样本和噪声样本对分类的影响,通过支持向量机来自适应地选取有价值的样本点。与此同时,为了处理最终选取的不均衡价值样本集,应用与以往不同的代价敏感学习机制,不仅针对类之间样本点的不同,而且针对类内样本点的不同来自适应地分配不同的权重,以此来提升最终分类的性能。
因此,为了选择有价值的样本信息并针对少数类样本自适应分配不同的权重,本文提出了一种结合价值样本选择器和自适应样本的代价敏感学习的新框架SSIC 来处理二分类中不均衡图像数据。该框架首先考虑到数据的统计特性,将数据中多数类分成多块和少数类数量相同的数据。然后每块多数类样本分别和少数类样本结合作为输入,之后使用压缩和激励网络[10]作为特征提取器组件来更好地提取特征信息。随后应用支持向量机自适应地从每块数据集中选择有价值的样本。此外,为了处理最终选取的不均衡价值样本,本文使用改进的代价敏感SVM 作为最终分类器。本文提出的框架可以最小化训练数据中不均衡分布的影响,并提高代价敏感学习的分类性能。
2 相关工作
现有研究的不均衡数据处理方法可以分为两种类型,即基于数据层面方法和基于算法层面方法。基于数据层面方法通过对少数类进行过采样或对多数类进行欠采样来均衡训练数据集中的样本数。而后者主要修改现有算法以更多地强调少数类样本的重要性[6,11],其中一种策略是代价敏感学习[1,12],它在区分少数类的同时可以保持原始类的分布。
2.1 采样方法
采样方法被认为是一种在数据层面对不均衡处理的数据预处理技术。在以往的文献中,总体来说有两种不同类型的采样方法被提出:欠采样和过采样。它们通过减少多数类样本或增加少数类样本来将不均衡数据转换为均衡数据,然后应用传统分类器训练最终的均衡数据集。
随机欠采样是一种流行并且很直接的方法,这种方法通过随机减少多数类样本来均衡不同类之间的样本数量,然而这种随机欠采样方法往往会导致大量有价值信息的丢失。因此为了更合理地对多数类样本进行欠采样,许多欠采样方法引入了数据清理策略,从而删除多数类中的重叠样本并提高分类性能,如精简的最近邻规则Tomek Links[13](CNN+Tomek Links)集成方法[14],以及基于编辑的最近邻清理规则(edited nearest neighbor,ENN)[15]等。但是,如上改进的欠采样方法还是会导致改变多数类样本的结构信息,并且会失去一部分有价值的信息。
过采样是另外一种处理不均衡数据的策略。过采样主要包括随机复制少数类样本或者生成新样本来增加少数类数量。通过随机复制得到的样本与原始样本具有高度相似性,这容易导致过度拟合问题。为了克服随机过采样问题,初始考虑样本分布的SMOTE[16](synthetic minority over-sampling technique)算法被提出,但SMOTE算法也有其缺点,包括出现过度泛化和方差[1]问题。随后如何选择过采样参考样本以及如何设计生成新样本的生成器成为过采样研究的核心问题。例如,一些代表性工作包括Borderline-SMOTE[17]、自适应生成采样ADASYN[18]和Kernel-ADASYN[19]算法。但是,所有过采样方法都会改变原始数据的分布,并可能生成导致过度拟合和重叠问题的不准确样本。
2.2 代价敏感学习
除了通过不同的采样策略来生成均衡的数据分布外,代价敏感学习是不均衡分类中另一个最重要的技术,并且近年来引起了极大的关注[1]。代价敏感学习通过使用不同的代价矩阵来描述任何错误分类的样本的代价,从而解决不均衡学习问题。代价敏感的目标是在不改变类分布的情况下为错误分类样本分配更大权重值[20]。
如今针对不均衡分类问题已经提出了许多不同的代价敏感学习的方法。在文献[21]中提出zSVM 是针对SVM 从不均衡数据集学习中修改算法之一,这是一种典型的阈值调整方法,通过将z的值从0 逐渐增加到某个少数值来优化z值。在文献[7]中,Shao等人通过使用基于图的欠采样策略来保留邻近信息并将权重偏差嵌入拉格朗日TWSVM(weighted Lagrangian twin support vector machine)公式中。在文献[22]中,Cheng 等人引入了指数参数来加强权衡参数的影响。Yan 等人[23]提出了一种新的代价敏感方法,其惩罚参数C基于聚类概率密度函数(probability density function,PDF)进行优化。但是,上述方法都没有考虑同一类中样本之间的差异性。
基于以上的采样方法和代价敏感学习,首先并没有考虑到有价值样本选取问题,其次也没有考虑到同类别的样本之间的差异性问题。因此,本文将价值样本选取与自适应样本的代价敏感学习用于处理不均衡框架中,从而在数据和模型层面上来处理不均衡问题。
3 SSIC 框架
本章提出了一个新的结合特征提取器压缩激励网络[10],价值样本选择器SVM 和代价敏感学习来处理不均衡数据的框架SSIC。在该框架中本文首先考虑到数据的统计特性,先将多数类样本分成多块与少数类样本数量相同的数据集,分别和少数类样本结合作为输入的训练集。与此同时本文为实现之后的高效训练,使用压缩激励网络从每块均衡数据中提取高级特征。然后本文使用SVM 自适应地从每块提取特征的数据集中选取有价值的样本。最后将最终选取的价值样本用改进的代价敏感SVM 来进行最终的分类。最终提出的整体框架SSIC 如图2 所示。SSIC 的主要贡献是同时在数据和模型的层面上来处理类不均衡问题。另一方面,本文使用SVM 来选择价值样本数据也一步简化复杂的学习任务。

Fig.2 Illustration of proposed SSIC framework图2 提出的SSIC 框架展示图
给定二分类数据集,其中训练数据集S={(xi,yi)|,yi∈{+1,-1,i=1,2,…,n},xi指第i个样本的特征向量,Smin与Smax分别为少数类和多数类样本集,其中S=Smin∪Smax。
3.1 价值样本选择器
为了选取更有价值的样本点,如图2 所示,本文充分考虑了数据的统计特性,首先从多数类样本Smax中分别选取多块子集Ni,使与少数类样本点数量相等,即|Ni|=|Smin|,之后将每块子集Ni分别与P(即Smin)组成多块子集Si,Si=P∪Ni。然后本文对每块子集Si使用压缩激励网络来提取更高级特征,与以往特征提取技术不同,压缩激励网络对图像数据的信道信息进行考虑,针对不同信道赋予不同的权重,从而压缩激励网络作为特征提取器不仅考虑了空间信息而且考虑到了信道之间的关联信息,以此获得原始输入数据更好的结构化特征表示。
在此特征提取的基础上,为了避免一些噪声或者冗余数据的存在,本文要从提取特征的每块数据集中自适应地选取有价值的样本。如图2 所示,由于样本的信息差异性和其与超平面的距离是同义的,如果样本越远离超平面,则分类器对其类标签信任度越大,因此这部分数据对分类器的影响很小。而另一方面,靠近超平面的样本却能向分类器提供最多有价值的信息[1]。因此,本文训练具有这些特征的SVM 分类器以自适应地检测每块数据集中每个样本与超平面的距离并关注最接近超平面的样本,这对于最终分类来说是至关重要的。图2 总结了选择有价值样本过程。
3.2 价值样本权重赋值
为了解决不均衡分类问题,以往的代价敏感策略为正类样本赋予较高的权重C+,为负类样本赋予较低的权重C-,通常令C+/C-=ratio[12],以使得在提升少数类误分代价的同时,保证多数类样本的权重总和与少数类相等。然而,这种权重的设置只考虑到不同类间样本重要性的差异,没有考虑到同一类内样本之间重要性的差异。因此,作为前期工作的延续,本文依然通过K近邻的方式来评估同一类样本的重要性差异。然而此时处理的样本为已经选定好的价值样本,此时需要针对价值样本的近邻个数来进行权重的设定,如针对少数类样本,近邻中多数类样本数越多,则赋予的权重更高些。基于这种权重的设置,不仅可以保证多数类样本的权重高于少数类样本,同时也为相同类别中更重要的样本赋予了更高的权重,以此提升模型对不均衡数据的分类性能。
为了使代价敏感SVM 能够更有效地应用于不均衡分类,自适应成本敏感学习通过为每个样本引入θi得到自适应不均衡分类器,目标函数如下:
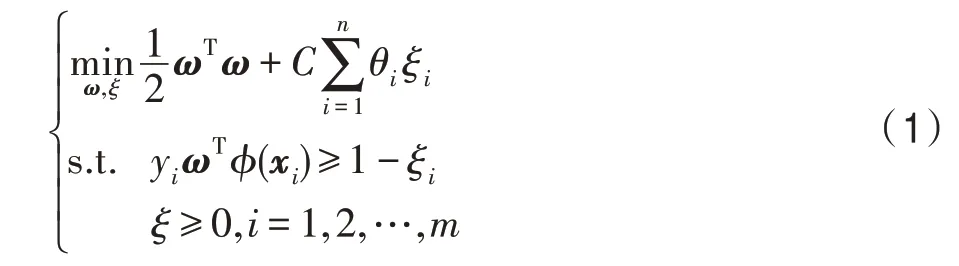
其中,xi表示第i个样本的特征向量,yi表示相应的标签,m表示最终选择的价值样本的个数。同时,考虑到少数类样本的预测结果比多数类样本重要性更高些,为了简化模型复杂度并降低计算复杂度,本文只仔细区分少数类样本的权重。因此本文在式(2)中重新为每个样本定义了θi。

为了能够针对不同少数类样本计算不同的权重值,本文将K近邻方法引入到模型中,如式(3)所示,其中定义为少数类样本近邻为多数类样本的个数,k定义为近邻样本的个数。m-为有价值的多数类样本个数,为有价值少数类样本中noise 样本。如果少数类近邻都为多数类,即为noise 点,本文将其权重值设为0。
4 实验与分析
为了验证本文提出的新框架在不均衡分类问题中的有效性,本章提出了广泛的实验研究来证明本文算法的性能提升和有效性。
4.1 数据集
MNIST 被认为是简单且解决了涉及数字图像分类的问题。数据集由尺寸为28×28 的灰度图像组成。有10个类对应于从0 到9 的数字。原始训练数据集中每个类的样本数量从第5 类中的5 421 到第1类中的6 742。CIFAR-10和CIFAR-100是比MNIST更复杂的图像分类问题。CIFAR-10包含10类32×32的自然物体彩色图像。初始数据集中每个类都有5 000个训练样本和1 000个测试样本。CIFAR-100 包含属于100个类(600个图像/类)的60 000个图像,这些图像进一步分为20个超类。每个类别的标准训练/测试分组包含500/100图像。Tiny ImageNet数据集是ILSV—RC2014 数据集中的一个标准子集,具有200个类。每个类别有500个训练图像,50个验证图像和50个测试图像。每个图像已经下采样到64×64 像素。
为了评估本文的框架在各种尺度数据集上性能提升情况,本文从上面的数据集中分别选取了两类不同的数据集。用随机抽取样本的方式在两类样本中分别抽取样本数有差距的两类样本,同时为了使数据具有不同程度的不均衡度,本文将每个提取的数据集中两类中的一类分别减少到与另外一类不同比例的图像数量,如1∶10,1∶100 等,根据后边实验来提取不同比例的数据。
4.2 方法与指标设定
为了测试本文提出的方法的有效性,本文将提出的方法与其他方法进行了对比。在对比方法中,本文采用SMOTE和ADASYN(adaptive synthetic sampling approach)作为过采样方法,由Python Imbalanced-Learn Library(版本0.4.3)实现。以上两种采样方法在通过压缩激励网络选取样本特征后,分别和价值样本选择器结合(SMOTE_SS 和ADASYN_SS)以及不与价值样本选择器结合(SMOTE_S 和ADASYN_S)作为最终的对比方法。在此过程中,本文将SVM 作为最终的分类器。同时,本文还将SSIC 框架与RCSSVM(robust cost sensitive support vector machine)[9]进行比较,以展示本文的方法的优势。
在本实验中,本文使用第4.1 节中描述的数据集来评估SSIC 框架性能。在不均衡分类中,准确性不是评估方法性能的适当措施,因此本文使用以下常用于不均衡数据分类的性能度量指标来评价不同分类器的分类性能,分别为负类查准率(Precision_N),正类查全率(Recall_P)以及宏观F1 度量(F_macro)。
4.3 结果与分析
为了在不均衡学习中用其他方法评估本文提出的框架的性能,进行了不同类型实验来展示所提出框架的有效性。首先,本文评估了针对具有不同不均衡率的CIFAR-10 数据集来展示框架的敏感性能。然后,本文比较了在CIFAR-100 数据集的特定比率下SSIC 和其他方法的柱状图的性能展示。最后,本文研究了MNIST 数据集与Tiny ImageNet 数据集中不同指标下提出框架与其他方法的性能改进。
首先本文将提出的框架在不同不均衡率的CIFAR-10 数据集上性能变化情况的对比图以及选取不同类别的CIFAR-100 数据集与其他方法的性能进行展示。通过图3 与图4 中显示的性能对比结果,图3 中(a)、(b)图分别表示在类别为(2,6)两类不均衡数据和(5,9)两类不均衡数据在Recall 指标上性能对比。图4 中(a)、(b)图表示在类别为(2,6)两类不均衡数据和(5,9)两类不均衡数据在F_macro指标上性能对比。通过本文可以发现SSIC 框架几乎是所有情况下的最佳方法。随着不均衡率的逐渐增加,曲线图上也显示出在大多数情况下,SSIC 性能都有所提升,并且从曲线图中分析,SSIC 在CIFAR-10 数据集的性能未显著下降。特别是对于少数类的召回率值,SSIC 对少数类的性能有所提高,这表明在选取有价值样本后并自适应地为不同的少数类样本分配权重是非常有效的。

Fig.3 Comparison of methods with respect to Recall_P on CIFAR-10图3 不同对比方法在CIFAR-10 上Recall_P 性能

Fig.4 Comparison of methods with respect to F_macro on CIFAR-10图4 不同对比方法在CIFAR-10 上F_macro 性能
图5 中展示了CIFAR-100 数据集中不同类别和固定不均衡比率的性能对比结果。对于少数类中每个类的召回率和F_macro值的情况,SSIC 和其他方法相比性能得到提升。从柱状图中看出SSIC 框架针对少数类可以获得更好的召回率,F_macro值也有很好的提升效果,从而也说明该框架对于更多的关注有价值的样本是有效的,与此同时针对不同少数类样本赋予不同的权重值也能针对不均衡数据增强分类器的性能。
除以上两个数据集的性能展示外,在MNIST 和Tiny ImageNet 数据集上进行的实验同样证实SSIC在不均衡数据分类的有效性。表1 和表2 分别比较不同类别MNIST 和Tiny ImageNet 数据集的负类查准率(Precision_N)、正类查全率(Recall_P)以及宏观F1 度量(F_macro)这三个指标的提升状况。MNIST数据集与Tiny ImageNet 数据集不均衡比分别定义为100 和10。结果证实提出的框架在所有数据集的表现优于任何其他方法,以此证明SSIC框架的优异性能。
此外,本文还展示SSIC 与以往不选取价值样本的样本自适应的代价敏感分类器(SA-SVM)[24]进行对比,并展示在F_macro上的提升值,提升值定义如下:


Table 1 Comparison of SSIC with other methods on MNIST dataset表1 在MINIST 数据集上SSIC 与其他方法的对比

Table 2 Comparison of SSIC with other methods on Tiny ImageNet dataset表2 在Tiny ImageNet数据集上SSIC 与其他方法的对比
其中,Rec1代表SSIC 的F_macro值,Rec2代表SASVM 的F_macro值,用CIFAR-10 与CIFAR-100 分别选取不均衡两类数据进行对比,其中不均衡率分别为100和10。
从图6 中可以看出,相比于SA-SVM,SSIC 框架在这两种指标上都有所提升。从Recall_P上的提升看,自适应地选取有价值的样本是非常有必要的。从F_macro的指标提升上来看,选取有价值的样本针对于多数类样本点的性能也有所提升,因为选取价值样本过程也避免了部分冗余和噪音的样本对分类器的一些困扰,以此使性能有了提升。
5 结束语

Fig.6 Relative improvement of Recall_P and F_macro made by SSIC related to SA-SVM图6 SSIC 与SA-SVM 在Recall_P 和F_macro 上的相对提升值
随着大数据时代的发展,不均衡数据分类问题的研究受到了广泛关注,然而由于数据集在数量上严重失衡,传统的学习方法不能有效地对其进行学习。为了处理不均衡分类问题,本文提出了一种新的框架SSIC。首先SSIC 框架充分考虑数据统计特性,将数据集中的多数类分成与少数类样本数目相同的几块数据集,分别与少数类样本结合作为初始的训练集,同时结合压缩激励网络从每块数据集分别提取高级特征。在提取特征的基础上,SSIC 从每块提取特征中自适应地选取一些更有价值的样本来作为最终的输入,以此减少部分噪音或者冗余样本的影响。通过选取价值样本,本文使用自适应权重分配的分类器来进行最终分类,此分类考虑少数类中不同样本的差异性,从而更好地处理不均衡问题。而在现实生活中,存在更复杂的数据集,例如:多类数据集、多标签数据集和更高维数据集等。因此,本文后续的工作会扩展所提出的框架并使其能够处理这些复杂的情况。
