面向开源源码大数据的数据质量研究*
2020-03-19包盼盼陶传奇黄志球
包盼盼,陶传奇,2,3,4+,黄志球,2,4
1.南京航空航天大学 计算机科学与技术学院,南京210016
2.南京航空航天大学 高安全系统的软件开发与验证技术工信部重点实验室,南京210016
3.南京大学 计算机软件新技术国家重点实验室,南京210023
4.软件新技术与产业化协同创新中心,南京210016
1 引言
为了帮助开发人员进行代码复用,部分研究人员关注编程智能化相关的研究。比如,在代码推荐中,Jiang 等人[1]将机器学习算法和传统信息检索方法结合进行方法块推荐,Gu 等人[2]利用深度学习方法进行API(application programming interface)使用序列的推荐。但是,大部分编程智能化相关的研究都聚焦于各种算法的研究,而忽略了研究所使用数据的质量问题。大部分相关研究中所使用的数据都来源于GitHub。GitHub 作为开源平台,项目托管者可能来自正规组织或软件公司(如Apache、Google 等),也有可能是新手开发者,由于开发者代码编写水平参差不齐,GitHub 上的项目并不能保证都具有较高质量。根据“garbage in,garbage out”,源码的数据质量会对基于大规模源码进行智能化学习的结果质量产生重要影响。
当前对开源源码数据进行处理的工作主要关注数据的过滤、清洗等。比如,江贺等人在进行方法块推荐的相关研究时,对采集的数据进行了筛选处理,包括删除代码行数少于5 行的代码片段和删除结果中可能重复的方法块。但是,鉴于源码数据的复杂性[3],简单处理较难满足研究人员对代码数据质量的要求。结合传统的数据清洗相关研究可以发现,方法块的冗余清除属于重复对象检测,仅仅是数据清洗研究内容的一方面。代码数据集作为智能化编程系统研究的基础,其数据质量的问题还缺乏相关的研究。
针对上述问题,本文对已有的开源数据托管平台上的海量源码数据进行综合分析,从不同的维度对源码数据质量进行评估,并建立一种面向开源源码大数据的质量分析方法。本文工作的主要贡献在于,考虑到已有研究工作的困难和不足,研究回答了以下两个重要问题:
(1)开源项目托管平台上的源码数据可能存在哪些质量问题。
(2)如何利用定性或定量的方式对开源代码数据质量进行评估。
2 研究背景
本文以国际通用的开源软件代码库GitHub 中的开源项目作为代码数据质量问题的研究对象。
通过对各种智能化编程系统的调研分析,以推荐系统为例,根据推荐结果进行分类,比较常见的推荐系统类型有方法块推荐[1]、API 序列推荐[2]、token 以及tokens 推荐[4-5]等。总的来说,其数据粒度小于等于方法块,因此以方法块作为数据质量评估的基本单元具有代表性和通用性。因此,本文评估的对象选择的是从开源项目中抽取的方法块。
本文分别以线上和线下两大类数据信息对源码数据质量进行评估。
线上数据信息来自于GitHub 中包含的对应项目信息。GitHub 代码库中包含对应项目的各种统计信息,包括Watch、Star 和Fork 等,这些统计信息中隐含着对应项目一定程度的质量信息,如果能够找到合适的指标并充分使用,就能在一定程度上对项目质量进行评估。本文在充分理解各个统计指标的基础上,综合使用各种指标信息来对项目质量进行科学可信的评估。图1 所示是GitHub 上单个项目的主页中10个可能包含项目质量信息的统计指标。
线下数据信息来源于项目本身,主要是源码质量[6-7]信息、方法块功能重复[8]信息和自定义方法调用信息等。因为本文选择以方法块作为数据质量评估基本单元,所以除了源码本身质量以外,是否具有独立、完整的功能也应该作为方法块数据质量的衡量维度之一。
这些方法块通常会被用于构建智能化编程系统所使用的数据集,因此本文希望能够帮助相关领域研究人员得到海量的、编程风格良好的、具有尽可能少的缺陷以及具有独立完整功能的方法块数据集。
代码数据质量评估核心在于选用哪些维度进行数据质量衡量,以及如何具体地评估各个维度,方法则主要有定性和定量两类。这也是本文主要的研究内容。
3 开源源码数据质量问题
本章研究回答两个重要问题中的第一个,即开源项目托管平台上的源码数据可能存在哪些质量问题。
本文的数据质量评估方法不局限于具体的程序设计语言,为了方便描述,本文用Java 程序设计语言为例进行陈述。
3.1 项目作者可信度问题
传统衡量GitHub 代码质量的方法通常基于项目的star数,即一个项目具有的star数越高,该项目质量越高。某些公司在招聘开发人员时,一个重要的加分项就是应聘者拥有高star数的GitHub 项目。然而,调查发现,部分被调查者有过帮助GitHub 项目作者“刷star”的行为。正是这样的欺诈行为的存在,使得GitHub 上低质量的项目也可能具有较高的star 数,因此本文将作者刷star 数量的行为作为一个重要的数据质量参数。
本文希望能够帮助智能化编程领域相关的研究人员得到海量的高质量方法块,因此如果能够判定某个具有高质量项目的作者确实是可信的,通常认为该作者具有较高的编程能力。进一步认为该作者的相关项目具有较高的质量,即使它们或许在单个项目统计指标上的数据质量并不是最优。
3.2 项目健康度问题
GitHub 作为全世界最大的开源项目托管平台,拥有海量的开源代码项目,给源代码方面相关研究提供了极为丰富的数据资源。但因为其作为项目托管平台,任何开发人员都可以在GitHub 上托管自己的任何项目。项目托管者可能是Apache、Google 这样的正规组织及软件公司,也有可能是正在学习编程开发的新手开发者。因此,开源平台上的项目质量也参差不齐,并不能保证都具有较高质量。
项目本身作为比方法块更大的粒度级别[9],其质量的高低在一定程度上可以表征对应方法块的质量。因此对方法块进行质量评估,首先要对对应的项目整体进行评估。因此如何对海量的开源项目中单个项目进行质量评估也是一个重要的研究问题。
3.3 源码质量问题
一个通过编译的Java 项目,其源码中仍然可能含有一些问题[10-12]。比如,不符合命名规则的变量或方法命名、未使用的局部变量或参数、空的try 语句等。如图2 所示,一个能够运行的方法块中仍然存在一些问题,1 和3 是不规范的变量命名,2 是没有使用的对象。
从方法粒度级别来看,这些问题通常不会影响方法块的功能实现。但在更小粒度上,比如进行API、API 序列、token sequence 等相关研究时,上述问题就会产生较大影响。比如,进行token sequence 相关研究时,需要对源码中用户自定义的变量名进行统一化处理,而不符合命名规范的变量名可能会对该处理操作带来困难。
因此,源码本身也是代码数据质量评估的一个重要方面。源码本身可能存在哪些问题和如何找出以及统计这些问题是本文一个重要的研究内容。
3.4 方法块功能常用性问题
删除数据集中的重复方法块可以解决数据冗余问题,尽可能使数据集具有最小性,在整个数据集层面上是必要的。但换个角度看,一个方法块在整个数据集中的冗余程度越高,它所具有的功能就越常用[13]。比如,在Java 开发中,两个方法块分别具有功能“Write content to file”和功能“Serialize an object to a file”,两个都是比较常见的功能需求。但是前一个功能更常见,所以一个进行方法块推荐的系统所使用的数据集中更应该包含前者,否则可能会导致用户需要却无法获取该功能。因此从方法块数据质量评估的角度来看,功能越重复的方法块,它的质量应该越高。
因此在方法块功能维度上,本文需要解决如何对方法块相似度进行计算[14]以及得到一个相似度阈值,使得能够判定相似度大于该阈值的两个方法块功能是相似的。
3.5 方法块功能原子性问题
正如之前所述,进行质量评估之后的方法块会被用于构建智能化学习的数据集,比如用于方法块和API 序列等推荐。无论方法块最终会被用于哪种类型的代码推荐,它都应该尽量具有独立完整的功能,即在方法体中尽可能没有对其他自定义方法的调用操作。
以方法块推荐为例,如果一个方法块中存在对其他自定义方法的调用,那么即使在最终推荐时用户获取到该方法块,但由于调用方法的缺失,用户也无法使用,这样就使得推荐结果在一定程度上丧失了实用性。因此,如果一个方法块中存在对自定义方法调用,该维度上应该被评估具有较低的质量。
4 开源源码数据质量评估
本章研究回答之前所述两个重要问题中的第2个,即如何利用定性或定量的方式对开源代码数据质量进行评估。如图3 所示,本文的评估方法包含5个维度。

Fig.2 Example of method that is still problematic through compiling图2 一个通过编译仍存在问题的方法块示例

Fig.3 5 quality evaluation dimensions for open source big data图3 面向开源源码大数据的5个质量评估维度
本文的评估方法充分利用作者可信度、项目健康度、源码质量、方法块功能常用性和方法块功能原子性5个维度信息,得到单个方法块的评估结果。一个完整的评估流程如图4 所示。
4.1 项目作者可信度评估
GitHub 的项目托管者刷star 数一般有两种常见的方式:请其他的GitHub 用户帮其进行该行为和委托该服务的提供商实施该行为。一般来说,第一种规模较小;第二种,结合图2 内容可知,规模可以较大,并且可能存在同时刷star以及fork 的行为。
针对上述两种情况,本文提出的解决方案是,通过从可信的GitHub 作者信息中获取可信作者具有的一般规律。因此,本文的解决方法是通过在具有较高质量的项目地址集上计算watch/(watch+star+fork)的值,评估项目作者可信度。具体来说,利用收集的365个具有较高质量的项目地址,获取其项目托管者主页地址,进而获取该作者在GitHub 上所有项目地址。然后,利用获取到的地址,获取对应项目watch、star 和fork 数,将各项对应相加之后,得到每个作者GitHub 所有项目得到的watch、star 和fork 总数。然后按照上述计算方法,得到watch/(watch+star+fork)的值,该值表征了该可信任GitHub 作者在该质量维度上的定量情况。计算对应作者所有项目总和在watch/(watch+star+fork)的值实际在一定程度上反映了该作者是否存在刷star 以及fork 的行为,比值越小,可能性越高。部分GitHub 作者对应总watch、star和fork 数统计和比值情况如表1 所示。

Table 1 Numbers and ratios information of some GitHub authors’total watch,star and fork表1 部分GitHub 作者总watch、star和fork 数统计以及比值情况
为了避免极端数值的影响,阈值计算方式是将365个watch/(watch+star+fork)比值去掉5个最大值和5个最小值之后,计算剩余355个值的平均值作为最终的阈值。最终计算得到的阈值保留3 位小数后为0.058。因此,对GitHub 项目作者可信度的评估方法为,计算对应作者所有项目总和在watch/(watch+star+fork)的值,如果值高于阈值0.058,则评估为可信。
4.2 项目健康度评估

Fig.4 Complete flow chart of data quality evaluation for method block图4 一个完整的方法块数据质量评估流程图
GitHub 每个项目主页会显示对应项目的各种统计信息,包括Watch、Star 和Projects 等。为了进行项目健康度评估,本文构建了一个Java 项目数据集,共包含6 000个Java 项目地址,该数据集可以在一定程度上代表GitHub 总体Java 数据质量情况。根据已有的数据集和指标,本文对项目质量进行评估的基本想法是,给出GitHub 总体Java 项目的一般性质量表征,然后对单个Java 项目,根据其对应指标上的对比,可以得到该项目的一个定性的质量度量。
在指标选取上,根据对有GitHub 使用经验的人员进行广泛的信息收集,最终确定选用的指标为Watch、Star、Fork、Issues、Pull requests 和commits,并且对这6个指标分别计算阈值,然后得到一个项目健康度的定性评估方法。
为了降低极端值对阈值的影响,本文先统计6 000个项目各个指标值的对应各个值出现次数,按照出现次数从高到低进行排序,然后取前0.3 的次数值计算平均值得到各个指标对应的阈值。阈值计算过程如算法1 所示。
算法1 项目健康度评估的阈值计算


如算法1 描述,首先对6 000个项目数据,针对指标Watch、Star、Fork、Issues、Pull requests 和commits分别获取每个项目的单个指标值,并统计各个指标值的对应各个值出现次数。比如,项目1 的Watch 指标值为200,则以200 为Watch 指标HashMap 的key、1为value,如果项目2 的Watch指标值也为200,则HashMap 中key 为200 的value 变为2。循环执行得到所有指标对应数值以及值的出现次数。然后,对各个指标对应的HashMap 按照value 大小从大到小排序,取前面的30%的数据,取出HashMap 中key 和value值,并计算均值,即得到对应指标的阈值。
本算法的优点在于:第一可以消除极端值对阈值的影响;第二可以利用更具有代表性的值来计算阈值。最终,保留3 位小数后,计算得到的各个指标对应阈值如表2 所示。

Table 2 Corresponding threshold value for each metric表2 各个指标对应阈值
因此,最终确定的对GitHub 项目质量进行评估方法为,采用定性的方式,待评估项目在对应指标上高于阈值则可以判定为质量较高。此外,由于本文给出了每个指标的对应阈值,用户也可以根据自身需求,只采用其中部分指标,或者是根据需要给指标指定优先级,进而进行项目质量的评估。这样可以更好地满足用户的特定需求,具有更好的实用性。
4.3 源码质量评估
源码质量评估主要分析源码本身可能存在哪些问题以及如何对这些问题进行定性或定量度量。本文利用静态代码分析方法[15],使用PMD(programming mistake detector)来对源码中缺陷进行分析和统计。选择PMD 的理由有两点:首先,PMD 是一种比较常用的静态代码分析工具,其性能值得信赖;此外,PMD 和脚本语言的结合使用,能够对Java 项目进行批量化静态分析。PMD 通过其内置的编码规则对Java 代码进行静态检查,主要包括对潜在的bug、未使用的代码、重复的代码、循环体创建新对象等问题的检查,这些规则在一定程度上覆盖了源码本身可能存在的问题,因此可以充分利用已有规则找出源码中可能含有的问题。
本文需要解决的一个问题是:PMD 进行静态代码分析的基本单位是Java 文件,而本文的目标是对一个Java 方法块进行缺陷类型和数量进行统计。为了解决这个问题,可以将PMD 和Java 抽象语法树(abstract syntax tree,AST)结合使用。
另一个问题是,Java 代码中不同的问题对源码数据质量影响程度不同,因此对应的PMD 内置规则也应该具有不同的优先级。为了解决这个问题,将调查研究和统计方法相结合。首先,根据30个具有4~6年Java 开发经验人员的意见,选择比较重要的8个PMD 规则集。然后,在质量比较高的Java 项目集中对不同PMD 规则集检查出的问题进行数量统计,在这些项目中某类问题出现次数越多,说明该类问题对源码数据质量影响越小。这里所使用的高质量Java 项目集是具有较高质量的项目中的Java 项目,共选用了45个。如表3 所示,是在45个高质量Java 项目上统计出的8个PMD 规则集对应的问题数量。
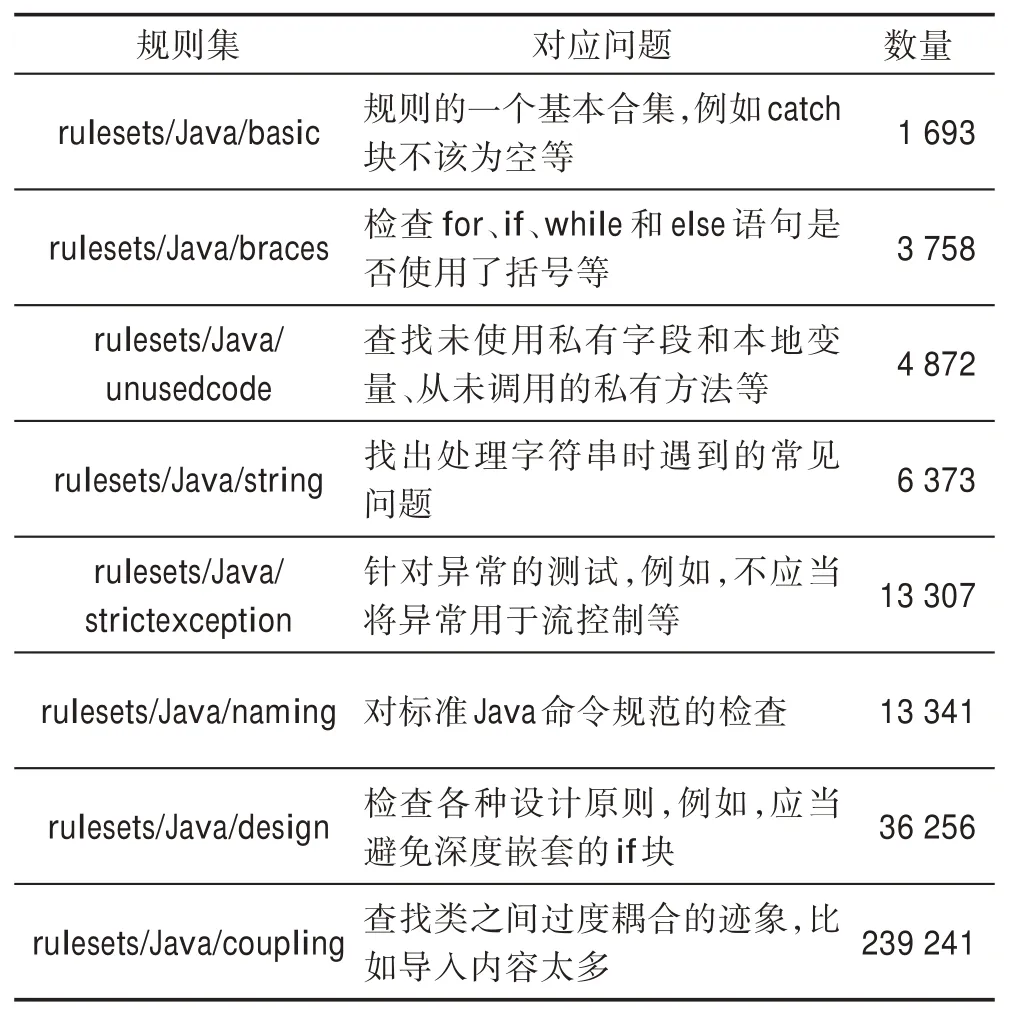
Table 3 8 types of PMD rules in high quality Java project sets表3 高质量Java 项目集中8 类PMD 规则检查情况
根据表3 的数量统计情况,可以得到各个规则集对应的优先级。在源码质量维度,本文使用这些PMD 规则集来进行质量评估,最终用户可以根据各个规则集在某个方法块中检查出问题的数量,结合已经测定的优先级,对该方法块质量进行定性的评估。
4.4 方法块功能常用性评估
一个方法块在整个数据集中冗余程度越高,对该方法块自身而言,它所具有的功能就越常用。因此,本文从方法块功能常用性维度对其质量进行评估。在该维度上,需要确定方法块相似度的计算方法以及相似度阈值的计算方法。
本文选择使用Simhash[16-17]方法计算方法块相似度。选择的原因主要有两个:(1)Simhash 是用来进行网页去重常用的高效方法,而评估方法块功能是否常见需要将单个方法块和数据集中每个方法进行相似度计算,因此计算速度对实用性影响较大;(2)Simhash 是一种局部敏感hash,如果两个字符串具有一定的相似性,在hash 之后,仍然能保持这种相似性。而这是进行代码相似度计算中的重要特性。
在相似度阈值计算方面,首先从Stack Overflow和相关论文中获取10个比较常见的Java 方法块功能需求。然后,将10个指定的功能发布给30个具有4~6年Java 开发经验的开发人员进行Java 方法块编写,最终得到10 组共300个具有相同功能的方法块。相似度阈值通过对10 组方法块计算相似度并取平均得到,保留两位小数之后的值为0.82。
本文考虑对单个方法块质量进行评估,而不是构建方法块数据集,因此还需构建一个用于和被评估方法块计算相似度的方法块数据集。并且,将不具有实际功能的main()函数、set()/get()函数、测试单元以及部分重写函数等函数进行清除。最终可以根据给定的数据集,计算待评估方法块与数据集中方法块功能的相似性,并根据阈值评估该方法块功能的常见程度,用户可以决定是否使用该方法块。
4.5 方法块功能原子性评估
方法块功能的独立完整性作为方法块数据质量评估的一个维度是有必要的。这里需要统计方法块中对自定义方法的具体的调用次数。
首先,对一个Java 项目中所有Java 文件分别构建一个抽象语法树。利用该语法树来识别Java 类中所有方法调用以及其所属的方法块。对方法中的所有方法调用进行处理之后,可以得到对应方法块中所有方法调用所使用方法的方法名及所属类,然后以类名+方法名的形式进行保存。对方法块进行识别、切分和保存之后,可以进一步抽取所有方法块对应方法名及其所属的自定义Java 类,进而得到单个Java 项目中所有的自定义方法的方法名,并同样以类名+方法名的形式进行保存。最后,将单个方法所调用方法和自定义方法进行比较,如果存在交集,则存在自定义方法调用情况,也可以统计出总的调用次数。并且,由于利用了方法所属类的信息,即使存在自定义方法和Java 已有方法或第三方JAR 包中方法同名的现象,也能根据所属类信息进行区分。而类名和方法名都重名的情况,本文认为该情况比较极端,暂且不予考虑。
因此针对方法块功能完整性评估,最终得到的是单个方法块中对自定义方法的调用次数。根据该值,用户可以判断对应方法块功能是否独立完整,以及对其他方法块功能依赖程度,最终决定是否使用该方法块。
5 实例应用及方法有效性验证
本章系统化介绍对GitHub 上一个Java 项目实施完整的数据质量评估过程,将结合具体实例对提出的方法块评估方法的有效性进行验证。主要针对包含数值计算和阈值的维度进行验证,即项目作者可信度、项目健康度和方法块功能常用性维度。而源码质量和方法块功能完整性维度是指导性的评估,用户根据自身需求决定是否使用,本文不再专门进行有效性验证。
5.1 数据收集
本章在开源软件项目托管平台GitHub 上收集开源项目数据用于进行数据质量问题分析,按照需求的不同收集了两种不同质量级别的项目地址集。
第一种是具有平均数据质量的项目集地址,本文将该数据集作为GitHub 总体项目数据子集,能够在一定程度上代表GitHub 总的数据质量情况。因此,本文的收集方法是通过language 和star 对项目数据地址进行检索爬取。为了更具一般性,取star 数在0~10 000 之间,以这样的方式爬取到6 000个Java 项目地址,具有典型性和代表性。
第二种是具有较高质量的项目集地址,进而获取其项目托管者主页地址,这里不再针对特定语言。本文收集了365个,语言包括C、C++、Java、C#、Android、iOS 以及Python 在内的,公认具有较高质量的项目的作者主页地址,具有典型性和代表性。考虑到本文是利用高质量项目对应作者的信息来计算项目作者可信度阈值,相当于使用了365个专家信息,可以满足阈值的计算需求。部分项目信息如表4所示。

Table 4 Information of partial project examples with high quality表4 部分所使用的高质量项目信息示例
5.2 实例应用
为了更好地理解本文评估方法的评估过程,本文从GitHub 中随机抽取一个Java 项目进行实例应用分析,项目主页链接为https://github.com/mi***cs/mi***er。
首先进行项目作者可信度评估。利用项目主页链接,可以获取到对应作者主页链接为https://github.com/mi***cs,进而统计该作者对应的所有项目的watch、star 和fork 数量,分别为157、1 679 和292,计算watch/(watch+star+fork)比值为0.074。该值大于项目作者可信度阈值0.058,因此在项目作者可信度维度可以判定该项目的作者是可信的。
进行项目健康度评估时,根据项目主页链接可以获取到Watch、Star、Fork、Issues、Pull requests 和commits 这6个指标值分别为121、1 338、275、97、25和1 366,分别大于对应阈值11、76、28、4、1 和58。因此,在项目健康度维度该项目评估为健康。
在源码质量评估中,利用AST 和PMD 将项目中所有Java 文件以方法块为单位进行切分,并得到每个方法块中不同PMD 规则检测出的缺陷数量。该项目切分得到的方法块数量为380,每个方法块中对应各个规则缺陷数量不等。以方法块metricData 为例,该方法块中有3个rulesets/Java/naming 规则检测出的规范,而该规范优先级较低,即在一定程度上是可以接受的。因此,该源码质量评估中,方法块metricData可以评估为具有较高质量。
进行方法块功能常用性评估时,同样以方法块metricData 为例,先计算该方法块和方法块数据集中每个方法块相似度,计算后得到相似度最大为0.78,小于阈值0.82。因此,在方法块功能常见性维度,该方法块功能不是较常见的功能。
在方法块功能原子性评估中,利用AST 得到该方法块中调用的方法数量为6,但都不是自定义方法,也就是说该方法对自定义方法调用为0。因此,该方法块功能具有原子性。
综合上述5个维度的评估结果,虽然该方法块功能不是较常见的功能,但在其他4个维度的评估中评价较高,因此最终评估该方法块具有较高的质量。
同理,该项目对应的其他379个方法块按照metricData 的评估方式,可以继续得到源码质量评估、方法块功能常用性评估和方法块功能原子性评估的评估结果,得到5个不同维度的最终评估结果。最终,该项目对应的380个方法块中,337个方法块评估为具有较高质量,其他的43个方法块质量评估为较低。
5.3 方法有效性验证
对于作者可信度的评估方法是计算对应作者所有项目总和在watch/(watch+star+fork)的值,值高于阈值0.058 评估为可信。为了验证该方法和该阈值是否有效,本文随机爬取GitHub 中10个watch/(watch+star+fork)的值低于该阈值的项目作者主页,然后人为分析对应作者所有项目中是否存在有问题的项目。如表5 所示,是10个评估方法判定为不可信作者的具体信息统计情况。

Table 5 Statistics on 10 untrusted authors through proposed evaluation approach表5 10个评估为不可信作者的信息统计
从表5 可以看出,大部分项目作者可信度维度评估为不可信的作者最终人为检查中也是有问题的。这能够说明,至少在项目作者可信度这个维度上,本文的评估方式是比较合理的。
一个需要解释的地方是,10个评估为不可信的项目作者中有4个被人为判定为是可信的,这是因为本文对项目作者可信的评估比较严格。因为本文希望能够通过该维度的评估来帮助相关的研究人员得到海量的高质量方法块,所以判定某个具有高质量项目的作者确实是真实可信的,就认为该作者确实具有较高的编程能力。进一步就可以将该作者所有项目都视为具有较高的质量。因此总的来说,本文对项目作者可信度的评估方法以及评估阈值的设定还是比较合适的,确实能够在一定程度上识别有问题的项目作者。
对GitHub 项目健康度进行评估方法为,在对应指标Watch、Star、Fork、Issues、Pull requests 和commits上高于测定阈值则可以判定为质量较高。因此,为了对该评估方法进行验证,本文随机爬取了5个在不同指标上低于对应阈值的项目,然后人为分析其对应项目源码,判定其质量高低。具体项目信息统计情况如表6 所示。

Table 6 Statistics on 5 low-quality projects through proposed evaluation approach表6 5个评估为低质量项目的信息统计
通过表6 的内容,可以发现,5个在项目健康度维度评估为质量较低的项目,在人为评估中确实是由于各种不同的原因而具有较低的质量。并且其对应各个评估指标都具有较差的表现。
和项目作者评估类似,本文对项目健康度的评估也比较严格。因为本文的面向对象是智能化编程系统,比如代码推荐系统,源码质量可能对整个系统的性能影响都很大,本文希望能够尽可能地只收集质量较高的项目。因此,可能会舍弃掉一些质量并不低的项目。
本文对项目健康度的评估方法以及评估阈值的设定还是比较合适的,能够在一定程度上筛选出质量较高的项目。
针对方法块功能常用性的评估是根据本文构造的数据集,计算待评估方法块与数据集中方法块功能的相似性,然后可以根据阈值评估该方法块功能的常见程度。因此,对方法块功能常用性维度进行验证的方法是,对数据集中方法块相似度大于阈值的方法块功能进行人为获取,进而判断对应功能是否常见。具体来说,直接计算数据集中方法块之间相似度,并将相似度大于阈值的方法块归为一簇。对簇规模较大的簇中方法块功能常用性进行评估。为了和已构建的方法块数据集进行区分,从GitHub上另外爬取了200个Java 项目来构建验证所使用数据集,切分得到方法块总数为118 254。表7 所示为10个较大簇方法块功能信息。

Table 7 Statistics on commonly-used function information in 10 clusters表7 10个方法块簇功能常用性信息
通过表7 的内容可以发现,统计的10个规模较大的簇中方法块都具有较为清晰的功能实现,并且从功能上看也是比较常见的一些Java 功能需求。从每个簇中方法块数量来看,虽然数量大小和对应功能的常用性并不是严格一致,但是总体来说仍然具有一定的正相关性。
根据验证结果,本文给出的方法和测定的阈值确实能在一定程度上筛选出功能比较常见的方法块。因此,本文认为对方法块功能常用性评估方法是比较合适的。
5.4 实验讨论
本文通过大量调研发现,源码数据的质量对源码相关的研究有重大影响,并最终会对推荐结果的质量产生影响。这一点本文之前的代码推荐相关的研究工作中已经得到证实。
而已有的一些对收集到的数据进行处理的工作相对简单。比如,江贺等人在进行方法块推荐的相关研究时,对采集的数据进行了简单的筛选处理,这难以满足研究人员对代码数据质量的要求。已有的聚焦于源码数据质量的研究工作较少,并且更关注如何对数据进行清洗问题,如周傲英等人的研究重点就是对数据进行清洗。他们较为具体地说明了数据质量的重要性和衡量指标,定义了数据清洗问题。然后对数据清洗问题进行分类,并分析了解决这些问题的途径。还说明数据清洗研究与其他技术的结合情况,并分析了几种数据清洗框架。
而在本文中,综合考虑了项目作者可信度、项目健康度、源码质量、代码块功能常用性和代码块功能原子性,共5个维度对代码块质量进行评估,而不是对源码数据进行筛选或者清洗。本文最终给出对单个代码块的质量评估结果,将代码块的筛选工作交由进行具体研究工作的研究人员来完成,研究人员可以根据自身需求进行自主选择是否使用某个代码块。
本文方法的有效性在5.3 节进行了验证。对于作者可信度评估方法的验证,结果如5.3 节中表5 所示。从表5 可以看出,大部分项目作者可信度维度评估为不可信的作者最终人为检查中也是有问题的。这能够说明,在项目作者可信度这个维度上,本文的评估方式是比较合理的。对项目健康度评估方法的验证,结果如5.3 节表6 所示。5个被项目健康度评估维度的评估方法评估为质量较低的项目,在人为评估中确实是由于各种不同的原因而具有较低的质量。这在一定程度上说明了本文的项目健康度评估方法的有效性。针对方法块功能常用性评估方法的有效性验证,结果如5.3 节表7 所示。可以发现,本文给出的方法和测定的阈值确实能在一定程度上筛选出功能比较常见的方法块。因此,本文认为方法块功能常用性评估方法是有效的。
综上所述,数据质量问题相当重要但是没有引起足够重视,本文方法较为有效地弥补了编程智能化相关研究在数据质量评估问题上的不足,具有一定的实用性和创新性。
5.5 方法有效性威胁
首先会对本文的面向开源源码大数据质量评估方法的性能产生影响的是项目作者可信度维度。本文对该维度的评估主要是利用watch/(watch+star+fork)比值,因为本文考虑刷star 数的两种方式是请其他的GitHub 用户帮助进行该行为,以及委托专门提供该服务的服务商实施该行为,尤其是考虑到大量刷star 的行为只能通过服务商提供。因此,本文认为所提出的针对该维度的评估方式是比较合适的。但是,如果一个项目刷star 的方式主要是请其他的GitHub 用户帮助进行该行为,并且他委托的用户有很多,那么就可能造成对watch、star和fork的数量都有舞弊的行为,在这种情况下,本文针对该维度的评估方法可能就不太适用了。虽然这是一种极端情况,但是该情况确实对本文方法的有效性有很大的威胁。因此,这个问题会在未来工作中进行进一步研究。
此外,本文的评估方法当前主要针对Java 语言。理论上本文的方法适用于所有编程语言。但是,由于本文只对Java 语言项目进行了研究,而没有考虑其他语言项目的特点,因此编程语言可能也是一个对本文方法有效性产生威胁的一个比较重要的因素。将来,会结合不同编程语言各自的特点,将本文的方法扩展到其他的语言环境。
6 总结
高质量方法块是进行智能化编程及相关研究工作的基础。随着基于开源源码的智能化软件开发日益盛行,研究人员也逐渐认识到源码数据质量的重要性,并尝试进行了一些简单的数据处理。然而,当前对于源码数据质量问题的关注度还比较缺乏。因此,本文面向相关研究中经常使用的开源项目托管平台上的代码数据,根据开源源码中可能存在的数据质量问题,从不同的维度,提出一种针对开源大数据的代码数据质量评估方法。本文旨在让从事相关研究的开发人员能够通过本文方法对研究中所使用的方法块质量进行系统的评估,从而提高智能化软件开发水平和质量。
未来工作将继续关注编程智能化方面的相关工作,包括将本文的数据质量评估方法应用到其他语言以及研究其他语言采用的代码检测工具及使用方法的工作。将深入进行评估方面的研究。目标是能够实现对智能化编程系统所使用数据集质量的自动化评估、所使用测试集的自动构建、所使用算法的自动分析和智能化编程系统评估使用的指标的自动选取及可解释性分析等。同时对常见的,如API 及方法块推荐等,建立完整的自动化、智能化和可解释性较好的评估系统。
