生成对抗网络的研究进展综述*
2020-03-19吴少乾李西明
吴少乾,李西明
华南农业大学 数学与信息学院,广州510642
1 背景
近年来,伴随着Alpha Go 成为第一个击败人类职业围棋世界冠军的人工智能机器人开始,机器智能得到了迅速发展。而机器智能需要人们应用大量的数据去训练机器,使其更加智能。其中,生成算法通常被视为机器对训练数据“理解”程度的衡量标准,生成算法通过学习一组信息之后生成信息分布,通过深度学习领域中的基于反向传播和Dropout 算法的判别式模型,将高维丰富的感知器输入映射到类别标签上[1-2],以此来判别生成算法生成的分布的正确性,若生成的分布正确,那么机器也一定正确地理解了这些信息。因此,生成算法被看作是对系统理解的一种度量,常应用于生成文本[3-4]、图像[5-6]、语音[7-8]及生成系统行为和系统状态[9]等领域。
然而,由于在最大似然估计和相关策略方面通常存在许多难以解决的概率计算问题,且在生成上下文时无法充分利用分段线性单元的优势,导致深度生成模型没有得到广泛的应用。但是,在统计信号处理和机器学习中,以产生或再现与真实样本难以区分的样本为目标的研究依旧是一大热点。特别是,获取高维数据分布的生成模型是一项具有挑战性但又非常重要的工作,因为它们对于各种应用程序(如文本到演讲合成、语音转换、图像到图像的翻译和照片编辑等)都具有重要的意义。
2014年,Goodfellow 等人[10]提出了一种通过对抗训练来评估生成模型的新框架——生成对抗网络(generative adversarial networks,GANs)。它的出现为解决工程和数学领域中高维度概率密度分布中采样和训练的问题提供了很大的帮助,迅速成为人工智能学界一个热门的研究方向。GANs 的基本思想源自双人博弈论,由一个生成器和一个判别器构成,通过对抗学习的方式进行训练,目的是估测数据样本的潜在分布并生成新的数据样本,这使得GANs 在各个领域得到迅速的发展,被广泛应用于各个算法、模型和神经网络中,从朴素贝叶斯到深度信念网络,再到高斯混合模型、隐马尔可夫模型、潜在狄利克雷分配和受限玻尔兹曼机等。
近年来,对于GANs 的基础研究和实际应用研究,都取得了相当不错的成果。本文将对GANs 近几年来的研究成果进行总结,介绍GANs 的基础理论及其实际应用成果。
2 GANs的基本原理
2.1 GANs原理
GANs 是一种深度生成模型,它包含两个相互竞争的神经网络模型:生成模型G和判别模型D。其中G的目的是学习真实样本的分布,生成相似度逼近真实样本的生成样本,而D的目的则是判断训练样本来自真实样本还是生成样本。简单来说,两个模型通过不断的对抗训练,G最大化生成以假乱真的生成样本,D最小化自己判别错误的概率。
模型G和D通过不断的对抗训练,使D正确判别训练样本来源的概率最大化,同时使G生成的生成数据与真实数据的相似度最大化。在训练优化D时,当D的输入为真实样本x时,希望D(x)趋于1;当输入为生成样本G(z)时,则希望D(G(z))趋于0,即希望1-D(G(z))趋于1,故极大化模型D。在训练优化G时,输入只有噪声z,此时希望生成样本G(z)通过D后的概率值为1,即希望D(G(z))趋于1,也就是说希望1-D(G(z))趋于0,故极小化模型G。因此,D和G的训练可以表示为关于值函数V(G,D)的极小化极大的双方博弈问题:
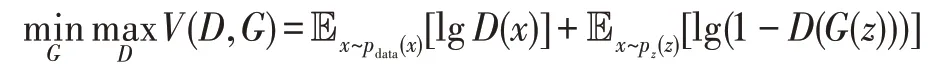
训练过程中,两个模型交替迭代,先固定G,训练D,更新D的参数,然后固定D,更新迭代G的参数,最终达到模型稳定。Goodfellow 等人在文献[10]中证明了当且仅当pz=pdata时,极大化极小的双方博弈问题存在全局最优解,即达到纳什均衡,此时生成模型G学会了真实样本pdata的分布,使得判别模型D的准确率稳定停留于1/2 上,即使得D只能对训练样本在0 或1 之间进行随机猜测。
2.2 GANs优缺点
相比较于以前的建模框架,GANs 框架具有以下的一些优势。相比较于蒙特卡洛估计、玻尔兹曼机和生成随机网络等生成网络,GANs 的计算过程不需要使用马尔可夫链,学习过程也不需要近似推理,这使得它能够更好地利用分段线性单元的优势,仅通过反向传播来计算梯度,从而回避了近似计算困难的概率难题。与完全明显的信念网络相比,GANs 因为不需要在采样序列生成不同的数据,使其能够更快地产生样本。相比于变分自编码器,GANs 没有变分下界,不需要引入任何决定性偏置,是渐进一致的,而变分方法引入的决定性偏置是有偏差的,由于变分自编码器优化的是对数似然的下界,而不是似然度本身,从而导致变分自编码器的生成效果比GANs 差。相比较于非线性独立分量分析,GANs 不需要对潜在变量(生成器的输入值)的大小进行限制,即不要求生成器输入的潜在变量有任何特定的维度或要求生成器是可逆的。
GANs 虽然解决了生成式模型中的一些问题,对其他生成算法的发展具有一定的启发意义,但GANs也并非完美,在解决了已有问题的同时也产生了一些新的问题。由于GANs 采用对抗学习的方法,导致模型收敛性的不稳定,虽然GANs 在纳什均衡时达到最优,但是只有当梯度下降在凸函数的情况下才能保证实现纳什均衡。而训练过程需要保证两个对抗网络的平衡和同步,否则难以得到很好的训练效果,但在实际过程中,两个对抗网络的同步不易把控,因此训练过程可能不稳定,这就导致了模型训练很难收敛的问题。此外,GANs 框架使用极大化极小的概念,这使得在训练过程中难以对模型训练情况进行评价。GANs 在训练过程中,生成模型可能出现退化现象,总是生成同样的样本点,无法继续学习,导致生成模型崩溃,而当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,使得训练无法继续,从而导致了GANs 的模型崩溃问题。相比其他生成式模型,GANs 无需预先建模,直接对真实样本进行采样训练,从而真正达到理论上可以完全逼近真实样本,这是GANs 的最大优势,但同时这也会使得模型过于自由。而对于尺寸大、像素高的图片,简单的GANs 又会导致模型不太可控,这就导致了GANs模型过于自由不可控的问题。
3 GANs的衍生模型
自2014年Goodfellow 等人提出生成对抗网络以来,GANs 已经成为最流行的深度生成模型之一,其研究也取得了快速的进展,衍生出了上百种相关的模型,在短短的几年里已在图像处理、自然语言、计算机视觉等领域中得到了广泛的应用,最终形成了所谓的GANs-zoo。本章将从GANs 模型中的损失函数、网络体系结构及其模型应用改进等方面的研究进展进行整理分析,并介绍其中具有代表性的模型,并将一些比较常见的GANs 衍生模型进行分类,如表1 所示。
3.1 基于损失函数改进的GANs
Nowozin 等人[14]对Nguyen 等人[15]提出的变散度估计框架进行扩展,提出f-GANs 模型,将散度估计扩展到模型估计,并称这种新方法为变分发散最小化(variable dispersion minimization,VDM),并证明了生成对抗训练是VDM 框架的一个特例。他们使用生成模型Q和变分函数T作为生成对抗网络的两个模型。通过实验表明,GANs 架构中的JS 散度可以被任意的f-散度(不同散度的总称)代替,证明了GANs 的广泛应用性。虽然使用交叉熵的定义可以保证模型收敛的速度,但是在决策边界为真的一边的样本均会被分类为真,即使是假样本,这样就会导致即使使用与真实样本相差甚远的假样本更新生成器时,判别器仍会判断为真,这就让假样本成功欺骗了判别器。从而导致了更新生成器的时候出现梯度弥散的问题,进而使得传统GANs 生成的图片质量不高以及训练过程不稳定的系列问题。针对以上问题,Mao 等人在文献[16]中提出了一种最小二乘生成对抗网络(least squares generative adversarial networks,LSGANs),该网络将传统GANs 的目标函数中的交叉熵损失函数替换成最小二乘损失函数,并将最小二乘损失函数作为判别器,根据样本到决策边界的距离进行惩罚,从而将假样本移向决策边界,这样就会生成更多的梯度来更新生成器,同时保证了模型的收敛性和稳定性,以此解决了GANs 中梯度消失的问题,但LSGANs无法解决这个核心问题——如何更好地测量生成数据和真实数据之间的散度距离。

Table1 Classification of GANs derived models表1 GANs的衍生模型分类
针对散度距离测量的问题,Arjovsky 等人[17]提出的WGAN(Wasserstein GAN)抛弃了传统GANs 的JS 散度(Jensen-Shannon 散度)定义,采用Earth Mover距离(EM 距离)来计算两个分布的距离,利用EM 距离来监控模型的好坏,解决GAN 训练不稳定、模型崩塌和生成模型的评价问题。WGAN 在处理Lipschitz限制条件时采用了权重裁剪方法,将参数的梯度值限制在一定的范围内,以便通过倒数限制D(x)的增长速度,但是该方法中的权重裁剪值却不好确定,这使得有时仍然只能生成较差的样本或无法收敛。针对WGAN 存在的缺点,Gulrajani等人在文献[18]中提出了WGAN 的改进版WGAN-GP,WGAN-GP 提出了一种新的Lipschitz 连续性限制手法,即通过给判别函数添加梯度惩罚项,将参数与限制联系起来,达到Lipschitz 限制条件,以此解决WGAN 的权重裁剪导致参数集中化、梯度爆炸和梯度消失的问题,但是对于梯度的模大于1 的区域的值,WGAN-GP 虽然也做出了惩罚,但是却无法保证每一个值的梯度的模都小于等于1,并且该方法计算成本很高。
以上所述均存在一个较强的假设,即鉴别器在每一步中(在函数空间中)都处于最优状态,相比较WGAN 和WANG-GP,Petzka 等人[19]提出一种较弱的正则化项来执行Lipschitz 限制。而Kodali 等人[20]提出的DRAGAN(deep regret analytic GAN)则将交替梯度更新过程看作regretminimization 进行训练,以达到纳什均衡,并且证明了在无参数限制和无需要求判别器在每一步中都处于最优状态的条件下,模型训练能够渐近收敛,在此基础上提出了一种新的梯度惩罚算法,支持更快的训练,实现更好的稳定性和建模性能,但本质上只是采用了不同的梯度惩罚函数。同样,Berthelot 等人在文献[21]中提出了一种新的平衡强化方法——BEGAN(boundary equilibrium GAN),该方法结合EM 距离的损失来训练基于自动编码器的GANs。BEGAN 抛弃了通过估计真实分布和生成分布之间的差距,反而通过估计分布的分布误差之间的相似度,以达到判别目的,但是BEGAN主要应用于图像领域中,对于高分辨率的图像的效果一般。为此,在BEGAN 的基础上,Li 等人[22]在判别器中新增去噪损失函数,以获取更多与真实分布相关的信息,以此提高训练效果和收敛稳定性,但其效果并未超过WGAN-GP。
在文献[23]中,Mroueh 等人利用奇异值分解概念,将分布嵌入到有限维特征空间中,并根据其均值和协方差特征统计进行匹配,同时匹配均值特征和二阶矩阵特征,使得真实数据分布和生成数据分布之间的嵌入协方差差异最大化,以此提升训练效果。在文献[24]中,Mroueh 等人建立了一种积分概率矩阵框架——FisherGAN来训练GANs。它在WGANGP的基础上继续改进,当WGAN-GP 对判别器函数的梯度做出惩罚时,Fisher GAN 会对判别器的二阶矩阵进行约束,使得模型可以稳定训练,但是FisherGAN对于积分概率度量(integral probability metrics,IPM)的约束较强,缺乏一定的灵活性。在神经网络中,将梯度的模限制在一个范围内,抽象地说就是让产生的函数更平滑一些,最常见的做法便是正则化,而频谱归一化则可以使正则化产生更明确的限制,因此Miyato 等人在文献[25]中提出了频谱归一化GANs,利用频谱范数[26]标准化神经网络的参数矩阵W,从而让神经网络的梯度被限制在一个范围内,以便让正则化产生更明确的限制,但这同时也牺牲了模型的收敛速度。
3.2 基于模型应用改进的GANs
上一节主要介绍了从损失函数方面进行改进的各种GANs 模型,通过各种改进,不但稳定了模型的收敛性,同时也解决了模型崩溃的问题。而在这一节中,将介绍从模型的内部网络体系结构和结合模型应用等方面进行改进的各种GANs衍生模型。
在无监督学习中,从大量无标记数据集中学习到可重复使用的特征是十分有意义的,特别是在计算机视觉领域中,如果能从大批量无标记图像和视频中学习到良好的中间特征,就可以将它用于诸如图像分类这样的监督学习任务。要建立图像的良好特征,可以通过训练无监督学习的GANs 模型,并把判别模型和生成模型作为特征提取器,然后再应用到有监督学习上。因此,在基于GANs 的思想上,2015年Radford 等人[27]提出了一种将有监督学习中的深度卷积神经网络CNNs 和无监督学习的GANs 结合在一起的架构——深度卷积对抗生成网络(deep convolutional GANs,DCGANs)。通过在不同训练集上训练表明,不论是判别模型还是生成模型,也不论是单个对象还是图像全局场景,DCGANs 都能学习到一系列特征,同时GANs 训练的稳定性以及生成结果质量都有了极大的提升,DCGANs 也因此建立起了CNNs在有监督学习和无监督学习之间的桥梁。
训练传统GANs 需要找到具有连续高维参数的非凸博弈的纳什均衡,而传统GANs 通常使用梯度下降法进行训练,这种算法虽然可以找到损失函数的最小值,但是无法找到博弈的纳什均衡。并且当该算法用于寻找纳什均衡时,该算法可能无法收敛,即使做了结构细化的DCGANs,其训练过程仍难以收敛。因此,Salimans 和Goodfellow 在文献[28]中提出Improved-DCGANs,针对DCGANs 的训练过程,利用特征匹配、小批量判别、历史平均、单侧标签平滑和虚拟批次正态化五种不同的增强方法,使训练朝着收敛方向进行。
针对GANs 无需预先建模,导致模型过于自由不可控的问题,Mirza和Osindero[29]提出了一种给GANs加上约束条件的模型,称为CGANs(conditional GANs)。CGANs 就是一种带条件约束的GANs,在G和D的模型中均引入条件变量y,通过将y作为G和D输入层的一部分来进行调节,以此提高对模型的控制。这个改进虽然简单,但是被证明非常有效,并广泛用于后续的相关工作中[30-32]。已有的文本图像生成方法可以生成比较粗糙的模型,但是却无法生成必要的细节和生动的物体,虽然CGANs 的出现提高了生成图像的质量,但是CGANs 仍无法产生高质量的图片。因此,Zhang 等人[6]在CGANs 的基础上提出了StackGAN 来生成高质量的图片。StackGAN 通过堆叠的方法来实现目的,即将合成过程分解为两个较易处理的阶段。第一阶段的GANs 利用文本描述粗略勾画物体主要的形状和颜色,生成低分辨率的图片;第二阶段的GANs 修正了第一阶段的结果,生成细节丰富的高分辨率图片,但是StackGAN 无法处理复杂文本。为了进一步提高生成样本的质量,稳定GANs的训练,Zhang 等人[33]提出了对StackGAN 进一步改进后的StackGAN++,相比于StackGAN,StackGAN++由多个生成器和多个鉴别器组成,它们以树状结构排列,让同一场景对应的多个尺度的图像由树的不同分支生成,以此提升模型对复杂文本的处理能力。但是StackGAN++仍无法很好地处理很复杂的文本,因此Johnson 等人[34]提出了一种从场景图生成图像的端到端的方法,以处理更长更复杂的文本,与从文本描述生成图像的方法相比,该方法能够从结构化场景图中明显地推理出对象和关系,并生成具有多个可识别对象的复杂图像。
Donahue 等人[11]在GANs 的基础上,结合编码器的定义提出一种双向生成对抗网络,不但能将潜在样本映射到生成的数据,而且能够将数据逆映射到潜在表示上。在CGANs的基础上,Perarnau 等人[12]则将编码器和CGANs 相结合,提出了用于图像编辑的可逆的CGANs,将真实图像映射到高特征空间和条件表示中,这就允许根据任意的属性重构和修改真实图像,即能够重新生成具有确定性的复杂修改的真实图像。在文献[2]中,Karacan 等人利用反卷积神经网络和卷积神经网络构造了新的条件GANs——属性-布局条件生成对抗性网络(attribute-layout conditioned GAN,AL-CGAN)。AL-CGAN 模型被拆解成两部分研究,即单属性条件的A-CGAN 模型和单空间布局条件的L-CGAN 模型。同时还会对缺失的空间布局进行补充,对每个场景进行粗语义标注,对缺失的属性进行属性预测。
上述表明了深度卷积网络能够提升GANs 生成高分辨率图片的细节,但是由于卷积网络的局部感受的限制,如果要生成大范围相关的区域,卷积网络就会出现问题。Qian 等人[35]提出将AttentiveNet 引入传统的GANs 中,以此生成注意力图(attentive map),并将注意力图应用于生成网络和判别网络中,使网络能够快速准确地定位到图像中的重点关注区域。但由于GANs 很难捕捉几何结构特征,使得GANs 在某些图像类别上很难建模,因此依靠卷积来建立不同图像区域之间的依赖关系的模型,其依赖关系的传递只能通过大范围的多个卷积层来实现。随着卷积大小的增加,网络的真实容量也在增加,却损失了计算效率。而self-attention 却能够做到依赖性和计算效率的平衡。因此,Zhang等人[36]提出将self-attention机制加入GANs 中,让生成器和判别器可以自动学习图像中的重要目标,形成了模型SAGAN(self-attention GAN)。SAGAN 克服了传统GANs 模型均在低分辨率特征图的空间局部点上来生成高分辨率的细节的缺陷——SAGAN 可以从所有的特征处生成细节,并且SAGAN 的判别器可以判别两幅具有明显差异的图像是否具有一致的高度精细特征,但仍有很大的提升空间。此外,Brock 等人[37]提出的BigGAN 以SAGAN 架构为基础,将正交正则化应用于生成器,使其适用于简单的“截断技巧”,并使用铰链损失作为GANs 目标函数,同时使用类条件BatchNorm 和含投影的D向G提供类信息,该方法极大地提高了生成图像的逼真性和精细度。
上诉介绍的各种改进只是众多改进中的一小部分,除此之外,研究者们利用各种相关的方法继续改进传统GANs,以改善传统GANs 的各种不足,例如:Ghosh 等人[38]利用多主体的GANs 来改进传统GANs模型崩塌的问题;Zhao等人[39]引入能量定义,提出了基于能量的生成对抗网络(energy-based GAN,EBGAN),该模型将判别器看作一个能量函数,将低能量赋给数据流行附近地区域,将高能量赋给其他区域,结果表明EBGAN 比传统的GANs 更加稳定,生成的图像分辨率更高;Qi[40]提出的损失敏感型生成对抗网络,进一步利用真实数据密度的Lipschitz 正则条件对其损失函数进行正则化处理,得到一个正则化模型,该模型提升了GANs 生成新数据的泛化能力;Li 等人[13]将最大均值差异作为损失函数,并结合自动编码器,结果表明它能够比传统GANs 更有效地生成更好的生成模型;Tolstikhin 等人[41]使用自提高的训练机制,通过融合各生成模型,达到更好的拟合数据分布的目的,从而克服了GANs训练难以及模型崩溃问题。
4 GANs的应用
GANs 作为一种生成模型,它并不局限于特定的数据类型,可以应用于各种数据,如图像、音频、文本等。它也不局限于特定的任务,可以应用于各种任务,如图像的处理、视频生成、恶意检查、通信保护和密码破译等。
4.1 GANs在图像领域中的应用
针对GANs 模型过于自由问题,除了给其加上约束条件外,也可以通过让GANs 分次完成任务,一次生成一部分,分多次生成完整的目标,来避免这个问题。因此,Denton等人[42]采用这个思想,在基于CGANs的基础上,提出了改进模型LAPGANs(Laplacian pyramid of GANs)。LAPGANs是一种生成式参数模型,通过带有Laplacian 金字塔框架的级联卷积网络,以逐步求精的迭代方式生成高质量的自然图像样本,LAPGANs 训练出来图像比GANs 训练出来的图像更加自然,边缘也更加明确,但由于LAPGANs 的网络深度较深,使得逐步求精的方法增加了网络简单记忆输入样本的难度。Li 等人[43]将对抗性生成式网络应用于Markovian 环境中,学习相同内容的不同描述之间的映射,通过生成网络G将输入的图像直接解码为合成图像的像素,然后利用判别器D去学习区分实际的特征块和不合适的合成特征块,通过对抗性训练反卷积神经网络来合成纹理,但是该方法在处理非纹理的数据上的表现不足。
GANs 模型不仅适用于二维空间,而且适用于三维空间。但不同于GANs 在二维空间的应用,在三维空间中,GANs 的生成器需要建立从二维空间到三维空间的映射关系,并依据该映射关系将2D 图像生成3D 形状的对象,这个映射关系既是重点也是难点,直接影响3D 对象的生成质量。Wu 等人[44]在DCGANs的基础上进行改进,提出了3D 生成对抗网络(3DGAN),它利用生成对抗网络和体卷积网络[45],建立从概率空间到3D 对象空间的映射,再利用判别器为三维对象的描述提供有用的特征信息,但是合成的3D 图像的锐度和边缘信息还有待提高。Gadelha 等人[46]提出的投影生成对抗网络(PrGANs),利用其训练一个可以准确表示3D 形状的深度生成模型,将2D图像生成3D 对象,并在传递给判别器之前将其转换为2D 图像,通过迭代训练周期,生成器通过改进生成的3D 体素形状来完善2D 图像到3D 对象的投影结果。将GANs 应用于三维空间上的探索还有很多,例如:Cao 等人[47]利用一种3D 辅助二重生成对抗网络(aided duet GAN,AD-GAN)来精确地将人脸图像旋转到任意指定的角度;Wang 等人[48]结合3D 解码器GANs 和长期循环卷积网络,以低分辨率填充缺失的三维数据,使三维模型具有语义合理性和上下文细节。
随着神经网络在无监督学习和半监督学习领域上的发展,可以通过对输入样本的重构来对数据分布进行显式建模,但是基于重构的学习方法往往会学习并保存全部输入样本的特征。在GANs 的基础上,Yi等人[49]提出了无监督和半监督学习下的分类生成式对抗网络框架,即将神经网络分类器与对抗生成模型相结合,对抗生成模型对训练有素的分类器进行正则化,以此使得与分类器一起学习的生成器能够生成高视觉保真度的图像。但由于传统GANs的输入是一组没有任何限制且完全随机的噪声信号z,这使得无法将z的具体维度和数据的语义特征对应起来,导致输入向量对输出产生不明确性的影响。因此,Chen 等人在文献[50]中提出了无监督学习的InfoGANs,他们将原本的输入向量z拆成子向量c(可解释的隐变量,表示对输出产生影响的因素)和子向量z′(不可压缩的噪声)。InfoGANs 通过约束隐变量c与生成数据之间的关系,使c能够直接代表数据某个方面的语义信息,进而使得c与生成数据具有较高的互信息,以此解决隐变量可解释性的问题。
为了提高图像的分辨率,Ledig 等人[51]提出了一种超分辨率生成对抗网络(super-resolution GAN,SRGAN),实现了低分辨图像合成4 倍放大的高分辨率图像,但生成的图像的纹理信息并不够真实,且常常伴有噪声。因此,Wang 等人[52]提出了一种增强分辨率的生成对抗网络(enhanced super-resolution GAN,ESRGAN),对网络的结构、对抗性损失和感知性损失进行改进。并在此基础上,引入残差-剩余密集块作为基本的网络构建单元,得益于这些改进,为亮度一致性和纹理恢复提供更强的监控,产生的纹理比SRGAN 更真实和自然,进一步提高了视觉的质量。GANs 应用于图像超分辨率的例子还有很多,例如:Huang等人[53]提出的双通道生成对抗网络通过感知全局结构和局部细节,实现了从一张单侧照片合成高分辨率的正面人脸图像;Kupyn 等人[54]提出了一种基于CGANs和内容损失的端到端学习法DeblurGAN,能够去除由于运动而产生的模糊;Kupyn等人对DeblurGAN进行改进得到DeblurGAN-v2[55],大大提高了去模糊效率、质量和灵活性。
图像到图像的转换是图像领域中一大热门研究方向,GANs 在该方向的研究也取得了一定的进展。Isola 等人[31]在CGANs 的基础上进行图像到图像的转换的研究,利用成对的数据集进行实验,表明了CGANs 是一种很有前途的图像到图像的转换方法,特别是那些涉及高度结构化图形输出的图像。图像到图像的转换通常使用一组成对的图像对来学习输入图像和输出图像之间的映射,但是对于许多任务,成对的训练数据很难获取,因此Zhu 等人[56]提出了一种在没有成对数据的情况下,设计双生成器与双鉴别器,形成双向风格迁移的CycleGAN 模型,学习将图像从域X转换为目标域Y的方法,解决了pix2pix 必须使用成对数据的问题。Chen 等人[57]提出一种利用非成对数据来实现图像增强的方法,其基于一个结构类似于CycleGAN 的双向GANs,并进行改进,以此来实现图像到增强图像的转换。
除了上述应用外,GANs 在各个领域的应用也十分广泛,Wang 等人[58]对图像生成过程进行了分解,提出了一种基于风格和结构的生成反求网络;Creswell等人[59]将GANs 应用于检索;Zhu 等人[60]提出利用生成式对偶神经网络直接从数据中学习自然图像流形;包仁达等人[61]提出了一种掩模控制的自动上妆GANs,能够重点编辑上妆区域,约束人脸妆容编辑中无需编辑的区域不变,保持主体信息;Reed 等人[9]综合了图像和描述在哪个位置绘制什么内容的指令;Vondrick 等人[62]利用大量未标记的视频来学习视频识别任务(例如动作分类)和视频生成任务(例如未来预测)的场景动力学模型;Taigman 等人[63]研究了将一个域上的样本转移到另一个域上的模拟样本的问题,可以应用于包括数字和人脸图像在内的视觉领域;Denton 等人[64]介绍了一种简单的基于对抗性损失的画中学习的半监督学习方法;Mogren[65]提出了一种基于连续序列数据的生成式对抗模型,并将其应用于古典音乐的集合;武随烁等人[66]针对GANs 无法有效提取图像局部与全局特征间依赖关系,以及各类别间的依赖关系,提出一种用于GANs 的孪生注意力模型;桑亮等人[67]基于GANs 的深度卷积网络,采用端对端的方式,复原了由于抖动或运动所导致的模糊图像的细节信息;时澄等人[68]利用GANs 对残缺图像进行补全。除此之外,GANs 的应用数不胜数,但仍需要继续研究。
4.2 GANs在信息安全领域中的应用
在数据隐私保护中,如何保证数据集的可利用性和隐私性的平衡是极为重要的。随着GANs 应用领域的不断扩大,其在隐私保护中也有所应用。GANs 利用自身的优势,将噪声添加到潜在空间而不是直接添加到数据中,减少了整体的信息损失,同时保证了隐私。Triastcyn 等人[69]提出了一种生成人工数据集的方法,在生成对抗网络的判别器中加入高斯噪声层,使输出和梯度相对于训练数据具有不同的私密性,然后利用生成器组件合成具有保密性的人工数据集,不但保留了真实数据的统计特性,同时为这些数据提供了差分隐私保护。Beaulieu-Jones 等人[70]结合GANs 和差分隐私提出了差分隐私辅助分类生成对抗网络,用于生成医疗临床数据。针对当GANs 应用于私人或敏感数据(如病人的医学病历),并且分布的集中可能泄露关键的病人信息的问题,Xie等人[71]提出了一种差分私有GANs 模型——DPGAN(differentially private GAN)模型,通过在学习过程中向梯度中添加精心设计的噪声来实现GANs 的差分隐私。同样,Huang 等人[72]结合GANs 提出一种上下文感知隐私模型,通过巧妙添加噪声来实现私有数据的发布。Frigerio 等人[73]通过差异隐私定义提出了一个保护隐私的数据发布框架,从时间序列到连续数据和离散数据的生成,均可以很容易地适应不同的用例,以保证在发布新的开放数据的同时保护用户的个性。Papernot 等人[74]提出了一种教师-学生模式的深度网络隐私保护方法,利用教师深度模型和学生GANs 模型,通过训练从而达到保护训练数据集的目的,但是这种将模型训练过程视为黑盒,仅从模型外部添加隐私保护机制,其保护效果的可控性是不够的。
GANs 除了应用于隐私保护外,还被应用于恶意检测中。为了有效地检测包括零日攻击在内的恶意软件,Kim 等人[75]提出了一种转移深度卷积生成对抗网络(transferred deep-convolutional GAN,tDCGAN),基于深度自编码技术,利用实际数据和tDCGAN 生成的修改数据学习各种恶意软件的特征,提取有意义的特征进行恶意软件检测。GANs 同样适用于信用卡欺骗检测,Fiore 等人[76]训练一个GANs 模型来输出模拟的少数类的欺骗例子,然后将这些例子与训练数据合并成一个增强训练集,从而提高分类器对少数类欺骗例子的分类效率。为了有效识别受害者向诈骗者发送大额转账,Zheng 等人[77]提出了一种基于GANs 的模型来计算银行每笔大额转账的欺诈概率,让银行采取适当的措施,以此防止潜在的骗子在概率超过阈值时取钱。除了这些恶意检测,GANs 还可以用于检测僵尸网络,Yin 等人[78]提出了一种基于GANs 的僵尸网络检测模型框架——Bot-GAN,生成模型不断生成伪样本,以辅助原检测模型提高性能。
GANs 的广泛适用性,使其在信息安全领域中最为古老的密码学中同样也适用。2016年,Abadi等人[79]利用GANs 的对抗学习机制,将传统的对称加密体系中的通信双方及敌手用神经网络进行代替,以此实现加解密的过程,达到保护通信过程的目的。在文献[80]中李西明等人改进Abadi 等人的模型,进行了抗泄漏加密通信测试,发现了利用生成对抗网络实现抗泄漏加密通信的可能性。Coutinho 等人[81]利用选择明文攻击的概念改进了Abadi 等人的模型,证明了神经网络在适当的环境下可以学习一次性密码本。除了保护通信之外,GANs 同样也适用于密码破译。Gomez 等人[82]基于GANs 提出CipherGAN,用于破译古典密码学中移位密码和维吉尼亚密码,Hitaj等人[83]提出了一种利用GANs 来增强密码破译的新方法——PassGAN,通过在泄露密码列表中训练GANs 来实现密码破译,为GANs 在密码学上的应用前景提供了更广阔的道路。
5 讨论
自2014年GANs 的诞生以来,它作为一种新型的生成模型得到了广泛的应用。作为一个生成模型,GAN 模型避免了一些传统生成模型在实际应用中的一些困难,巧妙地通过对抗学习来近似一些不可解的损失函数,这是其最大的创新之处,也是其产生问题的根源。针对其产生的各种问题,研究者们近几年不断地进行研究分析,将GANs 与各种相关的方法进行改进融合,得到了许多有效的成果。但目前的GANs 仍存在不足及缺陷,有赖于研究者们进一步解决。在应用上,GANs 被广泛应用于图像、文本生成、自然语言和信息安全等领域中,其中应用最为热门的领域当属图像领域。
虽然GANs 已经在许多方面得到应用,但其仍存在广大的应用前景,特别是在信息安全领域。在未来的工作中,可以从以下几点深入研究GANs 在信息安全领域中的应用。
(1)利用GANs 的特性,结合图像水印技术,将信息附着在图像上进行传输,达到消息的安全传递的效果。
(2)利用GANs 的对抗学习机制,分析病毒样本,预测新型病毒,形成自动防御体系。
(3)将GANs 与经典密码学相结合,分析破译率,并利用GANs 的对抗学习机制,保证公钥密码体制下的安全通信,实现消息的可认证性和保密性。
