基于功率检测和选择性集成的无线MAC协议识别技术
2020-03-13杨俊安黄科举
杨俊安 ,黄科举
(1.国防科技大学电子对抗学院,合肥,230037;2.安徽省电子制约技术重点实验室,合肥,230037)
引 言
在认知无线电和认知电子战领域,识别目标网络的介质访问控制(Medium access control,MAC)协议具有重要意义。对于认知无线电,利用主用户的MAC协议信息,可以预测频谱空穴随时间的变化情况,在充分利用频谱资源的同时降低对主用户的干扰[1]。例如,当主用户的MAC协议分别为载波侦听多路访问 (Carrier sense multiple access,CSMA)和时分复用 (Time division multiple access,TDMA)时,为了最大化频谱资源利用率,认知无线电用户应采用不同的接入机制[2-3]。在认知电子战领域,干扰目标的MAC协议信息能够用于决定最佳干扰时机[4],针对不同的MAC协议采取特定的干扰方式,有助于提高干扰效能[5-7]。认知无线电和认知电子战的相关研究均假定已知目标的MAC协议和参数,事实上,由于次用户相对于主用户的透明特性、干扰方与被干扰方的非合作特性,系统无法直接获取目标的MAC协议信息,需要研究基于目标网络功率变化情况的MAC协议识别方法。
认知无线电技术赋予无线电台感知频谱环境以及推理学习的能力[8],机器学习是实现认知无线电的学习、决策过程的重要途径[9]。利用机器学习中的分类算法,根据目标的功率变化进行MAC协议分类具有一定的可行性。
Hu等人[10]通过提取目标无线网的信号功率、信道空闲时间和信道占用时间的统计特征,训练支持向量机(Support vector machine,SVM)分类器,实现对TDMA、CSMA/CA、ALOHA、S-ALOHA四种协议的分类。但该方法假定网络中不同节点的功率和数据包长度均相同,在实际应用中具有一定的局限性。Rajab等人[11]通过检测目标信道的能量变化,提取活动时间和非活动时间的分布特征,并分别采用K最近邻(K nearest neighbor,KNN)分类器和朴素贝叶斯(Naïve Bayes,NB)分类器,识别802.11b/g/n三种协议。上述研究均采用单一分类器,并假定训练样本的网络配置与待识别目标相同。但在实际中,由于网络配置环境的多样性,目标的网络配置一般与训练样本不同,如网络通信负载、节点数及节点发射功率等。单分类器方法容易过拟合,对不同于训练样本配置的目标识别效果较差。
针对MAC协议识别的特征提取问题,本文提出根据功率检测序列提取碰撞概率估计特征和Fisher统计量特征。针对待识别目标与样本配置不同时识别效果较差的问题,本文提出一种将选择性集成应用于MAC协议识别的方法,以提升分类系统的泛化能力。利用OPNET软件仿真得到的TDMA、CSMA/CA、ALOHA、S-ALOHA协议数据进行协议识别实验。结果表明,本文所提特征对不同MAC协议具有较好的区分度,并且当目标与训练样本的网络配置不同时,选择性集成方法优于单分类器和全部集成方法。
1 系统模型
为简化问题,本文以单频点的无线MAC协议作为研究对象。单频点无线网络的MAC协议可分为无竞争和有竞争两类,其中有竞争MAC协议包括基于随机访问和基于预约机制[12]。采用无竞争MAC协议的网络中各节点按照事先确定的规则访问频谱资源,该规则保证各节点通信时不会发生碰撞,如TDMA协议。基于预约机制的MAC协议中节点在利用控制帧预约频谱资源后才能发送数据,如CSMA/CA协议。基于随机访问的MAC协议没有碰撞避免机制,节点在需要发送数据时立刻发送,如ALOHA协议和S-ALOHA协议。因此本文对TDMA、CSMA/CA、ALOHA和S-ALOHA四种MAC协议进行识别。
在进行MAC协议识别时,首先通过侦察获取无线网络的通信频率,采集该频点上信号的功率变化信息;其次根据功率变化信息提取用于MAC协议分类的特征;最后基于样本训练基分类器,并采用强化学习方法对基分类器进行选择性集成,得到分类系统。在利用该分类系统进行MAC协议识别时,采用投票法根据基分类器的结果得到系统的分类结果。
1.1 数据采集
假设通过一个接收节点采集目标无线网络传输信道上的功率信息,无线信道环境为加性高斯白噪声环境,如图1所示,则接收机在时刻t接收到的信号功率为

式中:NT表示目标无线网络中的节点个数;pi(t)表示接收机接收到网络中第i个节点的信号功率;n(t)表示背景噪声。设接收节点的采样时间间隔为τ,则目标网络的功率变化由序列pm=p(t=mτ),m=1,2,…,M表示。
图2为采样得到的功率序列{pm}示意图,由于背景噪声,序列{pm}存在一定的波动,但仍能根据功率变化情况估计目标网络中节点的通信行为。当功率变化大于一定阈值e时表示网络中存在节点通信行为的变化,例如图中m=6,15,25,36时pm-pm-1>e,表示有新的节点开始发送数据。

图1 信号接收模型Fig.1 Signal receiving model
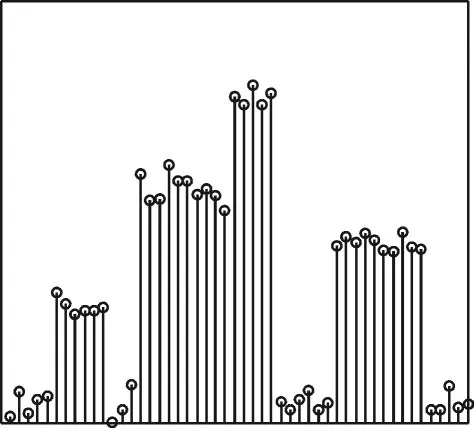
图2 功率序列Fig.2 Power sequence
1.2 特征提取
为了区分4种MAC协议,根据功率信息提取的特征,需要体现两方面特性:碰撞概率特性和发送时间周期性。如图3所示,TDMA和CSMA/CA协议分别采用时隙分配方式和RTS/CTS预约机制以保证传输过程中不发生碰撞,ALOHA和S-ALOHA协议采用随机接入的方式,传输过程中容易发生碰撞;TDMA和S-ALOHA协议采用分时机制,其数据包发送时间存在一定的周期性,CSMA/CA和ALOHA协议的数据包发送时间较为随机。根据碰撞概率和发送时间周期特性的不同,可以有效区分4种协议。
1.2.1 碰撞概率特征
当目标网络中不同节点同时发送信号时出现数据包碰撞,此时接收节点检测到的功率为多个节点所发送信号的功率之和。文献[10]假定所有节点的发送功率相同,当碰撞概率较大时,接收功率的变化范围也较大,因此采用接收功率的均值和方差作为碰撞概率特征。为了更符合实际情况,本文假定不同节点的发送功率不同,并在仿真时为不同节点设置不同的信号发送功率。图4为仿真得到的目标网络分别为不同的MAC协议时,对接收节点得到的功率序列{pm}归一化后的累积概率分布函数(Cumulative distribution function,CDF)。由于TDMA和CSMA/CA协议中不会发生数据包碰撞,其CDF呈阶梯状,在每个阶梯处的功率值对应目标网络中某些节点的信号功率;由于ALOHA协议和S-ALOHA协议中数据包碰撞概率较大,接收的功率可能为多个信号功率之和,其可能的取值更多,CDF曲线较为平滑,且相对集中分布在较小的功率值处。因此功率的统计特性能够一定程度反映目标网络中数据包碰撞的情况,本文采用序列{pm}的平均值Ep,方差Vp,偏度Sp,峰度Kp作为特征。
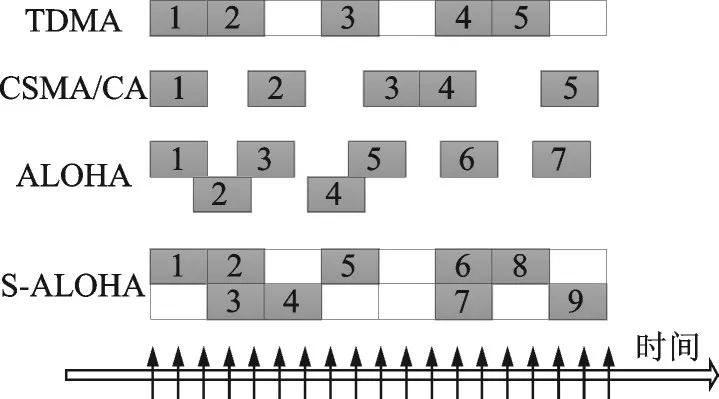
图3 不同MAC协议数据包传输情况示意Fig.3 Packet transmission in different MAC protocols

图4 归一化后功率的累积概率分布函数及概率密度函数Fig.4 Cumulative probability and probability density of normalized power values
除功率统计特性外,本文提出根据序列{pm}直接估计目标网络中发生碰撞的数据包比例RC。记RC=NC/N,其中N为{pm}中的数据包个数估计,NC为{pm}中发生碰撞的数据包个数估计。按照如下方式统计N和NC:pm-pm-1>e时记为一次数据包传输,如图2中m=6,15,25,36时满足条件,此时 N=4;pm-pm-1>e且pm-1>e时记为一次数据包碰撞,如图2中m=25时满足条件,此时NC=1,得到图2所示{pm}的RC=NC/N=0.25。
1.2.2 发送时间周期性特征
对于采用分时机制的MAC协议,虽然节点发起通信的行为是随机的,但节点进行通信的起始时刻是一个时隙的起始时刻,因此发送时间周期性可以作为区分MAC协议的特征之一。文献[10]假定所有数据包的长度相同,则采用分时机制协议的空闲时间和通信时间均为数据包传输时间的整数倍,统计空闲时间和通信时间的最小值、最大值和中位数作为特征。上述特征不适用于数据包长度变化的情况,且容易受到通信负载的影响。因此本文假定数据包长度随机变化,通过统计发送起始时刻的自相关函数最大值a和Fisher统计量g,用于估计通信节点发送行为的周期性。
首先利用序列{pm}得到目标网络的发送起始时刻标记序列{fm},即当m为发送起始时刻时令fm=1,否则令fm=0。图2所示的序列{pm}对应的序列{fm}如图5所示。序列{fm}的自相关函数能够体现其周期性,按照如下方式计算自相关函数的最大值a为
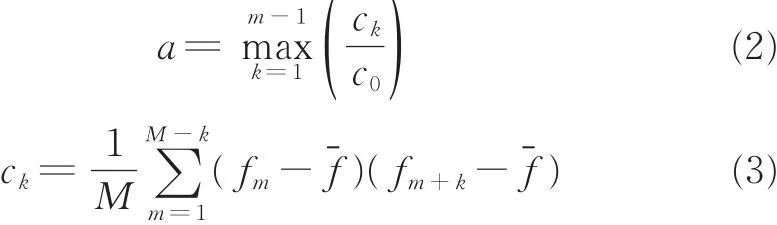
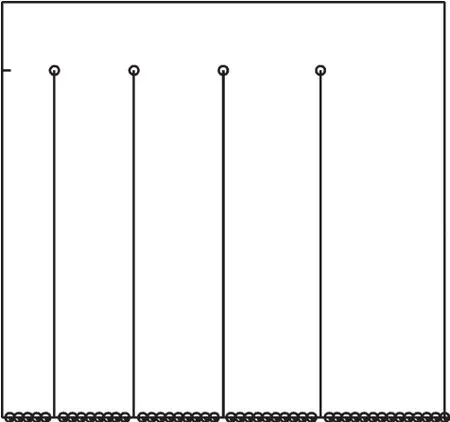
图5 发送起始时刻标记序列Fig.5 Identity sequence of transmitting start time
式中:F为序列{fm}的平均值;ck表示序列{fm}延时为k的自相关系数。
Fisher周期性检验中的统计量g[13]可以体现时间序列的周期性,g越大表明序列的周期性越强,其计算方式如下

式中{Fk}为序列{fm}的周期图。
从序列{pm}提取Ep,Vp,Sp,Kp,RC,a,g共 7维特征用于 MAC 协议分类,其中Ep,Vp,Sp,Kp以及RC体现协议的碰撞概率特性,a和g体现协议的发送行为周期性。
1.3 基于强化学习的选择性集成算法
泛化能力是指分类算法对新鲜样本的适应能力。泛化能力强的算法能够学习到隐含在数据背后的规律,对具有相同规律的训练集以外的数据,算法也能保持较好的分类效果[14]。因此,提升分类算法的泛化能力,有助于提升对不同于训练集配置网络的协议识别效果。
集成学习针对同一问题训练多个基分类器,并将基分类器集成为一个分类系统,该系统的分类准确率优于单个分类器,且具有较强的泛化能力。相比于将所有基分类器全部集成到系统中,从中选取较优的部分基分类器构建的集成系统可能提高分类效果,并且所需的预测时间更短[15]。选择部分基分类器进行集成的方法称为选择性集成(Selective ensemble,SE),或者称为集成剪枝[16]。
在构建集成系统时,首先利用训练集训练多个基分类器,其次利用验证集,按照特定算法选择最优的基分类器子集组成集成系统,如图6所示。基分类器的选择是选择性集成的关键。理论上可以通过枚举法,枚举所有可能的基分类器集合,并衡量每个基分类器集合的预测效果选择最优的集合,但这一方法的计算复杂度过高,实际中并不可行。采用贪婪方法直接选择分类效果最优的数个基分类器,得到的基分类器集合不一定为最优。
强化学习作为一种基于试错的行为学习方法[17],能够用于基分类器的选择。文献[18]采用强化学习方法,将基分类器的选择问题建模为马尔可夫决策过程,以分类准确率作为优化目标,在决策过程中对所有可能的基分类器集合的分类效果进行估计,并选择最优的集合,最终收敛到最优的基分类器集合。该方法比枚举法更加高效,并且能够一定程度上避免贪婪算法容易找到局部最优解的问题。
记基分类器集合为T={C1,C2,C3,…,CT},强化学习中的状态si由已选择的基分类器和当前考虑的基分类器组成,行为aj包括是否集成当前考虑的基分类器,如图7所示。在每次状态转移时决定是否包含特定基分类器到集成系统中,在每个状态si,以si的基分类器集合对验证集的分类效果作为该次决策的回报值。采用强化学习中的Q-学习[19]算法,将所选基分类器的分类效果作为回报值优化基分类器选择策略,最终收敛到最优的基分类器选择策略,其算法流程如图8所示,其中参数ε,α,γ分别表示随机选择行为的概率、学习速率和未来回报值的折扣比例,事先设置为固定值。
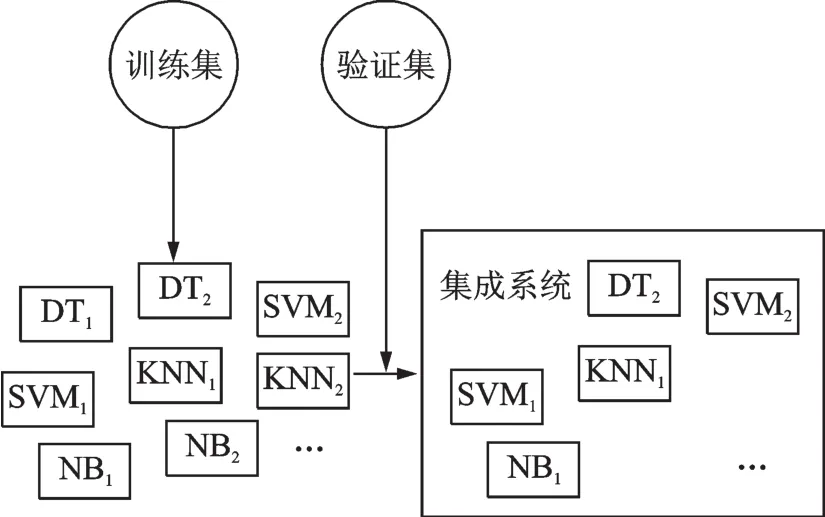
图6 选择性集成系统构建过程Fig.6 Construction of selective ensemble system

图7 选择性集成的马尔可夫决策过程Fig.7 Markov decision process of selective ensemble

图8 基于Q-学习的选择性集成算法流程Fig.8 Process of Q-learning based selective ensemble algorithm
2 实验结果和分析
2.1 数据集及算法参数
本文通过OPNET软件进行仿真,其无线网络环境配置如图9所示,目标无线网络包含9个节点,通过一个接收节点获取目标网络通信信道上的功率变化情况,设置接收节点的采样速率为104次/s,每次采样10 s,即105个采样点作为一个接收功率序列{pm},并根据该序列提取特征得到一个样本。本文实验分别仿真TDMA、CSMA、ALOHA、S-ALOHA四种MAC协议。为了体现无线网络配置场景的多样性,在仿真时随机设置通信节点的发射功率和数据包长度,并设置通信负载G为0.1,1或0.1~10之间的随机数,分别得到500,500,1 500个样本,总样本数为10 000个,样本数据分布情况如表1所示。
本文采用DT、SVM、KNN、NB四种基分类器,基分类器由基于Python语言的Scikit-Learn库实现,其中DT、KNN、NB分类器均采用默认设置,SVM分类器设置核函数为径向基函数,惩罚因子C=500,核参数gamma=20。用于选择性集成的Q-学习算法相关参数设置为ε=0.1、α=0.1、γ=0.9。
图9 OPNET软件仿真场景Fig.9 Simulation scenario in OPNET

表1 样本数据分布情况Table 1 Distribution of sample data
2.2 评价指标
分类系统对待分类样本进行分类后,对每种协议,统计如下3个统计量:TP(True positive)表示被分类系统识别为该协议且确实属于该协议的样本数;FP(False positive)表示被分类系统识别为该协议但实际不属于该协议的样本数;FN(False negative)表示被分类系统识别为不属于该协议但实际属于该协议的样本数。分类系统的准确率P和召回率R定义如下

F值是准确率和召回率的调和平均值,其定义如下

由于F值综合考虑分类系统的准确率和召回率,本文采用F值作为分类效果的评价指标。
2.3 实验结果
2.3.1 特征提取方法比较
采用选择性集成方法作为分类算法,比较不同特征对MAC协议识别效果的影响。在10 000个样本中,从4种MAC协议中各随机选取500个样本,其中1 000个样本作为训练样本集,另外1 000个样本作为验证样本集,其余8 000个样本作为测试样本集,分别采用文献[10]提取的特征和本文所提特征进行测试,得到对不同协议的分类F值。将上述实验重复10次后取平均得到的结果如表2所示。实验结果表明采用本文所提特征能够取得更好的分类效果,尤其对ALOHA协议和S-ALOHA协议的分类效果有明显提升。

表2 不同特征提取方法的分类效果Table 2 Classification result of different feature extraction methods
图10所示为相同样本分别采用文献[10]和本文特征时的分布情况,图10(a)采用文献[10]中的功率方差和通信时间中位数特征,图10(b)采用本文中的数据包碰撞比例RC和Fisher周期性检验统计量g。由于本文假定数据包发送时间长度为随机值,通信时间中位数无法准确反映网络中通信行为的周期性,因此图10(a)中的ALOHA协议和S-ALOHA协议样本点不易区分。而图10(b)中除RC接近0时ALOHA协议和S-ALOHA协议不易区分外,4种MAC协议在特征RC和g上具有一定的可区分性。

图10 相同样本提取的文献[10]特征和本文特征的分布情况Fig.10 Distribution of features of same samples in Ref.[10]and this paper
2.3.2 分类算法比较
在单分类器和全部集成方法的训练过程中,仅需要训练集样本用于分类器训练。在选择性集成方法的学习过程中,除需要训练集样本用于基分类器训练外,还需要验证集样本用于基分类器的选择。因此在将这些方法进行对比时,为保证其在训练时所用样本数相等,需要保证单分类器或全部集成方法的训练集样本数等于选择性集成的训练集与验证集样本数之和。
为验证训练样本对识别效果的影响,在实验1中随机选取训练样本,在实验2中从G=1.0的数据中选取训练样本,在实验3中从G=0.1的数据中选取训练样本。在实验1中,从4种MAC协议中各随机选取500个样本组成集合Y,作为单分类器和全部集成方法的训练集。从Y中随机选取1 000个样本作为选择性集成方法的训练集,剩余1 000个样本作为其验证集。将所有样本中除Y以外的样本作为测试集,得到不同方法对不同MAC协议的分类F值。将上述实验重复100次后取平均得到结果如表3所示。在实验2中,从4种MAC协议中各选取G=0.1的500个样本组成集合Y,其他步骤与实验1相同,得到结果如表4所示。在实验3中,从4种MAC协议中各选取G=1.0的500个样本组成集合Y,其他步骤与实验1相同,得到结果如表5所示。
在实验1中,单个DCT分类器的平均F值最大,对每种MAC协议的分类效果最优的方法均为单分类器。由于实验1中的训练样本包含了测试样本中所有的通信负载情况,因此单个分类器便能够取得较高的F值。在此实验条件下,选择性集成方法对泛化能力提升的效果不明显,同时其训练样本数少于单分类器和全部集成方法,因此选择性集成方法的识别效果不如单分类器和全部集成方法。在训练样本较为充分时,可能出现选择性集成方法不如最优的单分类器的情况[20]。
在实验2和实验3中,对大部分MAC协议,选择性集成方法的分类F值最大,且选择性集成方法的平均F值最大,识别效果提升明显。在实验2和实验3中用于训练的样本与测试样本的通信负载不同,单分类器由于泛化能力较差,对于和训练场景不同的样本识别效果较差,而全部集成方法和选择性集成方法通过提升分类系统的泛化能力,提高对未训练场景样本的识别效果,选择性集成方法的提升尤其明显。
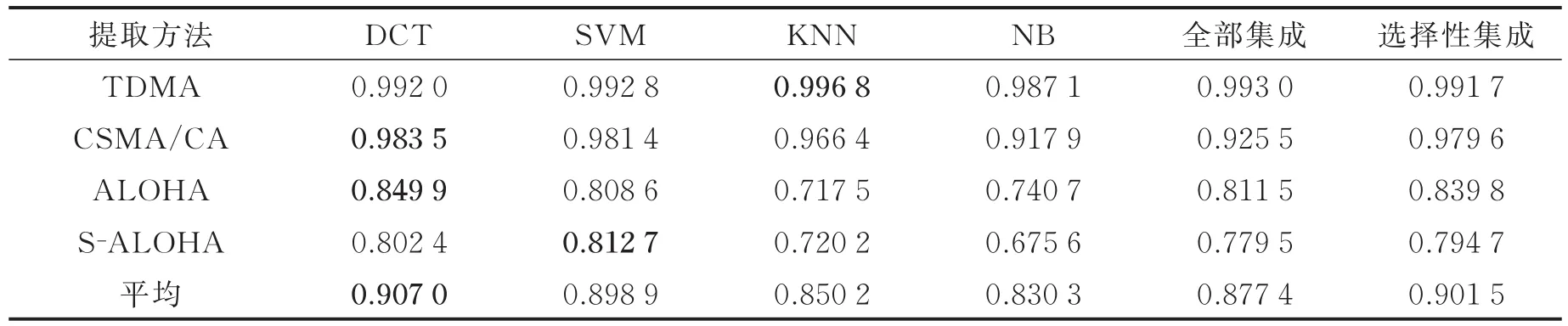
表3 实验1中不同分类方法的F值Table 3 F value of different classification methods in Experiment 1

表4 实验2中不同分类方法的F值Table 4 F value of different classification methods in Experiment 2
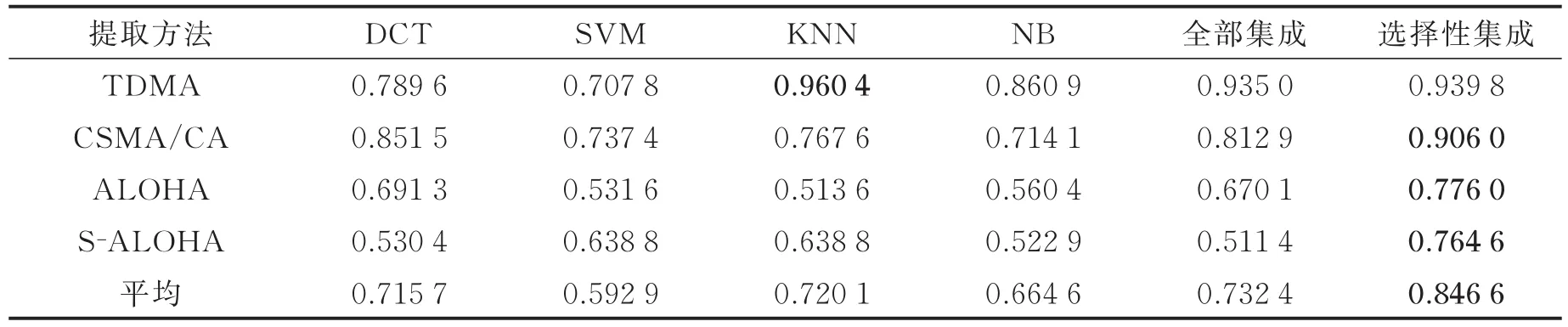
表5 实验3中不同分类方法的F值Table 5 F value of different classification methods in Experiment 3
在上述3个实验中,不同分类方法总体上对TDMA协议和CSMA/CA协议的分类F值更大,而对ALOHA协议和S-ALOHA协议的分类F值较小,这与2.2节中提取的特征造成ALOHA协议和SALOHA协议不容易区分有关。另外,实验3的识别效果总体上好于实验2,这是由于实验3中所用训练样本的通信负载G=1.0,而实验2中所用训练样本的通信负载G=0.1,通信负载较高时相同时间内的通信行为次数更多,MAC协议的特征更明显,因此训练得到的分类系统的识别效果更好。同时,在3个实验中,KNN分类器对TDMA协议的识别效果最好,但对ALOHA协议和S-ALOHA协议的识别效果较差,这与不同协议特征的分布情况和分类器的特性有关。
算法的识别时间对于实现实时分类具有重要影响。多次实验统计的结果表明,单分类器算法的单次识别时间为0.002 ms左右,全部集成方法的单次识别时间为0.05 ms左右,选择性集成方法的单次识别时间为0.01 ms左右。选择性集成方法的识别时间长于单分类器方法,但比全部集成方法更短,其识别时间满足实时性要求。
3 结束语
通过检测无线网络的功率变化识别其MAC协议对于认知无线电和认知电子战具有重要意义。由于不同无线网络配置不同,特征提取和分类算法的泛化能力对识别效果具有重要影响。本文根据典型MAC协议的特性,提出从碰撞比例特性和发送行为周期性两方面提取特征,所提特征适用于网络节点功率不同和数据包长度不同的情况,其分类效果优于原有特征。本文通过选择性集成学习提升分类系统的泛化能力,实验结果表明,当识别目标与训练样本的网络配置不同时,选择性集成方法的协议识别效果较单分类器和全部集成方法有明显提升。
本文提出的MAC协议特征对ALOHA协议和S-ALOHA协议的区分能力较差,还需进一步改进。由于选择性集成方法在学习过程中除需训练基分类器外,还需对基分类器进行选择,因此训练时间较长是该方法的不足。另外,对多频点MAC协议的特征提取方法和识别算法是今后的研究方向。
