一种用于提升深度学习分类模型准确率的正则化损失函数
2020-02-08杨斌李成华江小平石鸿凌
杨斌,李成华,江小平,石鸿凌
(中南民族大学 电子信息工程学院,智能无线通信湖北省重点实验室,武汉430074)
基于具有数百万个参数的大型卷积神经网络的深度学习算法在图像分类中表现出出色的性能[1-4].它可以自动从原始数据中学习鲁棒的特征,并共同优化特征表示和分类器以获得最佳结果[5]. 随着大数据时代的到来和计算能力的发展,神经网络的结构已从浅层网络演变为深层网络. 通过增加深度,神经网络可以获得近似的目标函数和更好的特征表示. 但是,这种方式增加了模型的复杂性,并且会遇到过拟合的问题.因此,学者们提出了许多正则化技术来克服过拟合问题,例如L1正则化[6]、L2正则化[7]和Dropout[8].
L1和L2正则化分别通过L1和L2范数限制权重的增长来降低网络的复杂性,因为通常认为参数值较小的模型相对简单,可以缓解过拟合问题.Dropout通过在每轮迭代训练中随机丢弃神经元之间的连接来训练不同的网络,最终融合所有模型来预测结果.这三种方法在一定程度上提升了模型的准确率.但是,L1,L2正则化,Dropou以及其他正则化方法都是对神经网络的权重进行约束,而对神经网络的输出分布的正则化技术在目前很大程度上尚未被探索[9,10].标签平滑方法[11]是一种输出正则化器的具体实现,其实验结果表明拟合平滑标签是增加模型泛化能力的一种有效的方法,但存在缺陷,即该方法需要根据经验手工设置平滑系数,需要多次实验才能找到最佳的平滑系数.
本文提出了一种新的标签平滑正则化损失函数,称为得分聚类损失函数,以缓解由标签边缘化效应引起的过拟合问题.具体来说,得分聚类损失会自动从数据集中学习每种类别的得分中心,并最小化样本得分与其相应的类别得分中心之间的距离.在传统的标签平滑方法[11]中,标签平滑的程度需要根据经验来手动设置超参数,而本文的方法可以自动从数据中学习一个最佳的标签,这个标签即为得分中心通过softmax函数归一化后的概率向量.得分聚类损失函数是可导的,能够通过梯度反向传播算法和softmax损失函数联合优化网络模型,有效缓解了过拟合问题,进一步提高图像分类任务的准确率.
1 标签边缘化效应
对于分类任务,网络模型通过使用“softmax”函数对输出得分进行归一化,从而产生分类概率:
(1)
其中zk是网络前向传播得到的得分.
在图像分类任务中,经常使用交叉熵损失函数来衡量预测概率和真实标签的差异:
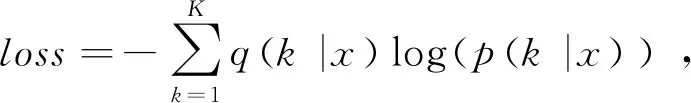
(2)
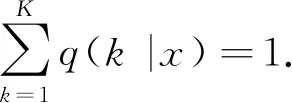
交叉熵损失对得分zk是可导的.导数如下:
(3)

在训练网络进行图像分类时,我们需要最小化交叉熵损失,这等效于最大化正确标签的对数概率log(p(k|x)).这种方式只考虑正确标签位置的损失,而不考虑其他标签位置的损失,会使得模型过于关注增大预测正确标签的概率,而不关注减少预测错误标签的概率,我们称这种现象为标签边缘化效应.最后导致的结果是模型在自己的训练集上拟合效果非常良好,而在测试集结果表现不好,即过拟合,也就是模型过于自信而导致泛化能力差[11].
2 提出的方法
针对标签边缘化效应引起的过拟合问题,本文提出了得分聚类损失函数,该函数为每一类样本学习一个得分中心,并使训练样本前向传播得到的得分向量向得分中心聚拢.得分聚类损失限制了预测正确标签位置得分的无限增长,使模型能够学到一个较为平滑的标签,减弱了模型的自信,增强了模型的泛化能力,从而提升了模型的准确率.得分中心通过softmax归一化后的概率,即为学到的平滑标签.
softmax损失函数表示如下:
(4)
其中Syi是第i个样本中属于yi类的得分,m为一批训练数据的个数.
得分聚类损失函数LSC定义为:
(5)
其中Si是i个样本的得分向量,SCyi是yi类的得分中心.SCyi的维度与Si相同,等于类别的个数.
SCyi初始化为全零向量,在训练过程中不断更新.yi∈{0,1,2,……j},j为类别取值.公式(5)将得分和得分中心的距离做了约束,减弱了模型过于关注增大正确标签的得分的能力.
SCj更新规则如下:
(6)
SCt+1j=SCtj-αΔSCj,
(7)
其中如果条件满足,δ(条件)=1,否则为0.t为迭代步数,α是得分中心的学习率,取值[0,1].公式(6)计算了一批训练数据中每一类的得分和其得分中心的平均差距,公式(7)通过减小此平均差距来更新得分中心.
使用softmax损失和SC损失来联合训练网络.最终的损失函数为:
Ltotal=Lsoftmax+λ*LSC=
(8)
其中λ用来平衡两个损失函数.当λ=0时,Ltotal退化为Lsoftmax,得分聚类损失失去了作用. 当λ太大时,softmax损失的效果将被忽略,这会导致训练效果不佳.单纯使用它们中的任何一个都不能改善网络. 因此,将它们结合起来联合训练网络是必要的.
在每轮迭代过程中,先通过公式(8)计算网络的整体损失,并利用梯度下降法更新网络权重参数,然后通过公式(6)和公式(7)更新得分中心.通过迭代训练,每一类的得分被约束到了得分中心附近,限制了预测正确标签位置得分的无限增长,从而缓解了过拟合问题.
3 实验和分析
3.1 数据集
本文实验中,分别在刚性物体和非刚性物体图像数据集上对比了得分聚类损失、L2正则化、dropout和标签平滑方法[11]的准确率.
标签平滑方法[11]将原始的独热码标签做了平滑处理,处理方法如公式(9).
(9)
其中ε是平滑参数.δk,y是Dirac函数,当k=y时取值为1,否则为0.k为独热码向量的维度,y为样本的类别标签.K为类别数目.如标签[1,0],在ε取0.1时,标签被平滑为[0.9,0.05].
L2正则化方法中,对权重进行了L2范数约束,抑制权重的增长来降低网络的复杂性,以缓解过拟合的问题.Dropout通过在每轮迭代训练中随机丢弃一定比例神经元之间的连接来训练不同的网络,以此方法达到缓解过拟合的目的.
在刚性物体图像分类任务中,我们做了十分类和二分类的任务.对于十分类任务,我们使用了MNIST数字识别数据集中的60000训练图像和10000测试图像.对于二分类任务,我们使用了CIFAR-10数据集中的飞机和汽车图像,其中包括10k训练图像和2k测试图像(此数据以下表示为CIFAR-2).之所以使用两类数据而不是整个CIFAR-10数据集,是为了得到样本得分的分布图来方便地说明得分聚类损失的影响.对于非刚性物体图像分类任务,我们使用了由袁非牛教授实验室[12]建立的烟雾图像数据集,该数据集包含用于训练的8805个烟雾图像和8511个非烟雾图像,和用于测试的552个烟雾图像和831个非烟雾图像.数据集详细情况见表1.

表1 本文与其他正则化方法准确率对比Tab.1 Comparisons with other regularization methods on accuracy
3.2 网络模型结构
对于任务A,我们训练了具有ReLu激活函数和含有512个节点的两层隐藏层的全连接神经网络.
对于任务B和任务C,我们训练了一个卷积神经网络,它由卷积层、批归一化层、最大值池化层和全连接层组成,网络模型结构见图1.

图1 网络模型结构Fig.1 The structure of model
3.3 网络模型训练
本实验的软件训练环境为:Windows系统,Python3.5,Tensorflow1.4.硬件环境为: Intel Core I7 CPU 3.30GHz,4-GB GPU(Nvidia GTX1050Ti GPU).
网络的权重参数初始化为标准差0.01的正态分布.对于标签平滑方法[11],使用[0.1,0.2,0.3,0.4,0.5]标签平滑参数做实验,发现0.1对所有任务效果最佳.对于得分聚类损失,在[0.1,0.01,0.001,0.0001]范围内改变参数λ,发现0.001对任务A和C效果最佳,0.0001对任务B效果最佳.训练超参数设置见表2.

表2 训练超参数设置Tab.2 Hyper-parameters setting of Training
3.4 实验结果和分析
采用的最终结果是最后1000步迭代的平均准确率,实验结果见表3.在任务A和B上,得分聚类损失的使模型的准确率提高了约0.2%~1%.在任务C中,得分聚类损失的使模型的准确率提高了约为0.1%~2%.在本实验所有分类任务中,得分聚类损失均表现出较强的正则化能力,可以更有效地提高模型的准确率和泛化能力.

表3 本文与其他正则化方法准确率对比Tab.3 Comparisons with other regularization methods on accuracy
为了阐明得分聚类损失对得分分布的影响,在任务B中提取softmax的输出,并绘制散点图进行分析.如图2所示,形状“x”是飞机样本,其标签为[1,0].它应该在二维坐标的右下角.形状“⊙”是汽车样本,标签为[0,1].它应该在左上角.当仅使用softmax损失函数训练模型时,预测的标签大部分是[1,0]和[0,1],这反映了模型对其预测非常自信,大量不同类别样本在[1,0]处混叠在一起,影响了分类准确率.
在加入得分聚类损失函数后,样本得分向每类的得分中心聚集.由于有分类错误的样本,所以飞机和汽车样本不再聚集在[1,0]和[0,1]处,而是分别在[0.89,0.11]和[0.9,0.1]周围.每个类别的分数有所下降,但准确率上升了.这反映了得分聚类损失减少了正确类别的得分,减弱了模型的自信程度,缓解了过拟合问题,从而改善了分类效果.

a)仅使用softmax损失的得分分布 b)加入得分聚类后的得分分布图2 得分分布图Fig.2 The distribution of score
4 结语
本文提出的得分聚类损失函数减弱了模型的自信程度,可以自动从数据中学习到较为合理的标签,起到了标签平滑的作用,避免了根据经验人工选择标签平滑系数,有效的缓解了过拟合问题.实验结果表明,得分聚类损失有助于增强分类模型的泛化能力,准确率有了显著的提升.并且该损失函数可以通过梯度反向传播算法与softmax损失联合优化分类模型,很容易嵌入其他分类模型和分类任务中,应用较为广泛.