超融合架构下部署Hadoop 集群的尝试与思考
2020-02-05李立
李立
(泰兴市人民医院,江苏泰兴 225400)
随着医院信息化建设需求的不断提高以及相关医疗信息化技术的创新发展,云计算、大数据BI、AI 等信息技术在医疗行业得到广泛应用[1]。现今,医学数据呈现出了庞大的大数据特征,数据稀疏、维度提高的数据应该如何科学地进行高效计算、分类存储、深度挖掘等将成为尚待研究的新兴课题。
1 研究背景
我院于2014 年开始开展虚拟化平台项目,使用的是两套IBM Flex 刀箱,配合两套EMC VPLEX做了两地METRO 部署。随着业务的不断扩展,同时考虑到信息集成平台项目尽快落地,2018 年开始陆续进行超融合部署,10 台DELL EMC 机架式服务器,其中3 个全闪节点加7 个混闪节点。2019 年,我院信息集成项目正式启动,集成平台和数据中心相继成功部署落地。然而,信息集成平台内的数据中心采集工作刚刚开始不足2 个月,VSAN 平台即出现了一次报警。超融合平台一共90T 的可用空间,在不足2 个月的时间就已经用去近80%,剩余空间甚至不能支撑BI 运营平台的数据抽取与分析,频频报错。经过仔细探讨与分析,我们逐渐发现端倪,超融合架构与Hadoop 集群的结合,利弊共存。
2 分析
2.1 超融合
2.1.1 关于超融合
超融合架构(Hyper-converged Infrastructure)是指我们在同一套信息设备单元中含有存储、计算、网络和虚拟池化等技术,包括数据备份、缓存加速、数据消重、数据压缩与业务连续性无缝对接保护等因素,多个业务节点通过网络重组得以实现高可用性的横向扩展,逐步形成了统一资源池的架构[2]。对于医院细节方面繁琐的控制要求较为突出,因为超融合架构的所有资源都是池化处理的,某一节点出现问题的情况下,超融合的机制可以十分有效地避免业务中断,当业务系统建立的同时也建立了业务系统镜像,因此,在提高系统容灾、冗余方面有着显著的作用,其工作架构拓扑见图1。

图1 超融合架构拓扑图
2.1.2 关于副本
首先,允许的故障数(FTT)定义了虚拟机对象允许的主机和设备故障数量。如果FTT 为n,则创建的虚拟机对象副本数为n+1,见证对象的个数为n,这样所需的用于存储的主机数为副本数+见证数=n+1+n=2n+1。如果我们此次设置的副本数为2,表示的就是最多允许1 台主机出故障,也即FTT 值为1,此时主机数最少为3。虚拟机存储策略允许的故障数,如果已配置故障域,则需要2n+1 个故障域,且这些故障域中具有可提供容量的主机[3]。
前述超融合能提供可靠的冗余方案,述及关于副本。此次数据中心部署的环境为7 台混闪节点,考虑到安全冗余度和性能实际使用率,因为超融合集群内有7 台主机,我们最多能允许有3 台主机同时发生故障而数据不丢失,所以,此次我们设置的副本数为2,即双副本机制。
2.2 Hadoop 技术
2.2.1 关于Hadoop
我院信息集成平台和数据中心建设采用了Hadoop 2.0 版本的技术架构,该基础技术架构属相对主流的云计算及大数据技术框架,该架构的核心技术是由HD FS 文件系统和MapReduce 的计算框架所组成,数据库方面是由数据仓库工具Hive 和分布式数据库Hbase 为核心所组成[4]。使用该框架解决了海量数据计算和大规模存储带来的问题,使用MongoDB 来进行存储,经过分词、索引后的数据,为前端的业务应用提供数据支撑。
2.2.2 关于副本
HDFS (Hadoop Distributed File System)格式即为Hadoop 分布式文件系统。HDFS 有很多特点:①保存了多份副本文件,并且提供丰富的容错机制,如副本丢失或宕机系统会自动恢复,默认存3 份副本。②运行在廉价的机器上。③适合海量数据的处理分析。
与集成平台厂商确认过后,我们得到了3 份副本的配置机制。我们分别查看了Hadoop 集群内的4台主机,存储占用情况只有1TB 不到,那为什么我们的超融合平台内查看的存储占用总共近80TB?是哪里的数据会占用这么大的空间?
2.3 真因
从图2 和图3 我们可以清楚地看到,正如此前所分析的,超融合技术我们设置的是双副本机制,Hadoop 集群我们默认设置的是三副本机制,仔细观察不难找出问题的真因所在,即:每一份数据都有6 个备份,且Hadoop 的数据写入与删除机制默认会存在空间不可释放性[5],导致了超融合平台存储占用率如此之高。
3 重构
基于存储空间不足,可以深刻认识到此前的集群部署极其不合理。但2 个月的数据中心的数据抽取与核对分析已经完成,并且有了很好的展示效果,是否该把整个集群重新部署?如何保证此前的数据不丢失并且进行集群的无缝重构?这是我们急需面对的问题。
3.1 容量与副本
考虑到之前超融合平台分配给每一台Hadoop主机的磁盘容量为10TB,纵观整个超融合平台存储磁盘总体容量与配比,此次部署Hadoop 集群内的磁盘容量缩减至6TB,且Hadoop 集群的副本数调整为2 副本,加上超融合机制的双副本,每份数据缩减至了4 个备份,保证数据安全的前提下,大大缩减了磁盘空间。
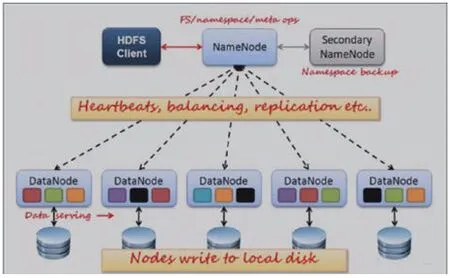
图2 HDFS 按照Master 和Slave 的结构分布

图3 HDFS 按默认配置Rack1,Rack2,Rack3
3.2 数据迁移
为了保证数据的完整性,我们通过超融合平台为原先Hadoop 集群中的一台Hadoop04 挂载一块500G 的硬盘,将原先10TB 磁盘中的1 个副本(所有数据都在内)复制到500G 的新磁盘内,复制完成后随即删除10TB 磁盘,重新分配1 个6TB 磁盘并挂载,并将500G 磁盘内的副本镜像再复制回6TB 磁盘中,完成之后随即再删除这块500G 的临时中转磁盘。同理,再选择另外一台Hadoop03 的主机,重复以上操作。
在完成了两台Hadoop 集群内主机的磁盘重新部署之后,整个超融合平台的存储空间大幅度释放开来,Hadoop 集群内的另外两台Hadoop01 和Hadoop02 主机则不需要通过挂载临时中转磁盘进行数据迁移,直接分配并挂载6TB 磁盘,副本复制即完成数据重新安全部署,如图4 所示。
3.3 分析
通过对Hadoop 集群内主机的重新调整和数据迁移,整体存储磁盘进行了重构,既保证了数据的完整性和安全性,又使得超融合平台内的存储空间得到大大释放,使得复杂且异构化的数据存储在统一平台实现了数据统一管理[6]。

图4 调整后的Hadoop01 配置
4 讨论
新一代的医院信息集成平台和数据中心建设需有大规模、高可用的数据管理系统做支撑,要求对联机事物处理的支持能力相对强大,才能确保系统具有安全性、可扩充性、可移植性、高效性和可靠性,必须能适应不同的软硬件架构平台[7]。医院信息集成平台和数据中心建设的系统架构要尽可能采用高性能的服务器集群,且要拥有强大的容灾能力和负载均衡性能。
本次所分享的案例,是超融合平台和Hadoop集群的一次不经意间的尝试,虽然仍然有来自于医院同行和专业厂家技术大咖的强烈建议:Hadoop是Apache 开源的分布式数据计算框架,一般可以使用在廉价的硬件设备组成的服务器集群上运行的应用[8],也就是说,Hadoop 集群正常应该与传统存储结合使用,将其跑在超融合平台上确实是有点奢侈,且从存储磁盘利用率上来讲不太划算,但是考虑到超融合强大的计算资源、存储资源和网络资源整合池化能力所带来的I/O 读写吞吐的大幅提升能力,以及从两平台互补的数据副本安全性角度来看,我们认为融合平台和Hadoop 集群的“联姻”未尝不可。
