基于演化算法的唐诗自动生成系统研究
2020-01-11穆肇南刘梦珠孙界平王成
穆肇南 刘梦珠 孙界平 王成

摘要:针对基于演化算法的唐诗自动生成系统展开研究.研究工作主要有:使用GloVe(Global Vectors for Word Representation)模型训练词向量,设计了基于关键词和平仄押韵的初始种群方案、基于语法语义加权值的适应度函数、基于锦标赛算法的选择策略、基于启发式交叉算子和启发式变异算子的演化算法;给出了基于演化算法的唐诗自动生成模型及系统实现.实验表明,根据给定关键词,该系统初步实现了唐诗的自动生成,生成的唐诗经人工修改后具有一定的欣赏价值.
关键词:演化算法;自动生成;唐诗;自然语言处理
中图分类号:TP391
文献标志码:A
文章编号:1000-5641(2020)06-0129-11
0引言
自然语言生成在自然语言处理领域中占据着重要的位置,它是研究和模仿人类自然语言文本生成的过程和方法。自然语言生成研究的是,计算机根据文本信息在机器内部形成表达的形式,即模拟人类生成一段高质量的自然语言文本.唐诗语言形式简洁凝练,是中华民族两千多年来思想、文化、精神、情感的一种艺术体现,人们希望借助技术手段,以人工智能为载体,让计算机自动“创作”出能与唐诗媲美的诗歌.
本文从唐代诗歌出发,对唐诗自动生成系统进行了研究和实现;基于演化算法搭建自动生成模型,构建了一套较完善的唐诗自动生成系统.实验表明,文本系统可简单模拟人的思维,生成较押韵的诗词作品.
1相关研究
国际上对机器生成诗歌的研究兴起于20世纪70年代,此后又诞生了很多英语、德语、日语、韩语等语言的不同类型、不同风格的机器自动生成的诗歌.先后经历了随机词汇连接方法(代表系统为Pete Kilgannon的“LYRIC3025”)、基于模板的诗歌生成方式(代表系统有RACTER、PROSE和RETURNER等)、基于进化算法的诗歌生成方式(代表系统为Levy的POEVOLVE和Manurung H.M.的MCGONAGALL系统)等生成诗歌的方式,以及近年来基于序列模型生成诗歌的方法.
在我国,汉语古诗词计算机语言学方面的研究在20世纪90年代中期才开始兴起,其中值得关注的有20世纪90年代林鸿城独立开发的“稻香老农作诗机”、1999年费越在中科院自动化所开发的春联艺术系统、2006年微软中文网站上提供的一个中文对联在线生成系统、2007年游维的基于遗传算法的宋词自动生成研究、2010年游维的又一种宋词自动生成的遗传算法及其机器实现的研究、2011年曹卫华的基于进化策略的仿唐诗自动生成系统研究.除此之外,还有台湾元智大学与北京大学计算语言研究所合作开发的“古诗研究的计算机支持环境”模型系统、以160万字的宋代名家诗作为研究对象的“宋代名家诗自动注音系统”.近年来,也开始有人利用循环神经网络(Recurrent Neural Network,RNN)等方法创作中文诗歌,如清华大学的九歌系统就是采用最新的深度学习技术,结合多个诗歌生成的不同模型对超过30万首古代诗歌进行训练学习,以及东北大学自主研发的机器翻译系统NiuTrans等.诗歌作为汉语精髓,时至今日仍需更多的探索和发现.
本文主要针对唐诗这种独特的汉语诗歌体裁,基于演化算法设计并实现一个机器自动生成仿唐诗的系统.本文主要研究工作包括以下几个部分.
(1)建立唐诗语料库.首先通过对唐诗格律的研究将唐诗细分为子句,统计子句中的词语;其次根据通过GloVe模型得到的词与词共现的频率,筛选出结合强度较高的词语来建立唐诗词表;最后利用工具对已经切分的唐诗中的词语进行注音、词性标注及平仄押韵等工作.
(2)语法语义的处理.首先根据全唐诗语料库中诗歌的语法规则,判断生成的仿唐诗词句语法的正确性;其次通过GloVe模型计算两个单词之间的语义相似性;最后采用人工方式对高频词进行风格和情感的评判.
(3)设计基于演化算法的仿唐诗自动生成系统.根据唐诗的特点,本文运用启发式交叉算子和启发式变异算子进行杂交与变异,设计了基于语法规则、语义相似的加权适应度函数,基于锦标赛算法的选择策略.
(4)实现基于演化算法的仿唐诗自动生成系统,包括给出数据库建立模块、语法语义处理模块、基于演化算法的生成模块的具体算法实现流程以及仿唐诗生成实例等.
2基于演化算法的系统设计
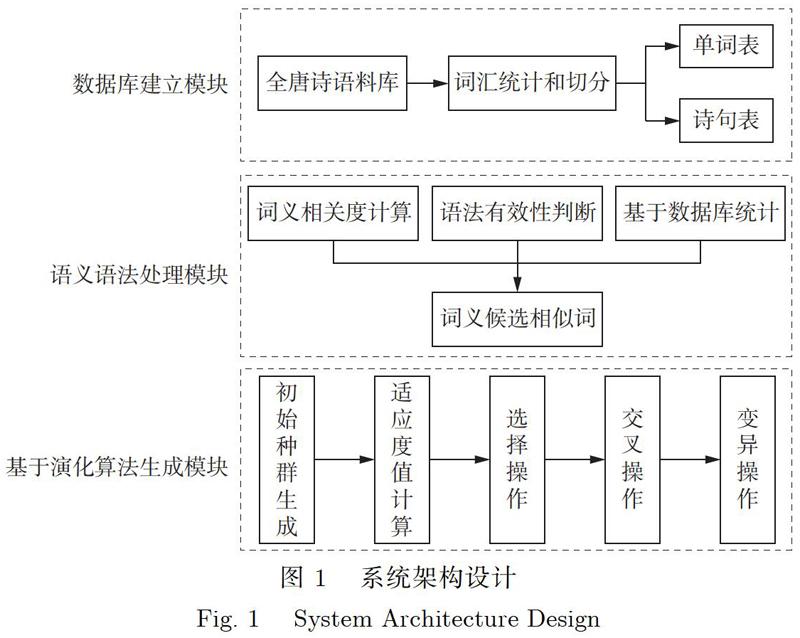
系统的总体架构分为3个基本模块:数据库建立模块、语义语法处理模块、基于演化算法生成模块.具体的系统架构设计如图1所示.
2.1数据库建立模块
先建立针对古代诗歌处理用的全唐诗语料库.由于本文的诗词生成主要集中于仿唐诗的机器生成,所以选取大量唐诗语料库进行切分,生成单字词;除此之外还将诗歌切分成单独的诗句并且存入数据库.数据项和数据结构设計如下.
(1)单字词,包括的数据项有编号、词语、拼音、平仄、词语频率、词语词性.
(2)诗句表,包括的数据项有编号、诗句.
由上述分析可知,本系统需要设计两张表:单字词表和诗句表.单字表用来存储单个字的基本信息.诗句表用来存放唐诗中出现过的所有诗句.
根据数据库分析中的存单字表的数据项可以设计出单字表,如表1所示.
同理,根据数据库分析中的存诗句表的数据项可以设计出诗句表,包含的字段有字段名、数据类型、长度、描述.
该模块实现的是对已有的唐诗的每行诗进行单字词的切分和各行诗诗句的切分,以及数据库建立的功能.
数据库建立包括对单字词进行词性、拼音、音韵、频率的标注等.利用分词工具对单字词的词性进行标注,利用注音工具对单字词的拼音进行标注,利用高频词查询工具对单字词的词频进行标注;继而利用SQL实现对单字表音韵的标注.
2.2语义语法处理模块
基于演化算法的唐诗机器自动生成设计根据适应度函数值的大小进行优胜劣汰,那么关键问题就是要设计出评价机器自动生成的唐诗优劣程度的量化计算方式.本文通过对大量唐诗的构成规律、语法结构、语义呈现及情感表达等方面的研究,总结出了唐诗的质量主要体现在语法的规范性和语义的关联度两方面.
在语法方面,主要考虑两个方面:一是唐诗词性组合规则;二是押韵平仄规则.首先本系统需要通过对大量唐诗词性组合规则的总结来确立合适的诗歌语法规则,通过对大量唐诗构成规律的分析总结出语法规则.然后需要考虑诗歌的押韵问题,押韵的要求可以根据词库的音韵标注来实现.系统最终从这两个方面判断生成的仿唐诗的语法合法性.
诗歌在语义方面要求风格统一、主题连贯、情感丰富等.对于给定的主题词,本系统主要使用GloVe模型计算两个单词之间的语义相似性,进而建立起词与词之间的关联度.GloVe融合了矩阵分解(Latent Semantic Analysis,LSA)的全局统计信息和局部上下文窗口(Local Context Window,LCW)优势.融入全局的先验统计信息,可以加快模型的训练速度,又可以控制词的相对权重.具体实现包括以下3步.
第一步,根据语料库构建一个共现矩阵X,矩阵中的每一个元素Xij代表单词i和上下文单词j在特定大小的上下文窗口内共同出现的次数.一般而言,这个次数的最小单位为1,但是GloVe模型根据两个单词在上下文窗口的距离d提出了一个衰减函数decay=1/d,用于计算权重,也就是说距离越远的两个单词所占总计数的权重越小.
通过以上模型计算两个单词之间的语义相似性,进而建立词与词之间的关联度,使词与词之间更有凝聚力,使产生的句子看起来更有意义,且符合语义语法的要求.语法语义处理模块流程图如图2所示.
2.3基于演化算法生成模块
基于演化算法生成模块主要是实现生成仿唐诗的功能,主要包括初始种群的生成、适应度值的计算、选择操作、交叉、变异这5个步骤.
首先,种群的初始化主要步骤如下.
第一,根据给定的主题词,从数据库中抽取与其相关的候选词,构成候选词空间.
第二,从候选词空间随机选择高频词进行随机组合,生成一首五言仿唐诗.
第三,判断生成的仿唐诗的第二行诗押的是什么韵脚,如押的是仄韵,那就再判断仿唐诗第四句是不是同样押的仄韵,如若不是则随机从候选词空间选择一个押仄韵且与韵脚语义相关度强的高频词来替换原来的词,从而使得整个诗歌押的都是仄韵;重复此操作,直到最终能够生成含有N个个体的初始种群.
其次,就是计算其适应度.本次试验个体适应性评判主要依据是否符合词性组合规则(C)、是否符合押韵平仄规则(Y)以及词义相关度(X),适应度函数F为以上3个测量依据归一化后的加权值,即
再次,就是选择操作,此操作就是从群体中选出更加适应环境的个体.在此操作中本系统采用了锦标赛算法,算法具体实现是通过父代与之生成的子代进行比较,适应度值高的个体会存活下来继续产生下一代个体,适应度值低的个体将会被其子代取代.基于演化算法生成模块的具体流程如图3所示.
最后,就是杂交和变异操作.杂交时随机选择两个父代个体,然后再将两个父代个体中的各行进行杂交生成新个体.变异则是在每一个个体中的每一行随机抽取一个位置,把此位置上的词换成候选词中与之词义相近的候选词,如果抽取的位置是韵脚,那就要在候选词里选取与韵脚押相同韵的词语来进行替换.
3基于演化算法的系统实现
3.1语法语义处理模块的实现
语法语义处理模块包括语法合法性的确立和语义相关度的计算的实现.语法规范的确立主要是通过合法的词性语法规则以及诗歌的平仄和押韵来实现的.就唐诗而言,每种体裁下的句法都有固定的总句数、每一句都有固定的总字数、每句话的最后一个字又或者是偶数句通常是押韵的.所以根据唐诗的这种语法要求,本系统通过对大量的唐诗进行学习總结出了语法规则,具体语法规则如N(名词)+V(动词)+N+N+V、N+V+A(形容词)+N+V;还对此次生成的五言绝句在其第二行与第四行的最后一个字进行了押韵操作,比如新生成诗的第二行的韵脚是平声,那本首诗第四行的最后一个字必然也是押平声.词义相关度通过使用GloVe模型计算两个单词之间的语义相似性来实现.
3.2基于演化算法的生成模块的实现
仿唐诗的生成模块是基于演化算法来实现的,具体算法的实现主要包括初始种群生成、交叉操作、变异操作、适应度值计算和选择操作这5个部分.
初始种群生成是根据输入的主题词,从数据库中抽取与其相关的候选词,随机选择满足押韵要求的候选词来填充诗歌需要押韵的位置,在满足平仄押韵要求的基础上,随机抽取候选词填充唐诗中剩余的位置来生成满足唐诗诗歌的要求,重复此操作,直到最终能够生成含有N个个体的初始种群.
则依据是否符合词性组合规则(C)、是否符合押韵平仄规则(Y)以及词义相关度(X)的加权来进行计算的,重复此操作直至计算出整个种群的适应度值.
选择操作是基于锦标赛算法,通过比较父代与子代的适应度值,选择适应度高的个体留下繁殖下一代,适应度值低的将被淘汰.因此,适应度值计算和选择操作的关系比较紧密.
交叉操作是随机抽取父代X1,然后随机在两行诗中产生一个杂交点point,其中X1中的第一行杂交点point之前(包括杂交点point本身)的部分保留,杂交点point之后的部分被X1第二行杂交点point后的部分取代,就这样X1经过变异后产生了新的个体.
变异操作就是在每一首诗的每一行诗句中以概率p随机抽取一个变异点point,变异点point前后部分继续保留,但是变异点point则选用与其相关的候选词进行填充,如若抽取到韵脚,则要选取与韵脚声调相同的字进行填充,以保证诗歌的押韵规则不被破坏.
以上为基于演化算法机器自动生成唐诗的具体实现,下面给出机器生成唐诗的演化算法實现流程,算法主要包括初始种群生成、适应度值计算、选择操作、交叉操作和变异操作,具体实现见算法1.
上述算法实现中,g为根据给定关键词产生的候选词集合,N为初始种群中个体的数量,k为设置的最大进化次数,F为适应度值,p为个体变异的概率.其主要计算由是否符合词性组合规则(C)、是否符合押韵平仄规则(Y),以及词义相关度(X)的加权和得到.
4实验结果与分析
4.1实验数据
针对本文的唐诗自动生成系统,采用以下参数进行测试:①进化次数分别为100次、200次、300次,相应对比数据为500次、1000次、1500次;②初始种群数分别为20个、30个、40个,相应对比数据分别为40个、60个、80个;③变异率(p)分别为0.1、0.3、0.5,相应对比数据分别为0.2、0.4、0.6;④输入的关键词分别为“花、风、秋、天、春”.具体测试数据如表2至表5所示.
4.2实验结果
本系统以关键字“花、风、秋、天、春”为例.当输入这些关键词,体裁为五言绝句时,系统自动提取关键词并在数据库中查找与关键词相关的候选词.部分候选词如表6所示.
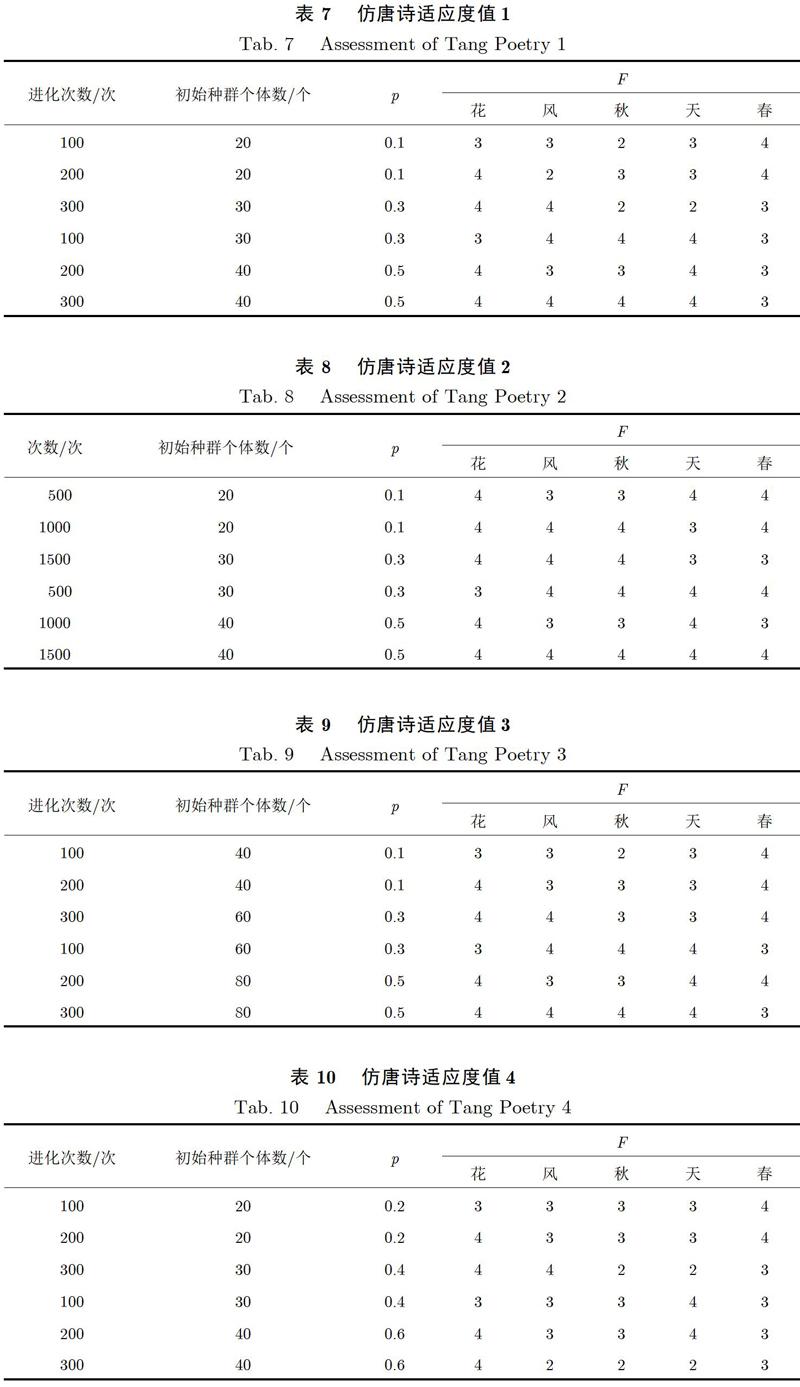
根据上述给定的关键词以及设置的各种参数,系统自动生成的仿唐诗适应度值如表7至表10所示.
根据上述实验结果数据显示,比较表7和表8可知,初始种群和变异率相同时,进化次数越大,所有关键词产生的诗歌整体质量有所提升;比较表7和表9可知,进化次数和变异率相同时,初始种群越大,所有关键词产生的诗歌整体质量也有所提升;比较表7和表10可知,进化次数和初始种群相同时,初始种群数量较小,变异率增大时,部分关键词产生的诗歌整体质量也有所提升,而当初始种群数量较大,变异率增大时,部分关键词产生的诗歌整体质量却有所下降.
由上述结果可见,进化次数和初始种群的大小对诗歌整体质量的影响呈正相关,变异率在初始种群较小的时候对整体诗歌的质量正相关,而在初始种群较大时,其影响却不明显甚至部分关键词产生的诗歌的质量有所下降.
通过多次输入关键词“花、风、秋、天、春”得到大量的仿唐诗,虽然这些仿唐诗和真正的唐诗比起来还有一定的差距,但是经过对诗词创作风格辨析的研究及人工筛选,还是能够得到适应度值较高且可读性较强的仿唐诗.生成仿唐诗的具体参数如表11所示.
5结论
在对国内外现有的机器自动生成诗歌方法研究的基础上,本文给出了一种基于演化算法的唐诗自动生成模型及其系统实现.首先通过对唐诗格律的研究,建立含有的词性、音韵、词频等属性的唐诗语料库;然后根据全唐诗语料库中诗歌的语法语义规则,判断生成的仿唐诗的词句语法合法性以及词义的相关度;最后结合唐诗构成特点,设计了包含初始种群、适应度函数、选择、交叉和变异等优胜劣汰操作在内的演化算法模型,并加以系统实现.实验结果表明,演化算法在唐诗自动生成方面具有较好的通用性,基本上达到了研究目标.本研究将现代机器智能技术与到中国传统文化进行交叉融合,弘扬了中国诗歌文化.但是研究工作也存在诸多不足之处,如系统的自学能力不足、生成诗句的好与坏的评测标准的定义缺乏、生成唐诗的评价体系欠缺等都将可以成为下一步研究的方向.
