多尺度生成式对抗网络图像修复算法*
2020-01-11李克文张文韬邵明文
李克文,张文韬,邵明文,李 乐
中国石油大学(华东)计算机与通信工程学院,山东 青岛266000
1 引言
随着深度学习在计算机视觉领域的飞速发展,图像编辑(image editing)和图像生成(image generation)问题的研究已经取得了显著的成效。本文讨论的图像缺失修复(image inpainting)问题,是介于图像编辑和图像生成之间的一个热点问题,在图像缩放、文物保护、公安刑侦面部修复、生物医学图像应用和航空航天技术等领域具有重大意义。
图像修复是一个传统图形学的问题:在一幅图像上的某一位置缺失了一定大小的区域,利用其他的信息将这个缺失区域恢复,让人们无法辨别出修复的部分。
如图1 所示(从左到右依次为原始图片、缺失图片以及修复图片),两幅图像中的缺失区域中分别有杯子和花,人们可以根据周围图像的内容,很容易就能把图像补全。由于人的大脑具有主观意识,不同的人修复效果存在差异性,因此在图像修复的过程中必须遵循结构性、相似性、纹理一致、结构优先等原则。但图像修复任务对于计算机却格外困难,因为这个问题没有唯一确定的解,如何利用其他的信息去辅助修复,如何去判断修复结果是否足够真实,是研究者们所关心的问题。

Fig.1 Repair of two different images图1 两张不同图片的修复
目前,基于结构的图像修复、基于纹理的图像修复和基于深度学习的图像修复是图像修复领域的三个主要方向,本文的研究主要是针对基于深度学习的图像修复算法。近年来,卷积神经网络(convolutional neural networks,CNN)[1-2]极大地提高了语义图像的分类、目标检测和分割等任务的性能[3-5]。国内外研究人员已经将CNN 模型用于图像修复任务,但仅使用CNN 的修复方法结果精度不高,性能有很大的提高空间。
针对现有方法存在的问题,本文提出一种多尺度生成式对抗网络模型,得到高精度、高准确率、视觉一致性强的修复图像:首先,提出了一种由生成器和对抗性判别器组成的深度生成对抗修复模型,利用重构损失和对抗损失,从随机噪声中合成缺失的内容。其次,提出了一种多尺度的判别器结构,通过使用不同分辨率的图像进行对抗训练进行图像修复。然后,生成器中使用扩张卷积来降低图片下采样过程中信息的丢失,利用当前流行的泊松混合方法对修复图像进行了一定的后续处理。最后,通过实验说明本文提出算法的优势和图像的修复效果。
2 相关工作
传统图像修复方法例如Bertalmio 等人[6]利用扩散方程沿着掩模边界的已知区域的低级特征迭代地传播到未知区域。虽然在修复中表现得很好,但仅限于处理小而均匀的区域。通过引入纹理合成[7],进一步提高了修复效果。Zoran 和Weiss 在文献[8]中,通过学习图像块的先验来恢复具有缺失像素的图像。
早期的基于深度学习的图像修复方法,如Ren 等人在文献[9]中学习了一种卷积网络,通过一种高效的图像块匹配算法[10]大大提高了图像修复的性能。当发现类似的图像块时,它的性能很好,但是当数据集中没有包含足够的数据来填充未知区域时,它很可能会失败。Wright 等人[11]将图像修复作为从输入中恢复稀疏信号的任务。通过求解稀疏线性系统,可以根据一些损坏的输入图像来修复图像。然而,这种算法要求图像高度结构化。Kingma 等人在文献[12]中提出了变分自编码器(variational auto-encoders,VAEs),通过在潜在单元上施加先验,使图像可以通过潜在单元采样或插值生成。然而,由于基于像素级高斯似然的训练目标,VAE 生成的图像通常是模糊的。
随着深度学习的进一步发展,Goodfellow 等人在2014 年提出的生成式对抗网络模型(generative adversarial network,GAN)[13]是深度学习发展中的一个里程碑式的进展。随着GAN 的问世,解决了利用传统的VAE 生成图片模糊的问题,取得了令人震惊的效果,理论上能够生成大量清晰图片。Larsen 等人在文献[14]中通过添加一个对抗性训练的判别器来改进VAE,该判别器来自生成式对抗网络,并证明了可以生成更真实的图像。与此工作最接近的是Pathak 等人提出的“Context Encoder”模型[15],该方法应用了一个自编码器,将学习视觉表示与图像修复相结合,但使用这种方法修复的图片效果在某些情况下并不理想,修复区域与整张图片会有明显的不一致性,在修复区域的边缘效果不是很好。针对“Context Encoder”模型出现的问题,早稻田大学的Iizuka 等人进行了改进[16],将设计扩展为两个判别器,使用经过训练的全局和局部上下文判别器来分别区分真实图像和修复图像,使网络能够产生局部以及全局一致的图像。
使用GAN 进行图像修复的主要问题之一是模型训练过程中的不稳定性,比如网络无法收敛,容易出现梯度消失以及梯度下降等问题,这导致了对该问题的大量研究[17]。最新的研究表明,传统GAN 中交叉熵(Jensen-Shannon divergence,JS 散度)不适合衡量生成数据分布和真实数据分布的距离,如果通过优化JS 散度训练GAN 会导致找不到正确的优化目标。Arjovsky 等人提出的Wasserstein GAN[18]从损失函数的角度对GAN 进行了改进,损失函数改进之后的WGAN 即使在全连接层上也能得到很好的表现结果,解决了训练不稳定的问题。Gulrajani 等人在Wasserstein GAN 基础上进行了改进[19],优化了连续性限制的条件,解决了训练梯度消失和梯度爆炸的问题并且加快了收敛速度。Mao 等人提出的LSGAN(least squares GAN)[20]模型使用了最小二乘损失函数代替了GAN 的损失函数,同样缓解了GAN 训练不稳定,生成图像质量差以及多样性不足的问题。
由于人们对于GAN 生成图片的分辨率要求越来越高,随之而来的另一个问题是由于网络在池化过程中会对图像进行下采样提取低维特征,造成图像中很多关键信息的丢失,判别器更容易分辨出图片真假,使得梯度不能指示正确的优化方向。那么如何有效地利用神经网络每层提取的特征,最大限度地减少下采样过程所带来的损失的同时充分提取图像的低维特征,是当前研究的一个热点。Yu 等人在2016 年提出了扩张卷积的方法[21],在卷积过程中可以扩大感受野的同时使特征图大小保持不变,有效地降低了传统卷积过程中由于下采样所带来的信息丢失,并用于图像处理。Wang 等人提出的“pix2pixHD”模型[22]利用条件生成对抗网络(conditional GANs)[23]来合成高分辨率逼真的图像,利用了一个最新的多尺度生成器-判别器结构,稳定训练的同时提升了图片质量并且提高了图片的分辨率。图2 所示为多尺度判别器模型示意图,它们具有相同的网络结构,但在不同的图像尺度下工作。将这些判别器称为D1、D2 和D3。具体来说,分别对真实的和合成的高分辨率图像进行下采样。然后训练D1、D2 和D3 分别在三个不同的尺度上区分真实图像和合成图像。

Fig.2 Multi-scale discriminator models图2 多尺度判别器模型
本文的工作建立在Pathak 等人提出的“context encoder”方法以及Iizuka 等人提出的“globally and locally consistent image completion”方法的基础之上。通过使用均方误差(mean squared error,MSE)损失结合GAN 损失,能够训练一个图像修复网络,避免了仅使用MSE 损失时常见的模糊。仅仅使用这种方式会使网络训练不稳定。本文通过使用WGAN 中的损失代替传统GAN 的损失,利用EM(earth mover)距离去衡量数据分布之间的差异,不训练纯粹的生成模型和调整学习过程来优先考虑稳定性来避免这个问题。此外专门针对图像修复问题对架构和训练过程进行了大量优化。特别地,不使用单一判别器而是使用多个判别器,采用类似于“pix2pixHD”模型[22]中的多尺度判别器来提高视觉质量。
3 多尺度对抗网络模型
在本章中,将介绍多尺度生成式对抗网络模型及原理,包括一个生成网络用于图像修复,四个额外的判别器网络辅助训练,即两个多尺度判别器网络,一个全局判别器网络和一个局部判别器网络,以便训练整个网络能够出色地完成图像修复任务。在训练期间,训练判别器以确定图像是否已经修复成功,同时训练生成器以欺骗所有判别器。只有通过一起训练的所有网络,生成器才能真正地修复各种图像。网络架构如图3 所示。

Fig.3 Network architecture图3 网络架构
3.1 生成式对抗网络原理
GAN 的主要原理来源于博弈论中的思想,整个网络包含两个相互对抗的网络结构,即生成网络G(generator)和判别网络D(discriminator),如图4 所示。通过G和D不断进行对抗博弈,进而使G学习到真实数据的分布,如果将对抗网络用于图像的生成,则经过不断地训练后,G可以从一个噪声中生成逼真的图像。G、D的主要功能是:G是一个生成式网络,G的输入是一个随机的噪声Z(随机数),通过这个噪声生成用于欺骗D的假图片即G(Z)。D是一个判别网络,用来判别一张图片的真实性。它的输入是一张图片,可能来自于数据集中的真实图片,也可能来自于G生成的图片,输出为D判定输入是真实图片的概率,如果输出概率是1,表明D判断输入为真实的图片,如果输出概率为0,表明D判断输入不可能是真实图片(即G生成的图片)。训练过程中,生成网络G的任务就是生成逼真的假图像去混淆判别网络D的判断。D的目标就是尽量辨别出G生成的假图像和真实的图像。因此,G和D的训练过程就构成了一个动态的“博弈过程”,最终达到平衡状态即纳什均衡。博弈的结果为在最理想的状态下,G可以生成足够真的图片,而D难以判定G生成图片的真实性,即输出概率为0.5,这样就训练出了一个可以大量生成逼真图片的生成式网络模型G。

Fig.4 Generative adversarial network model图4 生成式对抗网络模型
3.2 生成器
采用一个卷积自编码器作为生成器模型G,即一个标准的编码器-解码器结构,编码器结构采用具有缺失区域的图像作为输入,通过卷积操作生成该图像的潜在特征表示。解码器结构利用这种潜在特征表示通过转置卷积操作恢复原始分辨率,产生缺失区域的图像内容。与从噪声向量直接开始的原始GAN 模型不同,从编码器获得的隐藏表示捕获了未知区域和已知区域之间的更多变化和关系,然后输入解码器生成内容。中间层使用了扩张卷积,允许使用更大的输入区域计算每个输出像素,没有额外的参数以及计算量,相比于标准卷积层,扩张卷积网络模型可以在输入图像更大的像素区域的影响下计算每个输出像素。如果不使用扩张卷积,它将仅使用较小的像素区域,无法利用更多的上下文信息进行图像的合成。
生成器使用标准的自编码器网络,在此基础上添加了扩张卷积层,即Iizuka 等人提出的生成器网络去掉了中间两层卷积层,网络体系结构如表1 所示。从左到右依次为网络层类型(conv 为卷积层,d-conv为扩张卷积层,deconv 为反卷积层),卷积核大小,卷积核零填充的数目,步长以及该层输出通道数。
3.3 判别器
通过对生成器进行训练,使其能够利用小的重构损失填充缺失区域相应的像素。仅仅使用生成器并不能确保填充的区域在视觉上保持真实一致。生成的图像缺失区域像素非常模糊,只能捕捉到缺失区域的大体形状。为了获得更逼真的效果,加入了全局判别器、局部判别器以及多尺度判别器作为二值分类器来区分真假图像,目的是辨别图像是真实的还是经过修复的。判别器帮助网络提高修复结果的质量,训练有素的判别器不会被不切实际的图像所愚弄。这些判别器基于卷积神经网络,将图像压缩成对应的小的特征向量。预测对应于图像是真实的概率值。
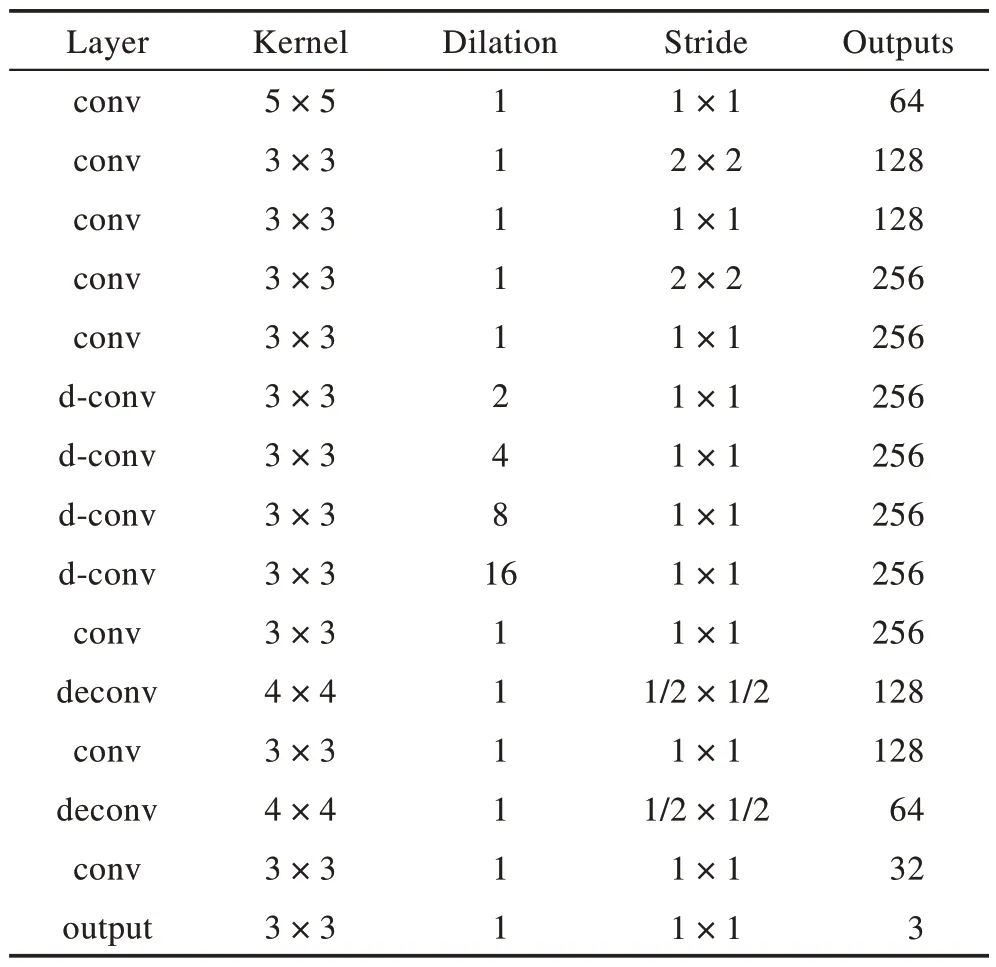
Table 1 Architecture of generator G表1 生成器G 体系结构
首先是局部判别器Dl,它决定了缺失区域的合成内容是否真实。能够帮助网络生成缺失内容的信息。它鼓励生成的对象在语义上是有效的。由于局部判别器的局部性,它的局限性也很明显。局部判别器损失既不能使一张脸的全局结构规范化,也不能保证缺失区域内外边缘的一致性。因此,修复图片的像素值沿修复区域边界的不一致性很明显。
由于局部判别器的局限性,引入另一个名为全局判别器的网络结构Dg来确定图像作为一个整体的准确性。基本思想为,生成图像修复区域的内容不仅要真实,还要与上下文保持一致。具有全局判别器的网络极大地缓解了不一致的问题,进一步提高了生成修复图片的效果,使其更加真实。
最后,提出了一种多尺度判别器网络结构。其基本思想是,对真实的和合成的图像分别进行下采样,下采样系数为2 和4,训练两个判别器Dm1、Dm2分别在两个不同的尺度上区分真实图像和修复图像。通过两个输入为不同分辨率图像的判别器网络,对生成器修复图像的过程进行了严格的控制,两个多尺度判别器以及全局判别器具有相似的架构,但具有不同大小的感受野。相比于单独使用全局判别器,联合多尺度判别器进行训练可以引导生成器生成全局一致性更强的修复图片以及更精细的细节,整张图片的修复效果在视觉上更合理。通过将两个多尺度判别器加入到网络中,能够得到效果更好的修复图片。
将Iizuka 等人提出的全局判别器和局部判别器去掉最后两层全连接层,其他结构不做改变。全局判别器、局部判别器和多尺度判别器网络体系结构如表2~表5 所示。从左到右依次为网络层类型、卷积核大小、步长以及该层输出通道数。表2、表3、表4、表5 分别为Dl、Dg、Dm1、Dm2。
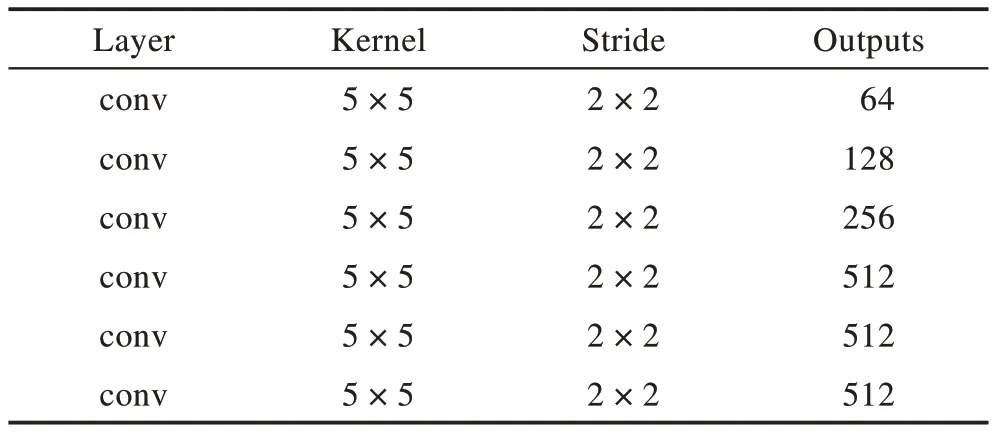
Table 2 Architecture of local discriminator Dl表2 局部判别器Dl 体系结构

Table 3 Architecture of global discriminator Dg表3 全局判别器Dg 体系结构
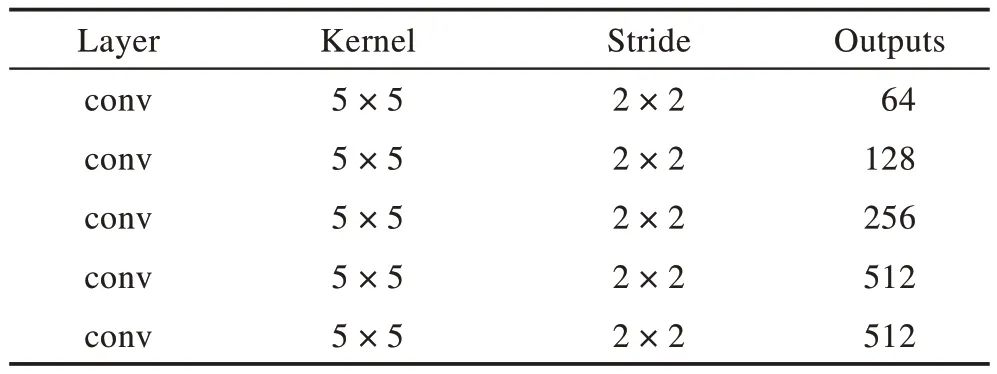
Table 4 Architecture of multi-scale discriminator Dm1表4 多尺度判别器Dm1体系结构

Table 5 Architecture of multi-scale discriminator Dm2表5 多尺度判别器Dm2体系结构
3.4 损失函数
通常有多种合理的方法来填充与上下文一致的缺失图像区域。例如可以通过一个损失函数来建模这种行为。因此首先向生成器引入重构损失Lr,负责捕获缺失区域的结构信息并与上下文保持一致,即修复图像与原始图像像素之间的L2 距离,z为噪声掩码:
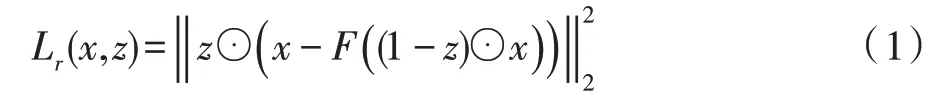
但仅仅使用Lr损失,观察到生成的修复图像内容趋于模糊和平滑。因为L2 距离损失的原因是由于严重惩罚了异常值,鼓励网络平滑地跨越各种假设以避免大的惩罚。通过使用判别器,引入了对抗性损失,这反映了生成器如何最大限度地愚弄判别器,以及判别器如何区分真假。对抗性损失是基于GAN 的损失。为了学习数据分布的生成模型,GAN学习一个对抗性判别器模型D,为生成器模型提供损失梯度。对抗性判别器D同时对生成器G生成样本和真实样本进行预测,并试图区分它们,而生成器G则通过产生尽可能“真实”的样本来混淆判别器D:
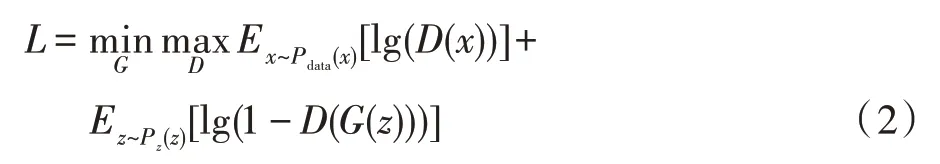
其中,Pdata(x)和Pz(z)分别表示真实数据x和噪声变量z的分布。通过最小化生成器损失以及最大化判别器损失来优化网络。
由于传统GAN 模型训练过程中的不稳定性,使用WGAN 的损失函数及方法训练GAN,具体做法为去掉判别器D最后一层的sigmoid,G和D的损失函数不取损失函数对数,本文算法不使用传统的GAN的目标函数而使用了这种方法:
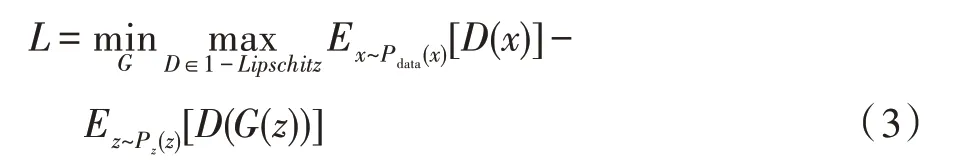
判别器D满足1-Lipschitz限制,本质上就是要求网络的波动程度不能太大,具体做法为每次更新D的参数之后,并将其绝对值截断,使其不超过一个固定的常数,即weight clipping。
4 个判别网络{Dl,Dg,Dm1,Dm2}对损失函数的定义相同。唯一的区别是,局部判别器仅为缺失区域提供训练的损失梯度,全局判别器和多尺度判别器在不同分辨率的整张图像上反向传播损失梯度。局部判别器Dl的输入为生成器G输出图像的修复部分和真实图像对应的部分。全局判别器Dg的输入为生成器G输出图像和真实图像。多尺度判别器Dm1的输入为生成器G输出图像和真实图像分别下采样2倍的输出图像和真实图像。多尺度判别器Dm2的输入为生成器G输出图像和真实图像分别下采样4 倍的输出图像和真实图像。判别器分别定义为:
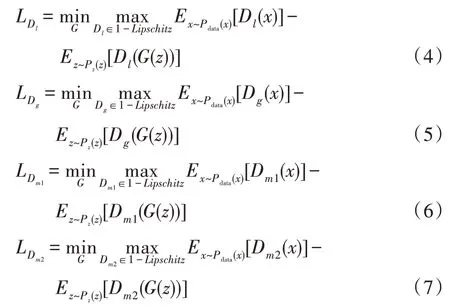
综上所述,整个网络优化的总损失函数定义为:
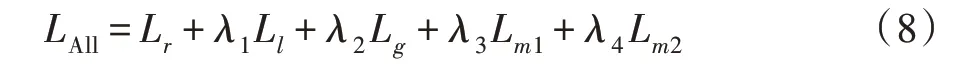
式中,λ1、λ2、λ3、λ4为不同损失相应的权重,用来平衡不同损失对整个损失函数的影响,λ1、λ2、λ3、λ4的具体数值在实验过程中需要人为设定。
4 训练
本文的工作是基于深度卷积对抗神经网络的实现,为了有效地训练网络,将训练过程分为3 个阶段:首先,训练生成器网络G,利用重构损失对网络进行训练,生成器可以得到模糊的修复内容,此阶段不包含对抗训练和对抗损失。其次,利用第一阶段训练完成的生成器网络去训练所有判别器网络{Dl,Dg,Dm1,Dm2},利用对抗损失去更新所有判别器。最后一个阶段对生成器和所有判别器进行联合对抗训练。每一阶段都为下一阶段的改进做好准备,从而大大提高了网络训练的有效性和效率,训练过程是通过反向传播完成的。

在进行对抗性损失的训练时,采用类似于文献[24]的方法,避免训练过程开始时识别器过强的情况。使用了文献[25]中建议的默认超参数(例如学习率)。设置λ1、λ2、λ3、λ4均为0.001。通过调整图像大小来完成训练,将图像裁剪为256×256 的图像用作输入图像。对于缺失区域,在图像中的中心正方形区域的输入设为0,即图像缺失部分,大约覆盖了1/4 的图像。全局判别的输入为256×256 大小的完整图像,局部判别器的输入为128×128 大小修复区域的图像,两个多尺度判别器的输入分别为128×128 和64×64 大小的完整图像。本文的网络模型可以合理填充缺失的区域,但有时生成的区域与周围区域会有颜色不一致的情况。为了避免这种情况,通过将修复的区域与周围像素的颜色混合来执行简单的后处理。特别地,本文使用了泊松图像混合[26]对图像进行后续处理。
5 实验结果与分析
本文使用从CelebA 数据集中获取的100 000 张图像来训练多尺度生成式对抗网络模型。80 000 张用于训练,20 000 张用于测试,该数据集包括各式各样的人脸图像,人脸图像的修复相对于场景图像的修复难度更大,面部图像的修复需要更多的修复细节,如五官的位置以及面部的对称性,修复难度相对较大,因此对神经网络的设计提出了更高的要求,batchsize大小设置为32。生成器网络经过20 000 次迭代,然后训练判别器经过10 000 次迭代,最后共同训练整个网络70 000 次。设备参数为CPU,Intel i7-8700;GPU,RTX2080Ti-11 GHz;内存,DDR4-3000-32 GB。代码在Pytorch 深度学习框架下运行,整个网络训练完成时间为5 天左右。
当然也可以尝试加入更多的多尺度判别器,在实验中发现两个判别器对于网络修复效果的提升已经足够,加入过多的判别器会使整个网络变得复杂,增加网络的参数以及运行时间。
将实验得到的修复结果与仅使用了一个作用于修复区域的判别器的CE(context encoders)方法,以及使用生成器和两个判别器的GLCIC(globally and locally consistent image completion)方法的实验结果进行比较。为了比较的公平性,重新训练了上述模型,并进行相同次数的迭代,结果如图5 所示。
图5 展示了CelebA 测试数据集上的人脸修复结果。在每个测试图像中,网络都会自动覆盖图像中间的区域,因为一般在中间部分会包含面部的重要组成部分(例如,眼睛、嘴巴、眉毛、头发、鼻子)。4 行分别代表了4 张不同测试图像的修复结果。第1 列图(a)分别对应着4 张原始未缺失的图像。第2 列图(b)为加了掩码的缺失图像。第3 列图(c)为“context encoders”网络的修复结果,由于这种结构缺乏对全局一致的理解,可以看到利用这种方法修复的结果不仅有明显的全局不一致性,缺失区域修复效果也非常模糊,无法达到图像修复任务的要求。第4 列图(d)为加入全局判别器以及局部判别的“globally and locally consistent image completion”方法的修复效果图,引入对抗损失使得网络能够更合理地对图像进行修复,局部判别器针对图像缺失区域产生影响,使得缺失区域部分能够成功完成修复,全局判别器针对修复图片的全局不一致性,会对整张图像产生影响,强制网络生成全局一致的图像,消除了明显的边缘差别,修复结果较好。第5 列图(e)即本文算法的修复结果,使用了WGAN 损失,使整个对抗网络的训练更稳定。加入了多尺度判别器,与全局判别器和局部判别器联合训练。可以看到相比于图(d)的结果,图(e)在修复的细节方面有了一定的提升,图像整体性更高,修复效果更加良好。

Fig.5 Comparison of repair results of different models图5 不同模型的修复结果比较
除了视觉效果之外,本文还对CelebA 测试数据集使用了PSNR(peak signal to noise ratio)和SSIM(structural similarity index)进行定量评估,这两个指标是通过不同方法获得的修复结果与原始人脸图像之间进行计算的。
第一个指标是峰值信噪比(PSNR),是一种评价图像的客观标准,它直接测量像素值的差异,单位是dB,数值越大表示失真越小。假设输入的两张图像分别是X和Y,计算公式如下:
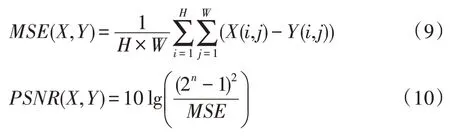
其中,MSE表示修复图像X和真实图像Y的均方误差,H和W分别为图像的高度和宽度,n为每像素的比特数,一般取8,即像素灰阶数为256。结果如表6所示。
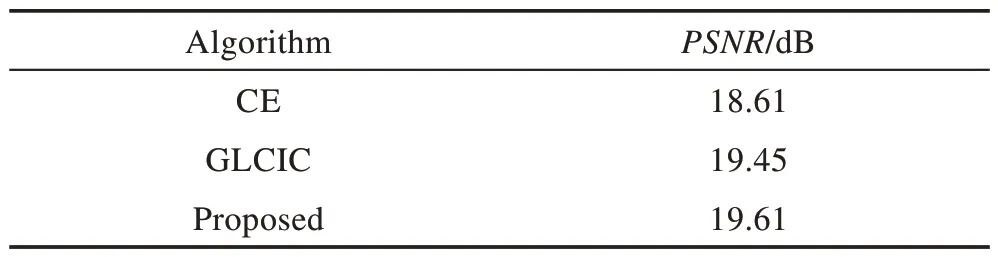
Table 6 Quantitative experimental results on PSNR表6 PSNR 上的定量实验结果
第二个指标是结构相似性指数(SSIM),它是一种衡量两幅图像相似度的指标,为一个0 到1 之间的数,数值越大代表修复图像和真实图像的差距越小,即图像质量越好。当两张图像一模一样时,其值为1。假设输入的两张图像分别是X和Y,计算公式如下:
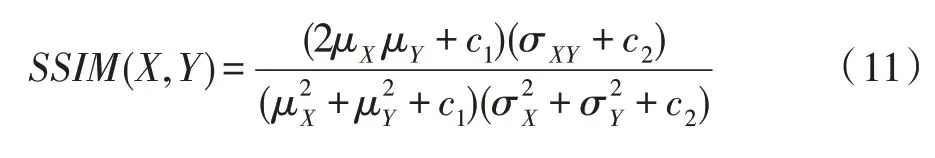
其中,μX和μY分别代表X、Y的平均值,σX和σY分别代表X、Y的标准差,σXY代表X和Y的协方差,而c1、c2分别为常数,避免分母为0。计算结果如表7 所示。
此外,为了证明本文算法可以适用于多种类型的图像修复,分别使用了ImageNet 数据集中获取的50 000 张图像和Places2 数据集中获取的50 000 张图像对本文模型进行相应的训练。网络模型训练方法和在CelebA 数据集中使用的训练方法相同,实验结果分别如图6 和图7 所示,表明该模型在ImageNet 数据集和Places2 数据集上也有着良好的表现。
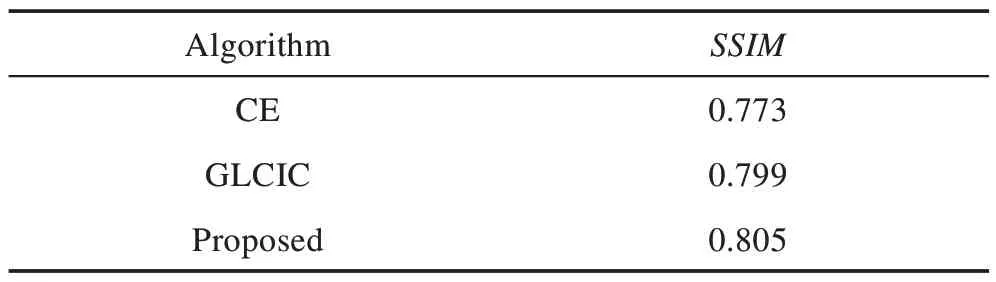
Table 7 Quantitative experimental results on SSIM表7 SSIM 上的定量实验结果
6 结束语
近年来,深度学习在计算机视觉领域成果百出,基于深度学习的图像修复技术的研究已经初见成效,有着广泛的应用前景。本文首先介绍了图像修复技术的研究背景及意义,简单回顾了国内外的研究现状,分析了现有算法存在的不足。然后对生成式对抗网络原理进行了介绍,分析了生成式对抗网络存在的问题,并将改进之后的生成式对抗网络模型应用到图像修复问题的研究中,提出了一种由生成器和多个对抗性判别器组成的多尺度生成对抗修复模型。利用重构损失以及多个对抗损失,从随机噪声中合成缺失的内容,结合WGAN 的思想,采用EM 距离模拟数据分布,提高网络稳定性的同时提升了图片修复的效果。最后在CelebA 数据集上进行验证,利用定性和定量的评价方法,证明了本文所提出的基于多尺度生成式对抗网络的图像修复算法相较于当前的图像修复方法具有更好的修复效果。并且在ImageNet 数据集以及Places2 数据集上也进行了相应的训练和测试,证明了该算法可以被应用于多种类型图片的修复,且具有很好的效果。
此外,在图像修复的实验过程中发现,在大多数情况下网络输出的图像修复效果很好,但在某些情况下网络输出的修复图像会出现一些奇怪的像素,即伪像,使得整张图片看起来很不自然,出现这种情况的原因可能是由于网络在卷积过程中将一些无效像素的特征进行了提取。这种情况对于图像修复任务来说是不好的。图像修复任务的目的是尽可能地通过图像现有的信息对缺失区域进行补全,伪像的出现使得修复效果变差。本文接下来的工作将针对这个问题对网络模型进行改进,寻找一种能够消除伪像的方法,如部分卷积,以达到更好的图像修复效果。

Fig.6 Repair results on ImageNet dataset图6 ImageNet数据集上的修复结果

Fig.7 Repair results on Places2 dataset图7 Places2 数据集上的修复结果
