低尺度血管检测在视网膜血管分割中的应用*
2020-01-11吴鑫鑫肖志勇
吴鑫鑫,肖志勇,刘 辰
江南大学 物联网工程学院,江苏 无锡214122
1 引言
报告显示,截至2017 年,全球约4.25 亿成人患糖尿病,占总人口的8.8%,预计到2045 年,糖尿病患者可能达到6.29 亿。2017 年全球糖尿病患者(20~79岁)分布中,中国达到了1.144 亿,排在第一位。据评估,全球有多达2.124 亿人或所有20~79 岁糖尿病患者的一半不知道已患病[1]。并且已知病史的糖尿病患者中,视网膜病变的患病率高达65.2%[2]。视网膜血管的形态、宽度、角度等信息可以直接用于疾病的诊断和筛选[3],因此早期的检测很重要。
传统的检测需要医生手工标注血管,任务量大,需要耗费近两小时[4]来完成一张图片的血管分割。为了节约人力,提高效率,需要借助计算机辅助,自动化地分割血管。视网膜血管分割方法主要有两大类:一类是非监督学习的分割方法;另一类是监督学习的分割方法。
非监督学习方法主要是根据血管的某个或者多个特性来提取血管。主要有基于形态学的方法、基于血管跟踪的方法、基于匹配滤波的方法和基于形变模型的方法。其中基于形态学的方法[4-6],主要利用了血管比背景亮度低的特点,通过形态学膨胀腐蚀等操作,能很好地检测出大部分血管。但是此类方法对高亮度区域(视盘、光斑)较敏感,并且对比度较小的血管以及细小的血管检测效果不太理想。基于匹配滤波的方法,主要利用血管具有较小的曲率,并且血管的横截面近似于高斯曲线的特性。最常见的有高斯滤波[5]、Gabor 滤波[7],操作简单,但是对噪音的影响较大。Azzopardi 等人[8]设计出了B-COSFIRE滤波器,该滤波器可以对不同方向上的血管主干和末端进行精确检测,尤其对细小的血管有很好的检测效果。基于血管跟踪的方法[9-10],主要利用了血管连续的特点,找到起始点,沿着血管网络不断延伸,直到满足终止条件停止。自动跟踪算法的难点在于初始种子点的设定,人为的设定需要增加人工负担,自动设定需要精确定位到血管内部。好的跟踪算法不仅能检测连续血管,还需要能够检测连续的血管段,这样才不会由于血管的局部连续而过早结束。基于几何形变模型的方法[11-12],主要是用连续的曲线来描述血管的轮廓。边界曲线通过能量函数的参数定义,为了使能量函数达到最小值,边界会在力的作用下,向血管的边界靠近,使得边界上的点处于稳定状态。这种方法对边界敏感,因此背景中的相似部分以及噪音会对结果产生一定的影响。
监督学习的方法主要是事先标记好血管点和背景点,再通过构造好的模型来学习输入到输出间的映射关系,不断调整模型。监督学习的改进方法主要有两个方面:一个是基于输入的特征,输入的特征的个数以及特征在血管方面的特征表达能力,Aslani等人[13]选用了高达17 个特征作为输入,包括了Gabor滤波响应特征、顶帽变换、B-COSFIRE 滤波响应等;而谢林培[14]仅用了彩色图像的3 个通道作为输入特征。另一种是基于模型,对于不同的模型,特征提取的能力也不一样,蔡轶珩等人[4]采用了支持向量机(support vector machines,SVM)作为分类模型,SVM 是比较典型的二分类模型,主要原则为间隔最大化,对眼底图像的血管类和背景类像素点有很好的分类作用;Vengalil等人[15]提出了一种基于卷积神经网络(convolutional neural networks,CNN)的血管分割方法。该模型由1 个输入层、8 个卷积层、3 个池化层和1 个输出层组成。模型的输入直接是未作任何预处理的彩色眼底图像,输出层以内核大小为1×1 的卷积层替换全连接层,直接输出分割结果。其中,输出结果为灰度图像,还需进一步后处理,通过阈值分割,得到最后的血管分割图。这种以卷积层取代全连接层的网络也被称为全卷积神经网络(fully convolutional networks,FCN),也是图像语义分割的常用模型,可以模拟人脑的视觉系统处理方式,分割效果甚至能够超过人眼。姜玉静[16]在FCN 的基础上,采用了在边缘检测方面效果突出的HED(holistically-nested edge detection)网络模型[17],并通过条件随机场(conditional random field,CRF)进行后处理,得到的血管分割精度高达95.15%。监督学习的方法,在充足的训练数据和优异的模型下,分割的结果往往表现得比非监督学习的方法更好。
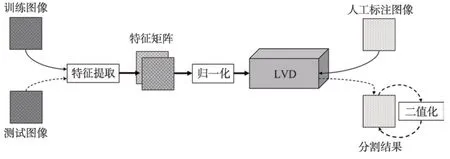
Fig.1 Flow chart of vessel segmentation图1 血管分割流程图
本文采用监督学习的方法,仅采用两个特征作为输入:一个是彩色视网膜图像对比度较高的绿色通道;另一个是经过B-COSFIRE 滤波得到的响应结果。网络模型采用的是LVD(low-scales vessel detection),每个尺寸通过子网络ADS(asymmetric depthfixed sub-network)提取血管特征,然后将两个低尺寸下的血管特征得到的单一输出结果融合原尺寸下的血管特征,得到输出结果,再二值化,得到最后的分割结果。
2 本文方法
分割血管的流程如图1 所示,在训练阶段,需要先对训练图像进行特征提取,将得到的两个特征归一化后,送入LVD 模型中训练,并通过人工标注图像进行不断自我学习。在测试阶段,需要将测试图像进行同样的特征提取和归一化操作,然后在训练好的网络模型中测试,得到测试结果。最后还需要二值化得到最后的分割结果。
2.1 特征提取
为了选取最典型的特征,本文除了将彩色视网膜眼底图像中对比度较高的绿色通道作为一个特征外,还使用B-COSFIRE 滤波器得到血管响应的特征。
B-COSFIRE 滤波器是受到简单细胞神经元对特定结构敏感的启发,开发出来检测图像中带状区域。B-COSFIRE 滤波器的输入需要通过一组线性对齐的高斯差分滤波器(difference of Gaussian,DoG)得到,这种计算模型是模拟丘脑内外侧膝状体背侧核细胞(lateral geniculate nucleus,LGN)感受视觉信号变化的过程[18]。图2(a)给出了一个检测垂直血管的B-COSFIRE 滤波器模型,其中垂直的白条是人为设计的血管,实心圆代表DoG 滤波器的过滤区域。以血管的中心黑点为模型的中点,将附近多个DoG 感应区域考虑进来后,整个B-COSFIRE 模型的感受野近似虚线围成的椭圆区域。最后,通过乘法操作将来自一组DoG 滤波器的响应结合起来,得到最终的滤波结果。DoG 滤波器表达式如下:
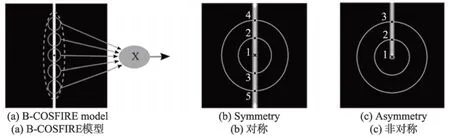
Fig.2 B-COSFIRE model and categories图2 B-COSFIRE 模型与类别
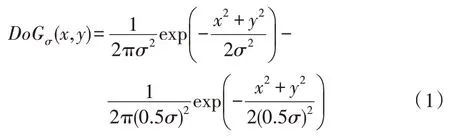
其中,外部高斯函数偏差为σ,内部高斯函数标准偏差为0.5σ[19]。对于给定的灰度图I,滤波后的结果为cσ(x,y)=|I×DoGσ|+,其中|·|+cσ符号表示去负为零,即整流线性单元(rectified linear unit,ReLU)。然后,通过响应结果cσ(x,y)自动构造B-COSFIRE 滤波器。图2 中显示了B-COSFIRE 两种滤波器,其中图2(b)是对称的B-COSFIRE 滤波器模型,可以检测血管主干;图2(c)是非对称的B-COSFIRE 滤波器模型,对血管末端有很好的检测效果。以图2(b)为例,以血管中心点(标注为1 的点,下同)和其周围的考察点(在同心圆上DoG 响应最大点,如标注2、3、4、5 的点,下同)构造一个三元组集合,其中σi为外部高斯函数的标准偏差,(ρi,φi)是第i个考察点以血管中心点为原点的极坐标,一共m个考察点。为了提高各个点位置的容错性,需要对DoG 滤波响应进行模糊移位操作。首先,模糊操作是计算DoG 滤波器的加权阈值响应的最大值,通过将DoG 滤波器的响应乘以高斯函数。偏差σ′的计算为σ′=,其中α、为常数,ρi为到血管中心点的距离。移位操作是将每个DoG 模糊响应朝着φi相反的位置移动ρi距离,以到达B-COSFIRE 滤波器的中心。移位量为(∆xi,∆yi),其中∆xi=-ρicosφi,∆yi=-ρisinφi。一个三元组(σi,ρi,φi)模糊移位的响应可以表示为:
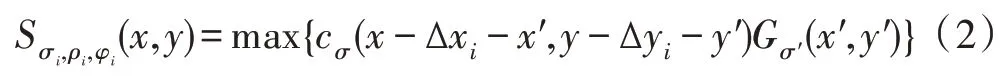
其中,-3σ′≤x′,y′≤3σ′。最后,求取集合S中所有三元组的模糊移位的几何平均,得到最终的滤波结果:

为了检测不同方向的血管,还需要设计不同方向上的B-COSFIRE 滤波器。而B-COSFIRE 滤波器能很容易调整,直接改变角度φi,就可以构造任意方向上的滤波器:


2.2 归一化
对数据的归一化操作,不仅可以降低运算量,而且会更快地收敛。本文将原始数据规范到[-0.5,0.5]的范围,大致分为两步。第一步,去掉异常值。本文通过3 倍标准差法去掉异常值,先将特征矩阵减去均值,得到新的特征矩阵,然后对特征矩阵中超过3 倍标准差的部分进行调整,使得新的特征矩阵与均值的差的绝对值不超过标准差的3 倍。第二步,缩放。在第一步操作基础上,对新得到的特征矩阵进行调整,采用最大最小规范化将数据映射到[0,1]的区间上,再减去0.5 得到。由于输入数据包含了多个特征,需要对每个特征维度进行归一化,然后再整合,一起作为LVD 的输入。
2.3 LVD
特征矩阵进行调整,采用最大最小规范化将数据映射到[0,1]的区间上,再减去0.5 得到。由于输入数据包含了多个特征,需要对每个特征维度进行归一化,然后再整合,一起作为LVD 的输入。FCN 是由Long 等人[20]提出来实现端到端的学习,并且输出和输入的数据尺寸相同,适用不同尺寸下的图像在同一网络模型中获取到特定的特征。在基于FCN 的网络架构中,Xie 等人[17]提出了HED 模型,如图3 左侧所示,该模型是在多尺度下,将每个尺度下的单一输出融合得到最后的结果,主要用来完成图像边缘的提取,具有很好的效果。本文简化了HED 模型,提出了LVD 模型,模型图显示在图3 中间。相比HED 模型,LVD 模型少了两个尺度,只保留了3 个尺度,分别代表原尺度和两个低尺度。并且在两个低尺度下都有一个单一输出层(single-output)。为了保留原尺寸的细节特征,需要将两个低尺寸下的single-output 融合原尺度下提取的feature maps,这样可以在一定程度上保留所有的细节,避免细节丢失。对于每个尺度下的特征提取,子网络的选取不仅要考虑到卷积核的尺寸,还需要考虑不同的组合。GoogleLeNet设计了Inception模块,从最初的Incetption v1到Inception v3,卷积核的尺寸越来越小,从Inception v3 到Inception v4,网络越来越深[21-24]。本文参考了Inception 模型简化参数和增加网络深度的思想,设计了非对称固定深度子网络(asymmetric depth-fixed subnet,ADS)。该网络有10 层卷积层,每一层的卷积核都是非对称的小卷积核,并且深度固定,如图4 所示。
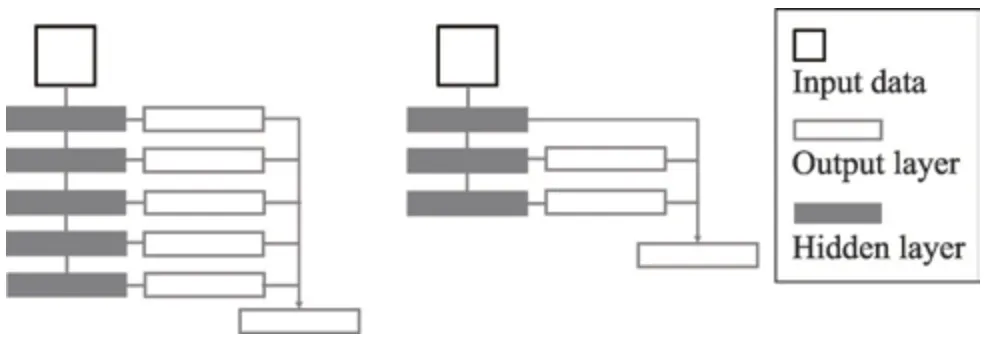
Fig.3 HED model and LVD model图3 HED 模型和LVD 模型
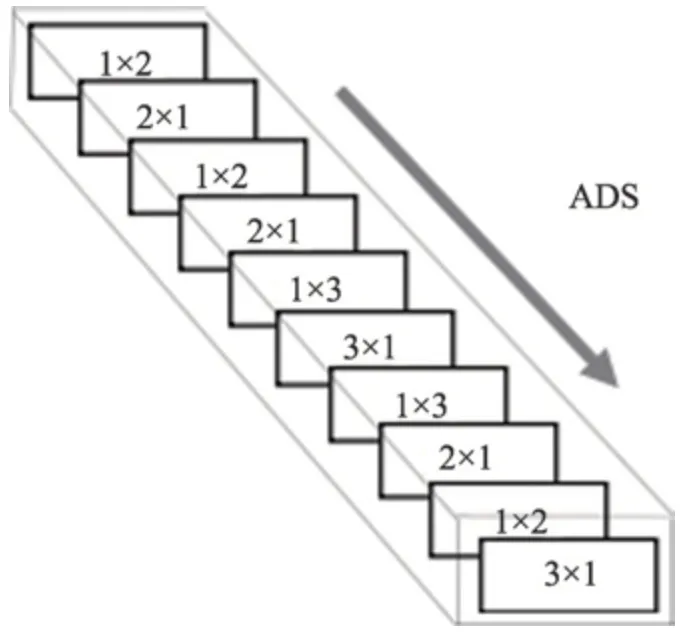
Fig.4 ADS structure图4 ADS 结构
其中,网络的第一层采用1×2 的卷积核,最后一层采用3×1 的卷积核。对于子网络ADS-N,则子网络ADS 中所有卷积核的深度都为N。将子网络ADS-N 组合到LVD 模型中,可以得到LVD 完整的网络结构,如图5 所示。网络中有3 个特征提取模块,主要是以尺度来划分,分为了原尺寸(scale0)模块、1/2 尺寸(scale1)模块和1/4 尺寸(scale2)模块。在原尺寸下,引入一个1×1 的卷积层,对特征进行降维,得到的feature maps 为M。在两个低尺寸下,用反卷积层(deconv)上采样,得到两个尺寸为scale0 的singleoutput。最后将原尺寸下的M个feature maps 与两个低尺度下的single-output 通过一个连接(concat)层融合,再用一个1×1 的卷积层卷积,得到一张与原图尺寸相同的二维血管灰度图,还需要对灰度图进一步阈值分割,得到最终的血管分割结果。在LVD 中,每个卷积层后跟一个BN(batch normalization)层来加速收敛和一个ReLU 层进行激活。网络中每一层的参数显示在表1 中,其中0 <M<N。
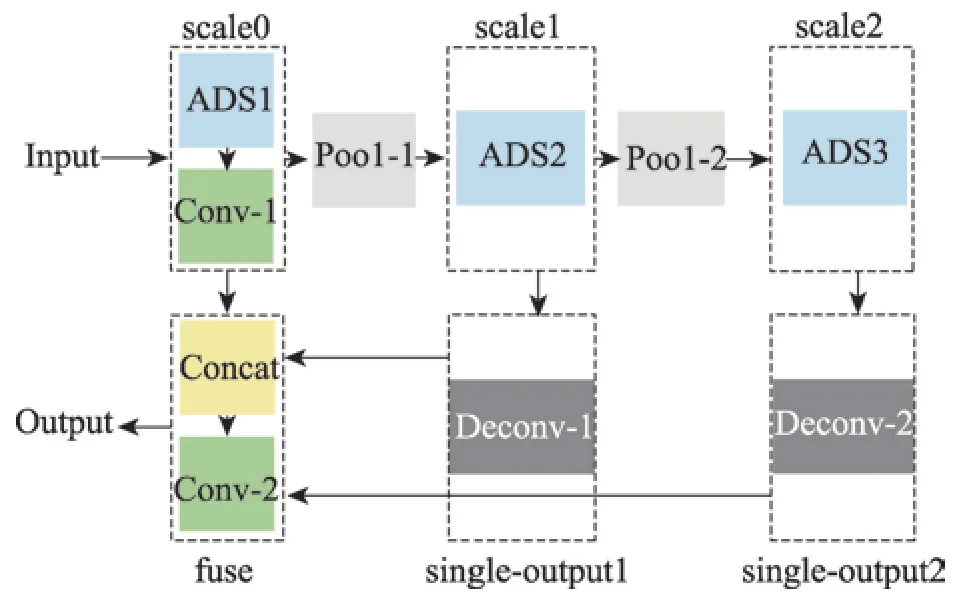
Fig.5 LVD structure图5 LVD 结构

Table 1 LVD parameters表1 LVD 参数
训练过程中,整个网络的损失函数采用均方误差,对于输出结果y与人工标注y′的均方误差计算如下:

其中,n代表像素点的个数,代表平方和。为了防止过拟合,在损失函数中引入了L2 正则化项,最终的损失函数Loss定义如下:
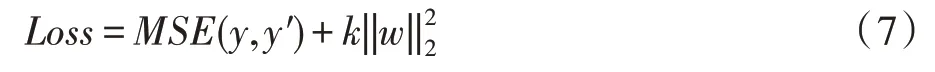
其中,w表示网络中边上的权重;k表示正则化项的权重。
3 实验与分析
3.1 数据集
DRIVE[25]是彩色眼底图库,一共40 幅图像,其中7 幅带有早期糖尿病视网膜病变,其余33 幅均为正常眼底图像。每幅图像的像素565×584,分成训练集和测试集,每个子集有20 幅图像,每幅图像对应两位专家手动分割的结果。本文选取第一位专家的分割结果作为评判标准,以第二位专家的分割结果作为人眼观察的结果。
数据集来自DRIVE 数据库,并通过旋转、缩放和镜像操作进行扩充。对于旋转,每张彩色眼底图像一次旋转3°,可以生成120 张不同角度的彩色眼底图像;对于缩放,每张彩色眼底图像从原尺寸的0.75 倍到原尺寸的1.25 倍,一次增加0.05 倍,可以产生11 个不同尺寸的彩色眼底图像;对于镜像,一张彩色眼底图像可以生成一个镜像。一张图像经过上面3个操作,再通过裁剪和填充使图像尺寸一致后,可以得到2 640张不同的彩色眼底图像,对于DRIVE 的20张训练集,扩充后,整个训练集拥有高达52 800张彩色眼底图像。
3.2 评价指标
评价指标主要有敏感性(Se)、特异性(Sp)、准确率(Acc)。计算公式如下:
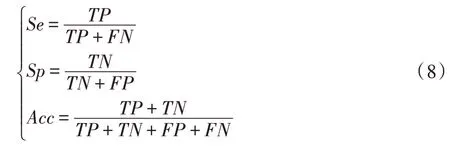
其中,真阳性(true positive,TP)表示将血管正确分割为正类的像素点数;真阴性(true negative,TN)表示将背景正确分为负类的像素点数;假阳性(false positive,FP)表示将背景错分为正类的像素点数;假阴性(false negative,FN)表示将血管错分割为负类的像素点数。另外,本文算法的性能也通过受试者工作特征(receiver operating characteristic,ROC)曲线来评价。ROC 曲线以真阳性率(true positive rate,TPR)为纵坐标,假阳性率(false positive rate,FPR)为横坐标。AUC(area under ROC curve)面积是ROC 曲线与横轴之间所夹的面积值,AUC 的值越接近1,表明算法的性能越好。
3.3 参数设置与实验分析
在特征提取阶段,B-COSFIRE的参数来自文献[8],对于对称的B-COSFIRE 滤波器,σ=2.4,σ0=3,α=0.7,ρ={0,2,4,6,8} ;而在非对称B-COSFIRE 滤波器中,σ=1.9,σ0=2,α=0.1,ρ={0,2,4,6,…,22};B-COSFIRE滤波器可以检测12 个方向的血管,即nr=12。
训练阶段,N=50,M=10,整个LVD 模型参数的初始化方式是从截断的正态分布中输出随机值,该正态分布的标准差为0.1;损失函数中的正则化的权值k=0.01,batch_size=5,学习率a=0.1,学习率采用指数衰减,衰减系数为0.99,衰减速度为200,迭代50 000 次,采用随机梯度下降算法更新参数,并采用滑动平均来控制变量更新的速度,控制速度的衰减系数为0.99。实验采用Tensorflow框架,在GeForce GTX 1080 Ti的两个GPU 上并行训练。
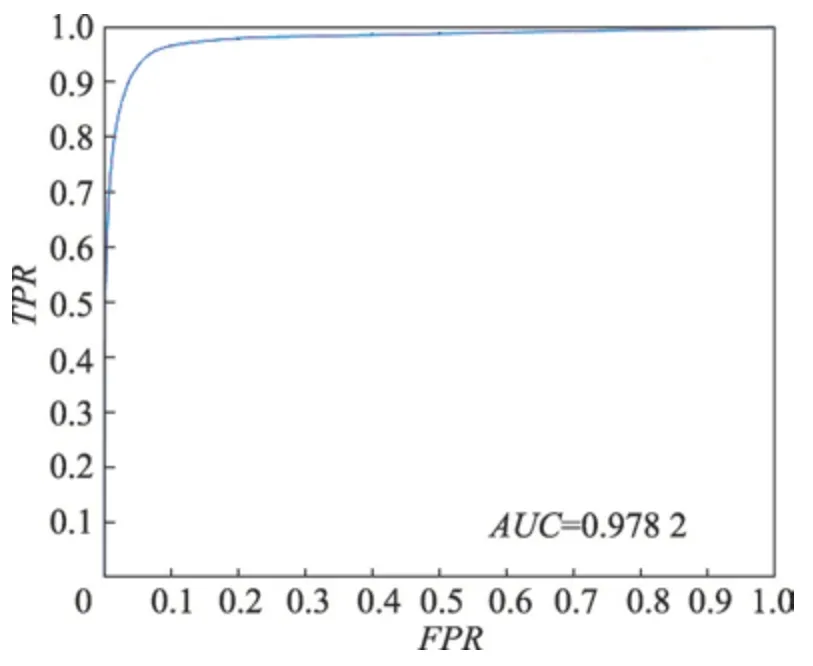
Fig.6 ROC curve图6 ROC 曲线
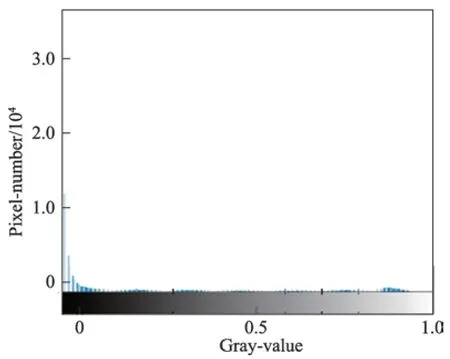
Fig.7 Histogram of test result图7 测试结果的直方图

Fig.8 Partial test results图8 部分测试结果
在DRIVE 训练集上进行测试,得到图6 的ROC曲线以及AUC 值。从图中可以看出,ROC 曲线靠近左上角,并且AUC 值高达0.978 2,体现了本文算法的可靠性。网络模型测试的结果是一张二维的灰度图,体现的是血管分布的概率图,还需要进一步二值化得到最终的分割结果。在阈值分割前,先将测试结果采用最大最小归一化法调整到[0,1]的范围内。为了分析血管的分布情况,取出一张测试结果的直方图进行分析,如图7 所示。可以发现,图中像素值的分布主要集中在0 和0.9 附近,通过最大类间方差算法可以自动地寻找最佳阈值,并进行阈值分割。最后对得到的网络模型在DRIVE测试集测试,Se、Sp、Acc平均指标分别达到了0.819 2、0.984 2、0.969 5,部分测试图像的分割结果显示在图8 中。其中,第三列为测试结果,第四列为二值化分割结果,最后一列表示的是二值化结果与专家分割图的对比,其中黄色区域为相交的区域,而红色区域是本文算法将背景错误划分为血管的部分,绿色部分为未被检测出的血管部分。以图8 中的第一张图为例,截取了对比结果的部分区域进行分析,为了检测本文算法对血管末端的检测效果,放大了局部血管末端,如图9(a)所示,可以看出检测的管末端基本跟专家分割的结果保持一致,并且血管的曲率、宽度、长度等属性几乎一致,也没有出现离散的点,具有很好的连续性。本文还放大了密集血管附近的区域,如图9(b)所示,可以看出,对于空间相邻的血管,并没有产生血管粘黏的现象,能很好地将血管间隙中的背景分割开来,达到了很好的检测效果。本文在实验中还发现,本文算法检测出了专家标记的血管部分,如图10 所示。将原图的绿色通道局部放大,可以看出原图中靠近视场边缘有一个细小的血管,如图10(a)中的白色箭头指向的区域,该血管对比度较小,肉眼很难看出,而本文算法却能够对对比度极低的细小血管进行检测,体现了本文算法的健壮性。本文算法也有不足的地方,如图11 所示。取了两块地方,一个是血管末稍处,还有一个是视盘区域,如图11(a)。其中血管末梢很多未被分割出来,而在测试结果中已经分割出来,如图11(b)所示。这跟本文的二值化方法有关,最大类间方差考虑的是全局,找到一个具体的阈值整体分割,缺少了血管的局部信息,导致二值化后未被正确分割出来,还需要进一步优化二值化方法,更多地考虑血管的局部信息。在对视盘区域分析时发现,将部分背景区域错误检测为血管。因为视盘亮度较高,边缘亮度较低,导致边缘区域对比度较高,被误检为血管,模型还需要进一步优化,更多考虑对视盘区域的特征学习。
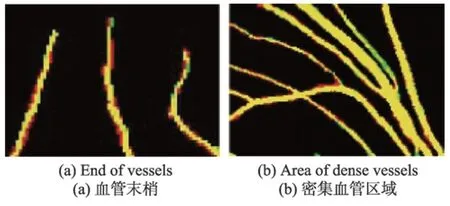
Fig.9 Local magnification图9 局部放大图

Fig.10 Unmarked blood vessels detected图10 检测出未被标注的血管
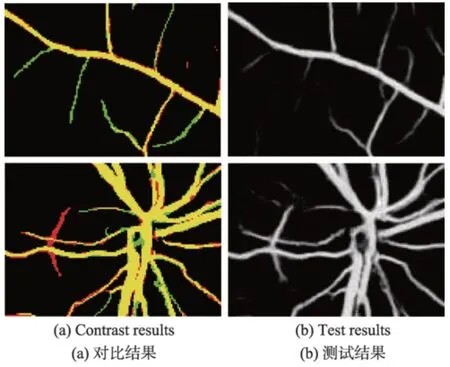
Fig.11 Undetected vessels图11 未检测出的血管
本文还与其他算法在DRIVE 数据库上的表现进行对比,结果展示在表2 中。其中,人眼观察的结果来自于DRIVE数据库第2位专家的分割结果。文献[8]仅采用B-COSFIRE 滤波器对血管进行特征提取,在不添加任何分类器的情况下,只靠阈值分割血管,效果接近人眼观察的结果;而单独地使用B-COSFIRE滤波特征,并没有考虑噪音问题,眼底图像中存在类似血管的背景噪音,单纯的阈值分割很难区别噪音,因此在文献[26]中,加入了RF(random forest)模型作为分类器,对包含B-COSFIRE 滤波特征的5 个特征对象进行训练,得到了0.960 6 的分割精确度;在本文算法中,利用全卷积神经网络的原理设计了新型的LVD 模型作为分类器,同样采用对血管响应较好的B-COSFIRE 响应特征作为训练对象,分割精确度达到了0.969 5。而在其他方法[17,27-28]中,训练数据都未采用眼底图像的B-COSFIRE 滤波特征,HED-CRF 算法直接采用的是未经处理的彩色眼底图像,分割精确度仅为0.951 5;FCN 和U-Net算法中都是采用了眼底图像局部的血管块,缺乏全局信息,分割精确度不高,分别为0.953 3 和0.953 1。对比发现,B-COSFIRE滤波响应特征更能让模型学习到血管的特征,并且对整个眼底图像的特征学习要比基于局部血管块的特征学习更容易获取到全局特征,分割效果更好。为了比较分类器的好坏,通过AUC指标进行分析,其中采用全卷积神经网络模型的AUC指标都超过了0.970 0,本文算法更是达到了0.978 2,而采用RF 模型仅有0.963 2,这是因为神经网络的学习能力要比传统的机器学习强,更深层次的网络更能表达图像的语义特征。并且本文采用的LVD 模型区别于文献[26-28]的全卷积网络模型,没有采用3×3 的卷积核,全部采用非对称的小卷积核,模型的表现比U-Net 模型还高。在DRVIE 数据库测试,Se、Sp、Acc、AUC分别达到了0.819 2、0.984 2、0.969 5、0.978 2,达到了先进水平。
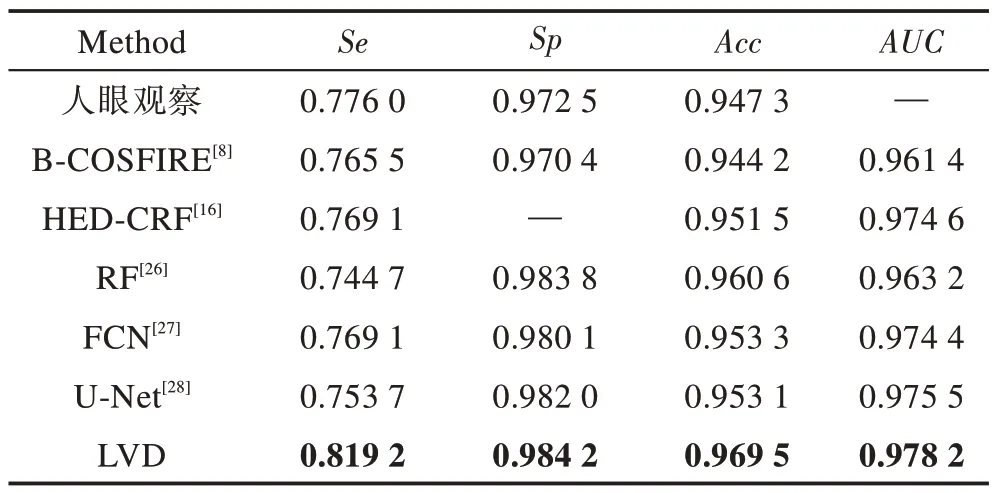
Table 2 Comparison of different algorithms on DRIVE表2 不同算法在DRIVE 数据库中的对比
4 结束语
本文针对自动分割血管设计了端到端的神经网络模型LVD,采用了彩色眼底视网膜图像中对比度较高的绿色通道和对血管有较好响应的B-COSFIRE滤波结果作为训练的两个特征,在3 个尺度下,分别用子网络ADS 提取血管特征,并将融合的结果通过最大类间方差获取最佳阈值后二值化,得到最终的分割结果。在DRVIE 数据库中,Se、Sp、Acc、AUC分别为0.819 2、0.984 2、0.969 5、0.978 2,体现了本文算法在血管特征提取上较强的学习能力,充分展现了本文算法在辅助医疗诊断的可行性。
