分类激活图增强的图像分类算法*
2020-01-11杨萌林张文生
杨萌林,张文生+
1.中国科学院 自动化研究所 精密感知与控制研究中心,北京100190
2.中国科学院大学 人工智能学院,北京100049
1 引言
图像分类是计算机视觉领域中的基本任务之一,它通过提取图像的判别特征将不同类别的图像区分开来。图像分类在疾病诊断[1]、场景识别[2]等领域有着重要的应用。近年来,由深度神经网络发展起来的深度学习[3]在各种计算机视觉任务上(如图像分类[4]、语义分割[5]、目标检测[6]等)取得了显著的成绩。然而深度神经网络巨大的参数量和高度的非线性化,使其学习机制不能完全被人所理解。因此深度神经网络的可视化、可解释性成为了深入理解深度学习的核心,也是突破深度学习发展瓶颈的关键[7]。
一种可视化、可解释特征图——分类激活图(classification activation map,CAM)[8]在2016 年被提出后,便得到了广泛的关注和研究。分类激活图是一种包含了高层语义信息的特征图,经过简单的后处理后,能够得到原始图像的分类热图,可用于可视化分析等。
分类激活图提供了直观的分类依据,但是分类激活图具有稀疏、不完整、不连续等问题[9-10]。主要原因是在分类标签的监督下,模型很容易陷入局部判别区域,而图像中其他的区域也能够提供一定的判别信息,这些判别信息可能是使模型获得更高层语义信息、提升分类性能的关键。除此之外,以往相关的研究中,大部分工作[8,11]仅仅利用分类激活图进行可视化分析等。事实上,具有可解释性的分类激活图能够帮助理解模型的结构,进一步改进和提升原有模型的性能。
基于以上观察,本文从分类激活图入手,改进和增强原有图像分类算法。针对原始分类激活图稀疏、不完整、不连续的问题,本文在特征层面上采用多尺度扩张卷积,并自适应学习每一个尺度的权重。由于原始分类激活图的获取需要两步的后处理,本文结合多尺度特征的学习设计了单步的多尺度分类激活图获取的方法,并且构成了端到端的网络模型进行学习。总结一下,本文主要的创新点和贡献为:
(1)提出了自动加权的多尺度特征学习方法。该方法简单、高效,并且能够根据梯度反传自适应学习每一个尺度特征的权重。
(2)将多尺度特征学习与分类激活图结合,提出了单步、直接的多尺度分类激活图获取方法,该方法能够嵌入到网络中形成一种端到端的结构。同时该分类激活图具有多尺度的特点,在一定程度缓解了原来激活图稀疏、不完整、不连续的问题。
(3)设计了一种分类激活图增强的网络结构ResNet-CE。该网络在三种公开的数据集CIFAR10、CIFAR100、STL10 上进行了大量的实验,结果表明ResNet-CE 的分类性能相对于基准模型ResNet 都有了明显提升,分类错误率分别降低了0.23%、3.56%、7.96%,并且优于目前大部分的分类模型。
2 相关研究工作
本文的工作涉及深度学习中主流的分类模型,基于扩张卷积的多尺度特征学习,分类激活图等,以下相关研究工作将从这几方面依次展开。
2.1 基于深度学习的图像分类模型
1998 年,Lecun 等人提出了神经网络的基本结构LeNet[12],应用在了手写数字识别上。2012 年,Krizhevsky 等人提出了8 层的AlexNet[4]利用GPU 加速,在大规模数据集ImageNet[13]上进行了验证,相对于传统的方法AlexNet 有了显著的提升。2014 年,Simonyan 等人考虑使用较小的卷积核和步长来提升参数量和网络深度,提出了16、19 层的VGG 模型[14]。与此同时,Szegedy 等人从多尺度的角度考虑引入了Inception 结构,并提出22 层的GoogLeNet[15]。进一步,2015 年He 等人设计了一种残差模块[16-17],在一定程度上缓解了由深度引起的梯度弥散的问题,使得网络深度得到了大幅度的提高,网络的性能也得到了极大的提升。进一步,2017 年Huang 等人从特征的重复、充分利用出发采用密集连接,提出了DenseNet[18]。表1 总结了以上模型的特点。
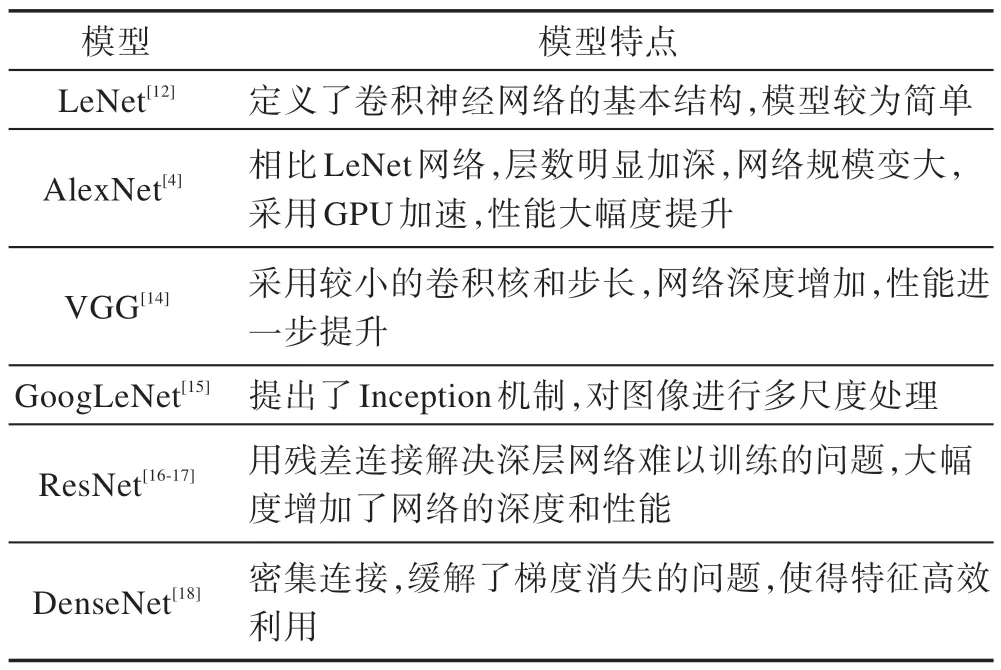
Table 1 Summary of related deep neural networks表1 相关深度神经网络的总结
2.2 基于扩张卷积的多尺度特征学习
与图像层面的多尺度学习不同,本文提出的多尺度学习是在特征层面进行的,并且根据梯度反向传播自动对每一个尺度的特征加权,该方法简单、有效,几乎不增加额外的计算量。该多尺度学习主要通过扩张卷积来实现,扩张卷积典型的特点是在参数量相同时,拥有更大的感受野。
扩张卷积,又称为空洞卷积。相比普通的卷积,扩张卷积引入了扩张率的概念,即在相邻的卷积核之间增加“空洞”(零元素)。扩张卷积的数学形式很早就被提了出来用于小波分解[19]。2015年,Yu等人[20]将不同扩张率的扩张卷积用于不同的网络层中,来提取上下文信息进行语义分割和图像分类。进而,他们将扩张卷积与ResNet 结合,提出DRN(dilated residual networks)模型[21]进行图像分割,并解决了由扩张卷积引入的Gridding artifacts 问题。后期大部分的工作将扩张卷积用于目标定位、语义分割等[22]。
2.3 分类激活图
深度神经网络的可视化或者可解释性有着重要的意义,这里重点介绍采用分类激活图的可视化方法。分类激活图是一种具有高层语义信息的特征图,由Zhou 等人[8]在2016 年提出来。构造分类激活图的基本思想是对网络中最后一层的特征图进行加权,该权重来自全连接层。在此基础上Selvaraju 等人[23]发现了一种通过梯度的方法计算该权重的方法,从而提出了梯度加权的分类激活图(gradient-weighted class activation mapping,Grad-CAM)。2018 年,Zhang 等人[9]证明了一种与原始分类激活图[8]等价但更直接的方法,但是该方法无法直接解决分类激活图固有的问题,Zhang 等人利用特征互补的方式实现分类激活图的补全,进行目标定位。结合文献[9]中的方法,本文提出了多尺度分类激活图获取方法,该方法能够直接嵌入到网络中提升判别能力、增强分类,并且在一定程度上缓解了分类激活图存在的问题,在3.3 节中进行了详细的介绍。
3 分类激活图增强的图像分类算法
本文以残差网络为例构造了ResNet-CE 模型,示意图如图1 所示。下面从基本网络骨干ResNet、多尺度分类激活图等依次展开相关的设计。
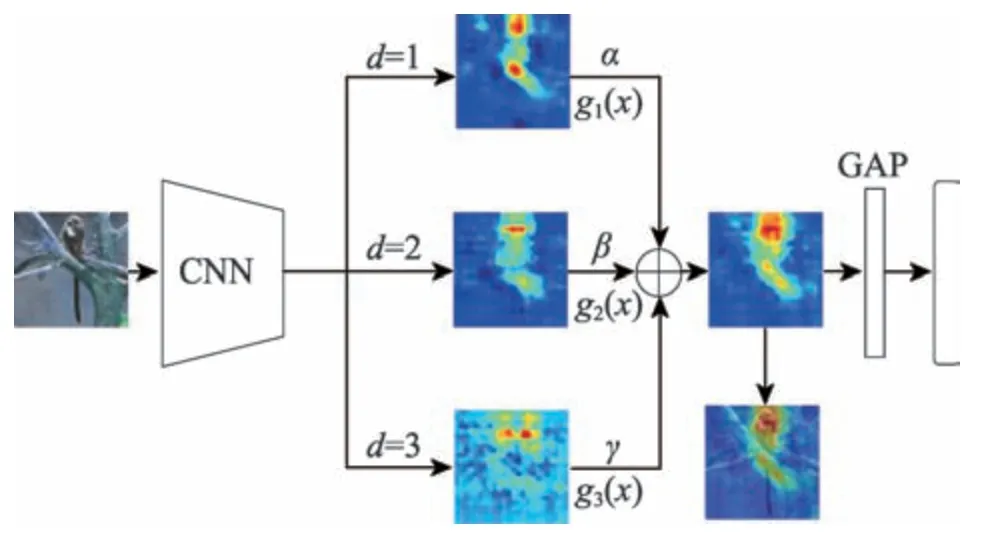
Fig.1 Framework of classification algorithm based on classification activation map enhancement图1 分类激活图增强图像的分类算法的基本框架
3.1 基本网络骨干
ResNet 的基本结构是残差模块,该模块在一定程度缓解了梯度弥散的问题,增加了网络的深度,提升了网络的性能。
如图2 所示,在该模块中,对特征图x∈ℝW×H×N和经过卷积输出的f(x)∈ℝW×H×N直接建立了一条连接,进行信息融合,得到输出h(x)∈ℝW×H×N:

其中,(W,H) 为特征图的宽和高,N为特征图的通道数。
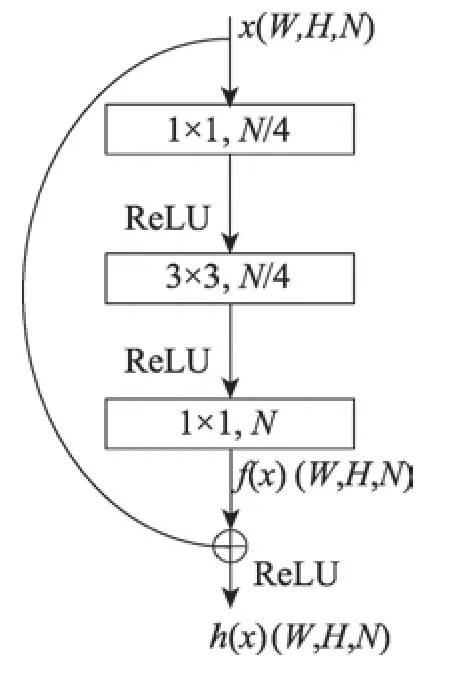
Fig.2 Residual block图2 残差模块
通过堆叠该模块,可以得到不同层数的网络结构。在一定的范围内,层数越深,模型的分类效果越好,但同时训练时间、测试时间以及需要的计算资源会相应地增加。兼顾分类性能和效率两方面的因素,参照文献[16]中ResNet-50(如表2 所示)的配置,取前3 个模块,n取值为16,进行本文的实验,提出的ResNet-CE 即在该配置下进行设计的。
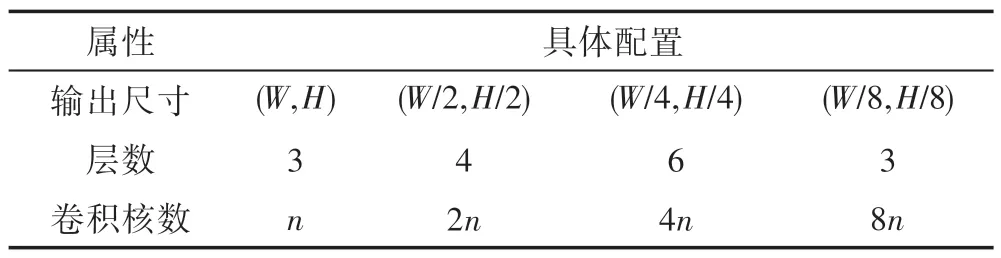
Table 2 Parameter configuration of ResNet-50表2 ResNet-50 参数配置
3.2 多尺度特征学习与分类激活图
某一扩张率的扩张卷积能够感受一定尺度的语义信息,而融合不同扩张率的扩张卷积能够获得多尺度或上下文的语义信息。同时,与使用多种不同大小卷积核的卷积相比,采用多种不同扩张率的扩张卷积可以大大降低参数量和运算量。如图3 为扩张卷积的示意图(从左至右扩张率依次为1、2、3)。扩张卷积与普通的卷积在相同参数量的情况下,感受野得到了大幅度的提升。卷积核大小为3×3,扩张率为d的卷积,其感受野与卷积核大小为[3+2(3d-1)]×[3+2(d-1)]的卷积相同,扩张率d为1 时,扩张卷积和普通的卷积相同。

Fig.3 Illustration of dilated convolution图3 扩张卷积示意图
对于特征图x(i,j),当采用卷积w(m,n)(其中i、j、m、n为二维矩阵的索引值),普通的卷积运算为:
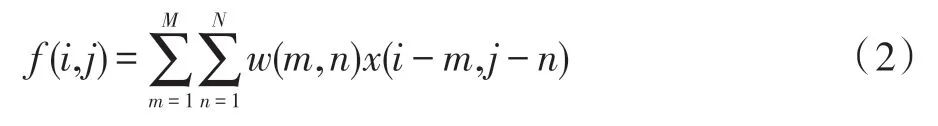
扩张率为d的卷积运算为:
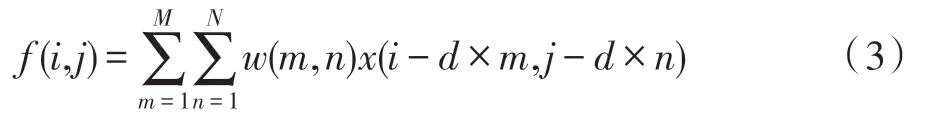
进一步,图4 展示了三种分类激活图的获取方法。原始的分类激活图(图4 Original CAM)需要两个步骤:(1)从全连接(fully connected,FC)层获得权重;(2)将权重映射回之前的特征图。文献[9]中采用了一种等价的方法(图4 Equivalent CAM),即用C个1×1 的卷积替换全连接层,并移至平均池化层(global average pooling,GAP)之前,从而直接得到通道数为C的特征图,即为分类激活图,其中C等于类别数。但是该方法没有直接解决分类激活图本身的问题,并且由N通道转换至C通道时丢失了太多的语义信息。

Fig.4 Methods to obtain classification activation map图4 分类激活图获取方法
考虑到多尺度特征学习以及语义信息的过渡,本文提出了多尺度分类激活图获取的方法(图4 Proposed method):即模型在由N通道的特征图转换成C通道的特征图时,引入了一个多尺度的卷积模块(图4 Multiscale conv block)。该模块中包含了多个尺度特征的提取,每一个尺度分别包含三个卷积,卷积核的大小分别是1×1、3×3、1×1,卷积的个数为N/2、N/2、C。扩张卷积在第二个卷积中实现,采用的扩张率为1、2、3(过大的扩张率会引入噪声和无关的上下文信息)。进行扩张卷积时,填补与扩张率相等个数的零元素来保持特征图的大小不变。其他两个卷积分别实现语义信息的过渡,降低运算量和直接将分类激活图嵌入到网络中形成端到端的结构。
利用该模块可以获得不同尺度的分类激活图,由于不同尺度特征的重要性不同,本文采用一种自适应加权的方式,具体的方法是:给每一个尺度的模块赋予一个初始权重,然后通过梯度反传的方式自动更新该权重,该方法简单但却十分有效。总结一下,构造该模型的具体步骤为:
(1)选取骨干网络的最后一层(或倒数第二层)作为提取分类激活图的特征图f(x)。
(2)将特征图f(x)通过多尺度卷积模块转变为具有类别信息的特征图g1(x)、g2(x)、g3(x)。
(3)对该特征图进行加权融合:

式(4)中,三个参数的初始权重设置为1 并随着网络的梯度反传自动调节,得到的g(x)进行批归一化处理。

式(5)中,E[⋅]表示均值,Var[⋅]表示方差,gk(x)表示第g(x)的第k个通道。式(6)中的γ、β是待学习的参数。
(4)对融合的分类激活图g(x)进行池化操作,再经过Softmax 输出最终的概率y:


式(7)、式(8)中,k的取值范围为[1,C],表示第k类的输出概率。
3.3 损失函数与评价指标
模型采用分类任务中常用的交叉熵作为损失函数,对于第k类,真实标签用yk表示,损失函数为:

评价指标用平均错误率(mean error,mE)进行度量,即测试集中分类错误个数n与测试集中样本总数N的比值:

4 实验与结果
由于构造ResNet-CE 时,另外加入了一个多尺度的模块,因此基准模型ResNet相应的多加入一个残差模块进行比较,确保参数量相当。ResNet 和ResNet-CE 严格采取相同的数据预处理方法、初始化方式、训练过程、优化方法、损失函数等。
4.1 数据集
本文在3 个公开数据集CIFAR10、CIFAR100[24]和STL10[25]上进行了相关的实验。其中,CIFAR10 数据集包含了10 种不同的类别,分别是飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车。每张图的大小是32×32,有3 个通道。CIFAR100 与CIFAR10 的图片格式一致,而类别为100 种。
4.2 CIFAR10 与CIFAR100 实验设置与结果
在CIFAR10 和CIFAR100 的实验中,有50 000 张图片作为训练集,10 000 张图片作为测试集。本文采用与文献[16]相同的数据预处理方法,即在训练集上进行两种处理:数据增广和不进行数据增广。数据增广:以0.5 的概率进行水平翻转,并将图片用零填充至36×36 的大小,然后在其中随机剪切出来32×32 的图片。无论哪种方式,都先在训练集上进行归一化,而在测试集上只进行数据的归一化,不进行数据增广。
实验采用随机梯度下降(stochastic gradient descent,SGD)的方式进行优化,与文献[16]不同的是,本文实验迭代次数为200,学习率初始值为0.1,在60、120、160 时以0.2 的倍率下调。训练时,图像批处理大小设置为128,测试时设置为100。按照以上设置,实验在PyTorch 0.4 框架下独立进行了5 次,计算出来5 次均值作为最后的结果,实验结果如表3 所示。
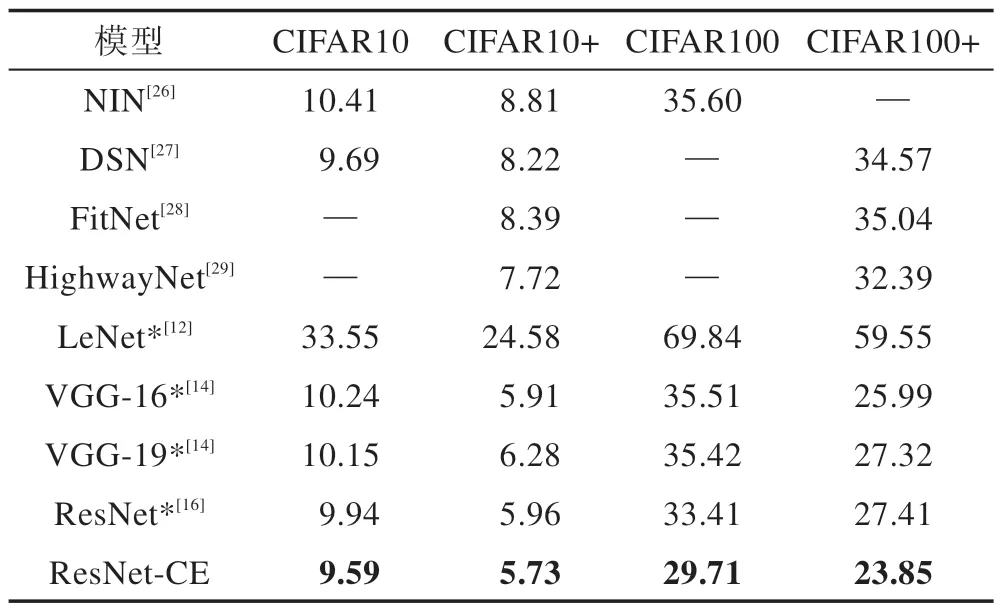
Table 3 Classification error rate of models on CIFAR10 and CIFAR100表3 模型在CIFAR10 和CIFAR100上的分类错误率 %
为了验证提出的ResNet-CE 的有效性,本文对比了多种模型在CIFAR10 和CIFAR100 上的实验结果,包括NIN(network in network)[26]、DSN(deeply supervised nets)[27]、FitNet[28]、HighwayNet[29]、LeNet[12]、VGG[14]、ResNet[16]。其中NIN 采用了一种多层感知机的卷积模块并用全局平均池化代替全连接层;DSN 为每个隐藏层引入伴随目标函数来提供直接的监督;FitNet采用了教师-学生的网络结构进行知识蒸馏;HighwayNet 应用了可学习的门限机制并引入了跨层的信息通道,以上模型直接引用了相关论文中的实验结果。LeNet、VGG、ResNet 在2.1 节进行了相关的介绍,在与ResNet-CE 相同的实验条件下,本文重新对这3 类模型进行了相关的实验(在表3 中加*号来区别)。
从表3 可以看出,本文提出的ResNet-CE 在两种不同数据预处理的实验下(“+”表示采用数据增广),分类的性能都好于基准模型ResNet 并且优于目前大部分主流的分类模型如VGG、HighwayNet、FitNet 等。采用数据增广时,ResNet-CE在CIFAR10和CIFAR100得到了5.73%和23.85%的错误率,相对于基准模型ResNet 分别降低了0.23%、3.56%。不进行数据增广时,ResNet-CE 效果更为明显,分类错误率低于基准模型0.35%和3.70%。
4.3 STL10 实验设置与结果
STL10 数据集[25]中包含了113 000 张图片,每张图像的大小为96×96。训练集有5 000 张图片,测试集包含了8 000 张图片,分别都有相同的10 个类别:飞机、鸟、车、猫、鹿、狗、马、猴子、船舶、卡车。除此之外,STL10 还包含了一些无标签的图片。该数据集可进行半监督学习和监督学习的实验,本文只利用有标签的图像进行监督学习,来验证提出算法在较大图片以及少量样本上的有效性,该数据集更符合实际的应用场景。
在STL10 上同样进行两种数据预处理,即数据增广和不进行数据增广。STL10 的数据增广:以0.5的概率水平翻转,并在图像周围填充零元素至100×100,然后在其中随机剪切出来96×96 大小的图片。网络配置和训练方式与CIFAR10/100 相同。
从表4 中的实验结果可以看出,ResNet-CE 相比于基准模型ResNet,在STL10 数据集上有明显的提升。在两种数据预处理下的实验,ResNet-CE 错误率分别降低了9.61%和7.96%,达到了27.03%和15.91%的错误率。由于STL10 训练集只有5 000 张图片,数据量小且少于测试集8 000 张图片,进行数据增广后,两个模型性能都有显著的提升。

Table 4 Classification error rate of models on STL10表4 模型在STL10 上的分类错误率 %
5 实验分析与讨论
5.1 自动加权的多尺度特征学习
为了验证自动加权学习方式的有效性,本文将ResNet-CE 多尺度卷积模块的每一个尺度权重系数固定为1,进行了对比实验,实验结果如表5 所示。
在表5 中,ResNet-CE(-)表示不采用加权的学习模型。由实验结果可以看出采用加权学习的ResNet-CE 在3 种不同的数据集上,分别进行的两种实验(共6 组实验)获得的分类错误率都有不同程度降低。在CIFAR10 和CIFAR100 上的错误率较低的程度不是非常明显,主要原因是该数据集相对简单,基准模型已经达到了很高的识别率。在STL10 上分类错误率较为明显,分别降低了3.59%、2.20%。

Table 5 Classification error rate of models in different learning styles表5 模型在不同学习方式下的分类错误率 %
5.2 多尺度分类激活图与分类热图
STL10 数据集分辨率较大,本文以STL10 为例,生成STL10 对应的分类热图进行分析和讨论。
分类激活图转成可视化的热图需要简单的后处理:首先对得到的分类激活图进行双线性插值,使分类激活图大小等于原始图像,进一步覆盖到原始图像上,从而得到热图,其过程如图5 所示。

Fig.5 Heatmap generation process图5 热图生成过程
根据上述方法,图6展示了由ResNet-CE和ResNet在STL10 生成的热图,其中第1、4 行是原始图像,第2、5 行是由ResNet产生的热图,第3、6 行是由ResNet-CE 产生的热图,热图中高亮的区域代表与分类相关的区域。
通过该热图能够发现:(1)模型是如何做出判断的,即模型判断的依据,如对于猫、狗、猴子等动物的判断,模型关注目标的脸部区域。对于船舶、飞机、卡车的识别,模型关注目标主体部分,这对模型或算法的理解和改进具有重要的意义。(2)基准模型ResNet 产生的热图(第2、5 行)表现出稀疏、不连续、不完整等问题,相对而言本文提出的ResNet-CE 稍微缓解了以上问题,语义信息更加明显和直观。尽管如此,得到的热图仍然是不完整的,对大部分图片,有相当一部分的区域被抑制了。另外,整体上看响应的判别区域越多越准,模型的表现越好,如何进一步挖掘判别区域将是一份有意义的工作。

Fig.6 Classification heatmaps generated by ResNet-CE in STL10 dataset图6 由ResNet-CE 在STL10 数据集上生成的分类热图
5.3 分类热图与模型输出
为了更加清楚说明分类热图与分类的关系,本文以图7 中的两组样本进行说明。图7 中第一列为待识别的图,第二列为ResNet 产生的热图,第三列为ResNet-CE 产生的热图。从图7 中可以看出ResNet-CE 感受到了更多、更精确的区域。
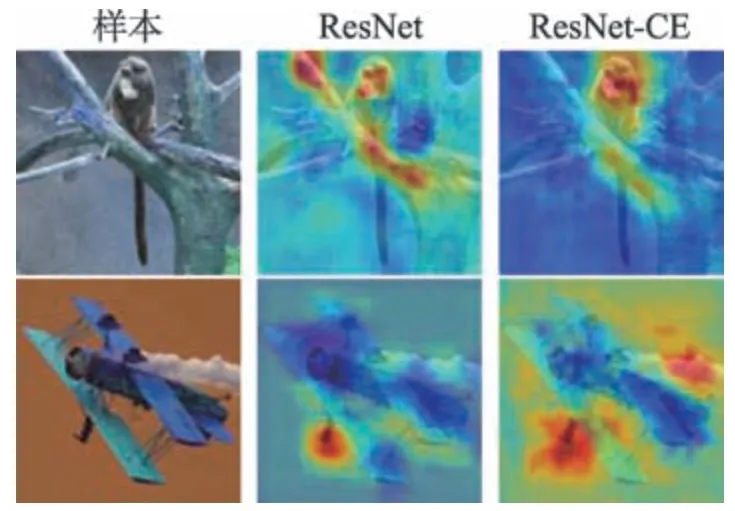
Fig.7 Samples and correspnding heatmaps图7 样本以及对应的热图
除此之外,表6 列出了这两个样本对应10 个输出通道的概率值。结合表6 和图7,可以看出样本1(标签为猴子,对应图7 的第一行),ResNet 抓住了两部分主要的特征,树干和猴子的脸部。输出通道#5和#8 的概率较大,分别为0.420 5 和0.377 0,其中#5对应的标签是鹿,#8 对应的是猴子。鹿的纹理和树的纹理有一定的相似之处,ResNet 没有很好地区分,而ResNet-CE 更多地关注了猴子脸部而抑制了树干的特征,得到的#8 的概率为0.644 3,#5 的概率为0.047 0。同样地,在样本2 中(标签为飞机,对应图7的第二行),虽然两个模型最终的结果都判为了第一类,即飞机,但是ResNet-CE 给出了更大的置信度(0.995 2),对应热图中的区域也更大、更准。
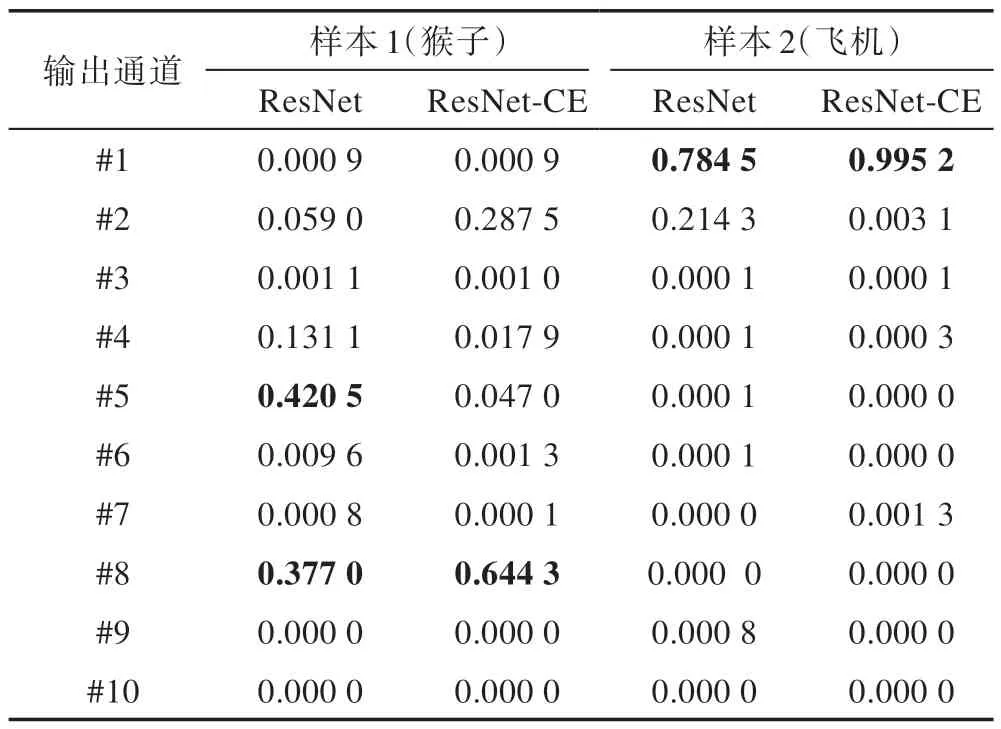
Table 6 Probability value of output channel of samples表6 样本输出通道的概率值
总的来说,ResNet-CE 通过多尺度扩张卷积得到了更多的具有判别性质的信息,进一步利用这些信息帮助模型做出决策和判断。通过不断的梯度反传,模型能够得到更准确的判别信息,从而提高模型的判别能力。
6 结束语
本文提出了一种分类激活图增强的图像分类算法。研究发现:(1)通过自动加权的多尺度扩张卷积能够在一定程度弥补原始分类模型下分类激活图不完整、不连续以及稀疏等问题;(2)通过对分类热图的进一步利用,挖掘出更多、更准的判别区域,能够在原有的分类模型上得到进一步的提升。本文提出的方法非常简单但十分有效,同时保留了分类激活图本身的可视化、可解释的功能,但是挖掘更多的目标区域仍需要进一步的探索。下一步的工作计划是研究图像中目标内部的相似性以及与背景的差异性,来挖掘更多的激活区域提升模型的性能。
本文提出的算法在医学影像的疾病诊断、无人驾驶的场景识别等有重要的意义。同时,也为分类算法等相关任务提供了一个新的研究思路和方向。
