个性化新闻推荐技术研究综述*
2020-01-11王绍卿李鑫鑫孙福振
王绍卿,李鑫鑫,孙福振,方 春
山东理工大学 计算机科学与技术学院,山东 淄博255091
1 引言
随着互联网、自媒体和新媒介技术的蓬勃发展,每天产生大量的网络新闻。网络新闻具有时效性、丰富性、深度性、交互性等特点,已经成为人们获取新闻的第一选择。网络新闻网站或新闻聚合网站众多,用户一般只是选择一个或很少的几个进行阅读。用户阅读新闻时,一般没有任何目的性,而只是想看发生了哪些有趣的事情或者大家都讨论什么。因此,用户的点击行为除了取决于个人兴趣外,还受大众潮流、新闻趋势的影响。另外,用户的点击行为还受新闻展示位置的影响。而在醒目位置展示的新闻一般是大众化的、热点的新闻,不具有差异化。新闻网站迫切需要把个性化的新闻向用户推荐。Google News、Yahoo!News、新浪、网易、今日头条、百度等都已经认识到个性化新闻推荐的价值所在,并已经在工业实践中应用了个性化新闻推荐。其中百度公司于2013 年12 月向学术界公开征集“面向推荐的重大突发新闻挖掘算法研究”解决方案;中国计算机学会于2014 年9 月开展了“用户浏览新闻的模式分析及个性化新闻推荐”大数据技术创新大赛;自2014 年以来,CLEF 协会连续举办多届新闻推荐竞赛,用于评估和优化新闻推荐算法。
尽管推荐系统在新闻领域已经取得了很大的进展,但仍需要进一步提高推荐性能,包括更好地对用户建模、更高级的推荐模型、可处理大数据等。
本文首先给出个性化新闻推荐的相关概念与系统架构,然后综述了各模块的研究进展,最后给出常用的数据集、实验方法、评估指标以及未来的研究方向。
2 相关概念与系统架构
推荐系统成为一个独立的研究领域正是源于其在新闻推荐领域的应用[1]。新闻的时效性、流行性、可扩展性等使得新闻推荐不同于产品推荐、电影推荐、音乐推荐等。为避免混淆,本文首先给出一些相关概念:
候选新闻:广义的候选新闻是指用户未阅读过的所有新闻,狭义的候选新闻指最近一段时间内(如24 h 内)发布的且用户未阅读的新闻。本文所用的候选新闻是指狭义的候选新闻。
候选推荐新闻:用推荐算法计算出来的,在一定程度上符合用户的兴趣偏好的新闻,或者一些突发新闻、热点新闻。
推荐新闻:在用户接口中,如计算机浏览器或移动端新闻APP 等,用户看到的推荐列表中的新闻。它是在对候选新闻排序后,通过设置评分阈值或指定Top-K值得到的。
个性化新闻推荐系统通常包含新闻建模、用户建模、推荐引擎和用户接口四部分,如图1 所示。
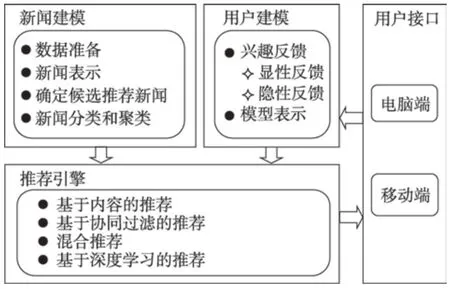
Fig.1 Architecture of system图1 系统架构
3 功能模块及关键技术
3.1 新闻建模
新闻文本中包含丰富的信息,但它是非结构化的文本,首先需要把它转换为结构化的文本,然后用模型把它表示出来。
3.1.1 数据准备
对于新闻聚合网站,如Google News、Yahoo!News、百度新闻、奇虎360 新闻等,需要首先扒取新闻,提取出新闻的标题、发布时间、正文等。对于CNN、新浪、搜狐、新华网等,则可以省略上述步骤;接下来需要对新闻文本进行分词(如果是英文则需要提取出词根);然后去除停用词,如中文的“是”“的”“在”“接着”,英文中的“is”“a”“the”等;最后从新闻文本中提取出时间、地点、人物等实体名称。其中,文本分词可分为细粒度分词和粗粒度分词,文献[2]中采用长度为10 的词串来分隔文本。
3.1.2 新闻表示
新闻文本具有静态特性和动态特性。静态特性包括特征词、主题分布、新闻类别、包含的实体、发布时间、发布媒体等;动态特性包括阅读该新闻的用户列表、新闻评分、累计点击量、流行度、时效性等。
在基于内容的新闻推荐方法中,主要采用抽取新闻文本特征词[3-4]和计算新闻组的主题分布[2],然后构造向量的方式来表示新闻。在Fab 系统[5]中,用100个权重最大的词来表示每个新闻文本,在Syskill &Webert 系统中则用了128 个特征词[1]。传统的向量空间模型是词袋模型(bags of words),忽略了词的顺序、语法、句法等因素。针对向量空间模型的不足,学术界提出了贝叶斯框架[6]、语言模型[7]、后缀树模型[8]、本体模型[9]、语义网络[10]等可更好地表示新闻。
在协同过滤方法中,文献[1]为每个候选新闻分配一个分数,这个分数与用户点击历史中的其他新闻短时间段内被共同访问的次数成正比。传统的矩阵因子分解方式,把新闻表示为潜在因子向量[11-12]。文献[13]把新闻表示为低秩矩阵,从而采用张量分解的方式进行新闻推荐。
在基于深度学习的推荐方法中,文献[14]利用卷积神经网络将新闻ID 和所有内容特征(包括层次分类、关键字和实体)作为文本来考虑,并使用字符级模型表示所产生的文本数据。文献[15]使用PVDBOW(distributed bag of words version of paragraph vector)训练新闻的分布式表示。文献[16]提出一个多通道和词-实体对齐的知识感知卷积神经网络,它融合了新闻的语义级和知识级表示。文献[17]提出一个基于去噪自动编码器变种的新闻分布式表示方法。文献[18]将每篇新闻的标题和文本结合起来,使用doc2vec 模型学习新闻的分布式表示。文献[19]使用inception 模块从新闻文本中学习新闻的分布式表示。
3.1.3 确定候选推荐新闻
为提高推荐的效率,应从最近发布的新闻中筛选出候选推荐新闻,它包括去除重复新闻,计算相关新闻、热点新闻和突发新闻等。
新闻聚合网站,如Google News、Yahoo! News、百度新闻、今日头条等,收集到的新闻会有很大比例重复性,需要去除重复。
对于同一个时间段发生的,相似度比较高[20]或关联比较密切[21]的多条新闻,需要选择一条作为候选推荐新闻,而其他作为相关新闻。因为显示推荐模块的空间有限,应保证推荐结果的多样性。如,一场足球比赛结束后的综合报道应该是候选推荐新闻,而出场阵容、半场比分、赛后的新闻发布会、技术统计等应该是相关新闻。常用的选择策略有链接分析模型(PageRank[22]、HITS(hyperlink induced topic search)[23]等算法)、基于协同的模型、基于关联的模型(SimRank算法[24]、Linkclus 算法[25])、子模模型[2]等。文献[19]使用潜在因子模型从百万级的候选新闻中筛选出数百个候选推荐新闻。
用户阅读新闻的兴趣常常受新闻趋势的影响,因此区域热点新闻和突发新闻同样也属于候选推荐新闻。文献[6]利用短时间内公众的点击分布来判定新闻趋势,从而确定候选推荐新闻。
3.1.4 新闻分类和聚类
用户的偏好都是基于新闻主题的,而新闻主题又是基于新闻类别的,有效的新闻分类和聚类可大大提高推荐的效率,并可增强新闻推荐的准确性。如,系统向一个完全不喜欢体育的用户推荐新闻时,完全没有必要计算该用户的偏好与一场普通球赛新闻的相似度。文献[2]首先采用MinHash[26]和局部敏感哈希(locality-sensitive Hashing,LSH)[27]把全部新闻分成多个小新闻组,然后用基于层次的方式进行聚类,并用潜在狄利克雷分布(latent Dirichlet allocation,LDA)[28]的方式抽取新闻组的主题分布,最后用一个主题向量来表示。
3.2 用户建模
用户对于新闻的交互行为中,会表现出显性或隐性的偏好。不同的推荐系统用不同的模型表示用户的兴趣偏好。
3.2.1 用户兴趣反馈
用户兴趣反馈分为显性反馈和隐性反馈。
3.2.1.1 显性反馈
显性反馈包含两种方式:用户定制和用户对阅读过的新闻进行评分。
用户定制是指用户向系统提供个人关注的新闻主题或分类[29-30],如NBA、足球、刘德华等。Google News 中可随时调整各新闻分类的权重,Zite 则是在注册时让用户选择感兴趣的主题。用户注册账号时提供的人口统计学信息也常常是进行推荐的依据,如年龄、性别、职业等。
新闻评分又分为两级评分和多级评分。如,在Yahoo!News 和CROWN(context-aware recommender for Web news)[13]中采用两级评分,喜欢和不喜欢。多级评分可以更详细描述对某条新闻的喜欢程度,如GroupLens[31]中用户对新闻的喜好程度可评价为1 至5 分。
3.2.1.2 隐性反馈
很多时候用户不能够准确提供个人偏好,或者不愿意显性提供个人偏好,更不愿意经常维护个人的偏好。因此,隐性反馈往往能够正确地体现用户的偏好以及偏好的变化。常用的隐性反馈信息有:是否点击[1,12]、停留时间[32]、点击地点[33]、是否加入收藏[13]、社交网络[34]、流行趋势[6]、点击序列[14]等。在协同过滤推荐方法中,常常把用户的隐性反馈转化为用户对新闻的评分。如,Google News[1]中用户阅读过的新闻记为喜欢,评分为1,没有阅读过的评分为0。文献[12]充分利用用户的隐性正反馈和负反馈,为每个用户创建具有区分度的模型。
3.2.2 用户模型的表示
用户的兴趣可分为长期兴趣和短期兴趣[1,6]。长期兴趣反映用户的真实兴趣;短期兴趣常与热点新闻相关联且经常改变,从最近的阅读历史中学习到的短期兴趣模型可快速反映用户兴趣的变化。常用的模型有向量空间模型[3]、语义网络模型[35]、基于分类器的模型[29]、分布式表示[14-17]等。
文献[1]使用短时间内用户共同访问的网页建模短期兴趣,而使用用户兴趣聚类结果建模长期兴趣。文献[6]从新闻趋势的角度对短期兴趣进行建模,即使用公众的点击模式,而不是仅仅使用用户自己的反馈。文献[36]中用户的长期兴趣配置文件是根据用户随时间读取的新闻创建的。为此,系统收集与这些新闻相关的标记,并通过考虑用户读取特定标记的次数来创建配置文件。而用户的短期兴趣配置文件是基于最近的一组用户与之交互(阅读、喜欢或共享)新闻。文献[16]使用注意力网络来建模用户点击过的新闻对候选新闻的影响。文献[17]把用户的浏览历史记录作为输入,使用循环神经网络(recurrent neural network,RNN)产生用户的分布式表示。文献[19]使用inception 模块学习用户的分布式表示。
3.3 推荐引擎
推荐引擎是个性化推荐系统的核心部分。它的功能是向用户推荐符合用户偏好的新闻,排序后以列表的形式向用户展示。
3.3.1 推荐方法
推荐系统的推荐方法可分为基于内容的推荐、协同过滤推荐、混合推荐和基于深度学习的推荐。
3.3.1.1 基于内容的推荐
一直以来,基于内容的推荐系统都被用来过滤并推荐基于文本的物品,如电子邮件或新闻[6,12]。基于内容的推荐是根据用户的阅读新闻历史记录进行推荐。计算候选新闻与用户阅读历史记录中新闻的相似程度,从而得到候选推荐新闻。基于内容的推荐可分为计算相似度和转化为分类问题两类方法。
(1)计算相似度。抽取出用户兴趣特征向量和候选新闻的特征向量,计算它们的相似性,向用户推荐相似度最大的K条新闻或者大于某个相似度阈值的新闻。文献[29]用最近邻的方式确定候选新闻是否符合用户的短期兴趣。常用的相似性度量标准有重叠系数(overlap coefficient)[37]、Jaccard 相似性[2]、余弦相似性(cosine similarity)[2]。
(2)转化为分类问题。以用户阅读过的新闻为训练数据,把新闻推荐问题转化为二分类问题:即喜欢和不喜欢。首先把非结构化的文本转化为结构化的文本,提取出特征向量;然后用机器学习的方法,如决策树归纳、朴素贝叶斯、支持向量机等,训练出一个模型;最后把所有候选新闻代入这个模型,计算出候选推荐新闻。例如,Syskill&Webert 系统[3]和Google News[6]使用了贝叶斯分类器。
基于内容的新闻推荐方法的主要优点有:(1)不需要其他用户的数据;(2)新出版的新闻可以被及时推荐给感兴趣的用户。主要缺点有:(1)浅层内容分析,没有考虑美观、时效性、多媒体元素等;(2)推荐结果缺乏新颖性,用户之前没有阅读过的新闻或突发新闻等无法进行推荐;(3)新用户无法进行推荐。
InfoFinder[38]和NewsWeeder[39]是纯粹的基于内容的推荐系统。现阶段,商业领域几乎没有纯粹的基于内容的推荐系统。
3.3.1.2 协同过滤推荐
协同过滤推荐的核心是基于用户的评分数据,与被推荐新闻的内容无关,即:在阅读历史中对新闻评分相似的用户在将来也会相似,从而把推荐转换为评分预测问题。
自从1994 年的GroupLens[31]之后,协同过滤在学术界获得极大的研究兴趣,取得了丰硕的研究成果,并应用到很多的工业实践中。
协同过滤推荐分为基于记忆的和基于模型的两种方法。
(1)基于记忆的方法。根据相似用户对新闻的评分或相似新闻得到的评分向用户进行推荐。关键的计算步骤是寻找相似用户或相似物品,因此可以分为基于用户的(UserCF)方法[31]和基于物品的(ItemCF)方法[40]。Digg 系统(http://digg.com/)采用了基于用户的推荐方法,因为热门度是新闻很重要的属性,基于用户的推荐可以在提供个性化的同时保证热门度。
为进一步提高基于记忆推荐的性能,学者们提出了缺省投票、逆用户频率、样本扩展[41]、方差权重因子、重要性赋权[42]、主流加权预测[43]等概念。
基于记忆的推荐方法的优点是算法简单、可解释性强,缺点是扩展性较差,难以应对大数据。
(2)基于模型的方法。首先线下处理历史评分数据,用统计和机器学习的方法生成一个模型,从而预测用户对候选新闻的评分。主要包括隐因子模型[11,19]和概率模型[1-2,44]两大类。
在基于隐因子模型的方法中,会抽象出一个隐形因子空间,然后把用户和新闻分布投影到这个空间上,进而预测用户对新闻的评分。概率模型预测的准确率较高,因此成为近年来的研究重点。常见的概率模型有朴素贝叶斯分类[6]、贝叶斯信任网络[45]、概率潜在语义索引(probabilistic latent semantic indexing,PLSI)[46]、潜在狄利克雷分布(LDA)[28]、MinHash[1]等。其中文献[1]分别用MinHash 和PLSI 对用户进行聚类,文献[2]使用了LDA 的方法计算新闻聚类或新闻组上的隐含主题。文献[44]使用MinHash 和LSH 向用户快速推荐最新的新闻。
对于基于模型的方法来说,必须解决模型的连续更新问题,即如何实现增量更新。
文献[1]用基于模型的方法对用户进行聚类分析,同时用基于记忆的方法计算不同新闻的共同阅读次数(covisitation counts)。
基于协同过滤的方式优点有:(1)共用其他人的经验,避免了内容分析的不完全或不精确,并且能够基于一些复杂的、难以表述的概念(如新闻品质、个人品味)进行过滤;(2)推荐个性化、自动化程度高;(3)推荐结果会有一定的惊喜度。缺点有:(1)新闻冷启动问题,推荐依赖于其他用户,需要较长时间收集其他用户的点击行为,导致突发新闻无法及时推荐;(2)用户冷启动问题,系统开始时推荐质量较差;(3)数据稀疏问题,用户已阅读的新闻远远小于每天产生的新闻;(4)没有考虑用户之间的差异,倾向于推荐热门新闻。
3.3.1.3 混合推荐方法
基于内容的推荐方法和基于协同过滤的推荐方法各有其优缺点。现有的系统大部分是一种混合系统,它结合不同算法和模型的优点,又克服它们的缺点。文献[47]将混合方案分为三种:后融合、中融合和前融合。文献[48]区分出了七种不同的混合策略。而文献[49]将其概括为三种基本的设计思路:整体式、并行式和流水线式。
文献[2,50]使用了整体式混合推荐方法。文献[6]使用了并行式混合推荐方法,首先利用基于内容的方法计算用户对新闻的喜好评分,然后混合文献[1]提出的基于协同过滤方法的评分,从而得到最终的预测评分。
文献[5]使用了流水线式的混合策略。首先根据阅读历史中感兴趣的新闻中的特征词建立基于内容的用户模型,然后根据内容模型确定相似用户,最后向用户推荐他的相似用户喜欢阅读的新闻。
文献[11]利用费舍尔核计算新闻之间的语义和词分布的相似性,提出一种基于内容的协同过滤方式用于新闻推荐。
文献[51]把主题模型、协同过滤和贝叶斯个性化排序整合到一个框架中,用于推荐用户可能会进行评论的文章。
3.3.1.4 基于深度学习的推荐
深度学习是机器学习领域的一个热门话题。伴随ACM RecSys 2016 年会上首次召开深度学习推荐系统研讨会,基于深度学习的推荐技术开始流行[52]。
传统的推荐方法,包括基于内容的方法和协同过滤方法,都采用浅层模型进行预测,依赖于人工特征提取,很难有效地学习到深层次的用户和新闻的隐性表示。而使用深层神经网络构建预测模型能够更好地抓住用户和新闻之间交互的非线性结构特征。并且,利用深度学习模型融合广泛的多源异构数据,包括社会化关系、用户或项目属性以及用户的评论和标签信息等,能够学习到更加抽象、更加稠密的用户和新闻的深层次表示[53]。
基于深度学习的推荐方法可以分为两类:基于单个深度学习技术的模型和基于混合深度学习技术的模型。例如,文献[54]使用卷积神经网络(convolutional neural networks,CNN)建模新闻的分布式表示及新闻推荐。文献[14]把CNN 和RNN 以分层的方式耦合在一起,从而可以同时提取上下文模式和处理长期和短期的依赖关系。文献[16]把知识谱图融入到CNN 中用于新闻建模,并设计注意力模块来建模用户的多样化兴趣。
3.3.2 推荐结果的排序
由于推荐结果展示给用户的条目有限,而不同的位置对推荐效果影响很大,文献[2]指出用户对新闻的兴趣是递减的。
文献[1]的评分独立于推荐引擎,文献[6]根据评分进行排序。文献[2]对混合推荐方法计算出的候选新闻集合进一步考虑热门性和时效性,进行微调后产生最终的推荐结果。
3.4 用户接口
用户接口承担展示推荐结果、收集用户反馈等功能。用户接口除了应具有布局合理、界面美观、使用方便等基本要求外,还应有助于用户乐于提供反馈。主要有两种类型的接口:电脑端和移动端。
电脑端接口适合用户在办公室、家庭等场所使用,具有屏幕尺寸大、可嵌入广告等优点。由于推荐系统是复杂商业系统的一小部分,通常作为一个独立的模块嵌入到复杂商业系统中,因此网页布局是非常重要的,如Google News 在其网页的右上角有“个性化”按钮;新浪网在其首页的中间部分嵌入“猜你喜欢”模块;网易网在其首页右上角有显著的“荐新闻”链接,在其首页中间部分嵌入“荐新闻”模块;Yahoo!News 用户点击喜欢(More like this)或不喜欢(Less like this)后,系统会弹出所评分新闻中的关键词供用户选择。
移动端接口可以方便用户随时随地查看新闻,且移动端本身的位置性、独有性有助于准确获取用户反馈。在非智能手机时代,文献[55]中强调只是把用户最感兴趣的新闻放在顶端而不限制用户的选择,随着智能手机的普及,推荐已经成为单独的一个模块,推荐的全部结果都应该是用户很感兴趣的新闻,用户若想阅读其他新闻,只需再点击非个性化的具体版块即可。文献[56]分别为Android、iOS和Windows平台设计了移动端接口。
4 个性化新闻推荐系统对比
现有文献中的个性化新闻推荐系统几乎全部包含新闻建模、用户建模、推荐引擎和用户接口4 个模块。表1 按照发表时间先后列举了14 个比较典型的系统/模型。由表1 可以观察到,不同的推荐方法对应不同的新闻建模和用户建模方法。随着时间的推移,研究人员发现越来越复杂建模的方法,从而更好地刻画新闻和用户。并且,基于深度学习的推荐技术具有较高的推荐准确度,成为现阶段最流行的推荐策略。另外,随着移动互联网的蓬勃发展,基于移动端的个性化新闻推荐接口越来越多。
5 常用数据集
5.1 UCI知识库
UCI 知识库(http://archive.ics.uci.edu/ml/)是Blake等人在1998 年开放的一个用于机器学习和评测的数据库。目前包含3 个可用于新闻推荐的数据集:Microsoft 数据集、MSNBC 数据集和Syskill&Webert数据。其中,Microsoft 数据集包含的是38 000 个用户在1998 年2 月某周内在微软主页的全部阅读历史记录;MSNBC 数据集包含的是989 818 个用户在1999 年9 月28 日在msnbc.com 上的阅读历史记录;Syskill&Webert 数据记录的是单个用户的阅读及评分历史记录。
5.2 Digg 数据集
Digg 数据集[61]是由美国南加州大学信息科学研究所收集的。收集的新闻是2009 年6 月份Digg 网站首页的3 553条新闻。包含两个表digg_votes和digg_friends。表digg_votes 中包含139 409 个用户对3 553条新闻的累计3 018 197 个投票。表digg_friends 包含71 367 个用户之间的1 731 658 个链接关系。该数据集删除了新闻标题和正文。
5.3 plista 数据集
plista 新闻推荐数据集[62]是在recSys2013 的新闻推荐系统挑战赛上公开的。该数据集包含2013 年6 月份的14 897 978 个用户在13 个新闻门户网站的84 210 795 条交互记录。
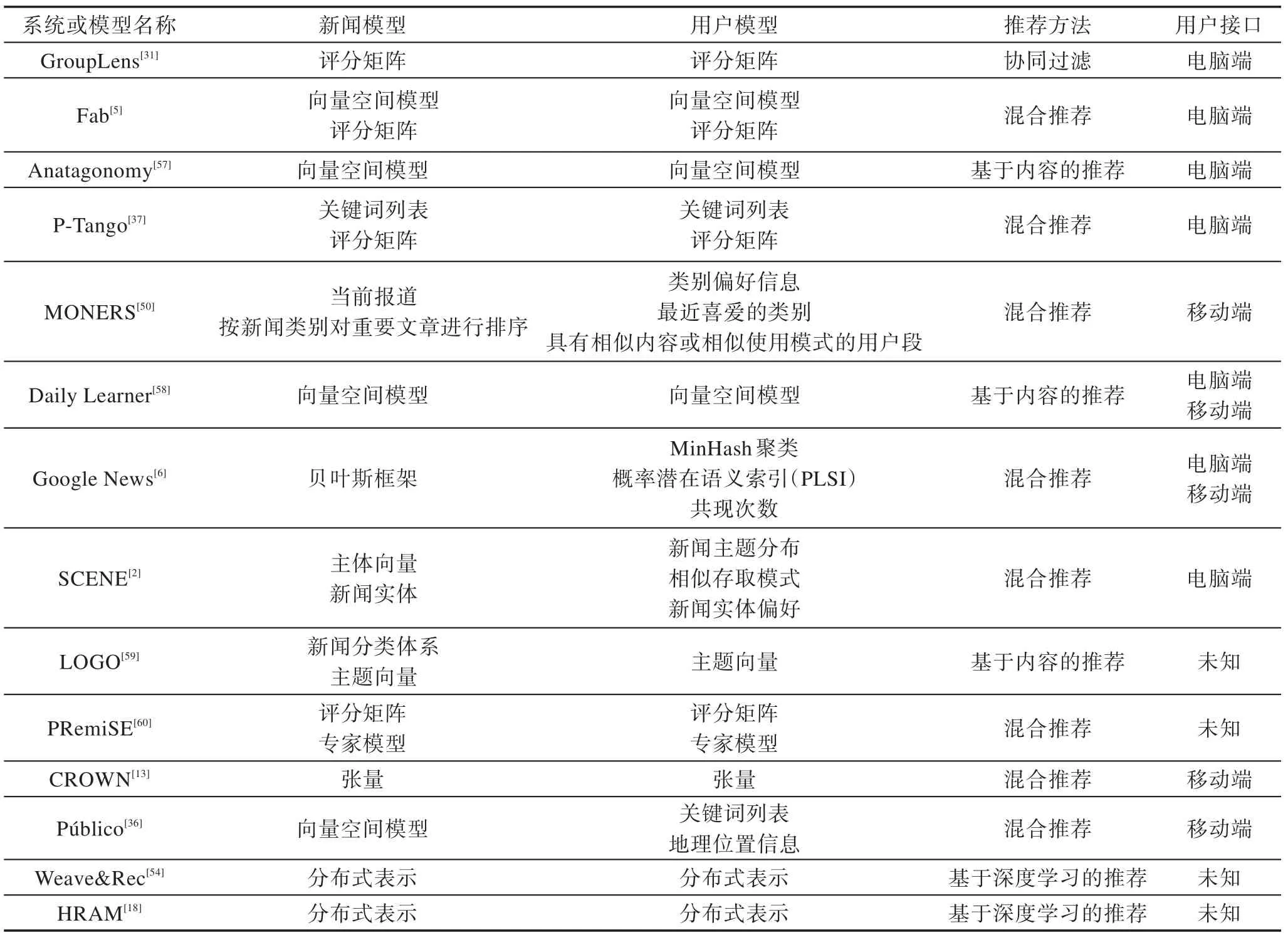
Table 1 4 components of some personalized news recommendation systems表1 一些个性化新闻推荐系统的4 个组件
5.4 Adressa 数据集
Adressa 数据集(http://reclab.Idi.ntnu.no/dataset/)包括两个版本Adresseadvisen 的新闻门户上的1 周流量的1.4 GB 数据集,以及10 周流量的16 GB 数据集。其中,1.4 GB 数据集包含11 207 篇新闻文章、561 733 个用户和2 286 835 个阅读行为;16 GB 数据集包含48 486 篇新闻文章、3 083 438 个用户和27 223 576 个阅读行为。
5.5 财新网数据集
2014 年中国计算机学会主办的“第二届中国大数据技术创新大赛”中公开了由财新网提供的数据集。包括10 000 个用户在2014 年3 月的所有新闻浏览记录。共包含10 000个用户对6 183条新闻的116 228条阅读记录。每条记录包括用户编号、新闻编号、浏览时间(精确到秒)以及新闻文本内容。
新闻推荐的大规模数据集的统计信息如表2所示。
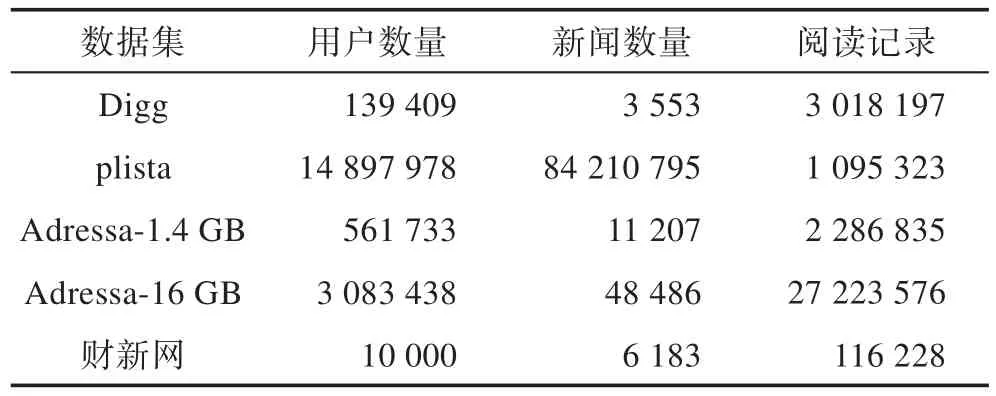
Table 2 Statistics of large-scale datasets of news recommendation表2 新闻推荐的大规模数据集的统计信息
6 实验方法和评测指标
6.1 实验方法
与面向其他领域的推荐系统类似,新闻推荐系统主要有三种实验方法:离线实验、用户调查和在线实验。如文献[2]同时采用了离线实验和用户调查的方法,文献[1,12]同时采用了离线实验和在线实验的方法,文献[6]采用了在线实验的方法,文献[16,18-19,54]采用了离线实验的方法。
6.2 评测指标
常用的评测指标有:点击率(HR)、准确率(Precision)、召回率(Recall)、F-score、平均绝对误差(MAE)、均方根绝对误差(RMSE)、AUC、LogLoss、Spearman 相关性、NDCG、Success@k、多样性、惊喜度等。文献[60]使用了F-score 评估指标,文献[1,63]使用了准确率(Precision)、召回率(Recall)评估指标,文献[6,64]使用了CTR 评估指标,文献[65]使用了Success@5 评估指标,文献[2]分别使用了F-score、准确率(Precision)、召回率(Recall)、多样性等评估指标,文献[37]使用了MAE评估指标,文献[16]使用了F1 和AUC指标,文献[19]使用了AUC和LogLoss指标,文献[18,54]使用了HR和NDCG指标。本文给出现阶段使用最多的F-score、HR、NDCG指标的具体计算公式。
F-score指标如式(1)所示:
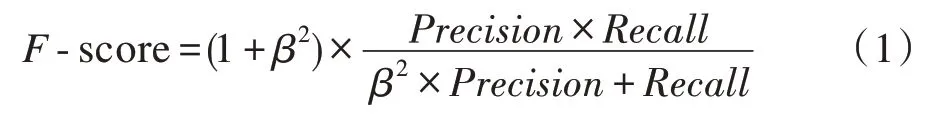
其中,Precision为准确率,又称为查准率,表示预测结果中,预测为正样本的样本中,正确预测为正样本的比例;Recall为召回率,又称为查全率,表示在原始样本的正样本中,被正确预测为正样本的比例。β用于调节Precision和Recall的重要性,当β=1 时,Precision和Recall同等重要;当β<1 时,Precision更重要些,否则Recall更重要些。
HR指标如式(2)所示:

其中,#hits@K表示推荐列表的前K项新闻中用户实际点击的个数,|GT|表示用户实际点击的新闻数量。
NDCG指标如式(3)所示:
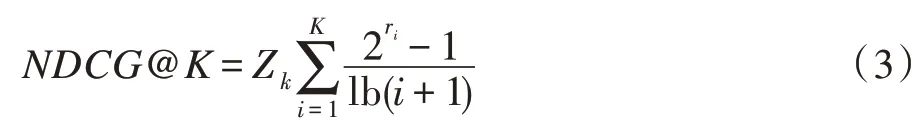
其中,Zk是归一化因子,用于确保完美推荐结果时的指标值为1。如果第i个推荐结果为测试集中的正样本,则ri的值为1,否则ri的值为0。
7 未来的研究方向
个性化新闻推荐是很早就开始研究的领域,近些年,伴随着新闻大数据的产生和移动互联网的蓬勃发展,又迎来了新的挑战。可以进行深入研究的方向主要包括:
(1)对新闻进行更准确的建模。文献[2]考虑了新闻中包含的实体名称,文献[6]考虑的新闻趋势是基于其他用户的点击行为,但时间上具有延迟性。有些新闻的时效性很强,如突发新闻、竞技比赛的报道等,这些新闻需要尽快地推荐给用户。而有些新闻的时效性较差,如富豪排行榜等,这些新闻即使不是最近发布的,如果用户对这些新闻感兴趣且之前没有阅读过,也应该进行推荐。研究人员还提出了标记语言模型、图模型、面向对象模型和本体模型等。文献[65]提出了上下文树模型和专家模型,可实现较高的预测准确率和惊喜度。文献[66]提出了基于本体表示的、与时间关联的建模方式。
网络新闻的来源多样,规模庞大,更新频率快,导致新闻的冷启动问题。对新闻进行更精准的建模,使得推荐结果具有新颖性、多样性和时效性等,是一个值得研究的问题。
(2)对用户进行更精准的建模。文献[1]仅使用了是否阅读新闻来对用户进行建模,文献[6]考虑了新闻趋势对用户的短期兴趣的影响,而用户的短期兴趣受很多上下文[67]因素影响。伴随着互联网的智能化,用户的行为数据和用户生成内容,如发布的新闻评论、转发行为、阅读时间、阅读地点等,都可以用于用户建模。
社会媒体的社交网络结构在信息的共享和扩散中发挥着越来越重要的作用。利用多源异构社交网络用户的信息融合、交互和信任关系建模的社会化推荐是一个新的研究方向。社交网络信息(发布的内容、社交好友等)、邮件信息(邮件内容、联系人等)等,都有助于更充分地挖掘用户的反馈信息,更精准地理解用户。
在新闻推荐领域,因为存在用户的兴趣漂移现象,所以需要实时对用户偏好进行更新,但对于新闻推荐中庞大的新闻数量、丰富的上下文信息,这种更新需要付出很大的代价,现阶段的研究还比较少,值得进一步研究。
(3)进一步优化推荐模型。新闻具有极高的时效性,需要进行实时推荐。用户浏览新闻时,在线新闻媒体需要在1 s 内提供推荐结果[1]。除了使用高速缓存方法外,文献[1]利用MapReduce 技术在几个机群之间分发计算任务,而文献[68]利用Ajax 技术实现异步解决方案。
权衡快速反映与过于敏感。一方面推荐的结果要快速反映用户兴趣的变化,另一方面又不要过于敏感,用户的偶尔涉猎不代表兴趣的变化。
传统的推荐模型具有简单、可解释性强等特点,而深度学习可以学习到用户和新闻的深层次特征,虽然目前已有相关研究出现,但这个方向值得关注。另外,将注意力机制与深度学习相结合,能够帮助推荐系统抓住新闻中最具有信息量的特征,推荐最具有信息量的新闻,值得未来深入研究。
(4)排序学习。由于推荐结果展示给用户的条目有限,而不同的位置对转换效果影响很大,推荐系统的排序学习成为一个重要的课题。排序学习算法可分为基于数据点的方法(point-wise)、基于数据对的方法(pair-wise)和基于列表(list-wise)的方法三种。其中基于数据点的方法目前使用最为广泛,基于数据对的方法和基于列表的方法是近年排序学习研究的热点。三种排序学习算法各有利弊,从信息完全度方面来分析,基于数据点的排序学习利用的信息是不完全的,样本复杂度为O(n),在三类算法中样本复杂度最低,但是排序效果较差;基于数据对的排序学习是部分完全的,样本复杂度为O(n2),排序效果一般;而基于列表的排序学习利用了完全的信息,样本复杂度为O(n!),排序效果最好。研究各种个性化推荐的算法和模型,设计适合个性化新闻推荐系统的排序学习模型是未来的一个研究方向。
另外,系统的灵活性、推荐的数量、推荐的覆盖率、推荐结果的惊喜度和多样性、用户的隐私保护[69]、模型融合方法、推荐模块的布局、商业价值转化率[68]也是需要深入研究的方向。
8 总结
新闻推荐是最早进行推荐系统研究的领域,已经取得了丰硕的研究成果,进行了很多的工业实践。工业实践已经表明高性能的推荐不仅可以节省用户的时间,而且能够吸引用户更多次的访问。但随着新闻大数据的产生,移动互联网的迅速发展,用户生成内容的增多,用户特征获取准确性的提高等,广大科研人员将面临新的研究机遇和挑战。希望本文能够为研究个性化新闻推荐的研究人员提供有价值的参考。
